

那些年在pytorch上过的当
电子说
描述
起因
最近在修改上一个同事加载和预处理数据的代码,原版的代码使用tf1.4.1写的,数据加载也是完全就是for循环读取+预处理,每读入并预处理好一个batch就返回丢给模型训练,如此往复,我觉得速度实在太慢了,而且我新写的代码都是基于pytorch,虽然预处理的过程很复杂,我还是下决心自己改写。
用pytorch加载预处理数据,最常用的就是torch.utils.data.Dataset和torch.utils.data.DataLoader组合起来,把数据预处理都在Dataset里写好,再在DataLoader里设定batch_size, shuffle等参数去加载数据,网上的教程非常多,这里我就不展开讲了。
过程
现在我已经获得了train_loader和test_loader,可以从它们里面每次读取一个batch出来训练,可照理说加载Dataset时占用了大量内存是正常的,因为数据都预加载好了,就只需要用DataLoader读取就行了,但在训练的过程中,内存不应该随着训练而逐渐增加。我眼睁睁看着内存占用从8、9个g,逐渐涨到了25个g,程序最终因为占满内存而崩溃。检查了半天自己的代码都没找出问题所在,后来用memory_profiler查看内存占用情况,发现问题主要出现在这一行代码:actual_labels += list(correctness),correctness的类型是torch.FloatTensor,actual_labels是python原生的list。
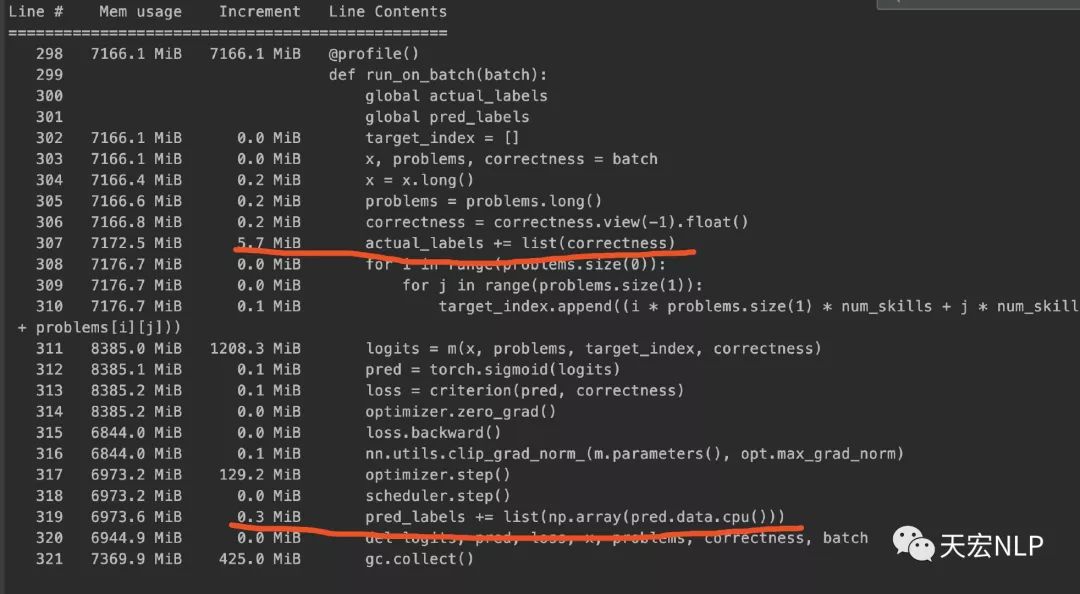
pred和correctness是同类型同长度的tensor,在将其转换为list再添加到已有的list中时,占用的内存相差了约5个Mb,于是我将上面代码改写为:

问题解决了!
为什么下面的代码就没事,上面直接将Tensor转为list就会发生这种奇怪的现象?我去github和知乎看到了遇到类似问题的issue与文章,下面是链接
- https://github.com/pytorch/pytorch/issues/13246
- https://zhuanlan.zhihu.com/p/86286137
- https://github.com/pytorch/pytorch/issues/17499
结论
目前得到的结论大概是python list的design有问题,导致了这种情况发生,pytorch团队虽然竭力修复,但他们表示因为这是python设计的缺陷,超出了他们的能力范围,上面第一个issue主要是针对DataLoader里num_workers>0时会导致内存泄漏,里面也提到了list与tensor互转亦会发生内存泄漏,这个issue已经一年多了还没能close。
因此,在使用pytorch时,应该尽力避免list的使用,一定不能让tensor和list直接互相转换,如果一定要做,应该将tensor从cuda转到cpu上,转为numpy.array,最后转为list,反之亦然。
-
PyTorch 中RuntimeError分析2026-03-06 1218
-
Pytorch 与 Visionfive2 兼容吗?2026-02-06 1102
-
pytorch怎么在pycharm中运行2024-08-01 3856
-
PCB板上过孔太多如何解决2024-07-16 12377
-
tensorflow和pytorch哪个更简单?2024-07-05 2379
-
如何往星光2板子里装pytorch?2023-09-12 675
-
那些年在pytorch上踩过的坑2023-02-22 1958
-
如何安装TensorFlow2 Pytorch?2022-03-07 1353
-
Pytorch AI语音助手2022-03-06 32175
-
PyTorch1.8和Tensorflow2.5该如何选择?2021-07-09 2481
-
基于PyTorch的深度学习入门教程之PyTorch简单知识2021-02-16 3155
-
PyTorch10的基础教程2020-06-05 1755
-
PyTorch如何入门2020-06-01 1991
-
Pytorch入门之的基本操作2020-05-22 2794
全部0条评论

快来发表一下你的评论吧 !
