

大数据应用的开发流程
电子说
描述
大数据常见处理流程包括:原始数据采集、数据清洗、数据存储、统计分析、存储至数据仓库、数据导出、导入数据库、数据可视化。
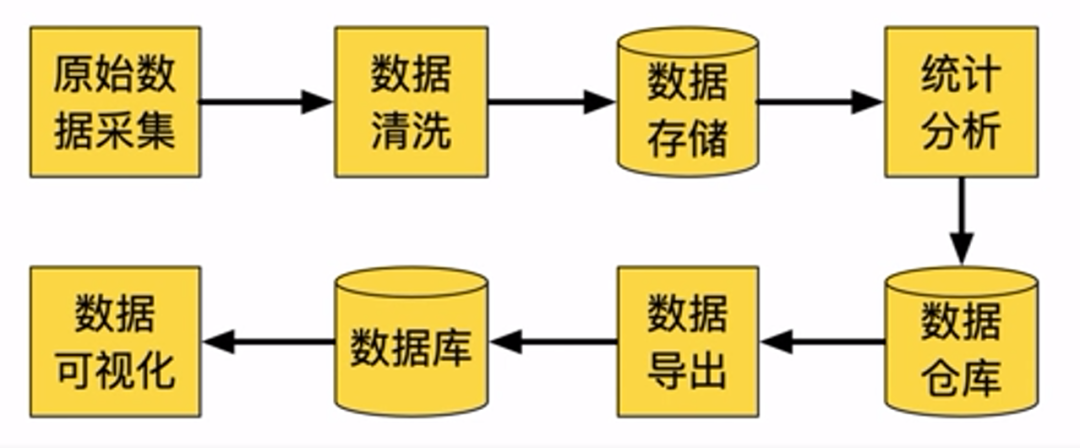
图片来源:学堂在线《大数据导论》
一、原始数据采集
原始数据采集的方式包括:爬虫程序采集、应用数据采集。
爬虫程序采集可在互联网中爬取需要的数据。
应用数据采集是指通过集群或分布式部署方式,将应用程序的日志文件存储于多个服务器中,再将日志文件数据集中存储。
二、数据清洗和数据存储
因为采集的数据中包含不符合要求的数据,如格式冲突的数据、漏项的数据、错误的数据等,所以需要数据清洗将不符合要求的数据去除。
数据清洗过程可以较简单,也可以较复杂。可以通过向数据缺失位置添加某值的方式简单完成数据清洗(含个人理解);也可以通过复杂的机器学习模型清洗数据。
数据清洗可借助ETL软件(根据百度百科:ETL是数据仓库技术)。一般,数据被清洗后,数据量较大,无法存储于计算机内存中,因此,需将数据存储于HDFS(数据存储)中或其他大数据存储方式中。
三、统计分析和数据仓库
统计分析可通过选择合适统计分析工具完成。可使用MapReduce技术实现并行统计分析,也可使用Hive数据仓库(Hive数据仓库具有数据整理、特殊查询、分析存储功能)、Python、R等进行统计分析。
统计分析的难点不在于选择统计分析工具,而在于需求和分析对象。个人理解:具体的需求和分析对象多样导致统计分析不能简单地以某一方式解决所有统计分析问题。
统计分析结束后,数据可被存储于数据仓库中,可使用Hive数据仓库搭建所需的数据仓库。数据仓库的数据不能直接向用户呈现。
四、数据导出和数据库
因为数据仓库的数据不能直接向用户呈现,所以需要将数据从数据仓库导出,并将数据导入数据库中以实现数据可视化。数据导出可使用Sqoop(Sqoop可提供数据导入功能)。
数据库一般为关系型数据库。
五、数据可视化
数据可视化的目标是使数据可被直观展示,传统图形化展示方式种类较多(根据网络资料理解:传统图形化展示方式包括条形图、排列图、饼图、环形图等)。大数据新型可视化方式包括:气泡图、数据画像、地图涂色等。
六、大数据应用案例
下文介绍Hadoop自带的MapReduce应用案例WordCount,WordCount可统计文件的词频。
(1)启动Hadoop系统服务,需启动HDFS与Yarn服务(根据百度百科:Yarn是新的Hadoop资源管理器,是通用资源管理系统)。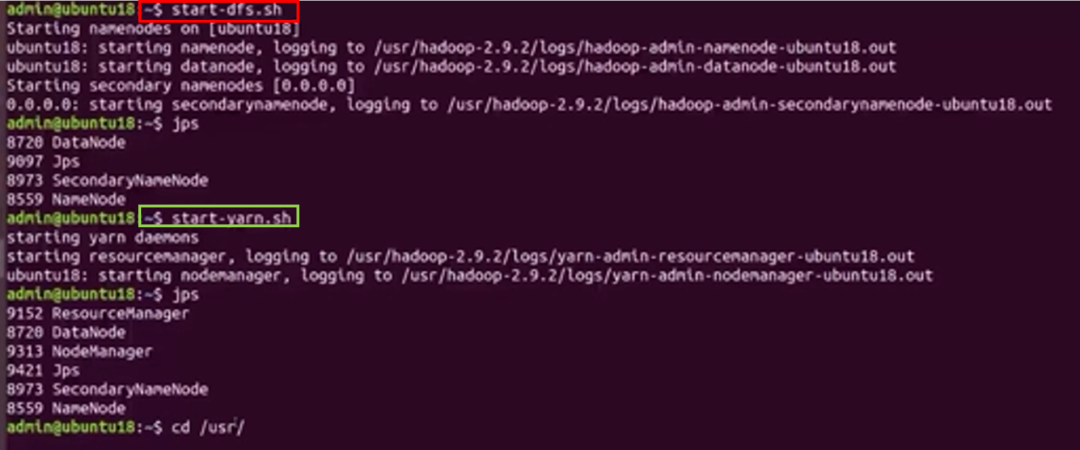
图中红框内命令为HDFS启动命令,绿框内命令为Yarn服务启动命令,图片来源:根据学堂在线《大数据导论》资料制作
(2)检查Hadoop安全模式是否为“OFF”状态,如果Hadoop安全模式的状态为“ON”,则只能读取HDFS中的数据,不能向HDFS中写入数据。
(3)准备需要处理的数据,即查看文本文件中的内容。
图中红框内命令为查看文件内容命令,绿框内为文件中的内容,图片来源:根据学堂在线《大数据导论》资料制作
(4)执行WordCount应用程序。WordCount的具体命令是hadoop jar hadoop mapreduce-examples-2.9.2.jar wordcount 被统计文件的目录名与文件名 统计结果输出文件目录名与文件名。
图中红框内为WordCount应用程序统计结果输出文件的内容,图片来源:根据学堂在线《大数据导论》资料制作
审核编辑:刘清
-
大数据应用开发流程-1(1)#大数据分析学习硬声知识 2023-07-13
-
[2.6.1]--2-6大数据应用开发流程-1jf_75936199 2023-03-14
-
发电全流程闭环大数据智能控制方案2021-06-30 960
-
大数据应用于实际的案例中的三步流程2019-04-25 1782
-
大数据应用开发如何入门需要知道这些2018-11-26 2346
-
大数据平台开发公司有哪些?2018-11-15 4534
-
DKHadoop大数据开发框架的构成模块2018-10-19 2303
-
大数据专业技术学习之大数据处理流程2018-06-11 4330
-
大数据运用的技术2018-04-08 3827
-
如何从零学大数据?2018-03-01 3972
全部0条评论

快来发表一下你的评论吧 !
