

简述深度学习中的Attention机制
电子说
描述
Attention机制在深度学习中得到了广泛的应用,本文通过公式及图片详细讲解attention机制的计算过程及意义,首先从最早引入attention到机器翻译任务(Bahdanau et al. ICLR2014)的方法讲起。
Encoder-Decoder
大多数注意力模型都是在Encoder-Decoder框架下发挥作用,Encoder-Decoder模型一般可以用来做机器翻译、文本摘要生成、问答系统、聊天机器人等。Encoder的输入是Source,Decoder要输出的是Target,一般通过RNN来编码输入的句子,得到一个包含的句子语义信息的Vector。假设句子由个单词组成,即。那么RNN或Transformer等模型就作为编码句子的Encoder,首先句子经过Embedding层,从one-hot形式变为词向量,假设它提取句子的语义信息的函数为,则:
对于Decoder来说,它的目标是根据Encoder编码好的句子信息解码出我们想要的结果,这结果可以是对原输入句子的回答,翻译,或摘要等。假设Decoder的输出为,和的大小关系并不确定,一般来说Decoder输出
假设t=i时,我们要输出,其实我们输出的是一个概率分布,然后再选取概率最大的那个单词当作输出( 贪心 search ),还有另一种方式叫 beam search ,这个不是本文重点就在此不多说了。根据Bahdanau et al. ICLR2014第一次提出的将Attention运用于机器翻译任务的论文中,的计算公式如下:
其中是RNN在timestep的hidden state,由如下公式计算:
由于直接输出的实际是一个长度为vocabulary size 的vector,因此最终根据生成的单词其实应该变成一个one-hot vector:
在这里简单地将Decoder整个生成yi的函数用表示:
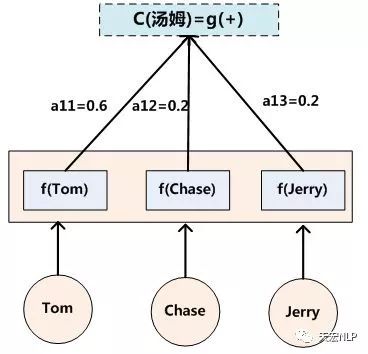
这样就是一个Encoder-Decoder框架运作的基本方式,更直观的可以参见下图。
Soft Attention
最常见也应用最广泛的Attention就是Soft Attention,上面的Encoder-Decoder框架,在Decoder生成每一个yi时,对原输入整个句子语义信息C都给予了同等的注意力,即原句中不同的单词对于生成每一个yi的贡献是相同的。这明显是有问题的,比如在中英翻译:“我今天吃了一个苹果”,“I ate an apple today”,在翻译apple这个词时,原句中的“苹果”对其生成apple要比其他词都重要,因此,需要一个给单纯的Encoder-Decoder模型融入更多的知识,那就是Attention。
Attention的有效性和作用是很intuitive的,比如人在读文章、观察物体时也是会有注意力的参与的,不可能读一页书读到第一行,还能同时注意第二十行的句子,注意力肯定是分配在某个局部的句子上的。因此,给Encoder-Decoder添加Attention,就是要让Decoder在生成时,给输入句子的单词分配不同的注意力权重,权重代表着单词对生成的重要性。
假设Encoder是RNN,输入每个单词后都会输出一个隐状态,那么对生成时,原先对生成每个yi都是相同的句子语义表示会被替换成根据当前要生成的单词yi而不断变化的。理解Attention模型的关键就是这里,即把固定的句子语义表示变成了根据当前要输出的单词yi来进行调整的、融入注意力知识的、不断变化的。
因此上面生成yi的式子变化成如下形式:
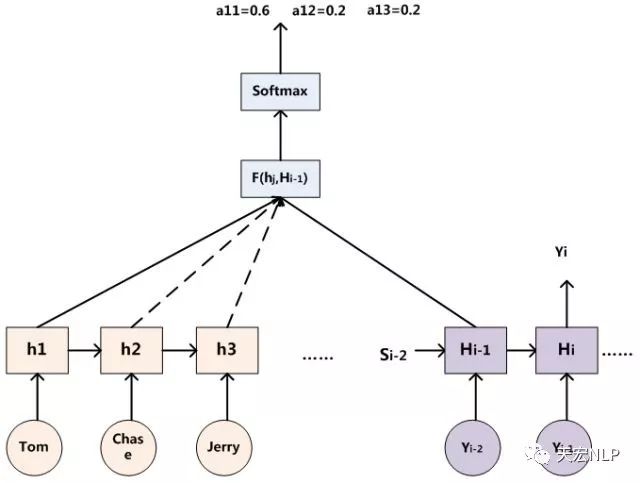
其中,t代表输入句子Source的长度,代表在Decoder输出第i个单词时给Source中第j个单词的注意力分配系数,而hj则是Encoder输入第j个单词时输出的隐状态(语义编码)。根据NMT论文原文, is an alignment model which scores how well the inputs around position j and the output at position i match. The score is based on the RNN hidden state (just before emitting yi) and the j-th annotation hj of the input sentence. 至于函数的选取下面会说明。下图是一个可视化的效果,帮助理解。
计算Attention
我们已经知道了attention是什么,有什么作用,下面具体说明到底怎么计算attention。
假设Encoder输入后输出的隐状态为,Decoder在输出前隐层节点状态为,那么可以用这个时刻的隐层节点状态去一一和输入句子中每个单词对应的RNN隐状态进行对比,即通过函数来获得目标单词yi和每个输入单词对齐的可能性。函数在不同论文里可能会采取不同的方法,然后的所有输出经过Softmax进行归一化就得到了注意力分配到每个输入单词上的权重。下图展示了这个计算过程:
上面说到不同的论文函数会采取不同的方法,其中较为普遍的类型有两种,一个是加法Attention,另一个是乘法Attention。
加法Attention
和为可训练的参数,将计算结果变成一个scalar,h与s之间的分号表示将二者concatenate到一起,产生一个更长的vector,然后和做矩阵乘法。最后再把得到的value一起送往softmax层,进而产生一个符合概率分布的attention。
乘法Attention
将加法和乘法排列组合变换,就能得到另一种方式——多重感知机(multi-layer perceptron)
在代码实现中,运用矩阵运算,可以大大加速计算,这里的不再是单个vector,而是组成的一个矩阵,与一同计算后,得到了一个长度为的vector ,它代表着在生成时,对分配的注意力权重。
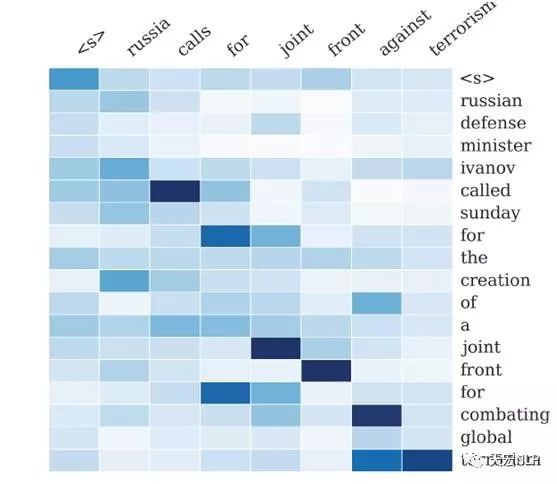
下图展示了在文本生成式摘要时,注意力的分配
Attention机制的本质思想
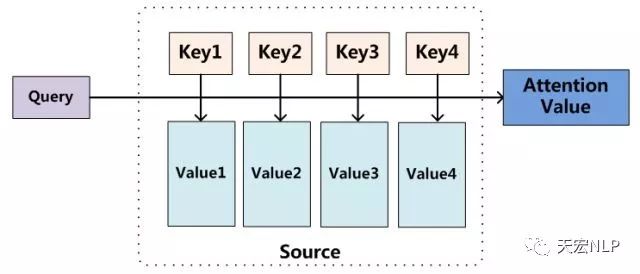
我们可以这样来看待Attention机制:将Source中的构成元素想象成是由一系列的数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,可以得到每个Key针对该Query,Value的分配到的权重系数,然后对所有Key的Value进行加权求和,便得到了最终的Attention值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
上式,代表Source的长度。上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value其实是同一个东西,即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
也可以将Attention机制看作一种软寻址(Soft Addressing):Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention值。通过Query和存储器内元素Key的地址进行相似性比较来寻址。之所以说是软寻址,是因为不像一般寻址只从存储内容里面找出一条内容,而是从每个Key地址都可能会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以得到最终的Value值,也即Attention值。
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为下图展示的三个阶段。
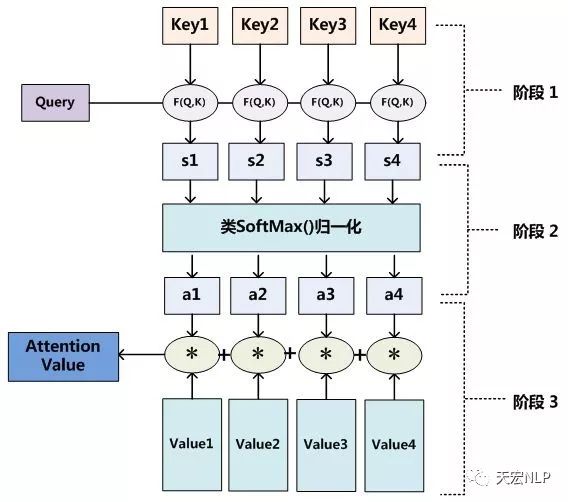
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个Keyi,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,计算公式分别如下:
接着将得到的数值进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。一般采用如下公式计算:
最后得到Query关于Source的加权后的Value值:
延伸阅读
Attention的变体有非常非常多,针对不同任务,不同的Attention机制也有不同的效果,下面最近较火的两种Attention,相信读完上面的内容,理解下面的Attention不再是难题,后续我也会再写一篇详细讲解self-attention计算过程的文章。
- Self-Attention
- Hierarchical-Attention
参考链接及图片来源:
- https://zhuanlan.zhihu.com/p/37601161
- https://www.jianshu.com/p/c94909b835d6
-
简述半导体原理——晶体管家族的核心工作机制2024-07-20 3545
-
深度学习与数据挖掘的关系2018-07-04 2974
-
深度学习在汽车中的应用2019-03-13 4067
-
深度学习中的图片如何增强2020-05-28 1372
-
深度学习中的IoU概念2020-05-29 2127
-
深度学习在预测和健康管理中的应用2021-07-12 1985
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2179
-
Attention的具体原理详解2017-11-23 8511
-
深度学习模型介绍,Attention机制和其它改进2018-03-22 19546
-
为什么要有attention机制,Attention原理2019-03-06 17654
-
首个基于深度学习的端到端在线手写数学公式识别模型2019-09-20 10728
-
简述位置编码在注意机制中的作用2021-06-16 3582
-
深度解析Asp.Net2.0中的Callback机制2021-09-27 951
-
计算机视觉中的注意力机制2023-05-22 760
-
NPU在深度学习中的应用2024-11-14 3700
全部0条评论

快来发表一下你的评论吧 !
