

Underlay网络之叶脊网络介绍
描述
为满足云业务的需要,网络逐渐分化为Underlay和Overlay。Underlay网络就是传统数据中心的路由交换等物理设备,依然信奉稳定压倒一切的理念,提供可靠的网络数据传输能力;Overlay则是在其上封装的业务网络,与服务更贴近,通过VXLAN 或者GRE等协议封装,给用户提供一个易用的网络服务。Underlay网络和Ooverlay网络即关联又解耦,两者相互关联又能独立演进。
Underlay网络是网络的地基,承载网络不稳,业务便无SLA可言。数据中心网络架构在经历三层网络架构、胖树(Fat-Tree)型网络架构后,正过渡到Spine- Leaf架构,迎来了CLOS 网络模型的第三次应用 。
传统数据中心网络架构
三层设计
2004-2007年期间,三层网络结构在数据中心十分盛行。它有三个层次:核心层(网络的高速交换主干)、汇聚层(提供基于策略的连接)、接入层(将工作站接入网络),这个模型如下: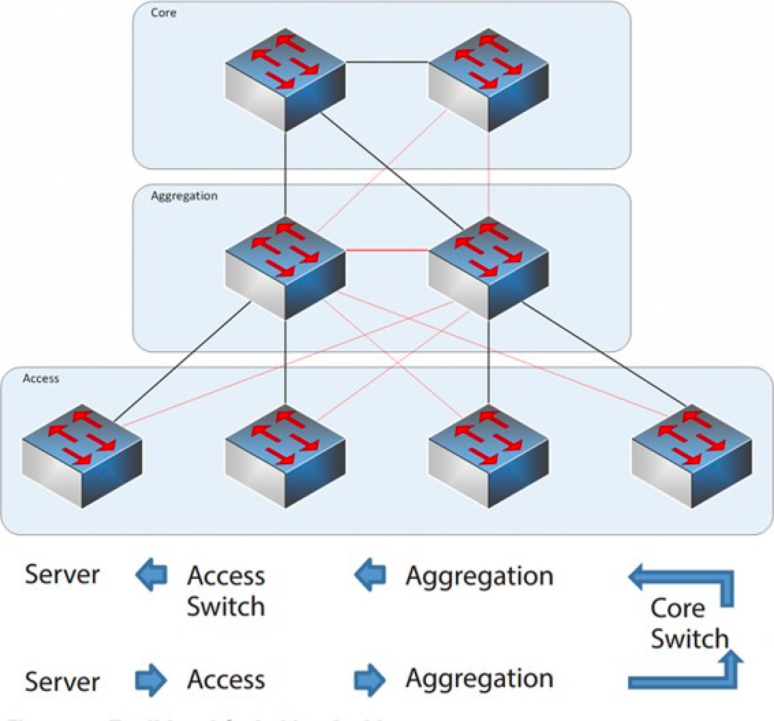
|三层网络结构
核心层(Core Layer) :核心交换机为进出数据中心的包提供高速的转发,为多个汇聚层提供连接性,核心交换机为通常为整个网络提供一个弹性的L3路由网络。
汇聚层(Aggregation Layer) :汇聚交换机连接接入交换机,同时提供其他的服务,例如防火墙,SSL offload,入侵检测,网络分析等。
接入层(Access Layer) :接入交换机通常位于机架顶部,所以它们也被称为ToR(Top of Rack)交换机,它们物理连接服务器。 通常情况下,汇聚交换机是 L2 和 L3 网络的分界点:汇聚交换机以下的是 L2 网络,以上是 L3 网络。每组汇聚交换机管理一个 POD(Point Of Delivery),每个 POD 内都是独立的 VLAN 网络。
网络环路与生成树协议
环路的形成大都是由于目的路径不明确导致混乱而造成的。用户构建网络时,为了保证可靠性,通常会采用冗余设备和冗余链路, 这样就不可避免的形成环路。而二层网络处于同一个广播域下, 广播报文在环路中会反复持续传送,形成广播风暴, 瞬间即可导致端口阻塞和设备瘫痪。因此,为了防止广播风暴,就必须防止形成环路。
既要防止形成环路,又要保证可靠性,就只能将冗余设备和冗余链路变成备份设备和备份链路。即冗余的设备端口和链路在正常情况下被阻塞掉,不参与数据报文的转发。只有当前转发的设备、端口、 链路出现故障,导致网络不通的时候,冗余的设备端口和链路才会被打开,使得网络能够恢复正常。实现这些自动控制功能的就是 STP(Spanning Tree Protocol ,生成树协议 )。
生成树协议在接入层和汇聚层之间运行,核心是在每个启用 STP 的网桥上运行的生成树算法,该算法专门设计用于在存在冗余路径时避免桥接环路。STP 选择用于转发消息的最佳数据路径,并禁用了那些不属于生成树的链路,在任意两个网络节点之间只留下一条活动路径,其他上行链路将被阻塞。
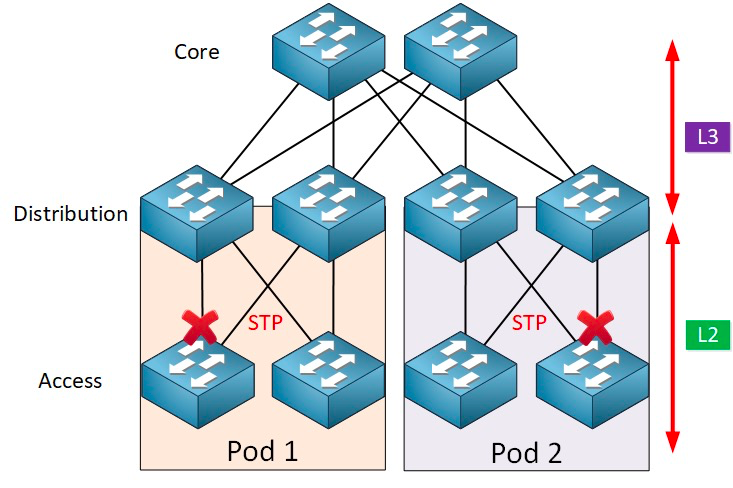
STP 有许多好处:简单,即插即用(plug-and-play),只需很少配置。每个 pod 内的机器都属于同一个 VLAN, 因此服务器无需修改 IP 地址和网关就可以在 pod 内部任意迁移位置。
但是,STP 无法使用并行转发路径(parallel forwarding path),它永远会禁用 VLAN 内的冗余路径。STP的缺点:
1、拓扑收敛慢。当网络拓扑发生改变的时候,生成树协议需要50-52秒的时间才能完成拓扑收敛。
2、不能提供负载均衡的功能。当网络中出现环路的时候,生成树协议只能简单的将环路进行Block,这样该链路就不能进行数据包的转发,浪费网络资源。
虚拟化和东西向流量挑战
2010年之后,为了提高计算和存储资源的利用率,数据中心开始采用虚拟化技术,网络中开始出现了大量的虚拟机。虚拟技术把一台服务器虚化成了多台逻辑服务器,每个VM都可以独立运行,有自己的OS、APP、自己独立的MAC地址和IP地址,它们通过服务器内部的虚拟交换机(vSwitch)与外部实体进行网络连接。
虚拟技术有个伴生的需求:虚拟机动态迁移,在保证虚拟机上服务正常运行的同时,将一个虚拟机系统从一个物理服务器移动到另一个物理服务器。这个过程对于最终用户来说是无感的,管理员能够在不影响用户正常使用的情况下,灵活调配服务器资源,或者对物理服务器进行维修和升级。
为了保证迁移时业务不中断,就要求在迁移时,不仅虚拟机的IP地址不变,而且虚拟机的运行状态也必须保持原状(例如TCP会话状态),所以虚拟机的动态迁移只能在同一个二层域中进行,而不能跨二层域迁移,催生了从接入层到核心层的大二层域(larger L2 domain)的需求。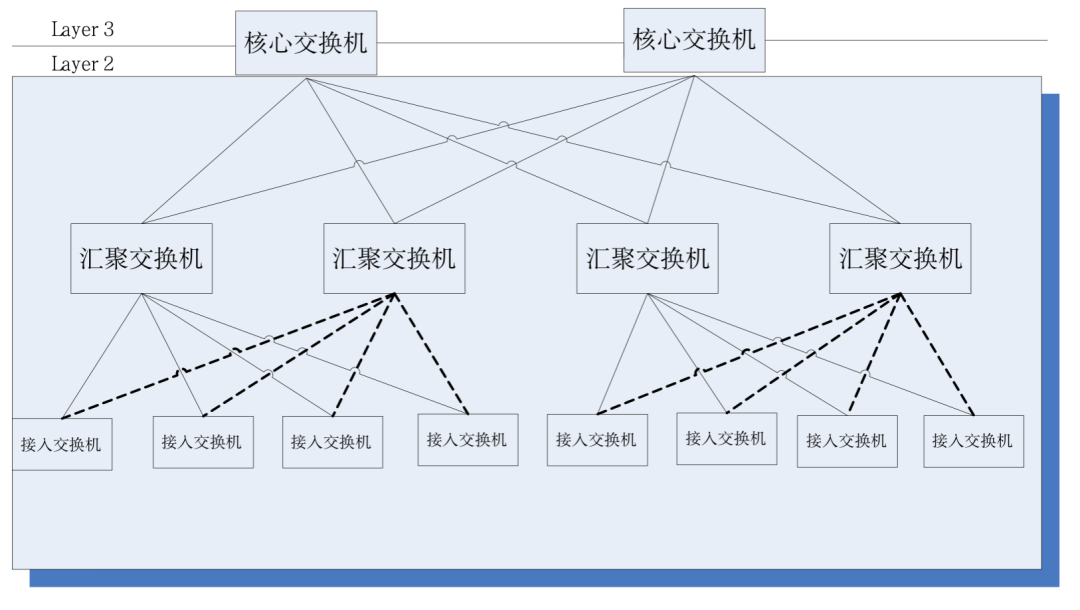
传统的大二层网络架构L2和L3的分界点在核心交换机,核心交换机以下的数据中心是一个完整的广播域,即L2网络。这样可以实现设备部署、位置迁移的任意性,不需要进行IP、网关等配置的修改。不同的L2网络(VLAN)通过核心交换机进行路由转发。
不过该架构下的核心交换机需要维护庞大的MAC和ARP表,对核心交换机的能力提出很高的要求 。另外,接入交换机(TOR)也对整个网络的规模造成一定的限制。这些最终限制了网络的规模、网络扩展及弹性能力,跨三层调度的时延问题,不能满足未来业务的需求。
另一方面,虚拟化技术带来的东西向流量也给传统三层网络带来了挑战。数据中心的流量总的来说可以分为以下几种:
南北向流量:数据中心之外的客户端到数据中心服务器之间的流量,或者数据中心服务器访问互联网的流量。
东西向流量:数据中心内的服务器之间的流量,以及不同数据中心间的流量,例如数据中心之间的灾备,私有云和公有云之间的通讯。
虚拟化技术的引入使得应用的部署方式越来越分布式,带来的“副作用”是东西向流量越来越大。
传统的三层架构通常是为南北向流量设计的。虽然它可以用于东西向流量,但可能最终无法按要求执行。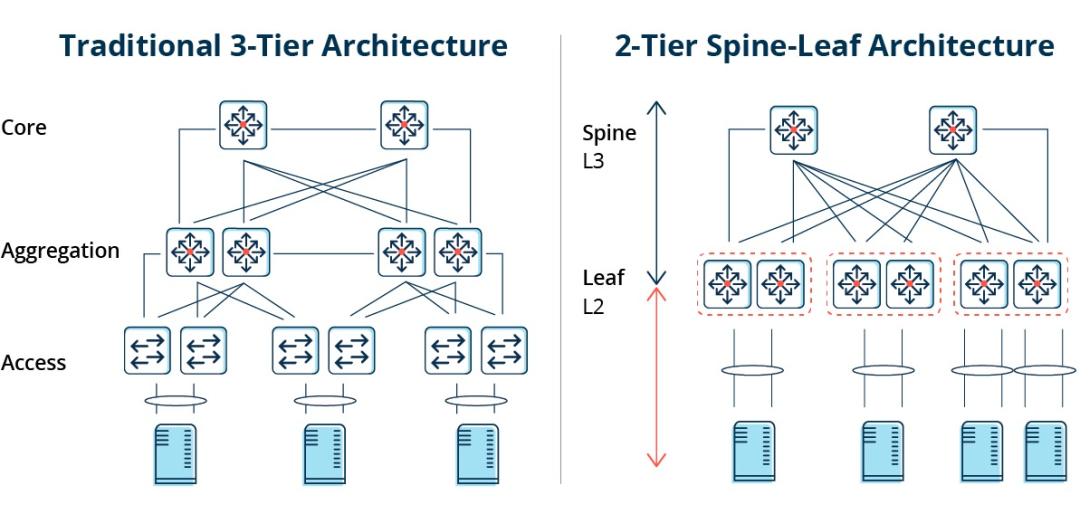
| 传统三层架构 vs. Spine-Leaf架构
三层架构中的东西向流量必须经过汇聚层和核心层的设备转发,不必要地经过许多节点.(Server -> Access -> Aggregation -> Core Switch -> Aggregation -> Access Switch -> Server)
因此,如果通过传统三层网络架构运行大量的东西向流量,连接到同一交换机端口的设备可能会争夺带宽,导致最终用户获得的响应时间很差。
传统三层网络架构缺点
由此可见,传统三层网络架构有着不少的缺点:
带宽浪费:为了防止环路,通常在汇聚层和接入层之间运行STP协议,这样接入交换机只有一条上行链路真正承载流量,其他上行链路会被阻塞,造成带宽的浪费。
大规模网络布放困难:随着网络规模的扩大,数据中心分布在不同的地理位置,虚拟机必须在任何地方创建和迁移,其IP地址、网关等网络属性保持不变,这需要fat Layer 2的支持。在传统结构中,无法进行迁移。
东西向流量不足:三层网络架构主要是为南北向流量设计的,虽然也支持东西向流量,但不足之处很明显。当东西向流量较大时,汇聚层和核心层交换机的压力会大大增加,网络规模和性能会局限在汇聚层和核心层。
使企业陷入成本和可扩展性的困境:支撑大规模高性能网络,需要大量的汇聚层和核心层设备,这不仅给企业带来了高昂的成本,同时也要求网络建设网络时必须提前规划规模。当网络规模较小时,会造成资源浪费,当网络规模不断扩大时,扩容困难。
Spine-Leaf 网络架构
什么是Spine-Leaf 网络架构?
针对以上问题,一种新的数据中心设计,Spine-Leaf 网络架构出现了,也就是我们所说的叶脊网络。
顾名思义,该架构共有一个脊(Spine)层和一个叶(Leaf)层,包括脊交换机(spine switches)和叶交换机。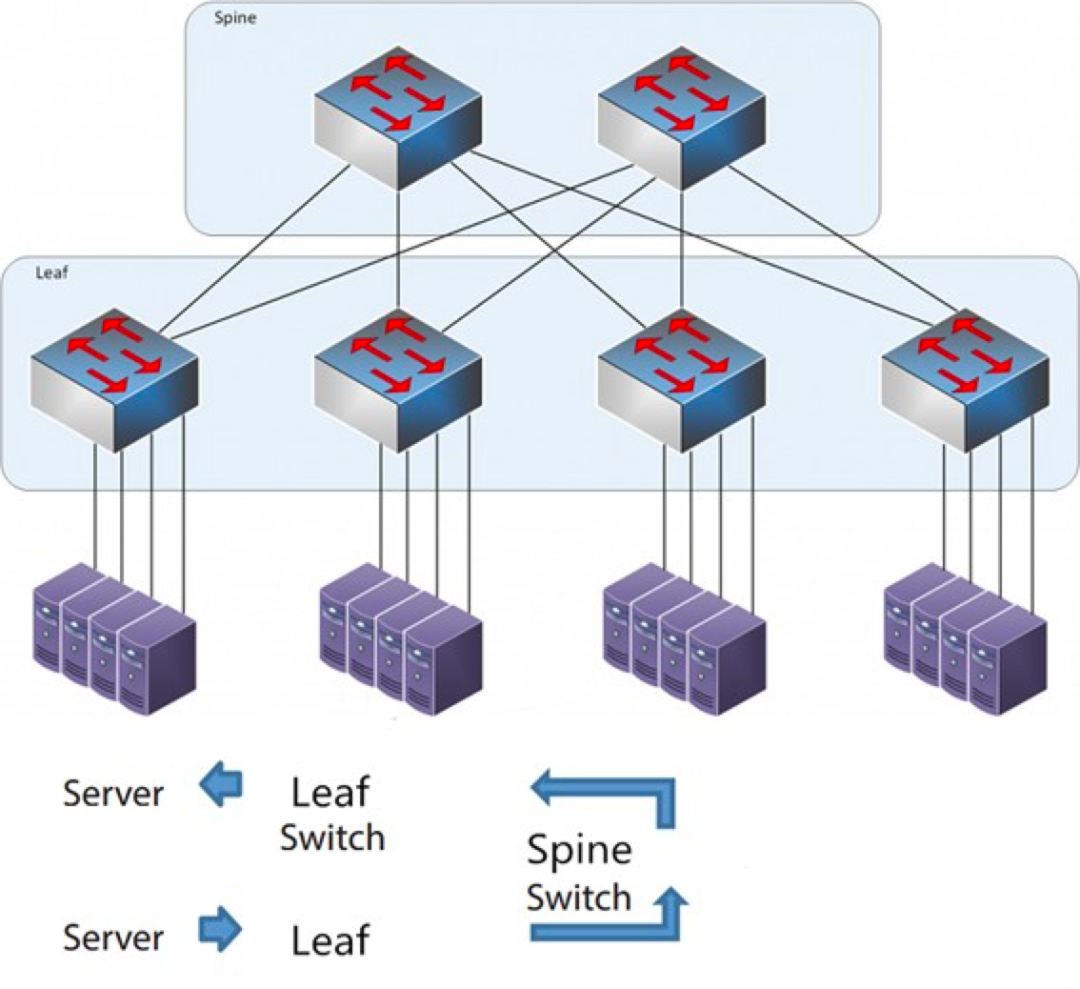
| Spine-Leaf架构
每个叶交换机都连接到所有脊交换机,脊交换机不直接相互连接,形成一个 full-mesh 拓扑。
在 Spine-and-Leaf 架构中,任意一个服务器到另一个服务器的连接,都会经过相同数量的设备(Server -> Leaf -> Spine Switch -> Leaf Switch -> Server),这保证了延迟是可预测的,因为一个包只需要经过一个 spine 和另一个 leaf 就可以到达目的端。
Spine-Leaf 的工作原理
Leaf Switch:相当于传统三层架构中的接入交换机,作为 TOR(Top Of Rack)直接连接物理服务器。与接入交换机的区别在于 L2/L3 网络的分界点现在在 Leaf 交换机上了。Leaf 交换机之上是三层网络,Leaf 交换机之下都是个独立的 L2 广播域,这就解决了大二层网络的 BUM 问题。如果说两个 Leaf 交换机下的服务器需要通讯,需要通过 L3 路由,经由 Spine 交换机进行转发。
Spine Switch:相当于核心交换机。Spine 和 Leaf 交换机之间通过 ECMP(Equal Cost Multi Path)动态选择多条路径。区别在于,Spine 交换机现在只是为 Leaf 交换机提供一个弹性的 L3 路由网络,数据中心的南北流量可以不用直接从 Spine 交换机发出,一般来说,南北流量可以从与 Leaf 交换机并行的交换机(edge switch)再接到 WAN router 出去。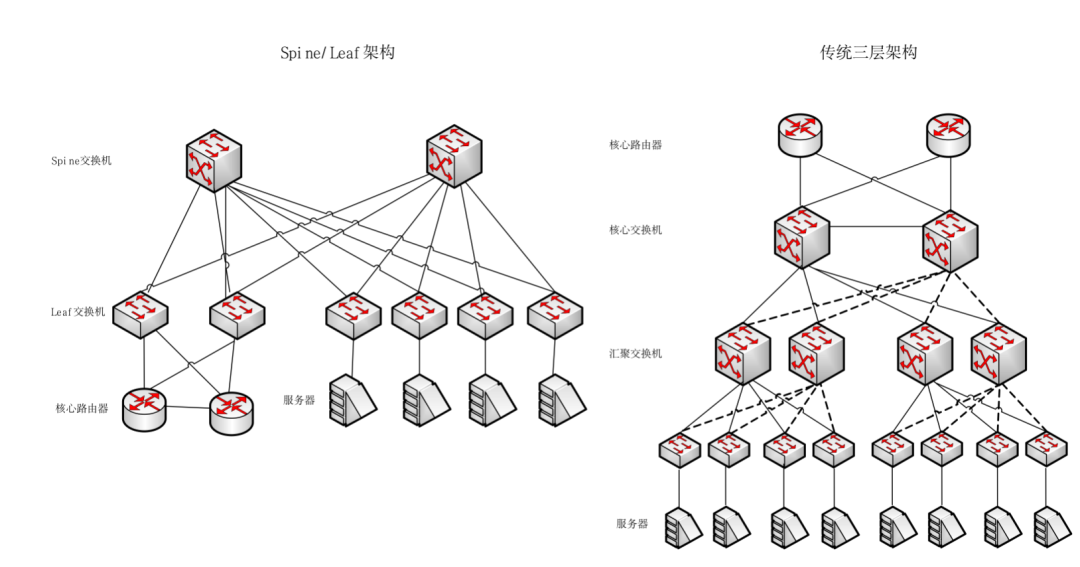
|Spine/Leaf网络架构和传统三层网络架构对比
Spine-Leaf的优势
扁平化:扁平化设计缩短服务器之间的通信路径,从而降低延迟,可以显著提高应用程序和服务性能。
扩展性好:当带宽不足时,增加脊交换机数量,可水平扩展带宽。当服务器数量增加时,如果端口密度不足,我们可以添加叶交换机。
降低成本——南北向流量,可以从叶节点出去,也可从脊节点出去。东西向流量,分布在多条路径上。这样一来,叶脊网络可以使用固定配置的交换机,不需要昂贵的模块化交换机,进而降低成本。
低延迟和拥塞避免——无论源和目的地如何,叶脊网络中的数据流在网络上的跳数都相同,任意两个服务器之间都是Leaf—>Spine—>Leaf三跳可达的。这建立了一条更直接的流量路径,从而提高了性能并减少了瓶颈。
安全性和可用性高:传统的三层网络架构采用STP协议,当一台设备故障时就会重新收敛,影响网络性能甚至发生故障。叶脊架构中,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。
通过ECMP进行负载均衡,非常适合使用 SDN 等集中式网络管理平台的环境。
SDN 允许在发生阻塞或链路故障时简化流量的配置,管理和重新分配路由,使得智能负载均衡的全网状拓扑成为一个相对简单的配置和管理方式。
不过Spine-Leaf架构也有一定的局限性:
其中一个缺点就是,交换机的增多使得网络规模变大。叶脊网络架构的数据中心需要按客户端的数量,相应比例地增加交换机和网络设备。随着主机的增加,需要大量的叶交换机上行连接到脊交换机。
脊交换机和叶交换机直接的互联需要匹配,一般情况下,叶脊交换机之间的合理带宽比例不能超过3:1。
例如,有48个10Gbps速率的客户端在叶交换机上,总端口容量为 480Gb/s。如果将每个叶交换机的 4 个 40G 上行链路端口连接到 40G 脊交换机,它将具有 160Gb/s 的上行链路容量。
该比例为 480:160,即 3:1。数据中心上行链路通常为 40G 或 100G,并且可以随着时间的推移从 40G (Nx 40G) 的起点迁移到 100G (Nx 100G)。重要的是要注意上行链路应始终比下行链路运行得更快,以免端口链路阻塞。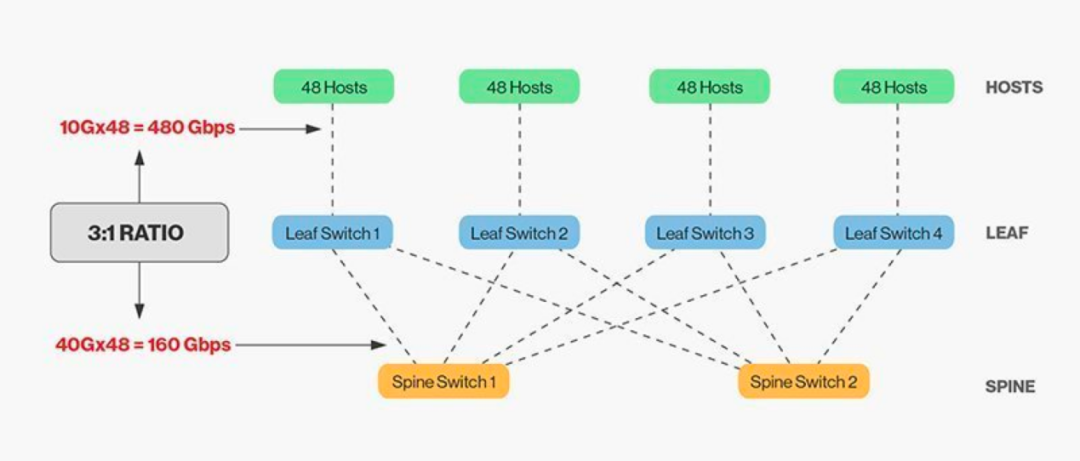
叶脊网络也有明确的布线的要求。因为每个叶节点都必须连接到每个脊交换机,我们需要铺设更多的铜缆或光纤电缆。互连的距离会推高成本。
根据相互连接的交换机之间的距离,叶脊架构所需要的高端光模块数量高于传统三层架构数十倍,这会增加整体部署成本。不过也因此带动了光模块市场的增长,尤其是100G、400G这样的高速率光模块。
Spine-Leaf 网络架构的应用
Facebook在2014年公开的数据中心架构是最具代表性的叶脊网络用例,此外谷歌第五代数据中心架构Jupiter也大规模采用了叶脊网络。
Facebook从14年开始对自己原有的数据中心网络架构进行改造,原因就在于面对网络流量2-4倍的未来扩张,现有的三层网络架构难以胜任。因此,Facebook提出了自己的下一代数据中心网络——data center fabric网络架构(也称为F4网络),在原始叶脊网络基础上进行模块化组网,能够承载数据中心内部的大量东西流量的转发,并且保证了足够的扩展性。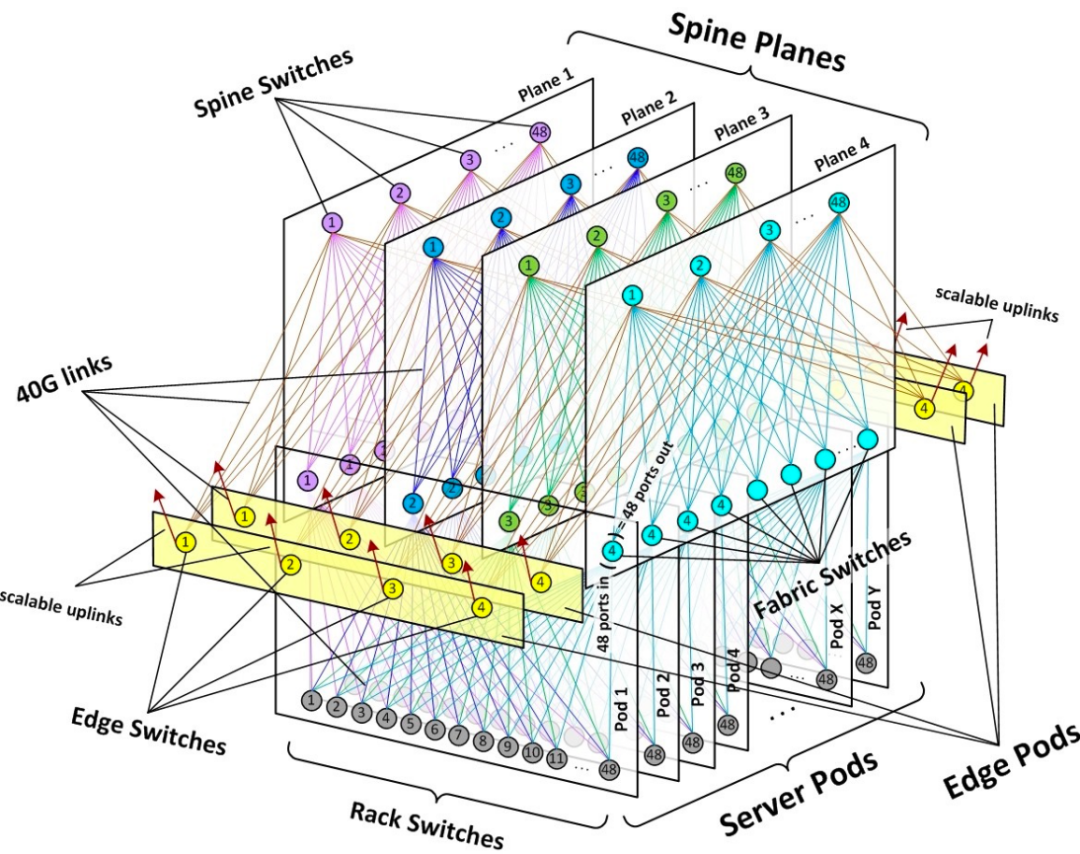
| F4架构
目前Facebook已经演进到F16架构,将Spine平面增加为16个。单芯片处理能力提升为12.8TBps, 使得Spine交换机由原来的BackPack更新为MiniPark架构,不仅体积更小,所要通过的路径仅需跨越5个芯片。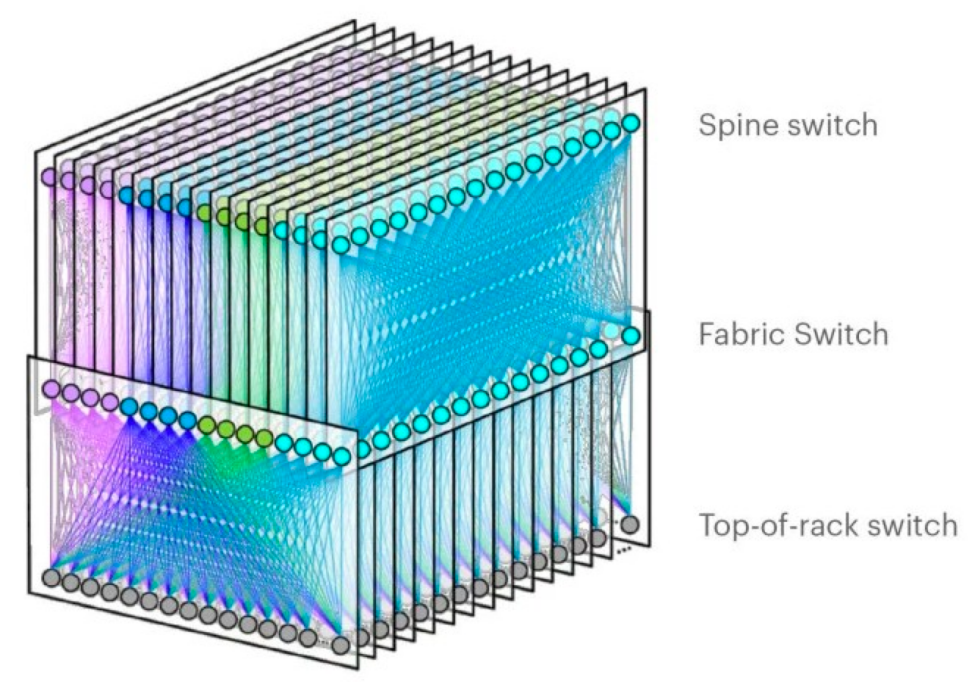
| F16架构
谷歌
2015年,谷歌在SIGCOMM会议上发表论文《Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network》,详细地阐述了谷歌过去多年在数据中心网络的创新和演进。
其中第五代的架构叫做Jupiter Network Fabrics,可以视为一个三层Clos。leaf交换机还是作为ToR,向北连接到叫做 Middle Block的spine交换机。
Middle Block和ToR组成一个集群(相当于Facebook的Server Pod,内部是一个二层Clos)叫做Aggregation Block Superblock。MiddleBlock向北还有一层super spine也就是Spine Block。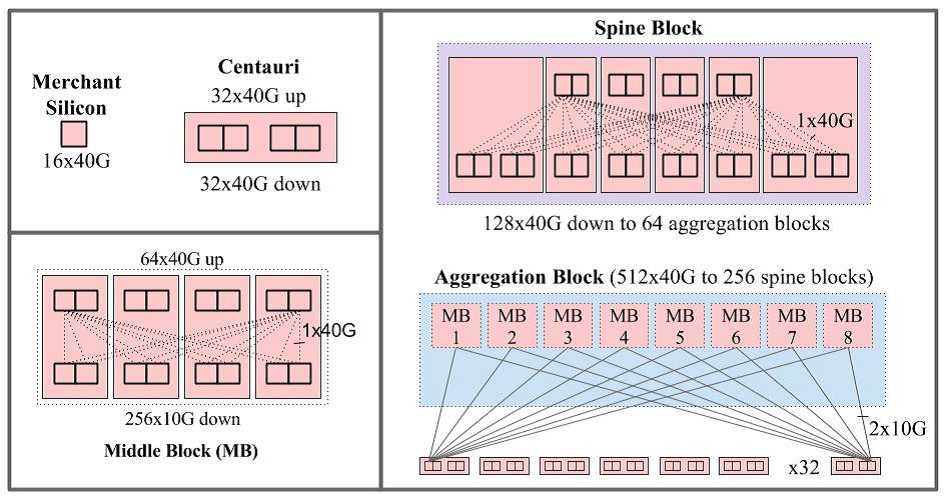
| Jupiter拓扑
super spine的数量可以一直增长,加入更多super spine交换机。但是每个新加入的super spine都要和原有的Pod全互联。从Pod的角度看,每加入一个super spine,Pod就要额外增加连接。为了解决这个问题,Google在spine 层和Pod层之间加入了Apollo Fabric。Apollo结构解除了spineblock和superblock的直连,但又能够动态地调整spineblock和superblock的连接关系,高效实现了全互联,并且能够动态地调整网络流量的分布。感兴趣的同学可以继续阅读《十年一剑,谷歌数据中心网络Jupiter的进击之路》。
总的来说,传统的三层数据中心架构的设计是为了应付服务客户端-服务器应用程序的纵向大流量传输。而虚拟化(即虚拟机动态迁移)从根本上改变了数据中心网络架构的需求,从而要求网络支持大范围的二层域,这使得数据中心二层网络的范围越来越大,甚至出现了大二层网络这一新领域。这也从根本上改变了传统三层网络统治数据中心网络的局面。
叶脊网络解决了横向网络连接的传输瓶颈,而且提供了高度的扩展性,它几乎能适应所有大中小型数据中心。可以预见,未来企业的IT建设都将走向收敛型和高层次的虚拟化叶脊网络架构。虽然叶脊网络为网络传输提供了拓扑的基础,但是还需要有配套合适的转发协议才能完全发挥出拓扑的实力。为了实现“大二层”,数据中心网络技术在近十年间经历了不断的迭代与优化,主要包括二层多路径、数据中心二层互联、端到端Overlay等几大类技术。
审核编辑:刘清
-
求助脊波网络编程2015-01-12 2445
-
贝叶斯网络精确推理算法的研究2009-08-15 1082
-
贝叶斯网络分析2017-03-31 1705
-
overlay网络与underlay网络的介绍区别2017-12-05 83719
-
脊叶网络架构下的布线是怎样的2020-01-02 2021
-
脊叶网络架构下的布线系统说明2020-12-25 1397
-
你们知道什么是叶脊网络吗2021-05-31 4453
-
探究Overlay网络模型和Underlay网络模型。2021-06-04 3496
-
叶脊网络Spine-Leaf架构布线方式的说明2021-12-23 7785
-
借助光连接与网络产品利器,实现数据中心网络优化2022-09-30 3751
-
SDN系统方法-叶棘网络2023-06-15 1642
-
为什么需要Overlay网络?Overlay网络是如何形成的?Overlay网络的应用有哪些?2023-08-21 2814
-
网络布局与光模块配置需求深度解析2024-04-01 3754
全部0条评论

快来发表一下你的评论吧 !
