

那些年在pytorch上踩过的坑
电子说
描述
今天又发现了一个pytorch的小坑,给大家分享一下。手上两份同一模型的代码,一份用tensorflow写的,另一份是我拿pytorch写的,模型架构一模一样,预处理数据的逻辑也一模一样,测试发现模型推理的速度也差不多。一份预处理代码是为pytorch模型写的,用到的库是torch,另一份是为tensorflow写的,用到的是numpy。在训练时,每个epoch耗时居然差距非常大,pytorch的代码在140w条数据上训练每轮耗时约45min,而tensorflow版的代码耗时仅约12min。
我把代码看了又看,百思不得其解,预处理的代码比较复杂,都包含两个for循环,pytorch版代码我把更多的预处理步骤放到了Dataset里,这样训练时加载每个batch后,再要处理的步骤就更少了,速度也应该更快,而tensorflow版代码的for循环里预处理的步骤明明更多,怎么会速度比我的代码还快呢?然而,经过我的测试发现,从加载每个batch的数据进来开始,经过预处理,直到输入到模型做计算前,两者的耗时差了约7~8倍。最后发现问题出在对pytorch的tensor进行了频繁的索引操作。
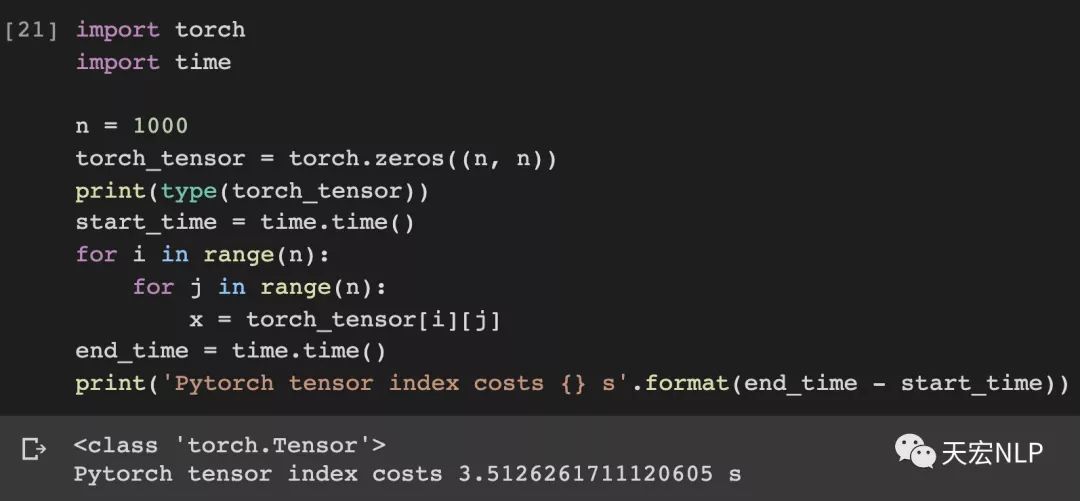
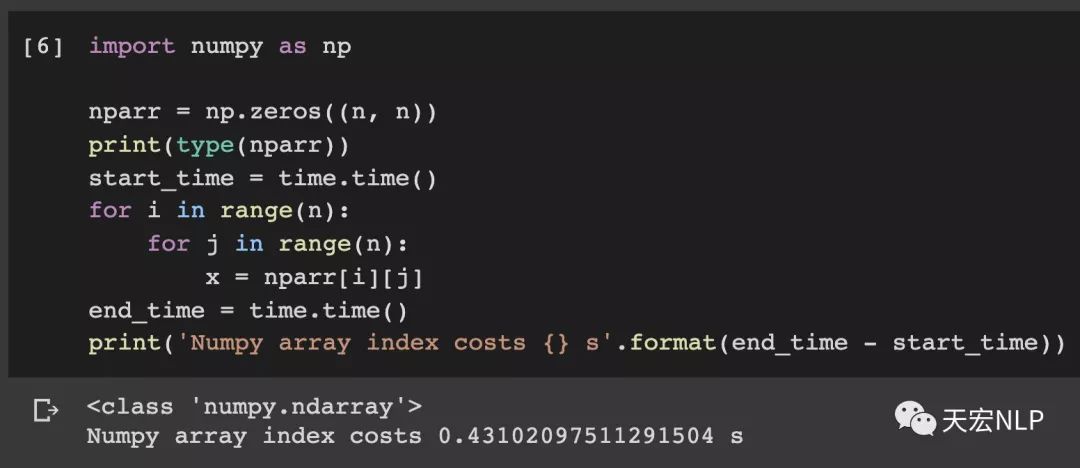
下面做个实验给大家直观体验一下,对tensor做索引和对array做索引的速度差距有多大,tensor和array都是大小(1000x1000)的二维数组。
Pytorch(version==1.4.1)索引1000000次耗时:3.51秒
Numpy索引1000000次耗时:0.43秒
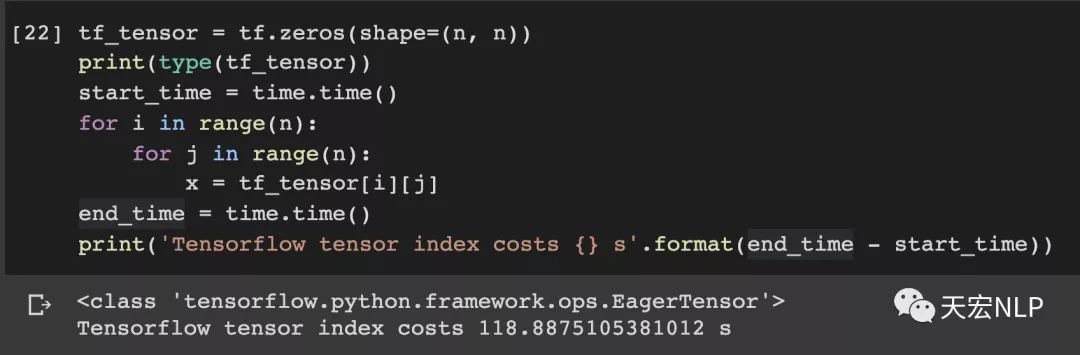
我还特意对比了一下对TensorFlow的tensor做索引的耗时
TensorFlow(version==2.1.0)索引1000000次耗时:118.89秒
由此可见tensor和array的索引速度至少差距在10倍,不过这也在情理之中,毕竟tensor要比array“重”得多。因此在使用pytorch和tensorflow时,频繁需要索引的操作一定要先把tensor转换为numpy.array来做!
除此之外,与其对二维数组进行索引,不如将其展平为一维数组,算上展平的时间,速度还会有不少提升。
Pytorch从3.51秒降到了1.94秒
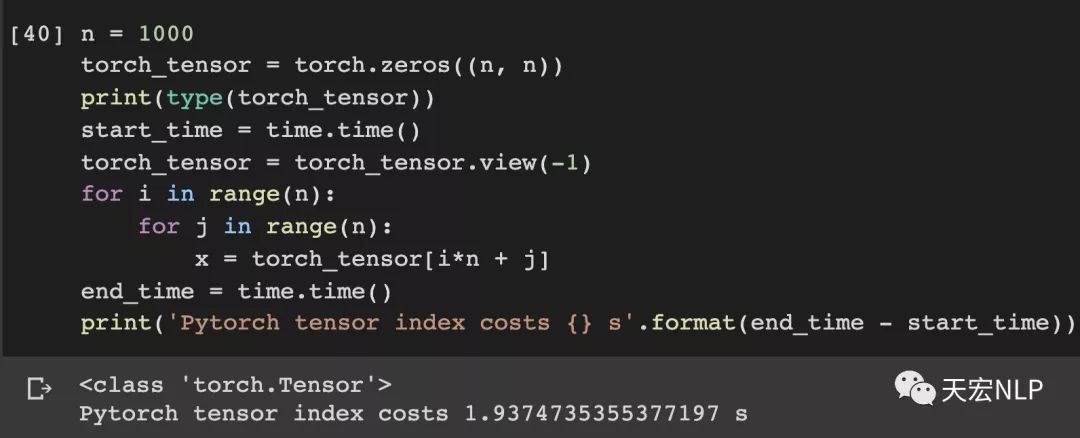
Numpy从0.43秒降到了0.29秒
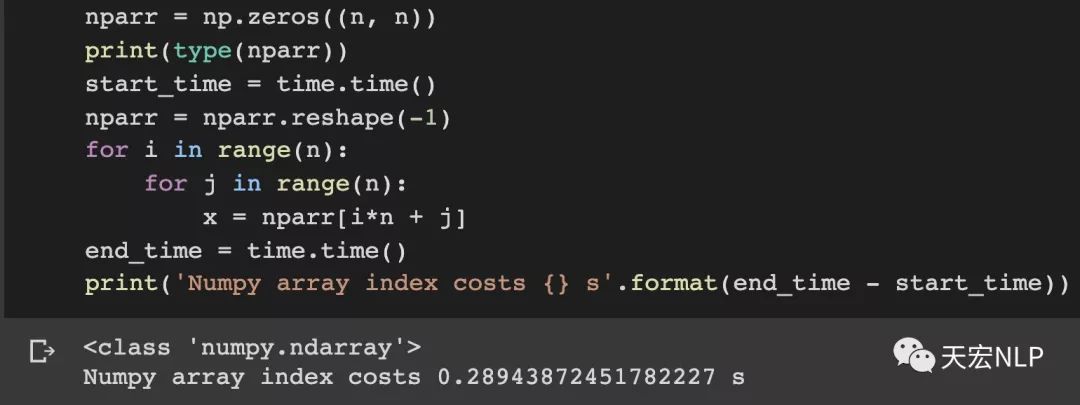
如果在训练和数据预处理过程中发现自己的代码跑起来速度非常慢,记得看一看有没有对tensor做太多次索引,如果有的话,要把它转为numpy.array,还有,尽量把二维、三维的索引变成一维的索引,这些都能加快你训练模型的速度。
PS:最后我的代码终于训练一轮也只需要不到12min了,后来又找了点加速的办法,把训练一轮的时间控制到了9min以内,这些就放在以后再写吧~
- 相关推荐
- 热点推荐
- 代码
- tensorflow
- pytorch
全部0条评论

快来发表一下你的评论吧 !
