

Ftrace使用tracefs文件系统保存控制文件
描述
简介
Ftrace是Linux Kernel的官方tracing系统,支持Function trace、静态tracepoint、动态Tracepoint的跟踪,还提供各种Tracer,用于统计最大irq延迟、最大函数调用栈大小、调度事件等。
Ftrace还提供了强大的过滤、快照snapshot、实例(instance)等功能,可以灵活配置。
内核配置Ftrace后,如果功能不打开,对性能几乎没有影响。打开事件记录后,由于是在percpu buffer中记录log,各CPU无需同步,引入的负载不大,非常适合在性能敏感的场景中使用。
相比kernle的log_buf和dynamic_debug机制,Ftrace的buffer大小可以灵活配置,可以生成快照,也有一定的优势。
ftrace 框架
整个ftrace框架可以分为几部分:ftrace核心框架,RingBuffer,debugfs,Tracepoint,各种Tracer。
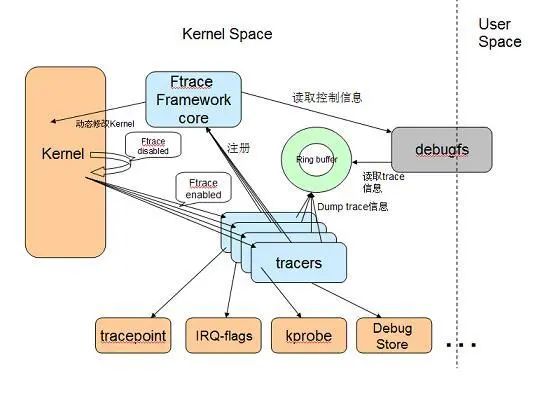
ftrace框架是整个ftrace功能的纽带,包括对内核的修改,Tracer的注册,RingBuffer的控制等等。
RingBuffer是静态动态ftrace的载体。
debugfs则提供了用户空间对ftrace设置接口。
Tracepoint是静态trace,他需要提前编译进内核;可以定制打印内容,自由添加;并且内核对主要subsystem提供了Tracepoint。
Tracer有很多种,主要几大类:
函数类:function, function_graph, stack
延时类:irqsoff, preemptoff, preemptirqsoff, wakeup, wakeup_rt, waktup_dl
其他类:nop, mmiotrace, blk
Trace文件系统
配置内核支持ftrace需要开启以下宏定义。
CONFIG_FTRACE=y CONFIG_STACK_TRACER=y CONFIG_FUNCTION_TRACER=y CONFIG_FUNCTION_GRAPH_TRACER=y CONFIG_HAVE_DYNAMIC_FTRACE=y CONFIG_HAVE_FUNCTION_TRACER=y CONFIG_IRQSOFF_TRACER=y CONFIG_SCHED_TRACER=y CONFIG_FTRACE_SYSCALLS=y CONFIG_PREEMPTIRQ_EVENTS=y CONFIG_TRACER_SNAPSHOT=y
Ftrace使用tracefs文件系统去保存控制文件和显示输出的文件。
当tracefs被配置进内核时,目录/sys/kernel/tracing将会被创建。为了挂载这个目录,你可以在/etc/fstab文件中添加以下信息:
tracefs /sys/kernel/tracing tracefs defaults 0 0
或者在运行时挂在:
mount -t tracefs nodev /sys/kernel/tracing
为了快速访问这个目录可以创建一个软链接::
ln -s /sys/kernel/tracing /tracing
注意:
在4.1版本之前,所有的ftrace跟踪控制文件都在debugfs文件系统中,该文件系统通常位于/sys/kernel/debug/tracing。
为了向后兼容,当挂载debugfs文件系统时,tracefs文件系统将自动挂载在/sys/kernel/debug/tracing。位于tracefs文件系统中的所有文件也将位于debugfs文件系统目录中。
任何选定的ftrace选项也将创建tracefs文件系统。文档中的操作都在ftrace的目录中(/sys/kernel/tracing或者/sys/kernel/debug/tracing)。
在mount tracefs后,即可访问ftrace的控制和输出文件。以下是一些关键文件的列表:
root@firefly:/sys/kernel/debug/tracing# ls README kprobe_profile set_graph_function available_events max_graph_depth set_graph_notrace available_filter_functions options snapshot available_tracers per_cpu trace buffer_size_kb printk_formats trace_clock buffer_total_size_kb saved_cmdlines trace_marker current_tracer saved_cmdlines_size trace_options dyn_ftrace_total_info saved_tgids trace_pipe enabled_functions set_event tracing_cpumask events set_event_pid tracing_max_latency free_buffer set_ftrace_filter tracing_on instances set_ftrace_notrace tracing_thresh kprobe_events set_ftrace_pid
available_events
用于设置或显示当前使用的跟踪器;使用 echo 将跟踪器名字写入该文件可以切换到不同的跟踪器。系统启动后,其缺省值为 nop ,即不做任何跟踪操作。在执行完一段跟踪任务后,可以通过向该文件写入 nop 来重置跟踪器。
available_filter_functions
记录了当前可以跟踪的内核函数。对于不在该文件中列出的函数,无法跟踪其活动。
available_tracers
记录了当前编译进内核的跟踪器的列表,可以通过 cat 查看其内容;写 current_tracer 文件时用到的跟踪器名字必须在该文件列出的跟踪器名字列表中。
buffer_size_kb
用于设置单个 CPU 所使用的跟踪缓存的大小。跟踪器会将跟踪到的信息写入缓存,每个 CPU 的跟踪缓存是一样大的。跟踪缓存实现为环形缓冲区的形式,如果跟踪到的信息太多,则旧的信息会被新的跟踪信息覆盖掉。注意,要更改该文件的值需要先将 current_tracer 设置为 nop 才可以。
buffer_total_size_kb
显示所有的跟踪缓存大小,不同之处在于buffer_size_kb是单个CPU的,buffer_total_size_kb是所有CPU的和。
trace_pipe
输出和trace一样的内容,输出实时tracing日志,这样就避免了RingBuffer的溢出。cat trace_pipe > trace.txt &保存文件,但是cat时候会带来一些性能损耗。
trace_options
控制Trace打印内容格式或者设置跟踪器,可以通过trace_options添加很多附加信息。
current_tracer
设置和显示当前正在使用的跟踪器。使用echo命令可以把跟踪器的名字写入current_tracer文件,从而切换不同的跟踪器。
dyn_ftrace_total_info
debug使用,显示available_filter_functins中跟中函数的数目,两者一致。
enabled_functions
显示有回调附着的函数名称。这个文件更多的是用于调试ftrace,但也可以用于查看是否有任何函数附加了回调。不仅ftrace框架使用ftrace函数tracing,其他子系统也可能使用。该文件显示所有附加回调的函数,以及附加回调的数量。注意,一个回调也可以调用多个函数,这些函数不会在这个计数中列出。
如果回调被一个带有"save regs"属性的函数注册tracing(这样开销更大),一个’R’将显示在与返回寄存器的函数的同一行上。
如果回调被一个带有"ip modify"属性的函数注册tracing(这样regs->ip就可以被修改),'I’将显示在可以被覆盖的函数的同一行上。
如果体系架构支持,它还将显示函数直接调用的回调。如果计数大于1,则很可能是ftrace_ops_list_func()。
如果函数的回调跳转到特定于回调而不是标准的"跳转点"的跳转点,它的地址将和跳转点调用的函数一起打印。
events
系统Trace events目录,在每个events下面都有enable、filter和fotmat。enable是开关;format是events的格式,然后根据格式设置 filter。
free_buffer
在关闭该文件时,ring buffer将被调整为其最小大小。如果有一个tracing的进程也打开了这个文件,当该进程退出,该文件的描述符将被关闭,在此过程,ring bufer也将被"freed"。
如果options/disable_on_free选项被设置将会停止tracing。
kprobe_events
激活 dynamic trace opoints。参考内核文档Documentation/trace/kprobetrace.rst。
kprobe_profile
Dynamic trace points 统计信息。 参考内核文档Documentation/trace/kprobetrace.rst。
max_graph_depth
被用于function_graph tracer。这是tracing一个函数的最大深度。将其设置为1将只显示从用户空间调用的第一个内核函数。
options
目录文件,里面是每个trace options的文件,和trace_options对应,可以通过echo 0/1使能options。
per_cpu:包含跟踪 per_cpu 信息的目录。
per_cpu/cpu0/buffer_size_kb:配置per_cpu的buffer空间
per_cpu/cpu0/trace:当前CPU的trace文件。
per_cpu/cpu0/trace_pipe:当前CPU的trace_pipe文件。
per_cpu/cpu0/trace_pipe_raw:当前CPU的trace_pipe_raw
per_cpu/cpu0/snapshot:当前CPU的snapshot
per_cpu/cpu0/snapshot_raw:当前CPU的snapshot_raw
per_cpu/cpu0/stats:当前CPU的trace统计信息
printk_formats
提供给工具读取原始格式trace的文件。如果环形缓冲区中的事件引用了一个字符串,则只有指向该字符串的指针被记录到缓冲区中,而不是字符串本身。这可以防止工具知道该字符串是什么。该文件显示字符串和字符串的地址,允许工具将指针映射到字符串的内容。
saved_cmdlines
ftrace会存放pid的comms在一个pid mappings,在显示event时候同时显示comm,这里可以配置pid对应的comm,如果配置,显示类似
saved_cmdlines_size
saved_cmdlines的数目,默认为128
saved_tgids
如果设置了选项“record-tgid”,则在每个调度上下文切换时,任务的任务组 ID 将保存在将线程的 PID 映射到其 TGID 的表中。默认情况下,“record-tgid”选项被禁用。
set_event
也可以在系统特定事件触发的时候打开跟踪。为了启用某个事件,你需要:echo sys_enter_nice >> set_event(注意你是将事件的名字追加到文件中去,使用>>追加定向器,不是>)。要禁用某个事件,需要在名字前加上一个“!”号:echo '!sys_enter_nice' >> set_event。以下三种方式都可以启用事件
echo sched:sched_switch >> /debug/tracing/set_event echo sched_switch >> /debug/tracing/set_event echo 1 > /debug/tracing/events/sched/sched_switch/enable
set_event_pid
tracer将只追踪写入此文件PID的对应进程的event。"event-fork" option设置后,pid对应进程创建的子进程event也会自动跟踪。
set_ftrace_filter 和 set_ftrace_notrace
在编译内核时配置了动态 ftrace (选中 CONFIG_DYNAMIC_FTRACE 选项)后使用。前者用于显示指定要跟踪的函数,后者则作用相反,用于指定不跟踪的函数。
如果一个函数名同时出现在这两个文件中,则这个函数的执行状况不会被跟踪。这些文件还支持简单形式的含有通配符的表达式,这样可以用一个表达式一次指定多个目标函数;注意,要写入这两个文件的函数名必须可以在文件 available_filter_functions 中看到。
缺省为可以跟踪所有内核函数,文件 set_ftrace_notrace 的值则为空。甚至可以对函数的名字使用通配符。例如,要用所有的vmalloc_函数,通过echo vmalloc_* > set_ftrace_filter进行设置。
set_ftrace_pid
tracer将只追踪写入此文件PID的对应的进程。"function-fork" option设置后,pid对应进程创建的子进程也会自动跟踪。
set_graph_function
设置要清晰显示调用关系的函数,显示的信息结构类似于 C 语言代码,这样在分析内核运作流程时会更加直观一些。在使用 function_graph 跟踪器时使用;缺省为对所有函数都生成调用关系序列,可以通过写该文件来指定需要特别关注的函数。
echo function_graph > current_tracer echo __do_fault > set_graph_function //跟踪__do_fault
snapshot
是对trace的snapshot。
echo 0清空缓存,并释放对应内存。
echo 1进行对当前trace进行snapshot,如没有内存则分配。
echo 2清空缓存,不释放也不分配内存。
trace
文件提供了查看获取到的跟踪信息的接口。可以通过 cat 等命令查看该文件以查看跟踪到的内核活动记录,也可以将其内容保存为记录文件以备后续查看。
trace_clock
每当一个事件被记录到环形缓冲区中时,都会添加一个“时间戳”。此标记来自指定的时钟。默认情况下,ftrace 使用“本地”时钟。本地时钟可能与其他 CPU 上的本地时钟不同步。
local:默认时钟,在每CPU中快速且精准,但是可能不会在各个CPU之间同步;
global:各CPU间同步,但是比local慢;
counter:并不是时钟,而是一个原子计数器。数值一直+1,但是所有cpu是同步的。主要用处是分析不同cpu发生的events
uptime:time stamp和jiffies counter根据boot time;
perf:clock跟perf使用一致。
x86-tsc:非系统自己时钟。比如x86有TSC cycle clock;
ppc-tb:使用powerpc的基础时钟寄存器值;
mono:使用fast monotonic clock (CLOCK_MONOTONIC)
mono_raw:使用raw monotonic clock (CLOCK_MONOTONIC_RAW)
boot:使用boot clock (CLOCK_BOOTTIME)。
trace_marker
用于将用户空间与内核空间中发生的事件同步。将字符串写入该文件将被写入ftrace缓冲区。
在应用程序中,应用程序开始打开这个文件并引用文件描述符::
void trace_write(const char *fmt, ...)
{
va_list ap;
char buf[256];
int n;
if (trace_fd < 0)
return;
va_start(ap, fmt);
n = vsnprintf(buf, 256, fmt, ap);
va_end(ap);
write(trace_fd, buf, n);
}
开始:
trace_fd = open("trace_marker", WR_ONLY);
注意:写入trace_marker文件也可以触发写入/sys/kernel/tracing/events/ftrace/print/trigger的触发器。详细看内核文档Documentation/trace/histogram.rst (Section 3.)。
trace_options
此文件允许用户控制在上述输出文件之一中显示的数据量。还存在用于修改跟踪器或事件的工作方式(堆栈跟踪、时间戳等)的选项。
trace_pipe:"trace_pipe"输出与"trace"文件相同的内容,但是对跟踪的影响不同。每次从"trace_pipe"读取都会被消耗。这意味着后续的读取将有所不同。跟踪是动态的:
# echo function > current_tracer # cat trace_pipe > /tmp/trace.out & [1] 4153 # echo 1 > tracing_on # usleep 1 # echo 0 > tracing_on # cat trace # tracer: function # # entries-in-buffer/entries-written: 0/0 #P:4 # # _-----=> irqs-off # / _----=> need-resched # | / _---=> hardirq/softirq # || / _--=> preempt-depth # ||| / delay # TASK-PID CPU# |||| TIMESTAMP FUNCTION # | | | |||| | | # # cat /tmp/trace.out bash-1994 [000] .... 5281.568961: mutex_unlock <-rb_simple_write bash-1994 [000] .... 5281.568963: __mutex_unlock_slowpath <-mutex_unlock bash-1994 [000] .... 5281.568963: __fsnotify_parent <-fsnotify_modify bash-1994 [000] .... 5281.568964: fsnotify <-fsnotify_modify bash-1994 [000] .... 5281.568964: __srcu_read_lock <-fsnotify bash-1994 [000] .... 5281.568964: add_preempt_count <-__srcu_read_lock bash-1994 [000] ...1 5281.568965: sub_preempt_count <-__srcu_read_lock bash-1994 [000] .... 5281.568965: __srcu_read_unlock <-fsnotify bash-1994 [000] .... 5281.568967: sys_dup2 <-system_call_fastpath
注意,读取"trace_pipe"文件将会阻塞,直到添加更多输入。这与"trace"文件相反。如果任何进程打开"trace"文件进行读取,它实际上将禁用tracing并阻止添加新条目。"trace_pipe"文件没有这个限制。
tracing_cpumask
可以通过此文件设置跟踪指定CPU,二进制格式。
tracing_max_latency
记录某些Tracer的最大延时。比如interrupts的最大延时关闭后,会记录在这里。可以echo值到此文件,然后遇到比设置值更大的延迟才会更新。
tracing_on
用于控制跟踪的暂停。有时候在观察到某些事件时想暂时关闭跟踪,可以将 0 写入该文件以停止跟踪,这样跟踪缓冲区中比较新的部分是与所关注的事件相关的;写入 1 可以继续跟踪。
tracing_thresh
延时记录Trace的阈值,当延时超过此值时才开始记录Trace。单位是ms,只有非0才起作用。
跟踪器使用方法
blk跟踪器
blktrace应用程序使用的跟踪程序。
blk tracer比较特别,需要设置/sys/block/xxx/trace/enable 才工作,可参考https://lwn.net/Articles/315508/
echo 1 > /sys/block/mmcblk0/trace/enable echo blk > /sys/kernel/debug/tracing/current_tracer echo 1 > /sys/kernel/debug/tracing/tracing_on cat /sys/kernel/debug/tracing/trace # tracer: blk # jbd2/mmcblk0p9--1100 [001] ...1 679.901410: 179,0 A WS 323710 + 8 <- (179,9) 265048 jbd2/mmcblk0p9--1100 [001] ...1 679.901428: 179,0 Q WS 323710 + 8 [jbd2/mmcblk0p9-] jbd2/mmcblk0p9--1100 [001] ...1 679.901469: 179,0 G WS 323710 + 8 [jbd2/mmcblk0p9-] jbd2/mmcblk0p9--1100 [001] ...1 679.901474: 179,0 P N [jbd2/mmcblk0p9-] jbd2/mmcblk0p9--1100 [001] ...1 679.901491: 179,0 A WS 323718 + 8 <- (179,9) 265056 mmcqd/0-998 [000] ...1 679.901627: 179,0 m N cfq1100SN dispatch_insert mmcqd/0-998 [000] ...1 679.901635: 179,0 m N cfq1100SN dispatched a request mmcqd/0-998 [000] ...1 679.901641: 179,0 m N cfq1100SN activate rq, drv=1 mmcqd/0-998 [000] ...2 679.901645: 179,0 D WS 323710 + 16 [mmcqd/0] mmcqd/0-998 [000] ...1 679.902979: 179,0 C WS 323710 + 16 [0]
function跟踪器
追踪所有的内核函数
查看可追踪的内核函数
root@firefly:~# cd /sys/kernel/debug/tracing/ root@firefly:/sys/kernel/debug/tracing# cat available_filter_functions
显示和配置当前的tracer
cat available_tracers blk function_graph wakeup_dl wakeup_rt wakeup irqsoff function nop cat current_tracer nop echo function > current_tracer echo do_sys_open > set_ftrace_filter echo 1 > tracing_on echo 0 > tracing_on cat trace echo nop > current_tracer echo > set_ftrace_filter
输出
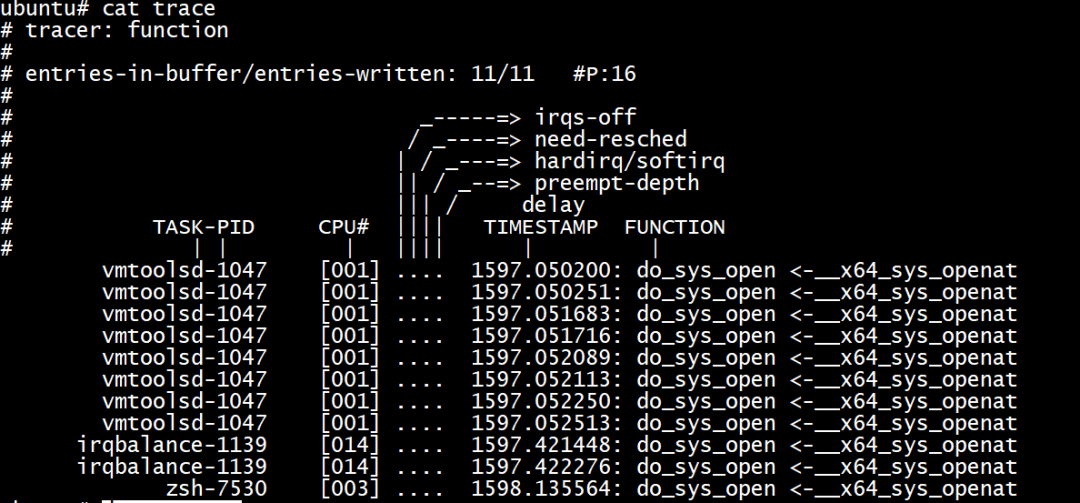
11/11
跟踪条目11个
#P16
表示当前系统可用的CPU有16个
TASK-PID
进程名字-PID
CPU#
进程运行在那个CPU上
irqs-off
中断开关状态
need-resched
可以设置为以下值
N:表示进程设置了TIF_NEED_RESCHED和PREEMPT_NEED_RESCHED标志位,说明需要被调度。
n:表示进程仅设置了TIF_NEED_RESCHED标志
p:表示进程仅设置了PREEMPT_NEED_RESCHED标志
.:表示不需要调度
hardirq/softirq
可以设置为以下值
H:表示在一次软中断中发生了硬件中断
h:表示硬件中断的发生
s:表示软件中断的发生
.:表示没有中断发生
preempt-depth
表示抢占关闭的嵌套层级
delay
用特殊符号表示延时时间
$:大于1s
@:大于100ms
*:大于10ms
#:大于1000us
!:大于100us
+:大于10us
TIMESTATION
时间戳。如果打开了latency-format选项,表示相对时间,即从开始跟踪算起。否则,使用绝对时间。
FUNCTION
表示函数名称
function_graph跟踪器
和“function tracer”比较类似,但它除了探测函数的入口还探测函数的出口。它可以画出一个图形化的函数调用,类似于c源代码风格。
echo function_graph > current_tracer echo do_sys_open > set_graph_function echo 1 > tracing_on echo 0 > tracing_on cat trace echo nop > current_tracer echo > set_graph_function
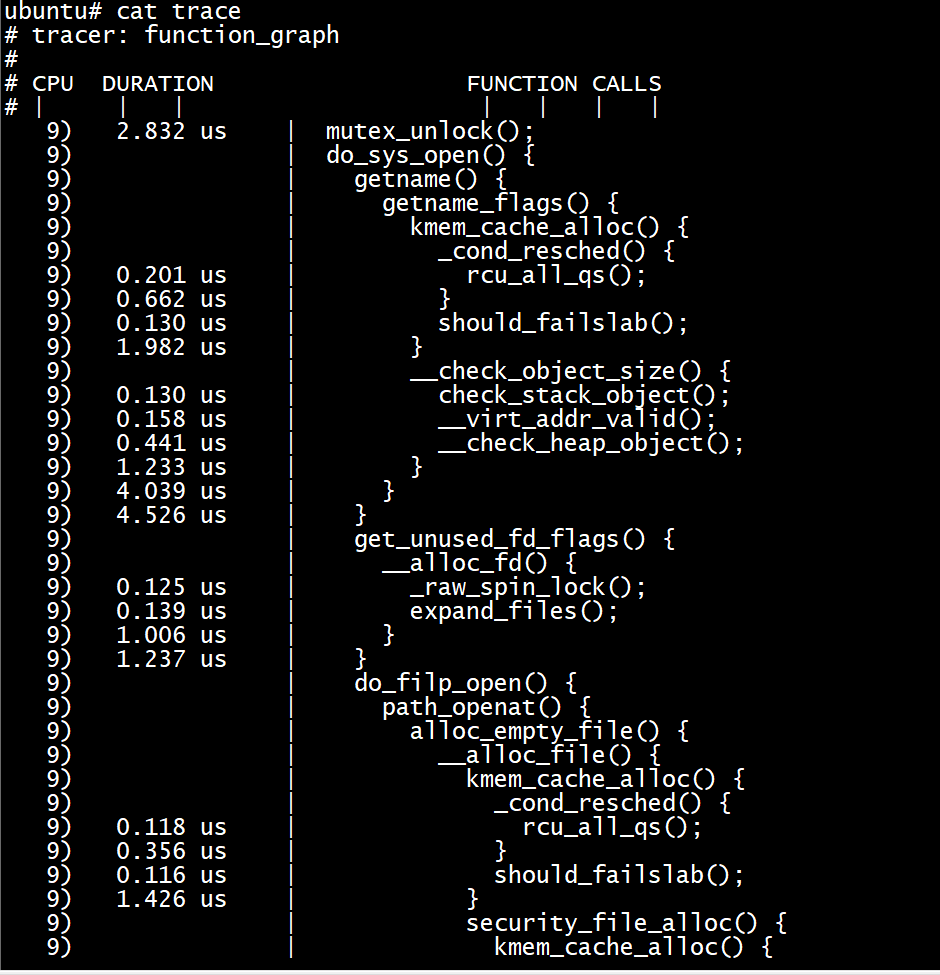
function_graph 和function跟踪器在Linux version 4.4.194的开发板上发现无法生效,给set_graph_function echo 特定函数后,仍会跟踪所有函数。但是在Linux version 5.4.0-135 ubuntu18.04中是生效的。不知道是不是内核版本差异的原因?
irqsoff跟踪器
当关闭中断时,CPU 会延迟对设备的状态变化做出反应,有时候这样做会对系统性能造成比较大的影响。
irqsoff 跟踪器可以对中断被关闭的状况进行跟踪,有助于发现导致较大延迟的代码;
当出现最大延迟时,跟踪器会记录导致延迟的跟踪信息,文件 tracing_max_latency 则记录中断被关闭的最大延时,遇到比设置值更大的延迟才会更新。
echo irqsoff > current_tracer echo 0 > tracing_max_latency echo 1 >tracing_on echo 0 >tracing_on cat trace
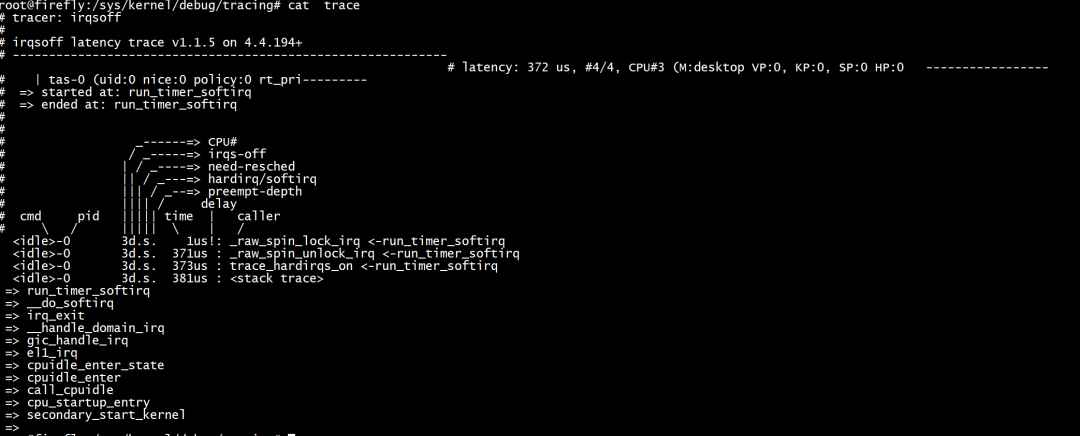
latency表示当前最大的中断延时为372us,跟踪条目总和为4个。
started at 和 ended at 显示发生中断的开始函数和结束函数分别为run_timer_softirq。
latency显示中断延时为372us,但是在stack trace 显示为306us,这是因为在记录最大延迟信息时需要花费一些时间。
其他参数说明可参考function跟踪器。
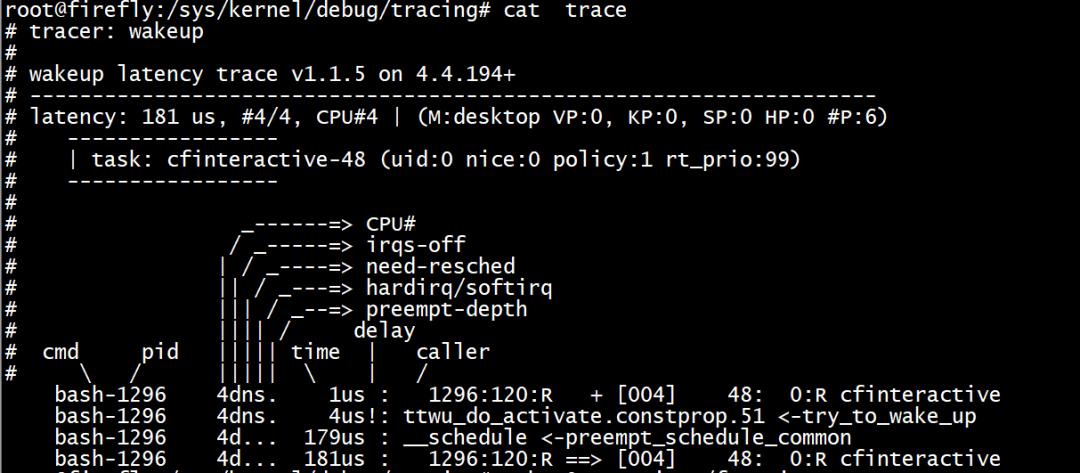
wakeup/wakeup_rt/wakeup_dl跟踪器
wakeup:显示进程从woken到wake up的延时,包括所有进程。
wakeup_dl:显示SCHED_DEADLINE类型调度延时。
wakeup_rt:显示实时进程的调度延时。
echo wakeup > current_tracer echo 0 > tracing_max_latency echo 1 > tracing_on echo 0 > tracing_on cat trace
stack跟踪器
内核栈大小是有限的,为了跟踪内核栈的使用情况,可以使用ftrace stack trace。
使能跟踪一段时间后,可以查看最大栈占用情况,stack_max_size这里打印的是最长栈的size。而在stack_trace 中打印的是最长栈的每个函数占用栈大小的情况,注意这里也只会记录的最长的栈情况。
echo stack > current_tracer echo do_sys_open > stack_trace_filter echo 1 > /proc/sys/kernel/stack_tracer_enabled echo 0 > /proc/sys/kernel/stack_tracer_enabled cat stack_max_size cat stack_trace

488 表示堆栈大小为488字节,其中el0_svc_naked使用了最大的栈空间360。
小结
总结下ftrace 跟踪器的三步法为:1,设置tracer类型;2,设置tracer参数;3,使能tracer
trace event 用法
ftrace中的跟踪机制主要有两种,分别是函数和跟踪点。前者属于简单操作,后者可以理解为Linux内核的占位符函数。
tracepoint可以输出开发者想要的参数、局部变量等信息。
跟踪点的位置比较固定,一般为内核开发者添加,可以理解为C语言中的#if DEBUG部分。如果运行时不开启DEBUG,不占用任何系统开销。
trace event使用方法
set_event接口
/sys/kernel/debug/tracing/available_events定义了当前支持的trace event。
root@firefly:/sys/kernel/debug/tracing# cat available_events raw_syscalls:sys_exit raw_syscalls:sys_enter ipi:ipi_exit ipi:ipi_entry ipi:ipi_raise emulation:instruction_emulation kvm:kvm_halt_poll_ns kvm:kvm_age_page kvm:kvm_fpu kvm:kvm_mmio kvm:kvm_ack_irq kvm:kvm_set_irq kvm:kvm_vcpu_wakeup kvm:kvm_userspace_exit kvm:kvm_toggle_cache .....
启用特定event,如sched_wakeup,echo到 /sys/kernel/debug/tracing/set_event。例如:
echo sched_wakeup >> /sys/kernel/debug/tracing/set_event
注意:需要使用>>,否则会首先disable所有的events。
关闭特定event,在echo event name到set_event之前设置一个!前缀,比如
echo '!sched_wakeup' >> /sys/kernel/debug/tracing/set_event
使能所有event,echo *:* or *:到set_event中:
echo *:* > set_event
关闭所有event,echo一个空行到set_event中
echo > set_event
events 通常以subsystems的形式展现,例如ext4, irq, sched等等。一个完整的event name类似nfs4format。
subsystem name是可选的,但是它会显示在available_events文件中。一个subsystem中所有的events可以通过 :*语法来表示,
例如:enable所有的irq event:
echo 'irq:*' > set_event
enable接口
所有有效的trace event同时会在/sys/kernel/debug/tracing/events/文件夹中列出。
enable event ‘sched_wakeup’:
echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
disable:
echo 0 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable
enable sched subsystem中所有的events:
echo 1 > /sys/kernel/debug/tracing/events/sched/enable
enable所有的events:
echo 1 > /sys/kernel/debug/tracing/events/enable
当读enable文件时,可能会有以下4种结果:
0 - all events this file affects are disabled 1 - all events this file affects are enabled X - there is a mixture of events enabled and disabled ? - this file does not affect any event
为了早期启动时调试,可以使用以下boot选项:
trace_event=[event-list]
event-list是逗号分隔的event列表。
event格式
每个trace event都有一个与它相关联的format文件,该文件包含log event中每个字段的描述。这个信息用来解析二进制的trace流,其中的字段也可以在event filter中找到对它的使用。
它还显示用于在文本模式下打印事件的格式字符串,以及用于分析的事件名称和ID。
每个event都有一系列通用的字段,全部都以common_作为前缀。其他的字段都需要在TRACE_EVENT()中定义。
format中的每个字段都有如下形式:
field:field-type field-name; offset:N; size:N;
offset是字段在trace record中的offset,size是数据项的size,都是byte单位。
举例, sched_wakeup event的format信息:
cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/format name: sched_wakeup ID: 60 format: field:unsigned short common_type; offset:0; size:2; field:unsigned char common_flags; offset:2; size:1; field:unsigned char common_preempt_count; offset:3; size:1; field:int common_pid; offset:4; size:4; field:int common_tgid; offset:8; size:4; field:char comm[TASK_COMM_LEN]; offset:12; size:16; field:pid_t pid; offset:28; size:4; field:int prio; offset:32; size:4; field:int success; offset:36; size:4; field:int cpu; offset:40; size:4; print fmt: "task %s:%d [%d] success=%d [%03d]", REC->comm, REC->pid, REC->prio, REC->success, REC->cpu
这个event包含10个字段,5个通用字段5个自定义字段。除了COMM是一个字符串,此事件的所有字段都是数字,这对于事件过滤非常重要。
event 过滤
trace event支持 filter expressions式的过滤。一旦trace event被记录到trace buffer中,其字段就针对与该event类型相关联的filter expressions进行检查。
如果event匹配filter将会被记录,否则将会被丢弃。如果event没有配置filter,那么在任何时刻都是匹配的,event默认就是no filter配置。
语法
一个filter expression由多个 predicates组成,使用逻辑操作符&&、||组合在一起。
field-name relational-operator value
数字类的操作符包括:
==, !=, <, <=, >, >=, &
字符类的操作符包括:
==, !=, ~
约等于操作符(~)接受通配符形式 (*,?)和字符类 ([)。举例:
prev_comm ~ "*sh" prev_comm ~ "sh*" prev_comm ~ "*sh*" prev_comm ~ "ba*sh"
配置filters
通过将filter expressions写入给定event的filter文件来设置单个event的filter。
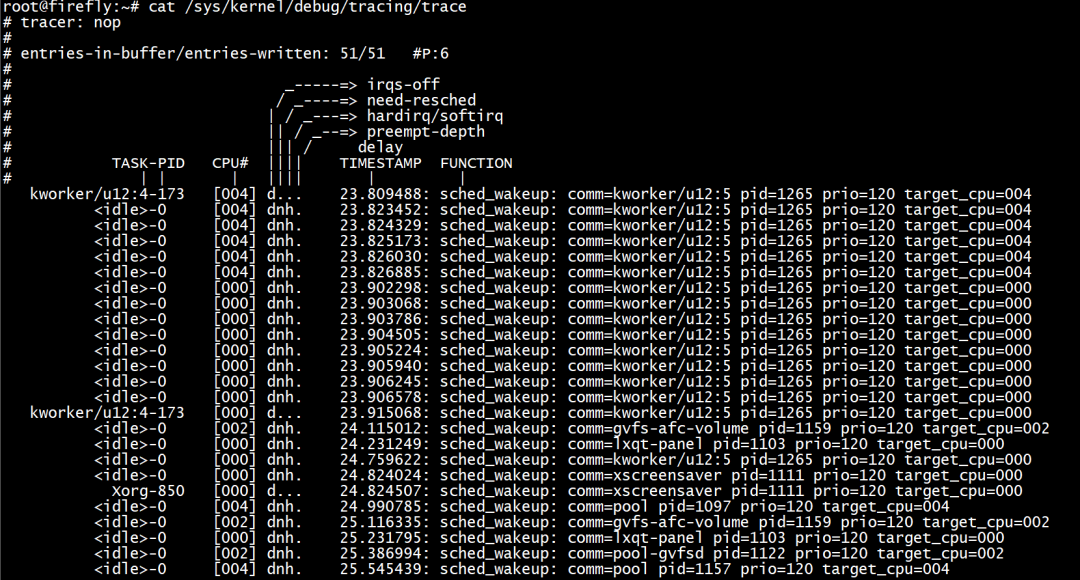
例如
echo 'pid > 1000' > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter # pid大于100的事件 echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable cat /sys/kernel/debug/tracing/trace
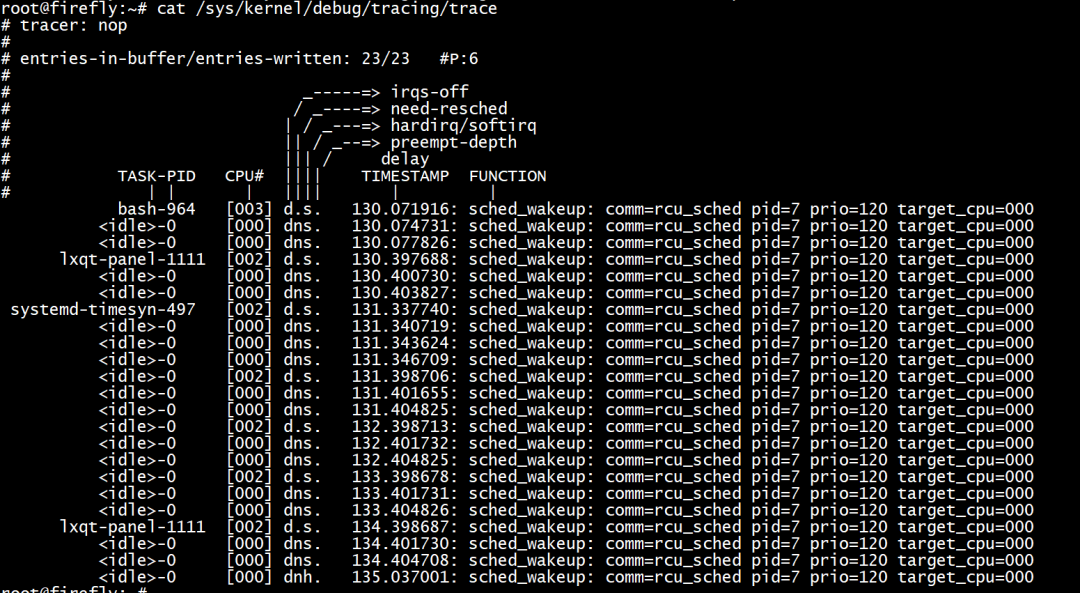
过滤进程名为rcu_sched的事件
echo 'comm == "rcu_sched"' > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter echo 1 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/enable cat /sys/kernel/debug/tracing/trace
如果表达式中存在错误,则在设置时会得到一个Invalid argument错误,错误的字符串连同错误消息可以通过查看过滤器来查看,例如:
cd /sys/kernel/debug/tracing/events/signal/signal_generate echo '((sig >= 10 && sig < 15) || dsig == 17) && comm != "bash"' > filter -bash: echo: write error: Invalid argument cat filter ((sig >= 10 && sig < 15) || dsig == 17) && comm != bash ^ parse_error: Field not found
清除filters
清除某个event的filter,echo 0 到对应event的filter文件。
清除某个subsystem中所有events的filter,echo 0 到对应subsystem的filter文件。
echo 0 > /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter echo 0 > /sys/kernel/debug/tracing/events/sched/filter
子系统filters
为了方便起见,可以将子系统中的每个事件的过滤器作为一个组来设置或清除,将一个过滤器表达式写入子系统根目录下的过滤器文件中。
如果子系统内的任何事件的过滤器缺少子系统过滤器中指定的字段,或者如果过滤器不能应用于任何其他原因,则该事件的过滤器将保留其以前的设置。只有引用公共字段的过滤器才能保证成功地传播到所有事件。
举例:
清除sched subsystem中所有events的filter:
echo 0 > /sys/kernel/debug/tracing/events/sched/filter cat /sys/kernel/debug/tracing/events/sched_switch/filter none cat /sys/kernel/debug/tracing/events/sched_wakeup/filter none
使用sched subsystem中所有events都有的通用字段来设置filter(所有event将以同样的filter结束):
echo 'common_pid == 0' > /sys/kernel/debug/tracing/events/sched/filter cat /sys/kernel/debug/tracing/events/sched/sched_switch/filter common_pid == 0 cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter common_pid == 0
尝试使用sched subsystem中非所有events通用字段来配置filter(所有没有prev_pid字段的event将保留原有的filter):
echo prev_pid == 0 > /sys/kernel/debug/tracing/events/sched/filter cat /sys/kernel/debug/tracing/events/sched/sched_switch/filter prev_pid == 0 cat /sys/kernel/debug/tracing/events/sched/sched_wakeup/filter common_pid == 0
PID filters
顶级文件夹下的set_event_pid 文件,可以给所有event配置PID过滤:
echo $$ > /sys/kernel/debug/tracing/set_event_pid echo 1 > /sys/kernel/debug/tracing/events/enable
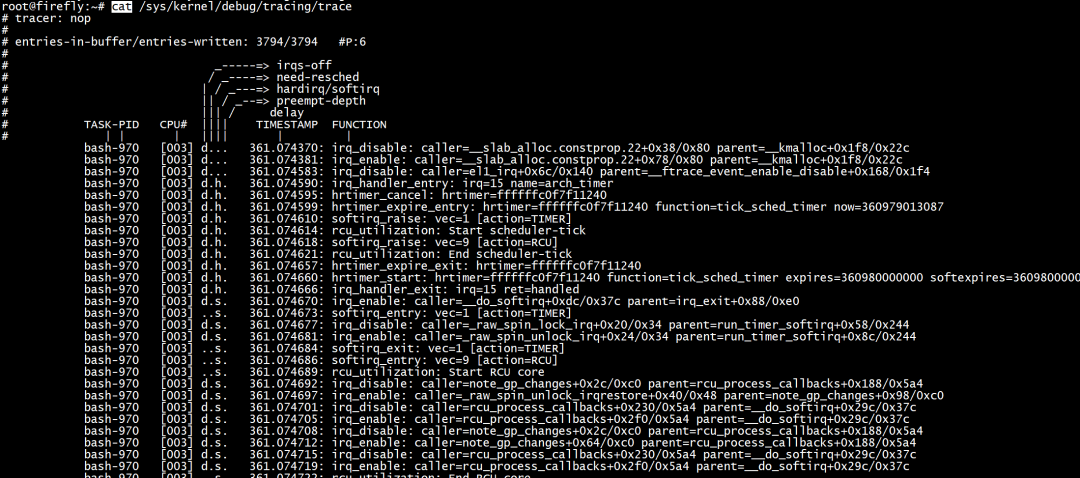
以上配置将会只追踪当前进程。
追加PID使用>>:
echo 123 244 1 >> set_event_pid
Event triggers
跟踪事件可以有条件地调用trigger commands,每当调用具有附加触发器的trace event时,就会调用与该event相关联的 trigger commands。
任何给定的触发器还可以具有与它相关联的事件过滤中描述的相同形式的事件过滤器。如果调用的事件通过关联的筛选器,则该命令将被调用。
给定的event可以有任意数量的trigger与它相关联,个别命令可能在这方面有所限制。
Event triggers是在“soft”模式上实现的,这意味如果一个event有一个或者多个trigger与之相关联,即使该event是disable状态,但实质上已经被actived,然后在“soft”模式中被disable。
也就是说,tracepoint 将被调用,但将不会被跟踪,除非它被正式的enable。该方案允许即使disable的event也可以调用trigger,并且还允许当前event filter实现用于有条件地调用trigger。
设置event triggers的语法类似于设置set_ftrace_filter ftrace filter commands 的语法(可以参考‘Filter commands’ section of Documentation/trace/ftrace.txt),但存在很大的差异。
语法
使用echo command 到‘trigger’文件的形式来增加Trigger:
echo 'command[:count] [if filter]' > trigger
移除Trigger使用同样的命令,但是加上了 ‘!’ 前缀:
echo '!command[:count] [if filter]' > trigger
filter部分的语法和上一节 ‘Event 过滤’ 中描述的相同。
为了方便使用,当前filter只支持使用>增加或删除单条trigger,必须使用!命令逐条移除。
支持的命令
enable_event/disable_event
当triggering event被命中时,这些命令可以enable or disable其他的trace event。当这些命令被注册,trace event变为active。
但是在“soft” mode下disable。这时,tracepoint会被调用但是不会被trace。这些event tracepoint一直保持在这种模式中,直到trigger被触发。
举例,当一个read系统调用进入,以下的trigger导致kmalloc events被trace,:1 表明该行为只发生一次:
echo 'enable_eventkmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger
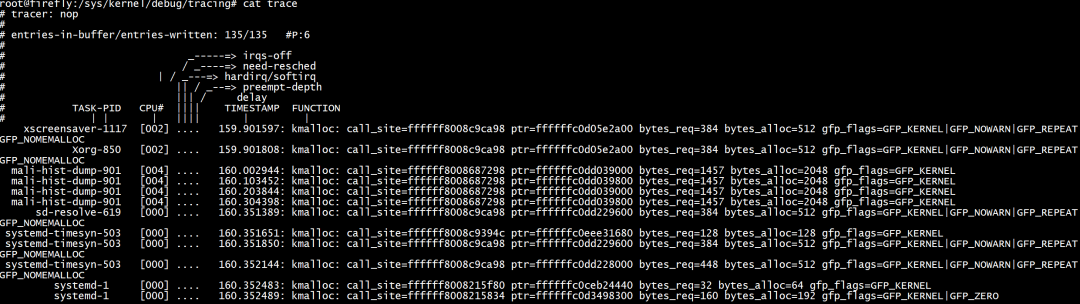
当一个read系统调用退出,以下的trigger导致kmalloc events被disable trace,每次退出都会调用:
echo 'disable_eventkmalloc' > /sys/kernel/debug/tracing/events/syscalls/sys_exit_read/trigger
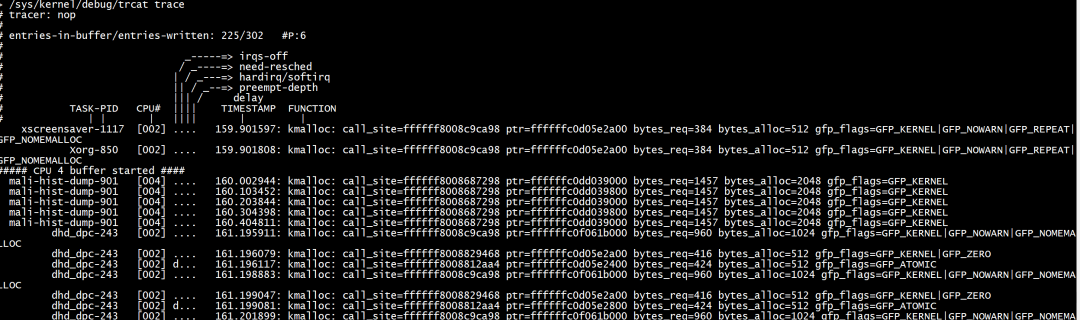
命令格式如下:
enable_event:: [:count] disable_event: : [:count]
移除命令:
echo '!enable_eventkmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger echo '!disable_eventkmalloc' > /sys/kernel/debug/tracing/events/syscalls/sys_exit_read/trigger
注意:每个 triggering event可以有任意多个触发动作,但是每种触发动作只能有一个。
例如,sys_enter_read可以触发enable kmem:kmalloc和sched:sched_switch,但是kmem:kmalloc不能有两个版本kmem:kmalloc and kmem1或者是kmem:kmalloc if bytes_req == 256 and kmem:kmalloc if bytes_alloc == 256。
stacktrace
在triggering event发生时,这个命令在trace buffer中dump出堆栈调用。
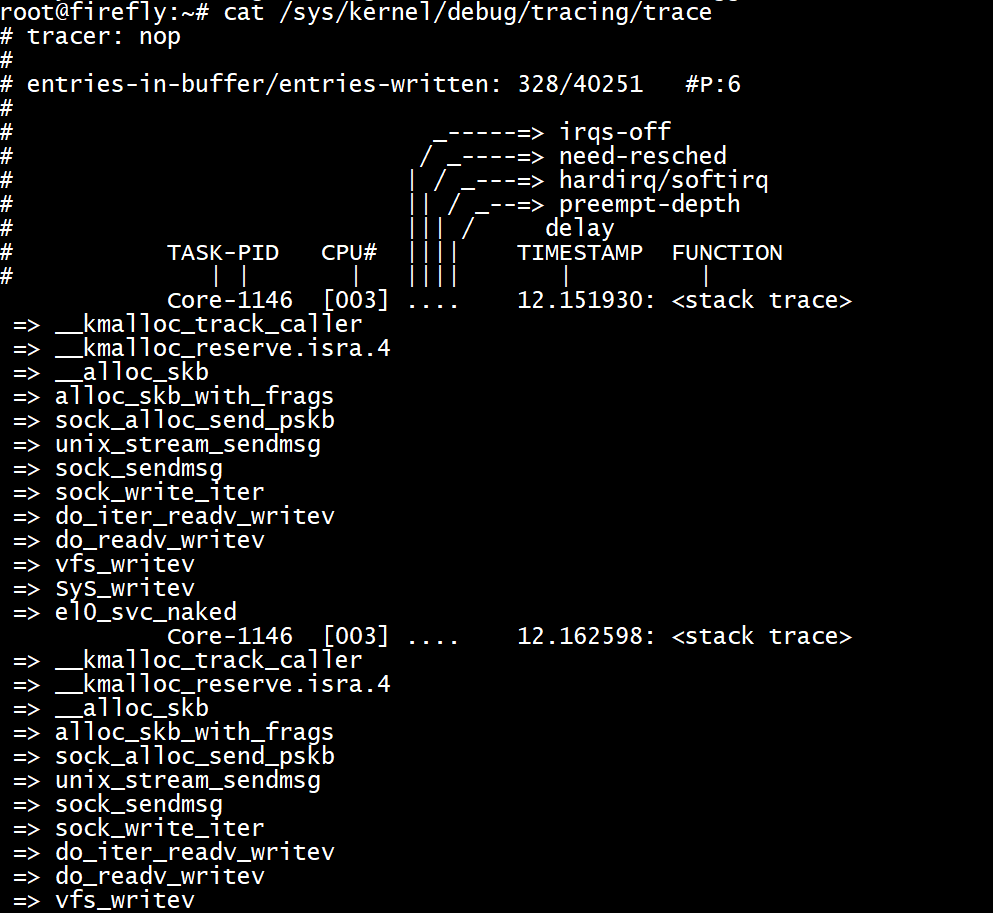
举例,在每次kmalloc tracepoint被命中,以下的trigger dump出堆栈调用,
echo 'stacktrace' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
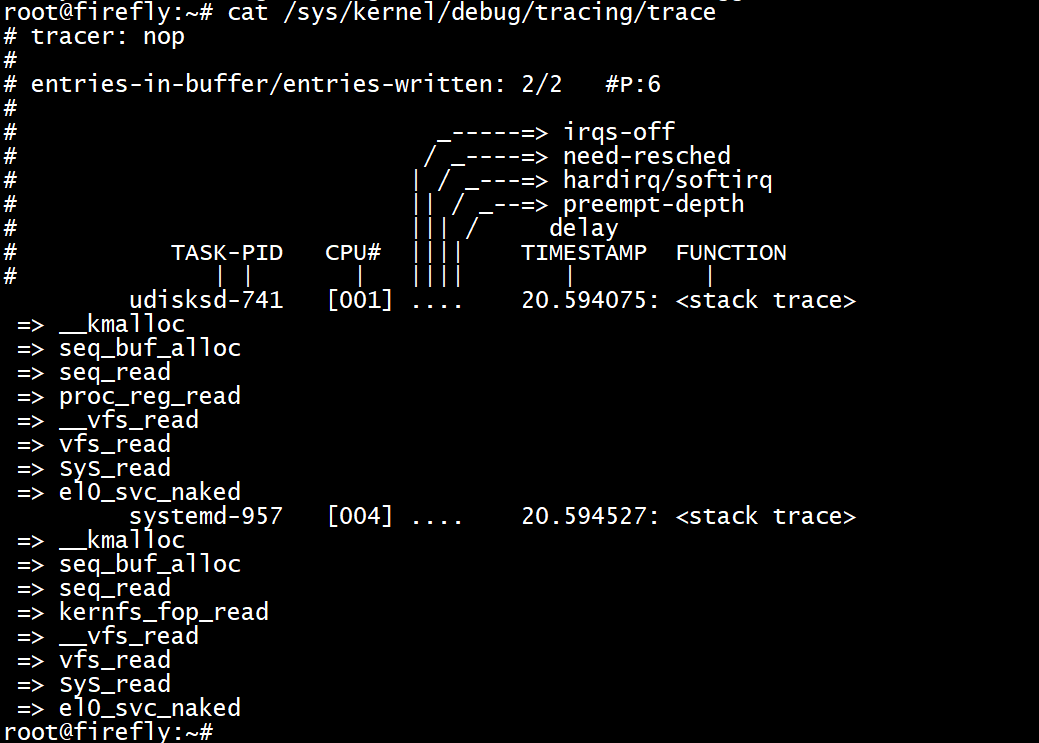
以下的trigger dump出堆栈调用,在kmalloc请求bytes_req >= 800的前2次
echo 'stacktrace:2 if bytes_req >= 800' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
命令格式如下:
stacktrace[:count]
移除命令:
echo '!stacktrace' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger echo '!stacktrace:2 if bytes_req >= 800' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
后者也可以通过下面的(没有过滤器)更简单地去除:
echo '!stacktrace:2' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
注意:每个trace event只能有一个stacktrace触发器。
snapshot
当triggering event发生时,这个命令会触发snapshot。
只有进程名为snapd才会创建一个snapshot。
如果你想trace一系列的events or functions,在 trigger event发生时,snapshot trace buffer将会抓住这些events:
echo 'snapshot if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger #配置trigger,只有进程名为snapd才会snapshot echo 'enable_eventkmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger #触发kmalloc cat /sys/kernel/debug/tracing/snapshot #查看快照
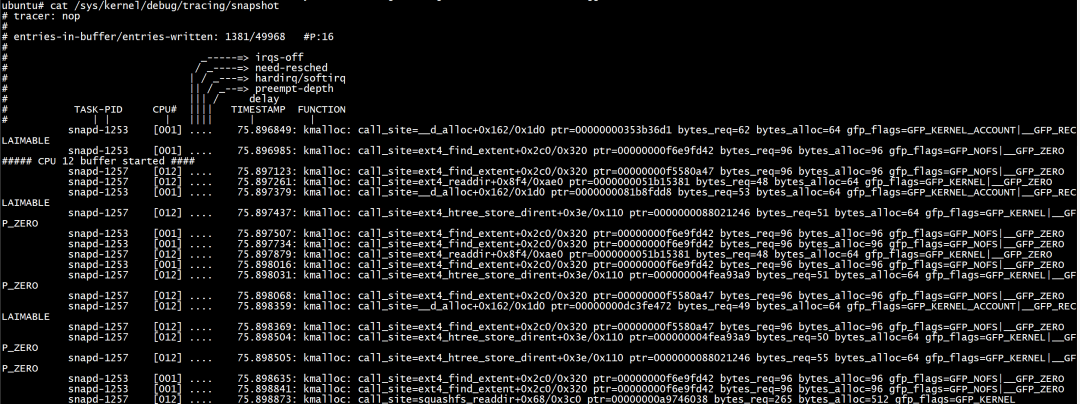
只snapshot一次:
echo 'snapshot:1 if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger echo 'enable_eventkmalloc:1' > /sys/kernel/debug/tracing/events/syscalls/sys_enter_read/trigger #触发kmalloc cat /sys/kernel/debug/tracing/snapshot #查看快照
移除命令:
echo '!snapshot if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger echo '!snapshot:1 if comm == "snapd"' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
注意:每个trace event只能有一个snapshot触发器。
traceon/traceoff
这个命令将会把整个trace tracing on/off当event被命中。parameter 决定了系统 turned on/off 多少次。没有描述就是无限制。
以下命令将 turns tracing off 在block request queue第一次unplugged并且depth > 1,如果您当时正在跟踪一组事件或函数,则可以检查跟踪缓冲区,以查看导致触发事件的事件序列:
echo 'traceoff:1 if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
一直disable tracing 当nr_rq > 1:
echo 'traceoff if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
移除命令:
echo '!traceoff:1 if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger echo '!traceoff if nr_rq > 1' > /sys/kernel/debug/tracing/events/block/block_unplug/trigger
注意:每个trace event只能有一个traceon or traceoff触发器。
hist
组合触发。这个命令聚合多个trace event的字段到一个hash表中。
echo 'hist:key=id.syscall,common_pid.execname:val=hitcount:sort=id,hitcount if id == 16' > /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/trigger cat /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/hist

审核编辑:刘清
-
Linux的文件系统特点2023-11-09 2532
-
谈谈什么是文件系统 文件系统的功能与特点2023-08-30 4565
-
FATFS文件系统原版文件下载2023-06-25 1107
-
roofs根文件系统简介制作(下)2022-09-18 3511
-
文件系统的分布式分发过程2022-07-01 2780
-
使用Ftrace研究Linux内核2022-05-05 2748
-
FATFS文件系统详解2021-11-29 1678
-
可以了解的Linux 文件系统结构2019-04-27 1113
-
linux文件系统中的虚拟文件系统设计详解2019-04-02 2460
-
文件系统是什么?浅谈EXT文件系统历史2018-06-28 6342
-
FatFs文件系统使用2015-11-06 1089
-
NTFS文件系统,NTFS文件系统是什么意思2010-03-29 6666
-
基于μC/OS-II的文件系统设计2009-06-17 735
-
Linux文件系统课程2009-04-10 570
全部0条评论

快来发表一下你的评论吧 !
