

自然语言入门之ESIM
电子说
描述
ESIM是ACL2017的一篇论文,在当时成为各个NLP比赛的杀器,直到现在仍是入门自然语言推理值得一读的文章。
本文根据ESIM原文以及pytorch代码实现对ESIM模型进行总结,有些地方的叙述保持了与代码一致而和原文不一致,比如在embedding处与原文就不完全一致,原论文只使用了我下面所写的initial embedding,不过在代码性能上应该是不会比原文的更差的,因为代码过长,仅放一些伪代码帮助理解。计算过程公式稍多,但无非是LSTM和Attention,理解起来并不太困难。
介绍 Introduction
自然语言推断 NLI
NLI任务主要是关于给定前提premise和假设hypothesis,要求判断p和h的关系,二者的关系有三种:1.不相干 neural,2.冲突 contradiction,即p和h有矛盾,3.蕴含 entailment,即能从p推断出h或两者表达的是一个意思。
❝为什么要研究自然语言推理呢?简单来讲,机器学习的整个系统可以分为两块,输入,输出。输入要求我们能够输入一个机器能理解的东西,并且能够很好的表现出数据的特点,输出就是根据需要,生成我们需要的结果。也可以说整个机器学习可以分为Input Representation和Output Generation。因此,如何全面的表示输入就变得非常重要了。而自然语言推理是一个分类任务,使用准确率就可以客观有效的评价模型的好坏;这样我们就可以专注于语义理解和语义表示。并且如果这部分做得好的话,例如可以生成很好的句子表示的向量,那么我们就可以将这部分成果轻易迁移到其他任务中,例如对话,问答等。这一切都说明了研究自然语言推理是一个非常重要而且非常有意义的事情。
❞
下面从Stanford Natural Language Inference (SNLI) corpus数据集里举几个例子:
A woman with a green headscarf , blue shirt and a very big grin(咧嘴笑).
The woman is very happy .
上面两个句子就是 「entailment(蕴含)」 ,因为女人在笑着,所以说她happy是可以推断出来的。
A woman with a green headscarf , blue shirt and a very big grin .
The woman is young .
「neutral」
冲突矛盾(contradiction)的例子
A woman with a green headscarf , blue shirt and a very big grin.
The woman has been shot .
「contradiction」
她中枪了怎么可能还咧嘴笑呢?
模型架构 Models
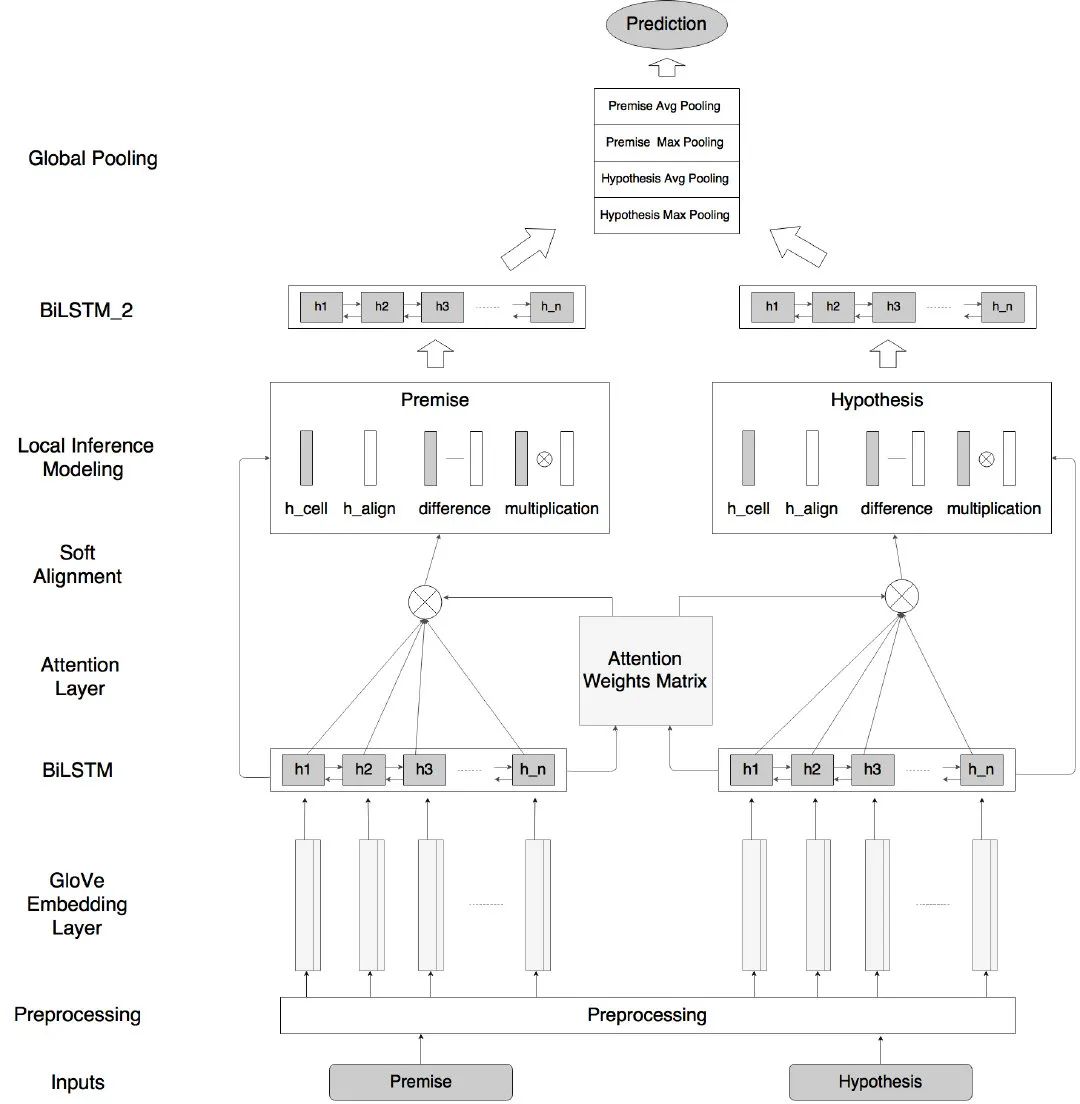
输入编码 Input Encoding
输入两个句子,从one-hot经过embedding层,有两个embedding层,分别是initial embedding( 「ie」 ) 和 pretrained embedding( 「pe」 ),都使用预训练好的词向量初始化,词向量维度为,不同的是 ie 的词表规模是训练集语料的单词个数,pe 的词表规模就是预训练文件所包含的单词数,且 pe 参数被冻结,ie中没被包含在预训练文件的OOV单词使用高斯分布随机生成,且所有embedding的方差都被normalize到1,得到和,每个单词的表示是一个 的向量,由其在 ie 和 pe 中对应的词向量 concat 得到, 为预训练词向量维度,
src_words, src_extwords_embed, src_lens, src_masks,
tgt_words, tgt_extwords_embed, tgt_lens, tgt_masks = tinputs
src_dyn_embed = self.word_embed(src_words)
tgt_dyn_embed = self.word_embed(tgt_words)
src_embed = torch.cat([src_dyn_embed, src_extwords_embed], dim=-1)
tgt_embed = torch.cat([tgt_dyn_embed, tgt_extwords_embed], dim=-1)
之后使用双向LSTM分别对a和b进行encoding,得到两个句子的隐层状态表示,论文中隐层向量的维度等于预训练词向量的维度,因为是bidirectional = True,所以 。
src_hiddens = self.lstm_enc(src_embed, src_lens)
tgt_hiddens = self.lstm_enc(tgt_embed, tgt_lens)
局部推理 Locality of inference
就是使用attention建立p和h之间的联系,即进行对齐操作,a和b中两个单词的注意力权重由向量内积得到。
Local inference collected over sequences(不知道咋翻译)
接着利用得到的注意力权重,对b进行加权求和,即从b中选取与相关的部分来得到表示,对b同理
similarity_matrix = premise_batch.bmm(hypothesis_batch.transpose(2, 1).contiguous())
# hyp_mask shape = [batch_size, tgt_len]
prem_hyp_attn = masked_softmax(similarity_matrix, hypothesis_mask)
# prem_mask shape = [batch_size, src_len]
hyp_prem_attn = masked_softmax(similarity_matrix.transpose(1, 2).contiguous(), premise_mask)
# Weighted sums of the hypotheses for the the premises attention,
# [batch_size, src_len, hidden_size]
src_hiddens_att = weighted_sum(hypothesis_batch,
prem_hyp_attn,
premise_mask)
# [batch_size, tgt_len, hidden_size]
tgt_hiddens_att = weighted_sum(premise_batch,
hyp_prem_attn,
hypothesis_mask)
局部推理信息增强 Enhancement of local inference information
现在a的每个单词有两个vector表示,分别是和,b亦然,再对两个vector分别做element-wise的减法与乘法,并把它们 concat 到一起,得到维度为原来四倍长的vector,
src_diff_hiddens = src_hiddens - src_hiddens_att
src_prod_hiddens = src_hiddens * src_hiddens_att
# [batch_size, src_len, 2 * lstm_hiddens * 4] 乘2是双向
src_summary_hiddens = torch.cat([src_hiddens, src_hiddens_att, src_diff_hiddens,
src_prod_hiddens], dim=-1)
tgt_diff_hiddens = tgt_hiddens - tgt_hiddens_att
tgt_prod_hiddens = tgt_hiddens * tgt_hiddens_att
tgt_summary_hiddens = torch.cat([tgt_hiddens, tgt_hiddens_att, tgt_diff_hiddens,
tgt_prod_hiddens], dim=-1)
推理合成 Inference Composition
继续使用LSTM提取特征,得到两个句子因果关系表示。因为 concat 操作会使得参数量数倍增长,为了防止参数过多导致的过拟合,把和经过一个激活函数为ReLU的全连接层,将维度从投影到,这样之后再经过一个BiLSTM层,得到
src_hiddens_proj = self.mlp(src_summary_hiddens)
tgt_hiddens_proj = self.mlp(tgt_summary_hiddens)
# [batch_size, src_len, 2 * lstm_hiddens]
src_final_hiddens = self.lstm_dec(src_hiddens_proj, src_lens)
tgt_final_hiddens = self.lstm_dec(tgt_hiddens_proj, tgt_lens)
池化层 Pooling
将组成整句话的sequence vectors分别通过 average pooling 和 max pooling(element-wise),变成单独的一个vector,并将它们再次 concat 起来,得到能完整表示p和h以及两者之间关系的final向量v
最后将他们送入分类层,分类层包括两个全连接层,中间是tanh激活函数,输出维度为标签种类个数。
hiddens = torch.cat([src_hidden_avg, src_hidden_max, tgt_hidden_avg, tgt_hidden_max], dim=1)
# [batch_size, tag_size]
outputs = self.proj(hiddens)
实验 Experiments
数据集 Data
数据集使用的是Stanford Natural Language Inference (SNLI) corpus,每条数据是三个句子,分别代表premise, hypothesis和tag
训练参数设置 Training
使用Adam优化函数,lr=0.0004,batch_size=32,所有LSTM的隐层状态维度皆为300,dropout也被在各个层中使用且p=0.5,预训练词向量使用的是glove.840B.300d,在SNLI数据集上达到了88%的acc。
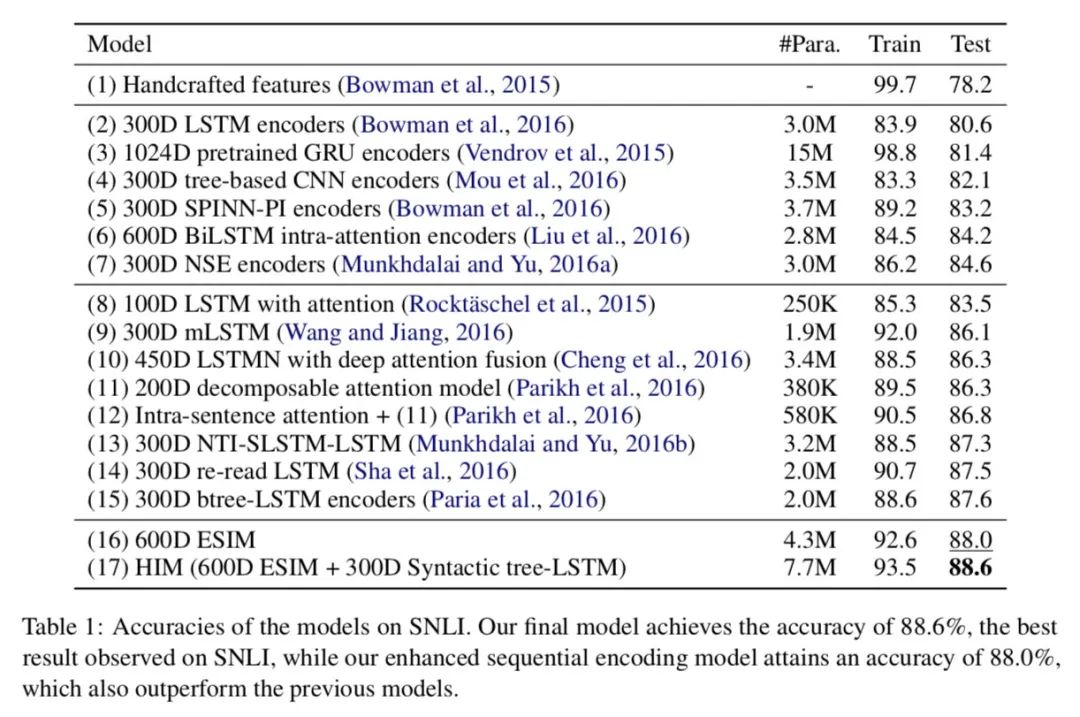
实验结果
HIM是使用Tree-LSTM引入了句法信息的方法,较为复杂不再赘述,有兴趣的同学可以去阅读原文。
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2867
-
PyTorch教程16.5之自然语言推理:使用注意力2023-06-05 825
-
什么是自然语言处理2021-09-08 2775
-
自然语言处理之66参数学习2020-07-16 2258
-
求自然语言处理笔记2020-06-04 2873
-
自然语言处理的词性标注方法2020-04-21 2279
-
自然语言处理的语言模型2020-04-16 2805
-
【推荐体验】腾讯云自然语言处理2019-10-09 2942
-
自然语言处理入门基础之hanlp详解2018-11-29 1045
-
自然语言处理怎么最快入门?2018-11-28 2732
-
python自然语言2018-05-02 6428
-
什么是自然语言处理_自然语言处理常用方法举例说明2017-12-28 18821
全部0条评论

快来发表一下你的评论吧 !
