

AMD RDNA2 GPU架构详解
描述
2019年,AMD 放弃了长期使用的 GCN 架构,转而采用 RDNA。本文我们将来分析下RDNA 2,RDNA 2在RDNA 1基础上进行了扩展,同时添加了光线追踪支持和其他一些增强功能。
在本文中,我们可以做一些有趣的事情,并从 RDNA 2 的角度来看一些游戏。
架构
顾名思义,RDNA 2 建立在 RDNA 1 架构之上。AMD 进行了多项更改以提高效率并使硬件功能保持最新状态,但基本的 WGP 架构仍然存在。每个 WGP 或工作组处理器都具有四个 SIMD。每个 SIMD 都有一个32宽的执行单元,用于最常见的操作。RDNA 2 获得一些额外的点积运算指令,以帮助加速机器学习。例如,V_DOT2_F32_F16 将成对的 FP16 值相乘、相加,然后添加一个 FP32 累加器。它不像Nvidia的张量核那样,在Nvidia中,像HMMA这样的指令直接处理8×8矩阵。但这些指令让RDNA 2用更少的指令来做矩阵乘法,而不是使用普通的融合乘法-加法指令。
每个 SIMD 都有 32 个宽度的执行单元用于最常见的操作,一个 128 KB 的矢量寄存器文件,并且可以跟踪多达 16 个波面。因此,AMD 减少了 RDNA 2 可以跟踪的波面数量,从 RDNA 1 中的 20 个。GPU 不会像高性能 CPU 那样进行乱序执行。相反,它们保持大量线程处于运行状态,并在线程之间切换以保持执行单元被占用以隐藏延迟。在 RDNA 2 上,SIMD 基本上有 16 路 SMT,而在 RDNA 1 上有 20 路。
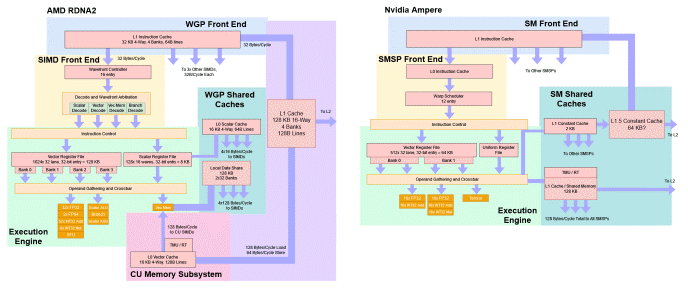
RDNA 2 架构的 WGP 和 Nvidia Ampere 的 SM 的基本草图
这听起来像是一种回归(regression),但跟踪更多的波阵面(类似于CPU线程)可能是昂贵的。线程或波面选择逻辑必须解决与CPU调度器非常相似的问题。每个周期,每个条目都必须检查,看它是否准备好执行了。AMD可能希望将每个周期的检查次数从20次减少到16次,以便在更低的功率下达到更高的时钟速度。在相同的处理节点上,RDNA 2的时钟比它的前身要高得多,所以AMD在这方面做得很好。
RDNA 2也比安培好。尽管这两种架构都使用基本的构建模块(SMs或WGP),每个周期可以执行128个FP32操作,但RDNA 2 WGP可以保持64个波阵面。Ampere SM只能保持飞行中的48个warp。RDNA 2也有更多的向量寄存器文件容量,这意味着编译器可以在不减少占用的情况下在寄存器中保存更多的数据。

这让 RDNA 2 WGP 有更好的机会通过保持更多的工作在进行中来隐藏延迟。将其与更好的缓存相结合,每个 RDNA 2 WGP 都应该能够比 Ampere SM 更有力。
WGP 的四个 SIMD 被组织成两个一组,AMD 称之为计算单元 (CU)。一个 CU 有自己的内存管道和 16 KB L0 向量缓存。在 CU 级别,AMD 增强了内存管道以添加硬件光线跟踪加速。具体来说,纹理单元现在可以执行射线相交测试,每个周期进行四次框测试或每个周期进行一次三角形测试。盒子测试发生在 BVH 的上层,而三角测试发生在最后一层。BVH,或有界顶点层次结构,使用分而治之的方法加速光线追踪。因为检查场景中的每个三角形都非常昂贵,盒子测试缩小了光线穿过的区域,理想情况下 GPU 最后只检查一组狭窄的三角形。

RDNA 2中引入的光线追踪加速指令
光线追踪加速是通过一些新的纹理指令来访问的。显然,这些指令实际上并没有做传统的纹理工作,但是纹理单元是附加这个额外功能的一个方便的地方。新的指令本身只做交集测试。常规的计算着色器代码处理遍历BVH。它还必须计算逆射线方向,并将其提供给纹理单元,即使纹理单元本身有足够的信息来计算。AMD可能想要最小化支持光线追踪的硬件成本,并且认为他们有足够的常规着色器来解决这个问题。
缓存
除了在功能上与英伟达不相上下之外,RDNA 2还可以扩展到性能上。最高端的RDNA 1 GPU RX 5700 XT只有20个WGP。它也建立在一个251平方毫米的小芯片上,与英伟达的中端卡竞争,而不是挑战他们的高端卡。RDNA 2的RX 6900 XT将WGP数翻了一番,并提高了时钟速度,显示了AMD想要挑战英伟达最佳性能的雄心。但就像增加CPU的核心数量一样,GPU的扩展也会产生更高的带宽需求。英伟达选择了耗电384位GDDR6X设置来为安培供电。AMD选择了256位的GDDR6配置。为了避免内存带宽瓶颈,RDNA 2获得了额外级别的缓存。AMD将其命名为“无限缓存”,并在内部将其称为MALL(内存连接最后一级)。
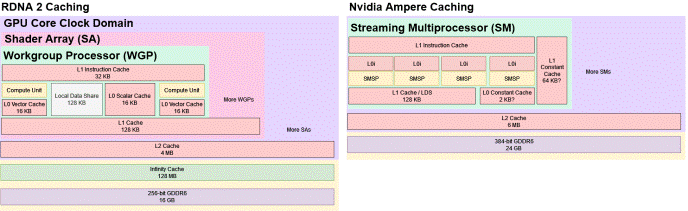
RDNA 2和英伟达Ampere的缓存层次结构的简化草图
MALL的名称是有意义的,因为所有的VRAM访问都要经过它。RDNA 2的L2也是一个由整个GPU共享的缓存,但是如果虚拟内存页面被设置为非缓存,就可以绕过它。同步屏障也可以刷新L2以确保一致性。这些访问可以被RDNA 2上的无限缓存捕获,而以前的AMD GPU将从VRAM中提供服务。
因为L2应该足够大以捕获大量的内存访问,无限缓存的性能并不是那么重要,AMD在一个单独的时钟域上运行无限缓存。这意味着它可以调得更低以节省电力。
延迟
通过延迟测试,我们可以看到AMD复杂的四级缓存系统的运行情况。我们还可以看到英伟达更简单的两级缓存结构。Ampere的SMs具有更大的L1缓存容量,当RDNA WGP必须从较慢的每个SA L1缓存时,可以让SM服务请求从其第一级缓存。在较大的测试规模下,RDNA 2具有明显的延迟优势,特别是当测试规模溢出英伟达的L2时。
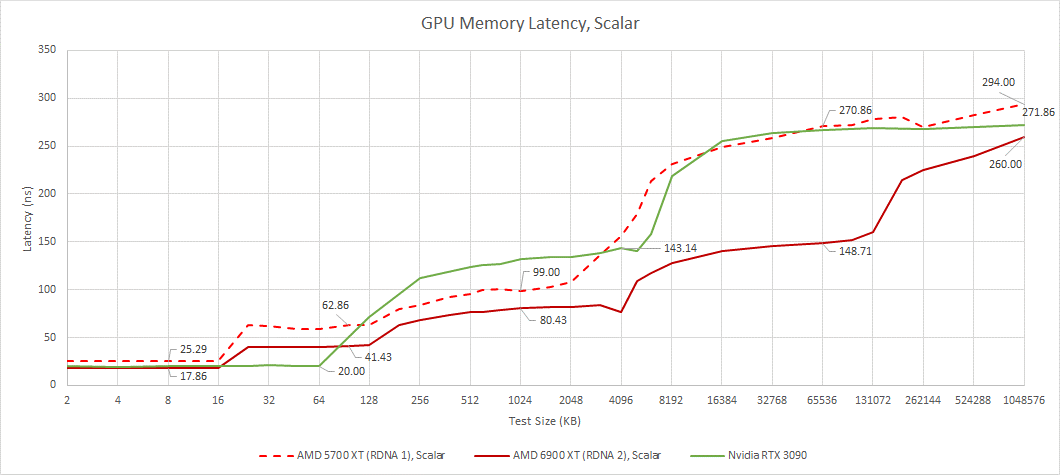
与 RDNA 1 相比,前三个缓存级别的性能提升较小,主要来自时钟速度的提高。然后 Infinity Cache 在更大的测试规模上产生巨大影响。对于如此大的缓存,延迟非常低。作为对比,RTX 3090 的 L2 有 140 ns 的延迟,但只有 6 MB 的容量。
无限缓存延迟也值得仔细研究。AMD 的 Adrenaline Edition 软件非常先进,可以让用户几乎任意设置最大时钟速度。我们可以使用它来查看缓存在 GPU 核心时钟变化时的行为。
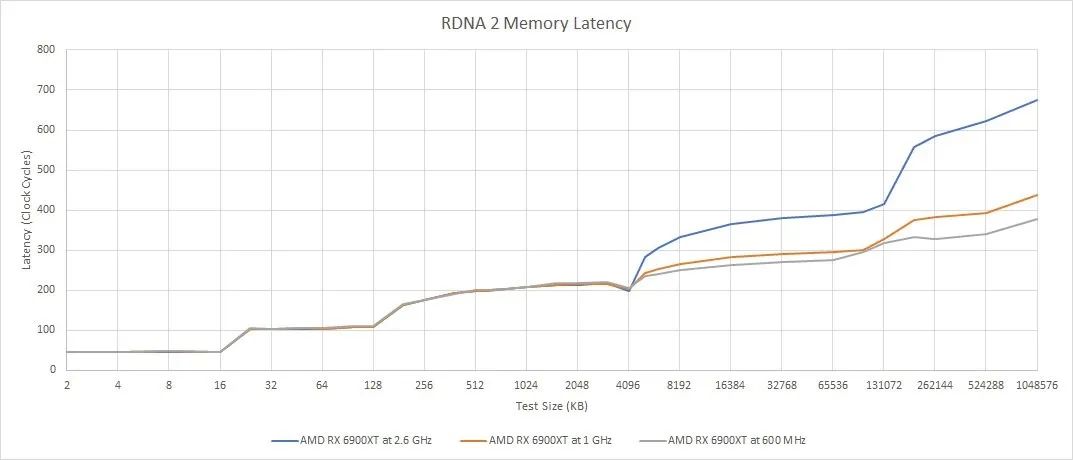
在较低的时钟下,RDNA 2 的 WGP 从 Infinity Cache 获取数据所需的周期更少。这可能意味着在较低时钟下提高着色器利用率。
从矢量方面,我们看到了同样的故事。RDNA 2 与速度更快的 RDNA 1 非常相似,带有一个额外的巨大缓存。矢量访问比标量访问延迟更高。Nvidia 没有单独的标量内存层次结构。他们的架构确实有常量缓存,但那些是只读的,并且比 AMD 的标量数据路径服务的用途更有限。
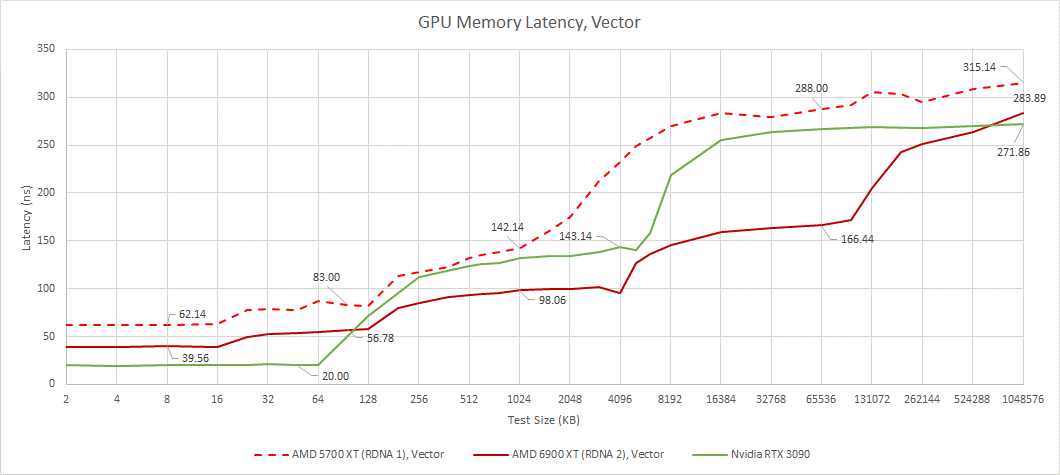
Nvidia 受益于较小测试规模的较低延迟,而 RDNA 2 在较大测试规模上保持优势。AMD 的 L2 和 Infinity Cache 延迟看起来非常好,考虑到 RDNA 2 必须检查比 Nvidia 更多的缓存级别。一旦我们到达 VRAM,情况就会逆转。
带宽
带宽也很重要,因为 GPU 旨在并行处理大量操作。让我们从查看单个工作组的带宽开始。运行单个工作组将我们限制在 AMD 上的单个 WGP,或 Nvidia 架构上的 SM。这是我们可以在 CPU 上获得的最接近单核带宽的值。与 CPU 上的单核带宽一样,此类测试并不特别代表任何现实世界的工作负载。但它确实让我们从单个计算单元的角度了解了内存层次结构。
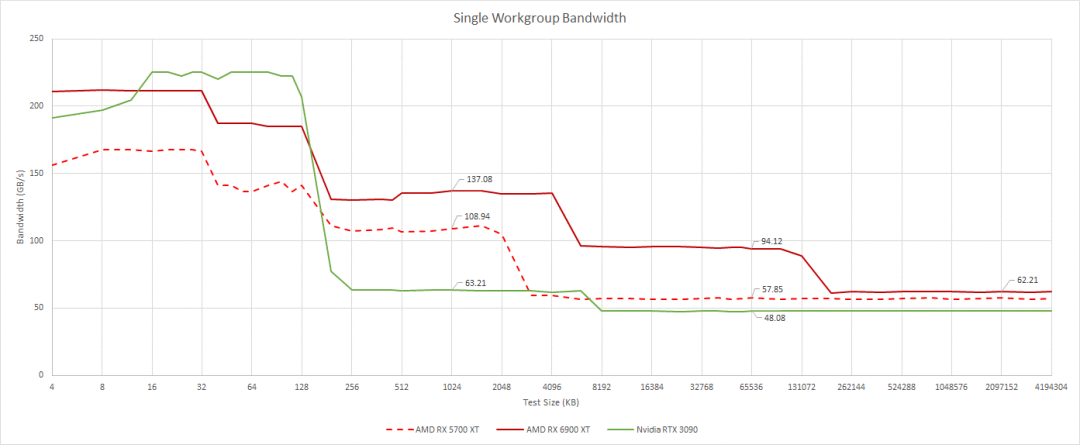
不评论第一级缓存带宽,因为由于地址生成和边界检查开销,这很难测试
通过一个WGP, RDNA 2通过高时钟实现了非常高的缓存带宽。这种优势在大型测试中尤其突出,其中128 MB无限缓存发挥了作用。AMD的缓存架构比英伟达的要好得多。在低占用时,即使是无限缓存也可以提供比安培L2更多的带宽。
随着我们使用更多的工作组和加载更多的WGP或SMs,带宽需求明显上升。这对共享缓存提出了更大的要求。AMD在这方面做得很好。L2带宽开始时非常出色,并且随着我们加载更多WGPs而扩展得非常好。在我们开始获得良好的带宽之前,我们必须在Nvidia的RTX 3090上加载更多的SM。
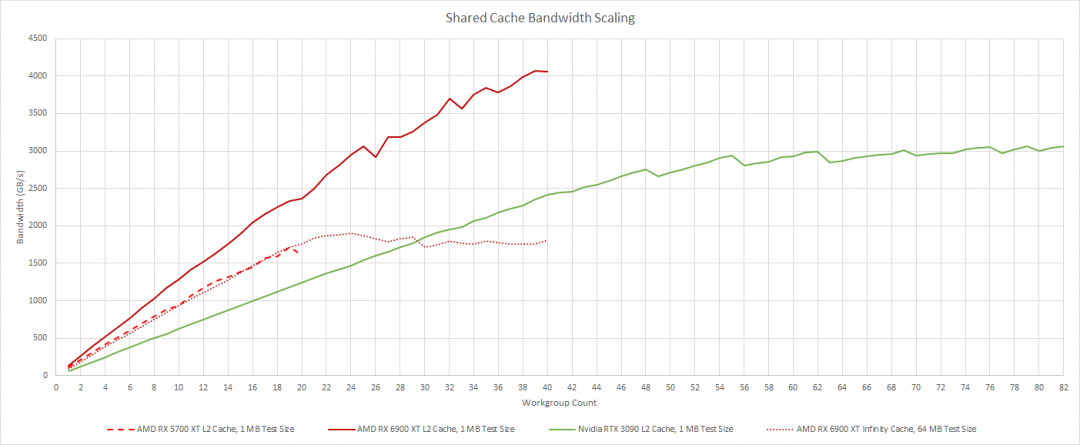
Infinity Cache 带宽扩展也非常好,实际上与 RDNA 1 的 L2 带宽非常接近。它无法与 Nvidia 的 3090 上的 L2 带宽相匹配,但它不需要,因为它前面的 4 MB L2 应该可以捕获大量访问。到目前为止,AMD 在缓存带宽方面看起来相当不错。然而,VRAM 是另一回事。
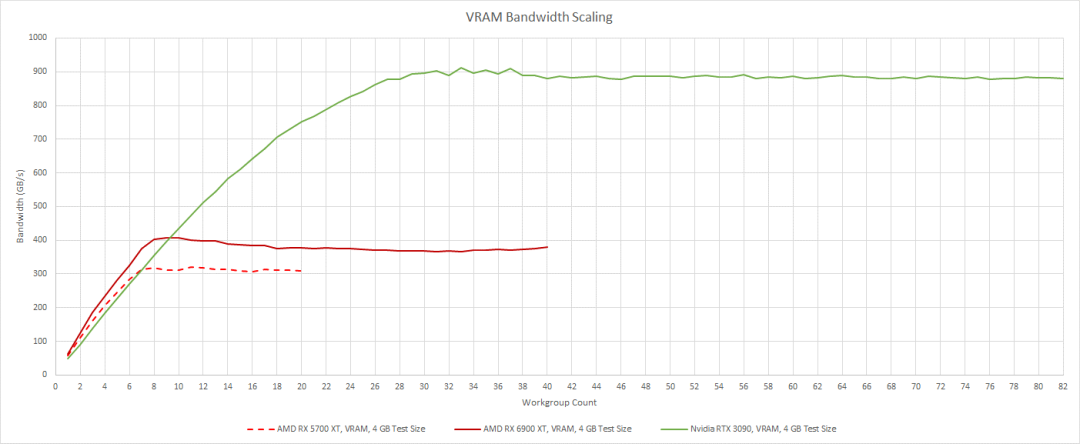
Nvidia 拥有巨大的 VRAM 带宽优势。对于高速缓存无法容纳的大量工作负载,Ampere 耗尽 VRAM 带宽的可能性要小得多。然而,两代 RDNA 都更善于利用它们拥有的 VRAM 带宽。他们不需要那么多的工作来充分利用他们的可用带宽。
CU 和 WGP 模式
AMD RDNA 架构中的 WGP 可以在 WGP 模式和 CU 模式下运行。在 WGP 模式下,128 KB LDS 用作单个统一内存块。WGP 中的所有四个 SIMD 都可以访问整个 128 KB。在 CU 模式下,LDS 被分成两个 64 KB 的一半,每个都与一对 SIMD 相关联。
LDS延迟在两种模式下保持相同,约为19.5 ns,即使CU模式应该简化来自LDS的请求路由。这同样适用于RDNA 1,它具有大约26.6 ns的LDS延迟。
LDS组织差异使我们能够通过使用单个工作组进行测试来命中单个CU(WGP 的一半)。因为每个CU都有自己的内存管道和L0缓存,所以当我们在WGP中只使用一个CU 时,我们会看到 L0 带宽下降。一旦我们到达 L2 之后,带宽就不会下降。
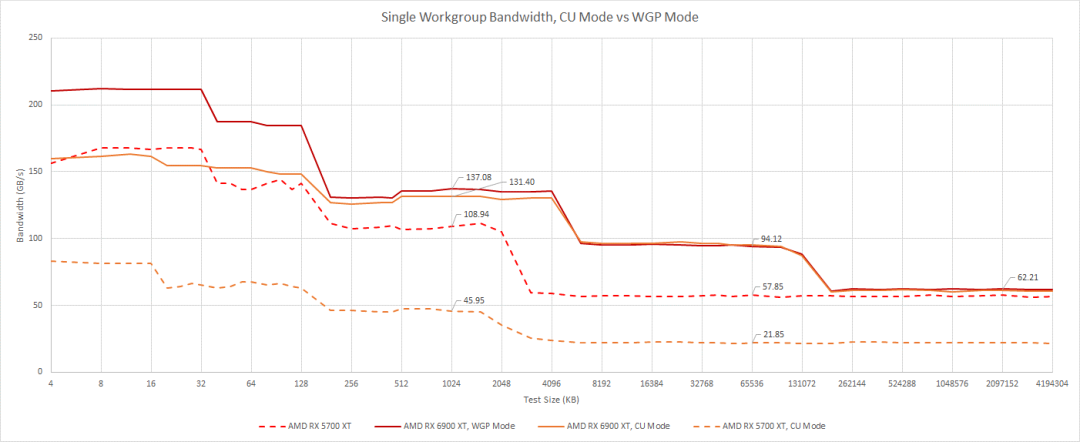
与RDNA 1相比,这是一个很大的改进,RDNA 1在缓存层次结构中看到了带宽的显著下降。带宽通常取决于队列隐藏延迟的能力,因此RDNA 2在分配队列条目方面可能更灵活。也许L1和L2之间的一些队列在RDNA 1中按CU分配,但在RDNA 2中按WGP分配。对于GPU工作负载,这意味着如果运行在WGP的一半中的波提前结束,RDNA 2会表现得更好。
从游戏的角度
RDNA 2 是游戏优先架构,所以让我们看看 RX 6900 XT 在这些工作负载中必须处理什么。研究游戏也将帮助我们了解游戏工作负载是什么样的。
赛博朋克2077,RT On
CD Projekt Red的《赛博朋克2077》是现代GPU技术的展示。它使用带有大量光线追踪的DirectX 12来提供丰富的图形效果。不幸的是,这些影响可能非常严重。光线追踪对性能的影响尤其大。请记住,这个游戏的数字是在GPU的最大时钟设置为1800mhz的一致性下获得的。3950X禁用了boost。因此,这里的数字不应被视为股票业绩数字,也不应与其他系统进行比较。我们只关注显卡在做什么工作。在这场比赛中,我们将沿着Jig Jig街向下看。
RT 相关工作占用大约 21 毫秒的帧时间。其中超过 9 毫秒用于构建 BVH,因此优化 BVH 构建时间几乎与优化 BVH 遍历一样重要。为了渲染光线追踪效果,6900 XT 必须进行 5.8 亿次方框相交测试和 1.095 亿次三角形相交测试。以达到的 25.9 FPS,即每秒 150 亿次盒子测试和 28 亿次三角测试。
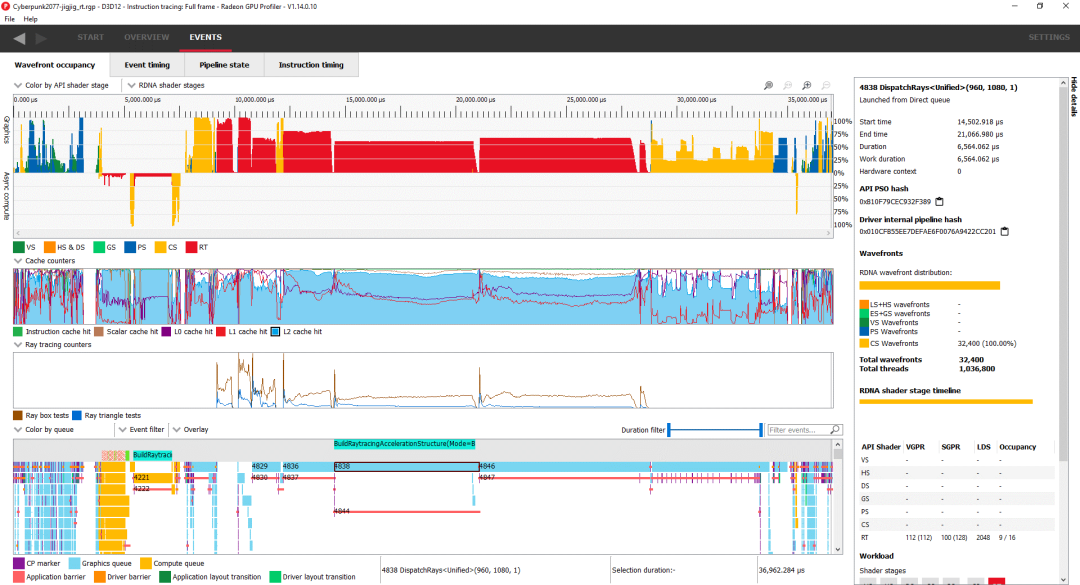
使用 Radeon GPU Profiler 检查帧。顶视图在渲染框架时显示占用情况
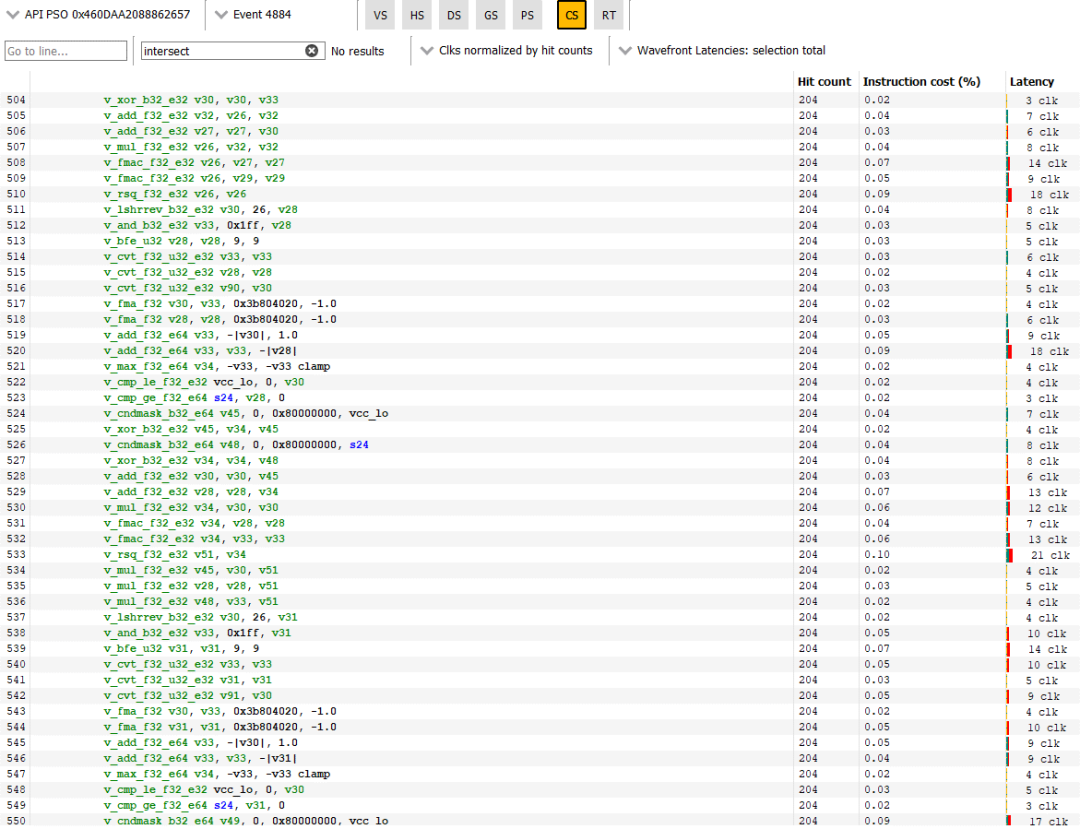
除了光线追踪,赛博朋克还大量使用计算。传统的光栅化退居二线,也许显示出尖端游戏的趋势。因为大部分时间都花在了光线追踪上,所以让我们从运行时间最长的 DispatchRays 调用开始仔细看看。具体来说,让我们看看单独使用 7.2 毫秒的那个:
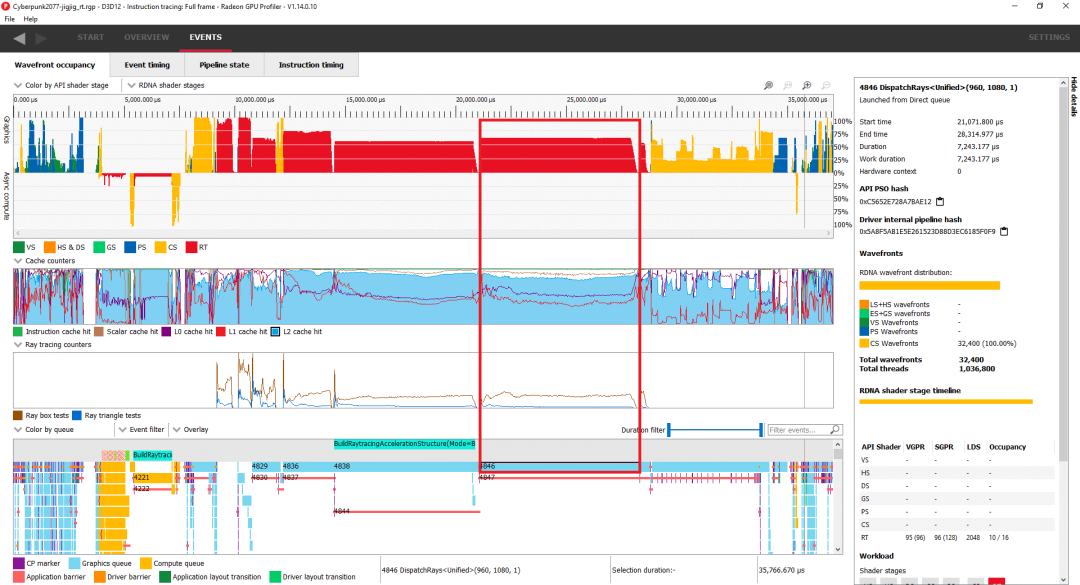
在我们正在查看的电话周围放一个方框 在内部,RDNA 2 将光线跟踪内核视为计算着色器。这个特定的调用启动了 32,400 个计算波阵面。6900 XT 的 40 个 WGP 总共可以保持 2560 个波面在飞行中,所以这足以填满整个 GPU。然而,RDNA 2 无法让这个内核的 2560 个波面保持在飞行状态,因为它没有足够的向量寄存器文件容量。与 CPU 不同,GPU 可以灵活地分配向量寄存器文件容量。为每个线程(波面)提供更多寄存器有助于防止寄存器溢出,但也会减少它可以保持运行的线程数量。
对于这个内核,编译器选择使用 96 个矢量寄存器,这意味着 RDNA 2 的矢量寄存器文件容量仅足以跟踪每个 SIMD 的 10 个波面,或者整个 GPU 中的 1600 个。一方面,这意味着每个 SIMD 都无法通过在一个停顿时在波面之间切换来保持执行单元忙碌。另一方面,使用更多的寄存器可以让编译器暴露更多的指令级并行性。从配置文件来看,RDNA 2 花费大量时间占用受向量寄存器容量限制,因此减少 RDNA 1的最大占用看起来是合理的。
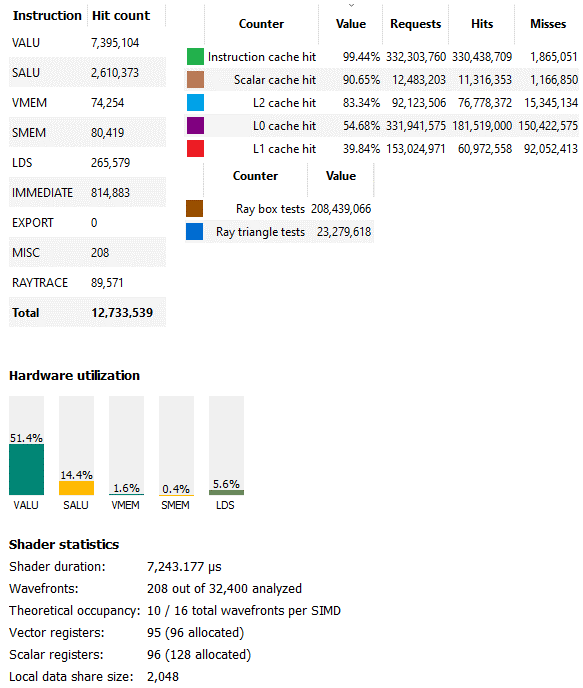
更多关于那次call的细节
在这种情况下,操作者可能做出了正确的权衡,或者至少没有做出糟糕的决定。51%的矢量ALU使用率处于一个良好的位置。着色器没有被充分利用。与此同时,利用率不会超过70-80%,这意味着只能使用计算方案。我们也看到少量的LDS使用。AMD使用LDS存储BVH遍历堆栈,使写入和延迟敏感的读取远离未优化的全局内存路径。其他光线跟踪调用显示了类似的硬件使用模式。
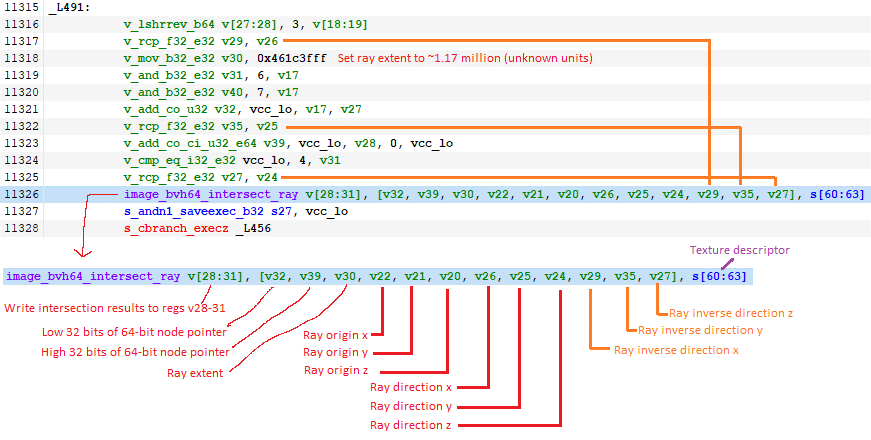
这是命中 RT 单元的着色器的基本块。着色器必须使用三个额外的指令来计算光线方向的倒数,并将其与光线方向一起提供。三个额外的指令并不多,但这些相互指令相当昂贵,并且与更简单的 FP32 操作相比只能以四分之一的速率执行。最重要的是,编译器必须使用三个额外的寄存器来保存反向光线方向。我不确定这会产生多大的影响,但还有改进的余地。
不幸的是,AMD 没有通过他们的分析工具公开 Infinity Cache 计数器。不过,我们还是可以看看前三级缓存是怎么做的。首先,L0 缓存命中率很差,略低于 55%。即使在 Bulldozer 等低于标准的实现中,CPU 通常也能看到超过 80% 的一级缓存命中率。128 KB 的中级缓存有助于捕捉其中的一些未命中,使累积的 L0+L1 命中率略低于 73%。我在这里的印象是L0和L1缓存太小了。4 MB L2 是这里的英雄,在进入更高延迟的 Infinity Cache 之前将累积命中率提高到 95.4%。
RDNA 2 的 16 KB 标量缓存实现了相对较好的命中率,刚好超过 90%,更重要的是从向量路径卸载了一些请求。从指令方面看,L1i 的命中率超过 99%。GPU 程序的指令足迹似乎比 CPU 程序小,32 KB L1i 似乎足够了。
BVH建筑
RGP 将几个部分注释为对构建BVH的BuildRaytracingAccelerationStructure的调用。如前所述,这些部分占用了很大一部分光线追踪时间,所以让我们也看看其中的一个。最长的一个是调用号 4838,奇怪的是它是一个 DispatchRays 调用并显示交叉测试活动。我不确定那是什么意思,所以我将转到第二长的那个。
调用4221对应于CmdDispatchBuildBVH,在计算队列中运行。它的占用率很低,因为只有160个波阵面发射。这远远不足以填满GPU,所以这部分可能会受到延迟的限制。同步障碍阻止GPU使用异步工作来保持执行单元繁忙。幸运的是,这部分只持续1.7毫秒。
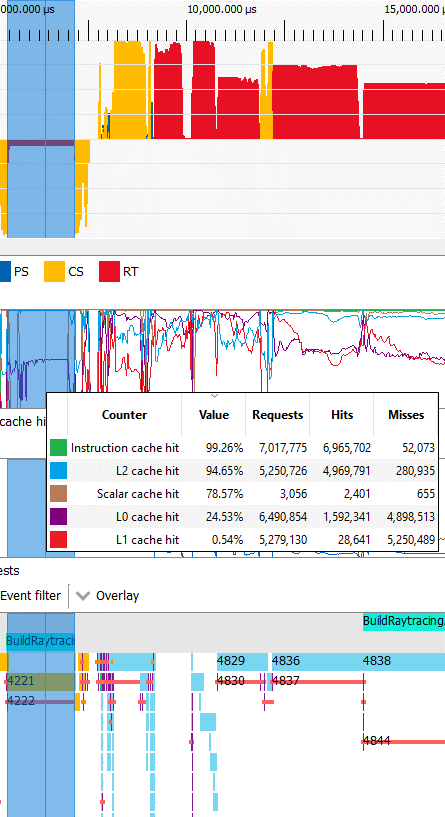
与上面介绍的光线遍历部分不同,AMD 的驱动程序选择在这个 BVH 构建部分使用 wave64 模式。我怀疑这是最好的选择。wave32 模式在占用率低的情况下应该更可取,因为它允许更多的线程级并行性。但 AMD 可能有充分的理由使用 wave64,所以我将不再是一个纸上谈兵的四分卫,而是转向缓存。
和以前一样,指令缓存命中率非常高。标量缓存没有足够的标量内存访问。在向量方面,16 KB L0 的性能非常差,命中率低于 25%,而 128 KB L1 也可能不存在。RDNA 的 L2 最终服务于大部分内存流量,并且以比光线遍历部分更极端的方式。由于占用率很低,L0/L1 缓存命中率很低,L2 延迟很可能成为构建 BVH 时的限制因素。
计算
除了光线追踪(技术上被视为 RDNA 上的一种计算形式)之外,《赛博朋克 2077》还大量使用了计算着色器。该游戏中的非光线追踪计算往往包含大量持续时间较短的调用,而不是一些非常繁重的调用。持续时间最长的计算调用(编号 4473)是为 wave32 模式编译的,运行时间不到 0.7 毫秒。RDNA 2 午餐吃这个。着色器不使用大量矢量寄存器或 LDS 空间,并启动 130,560 个波前。因此,入住率非常好。
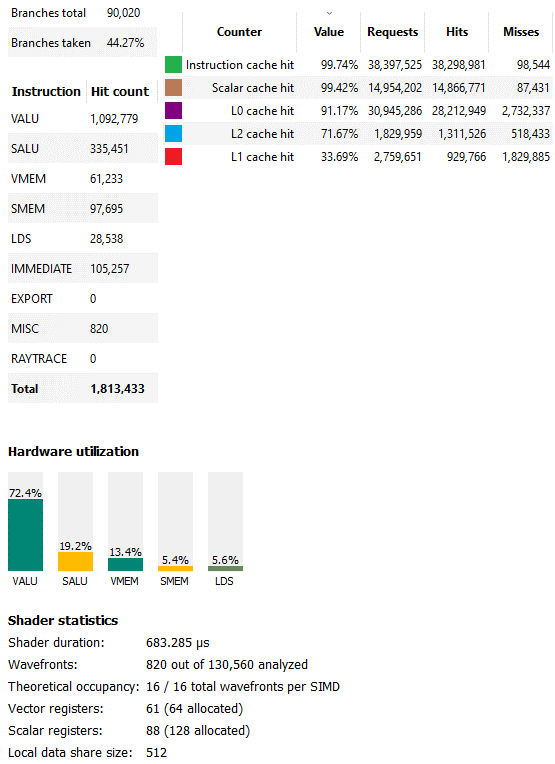
矢量ALU的利用也很好。事实上,这简直太好了。再高一点,我们就称这部分为有限计算。RDNA 2的标量数据路径在卸载应用于波前的计算中起着关键作用。缓存命中率也有助于良好的计算利用率。大约94%的向量访问是由L0和L1缓存提供服务的,其中大部分来自L0。L2使累积命中率超过98%。L1指令缓存和标量缓存的命中率如此之高,以至于失败基本上是噪音。对于这个着色器,良好的缓存命中率和高占用率结合起来让RDNA 2发光。
第二长的计算着色器(编号4884)运行了不到半毫秒,并表现出不同的特征。它使用的是wave64,并且占用被矢量寄存器文件容量限制为每个SIMD只有四个波。尽管如此,RGP仍然报告了非常好的VALU利用率。这可能是因为这个内核绝大多数由矢量ALU指令组成。没有太多的内存访问,而且大量的内存访问确实会发生在标量路径上。
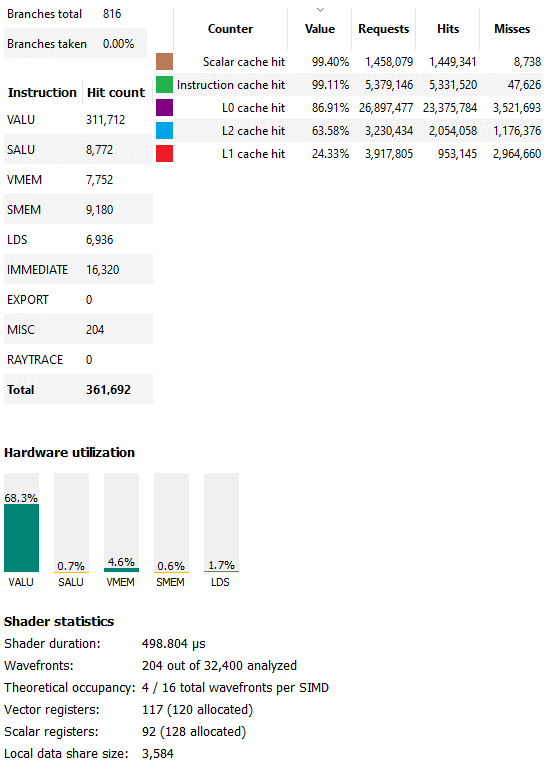
此外,这个计算着色器的分支很少,RGP 没有选择任何已采用的分支。GPU 上的分支非常昂贵,GPU 没有分支预测并且必须暂停线程直到分支条件得到解决。没有采取的分支也意味着分歧不是一个大问题。总的来说,这个着色器主要由直线 FP32 spam组成。GPU 喜欢这些东西。RDNA 2 也不例外,尽管占用率低,但硬件利用率非常好。
赛博朋克 2077,RT关闭
光线追踪效果很酷,但Cyberpunk 2077在关闭 RT 的情况下看起来仍然非常好。如果美术师和开发人员擅长他们的工作,传统的光栅化仍然可以渲染出令人印象深刻的场景,而 CP2077 的工作人员似乎绝对能胜任这项任务。
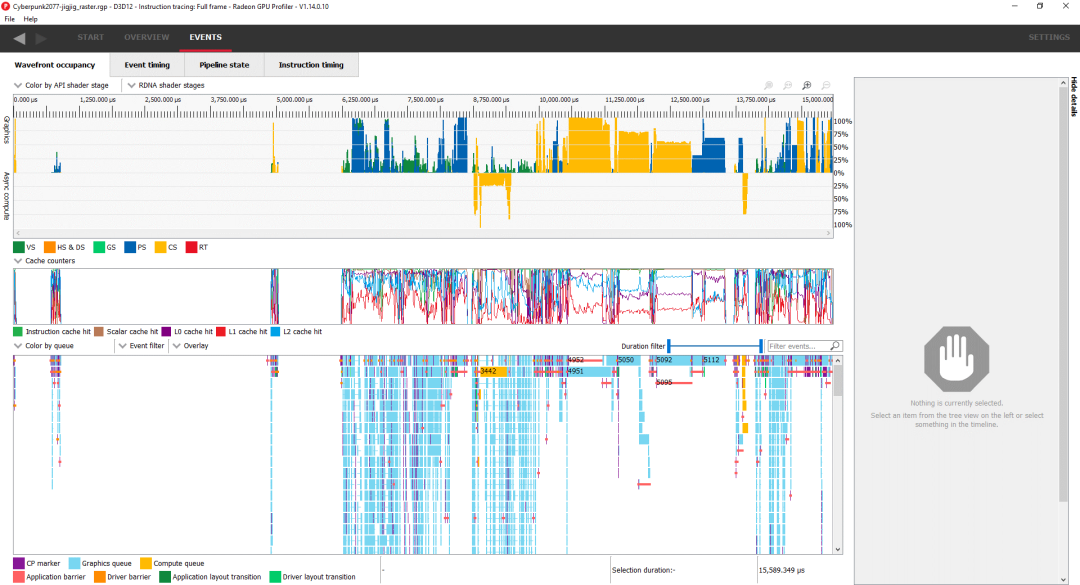
开头附近的大量空白区域没有 GPU 活动表明我们受 CPU 限制
如果没有光线追踪,传统的顶点和像素着色器就会介入并发挥更大的作用。然而,该游戏仍然大量使用计算着色器,并且异步计算也出现了。三个持续时间最长的调用都是计算的,总结如下:
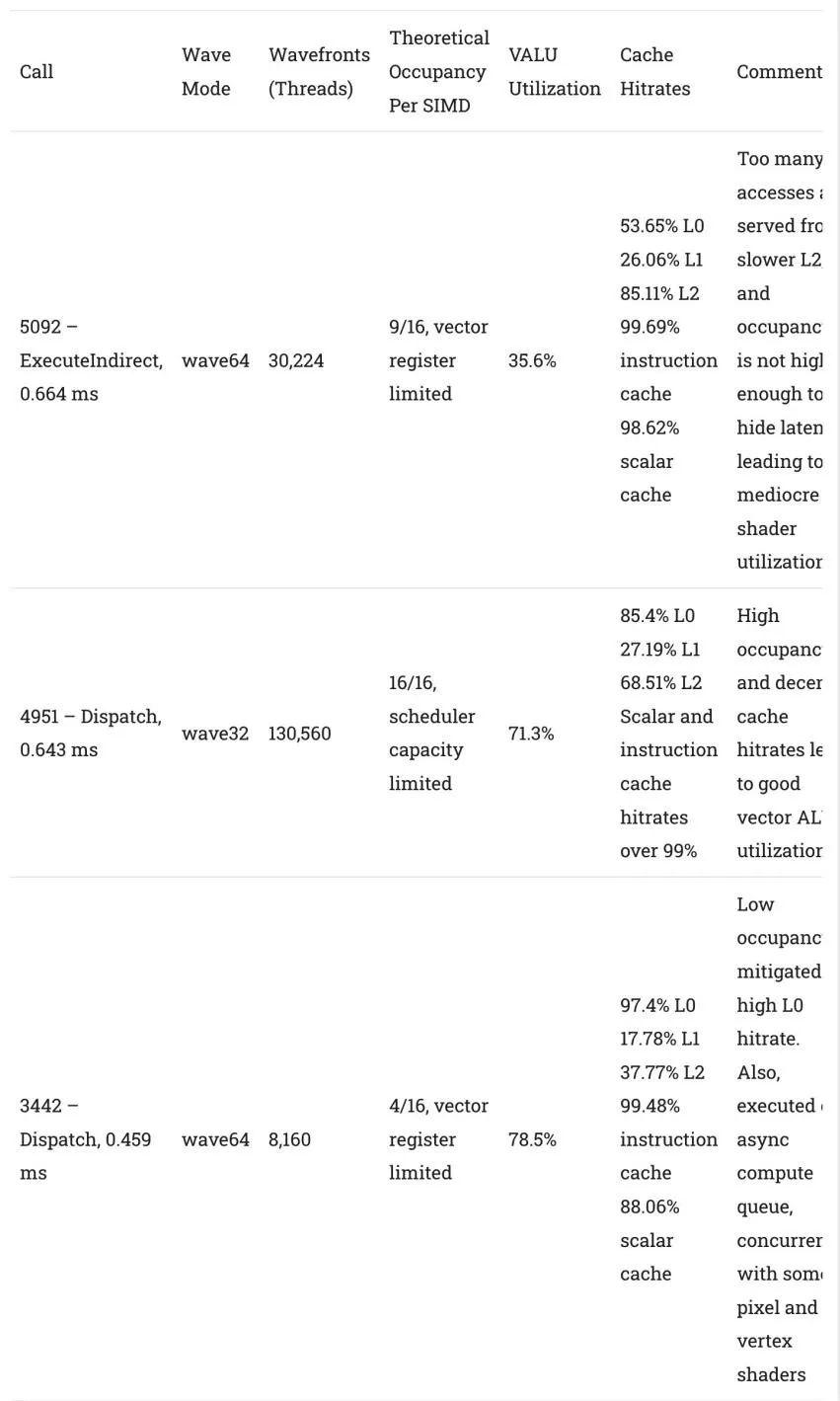
比较三个最长的GPU调用,这三个都是计算着色器
RDNA 2在这些计算内核中表现非常好,即使对于运行时间最长的内核来说,利用率处于较低的水平。矢量寄存器文件容量继续限制架构可以利用的并行性,但这个问题并不是AMD独有的。在缓存方面,128 KB L1通常表现不佳。我们看到256 KB的中级缓存对于cpu来说已经很普通了。GPU缓存就更难了。一次又一次,RDNA 2的L1错过的比命中的多。我很高兴AMD选择在RDNA 3中增加L1缓存容量。好的一面是,标量缓存和指令缓存的命中率继续保持良好。
光栅化
与光线追踪不同,传统的栅格化管道非常高效。光栅化可以使用简单的计算将3D点映射到2D屏幕空间,而不是到处发送光线并观察它们击中了什么。然后,GPU使用固定功能硬件将工作分配到像素着色器,这些着色器决定这些像素应该是什么颜色。像以前一样,让我们看看CP2077中几个最长的栅格化调用。
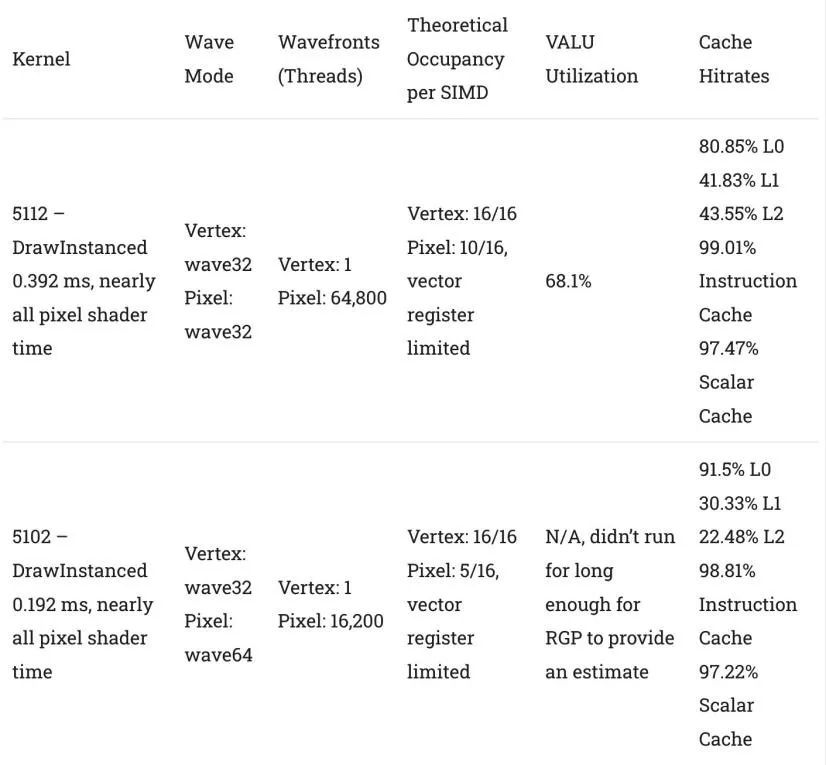
通过栅格化工作,L1缓存的显示更加可信。hitrate仍然不是很好,但在某些情况下,它可以捕捉到足够多的L0错误,以确保绝大多数请求不需要从L2或更高的地方得到满足。这可能是一个很大的优势,因为L1的延迟和带宽特性比L2要好得多。
还有一组顶点着色器工作靠近帧的开始。这很难分析,因为有大量的微小呼叫,但窥探一些显示,它们通常每次发射不到100个波阵面。从我们的延迟和带宽缩放测试来看,RDNA 2在低占用率的情况下表现非常出色,可能比英伟达的Ampere更好地应对这些呼叫。
泰坦尼克荣誉与荣耀,Megademo 401(光栅化,4K)
拥有数百万美元预算的大型工作室能够制作出具有深刻故事情节和令人印象深刻的视觉效果的复杂游戏。但他们并没有垄断乐趣,独立创作者用较小的预算也可以创造出沉浸式和视觉上令人惊叹的东西。其中一个例子就是正在进行中的《泰坦尼克号荣誉与荣耀》项目,该项目专注于用3D技术重现泰坦尼克号。它使用虚幻引擎,并使用DirectX 12运行。
与许多独立游戏一样,开发者花在优化上的时间和资源较少。但也许是因为它还没有经过优化,演示文稿的细节水平令人惊叹,即使在现代GPU上也非常沉重。
在这里,我们俯视头等舱休息室,游戏以 4K 分辨率运行,GPU/CPU 时钟设置如前。像素着色器主导此工作负载,但计算着色器也发挥作用。异步计算使用率极低,几乎所有调用都发生在图形队列上。
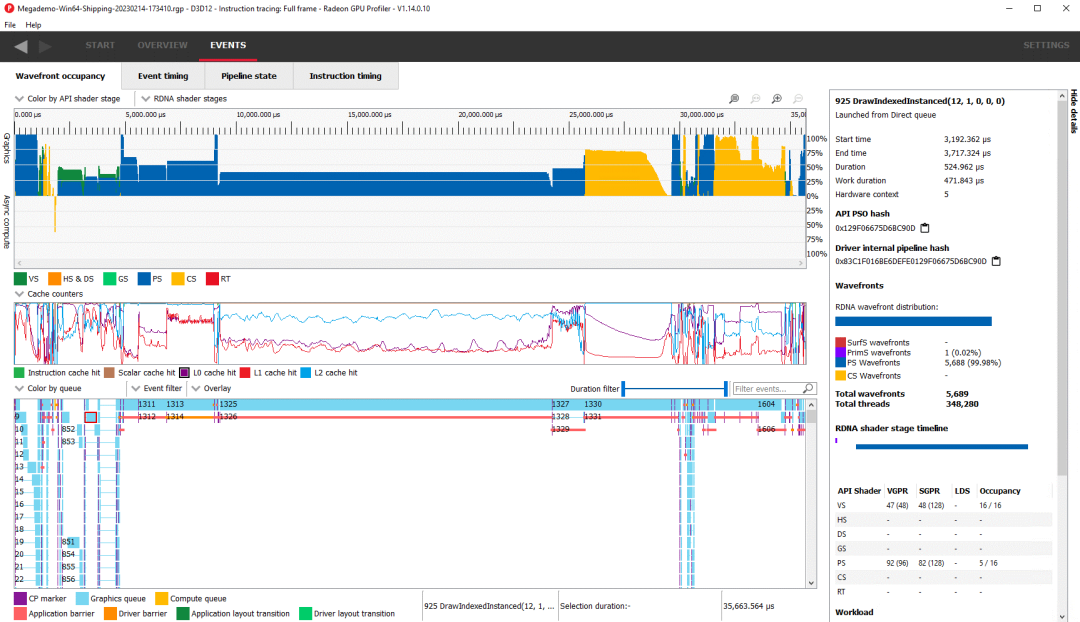
最长的调用是事件 1325,一个以 wave64 模式运行的像素着色器。它发射了 129,652 个波前,或足以覆盖 4K 分辨率下的每个像素的波。由于向量寄存器文件的限制,占用率很低。向量 ALU 的利用率也很低,这可能是由于占用率低和缓存命中率一般。
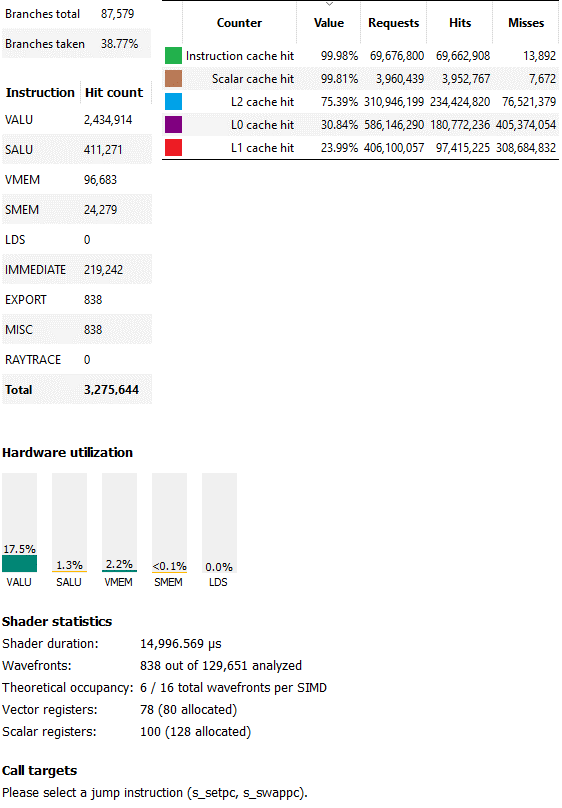
长时间运行的像素着色器的分析器统计信息
事件 1330 是第二长的调用,是一个启动 16,320 个 wave32 波前的计算着色器。占用率再次受到向量寄存器文件的限制,但这次每个 SIMD 有 12 个波更好。着色器实现了 27.7% 的矢量 ALU 利用率,这是可以接受的,但仍然偏低。L0 命中率还不错,为 59.69%,而 L1 命中率低得令人尴尬,只有13.11%。幸运的是,二级缓存以 99.82% 的命中率挽救了局面。计算利用率应该真的更好,因为每个 SIMD 12 个 wave 并不是很糟糕的占用率。但仔细观察就会发现另一个问题。工作在线程之间分布不均,有些线程先于其他线程完成。
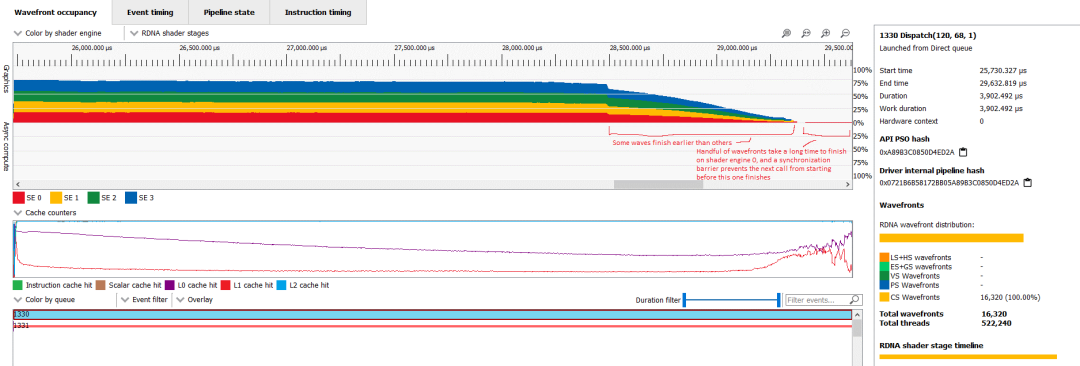
放大该计算着色器,添加注释并将着色设置为着色器引擎
显然,下一个调用需要计算着色器写入的数据,因此同步屏障会阻止它执行,直到计算着色器中的所有线程都完成执行。最后,这意味着许多 6900 XT 的 WGP 处于空闲状态或没有足够的线程级并行性来有效隐藏延迟。这对任何 GPU 来说都不是很好,但 RDNA 2 的高时钟速度和在低占用率下更好的处理应该让它比 Nvidia 的 Ampere 更好地应对。
通过 THG,我们可以看到 DirectX12 在光栅化方面的作用。它不像《赛博朋克 2077》那样进行光线追踪,但两种工作负载的缓存行为惊人地相似。
枪手,热火,PC
Gunner, HEAT, PC (GHPC) 是坦克模拟独立游戏。它旨在准确描绘冷战后期坦克上的火控系统和传感器,同时比 DCS 之类的东西更容易获得。与 THG 演示不同,GHPC 使用 Unity 引擎并运行 DirectX 11。不幸的是,AMD 的分析器不支持 DirectX 11。我使用 PIX 来分析游戏。但这一直很烦人,因为 PIX 有一个令人讨厌的习惯,即它自己和它试图分析的游戏都会崩溃。
GHPC 绝大多数使用传统的像素和顶点着色器。我在 4K 下运行游戏,所以毫不奇怪,有很多像素着色器工作。使用计算着色器。但与上面的 DirectX 12 工作负载不同,它们所起的作用非常小。
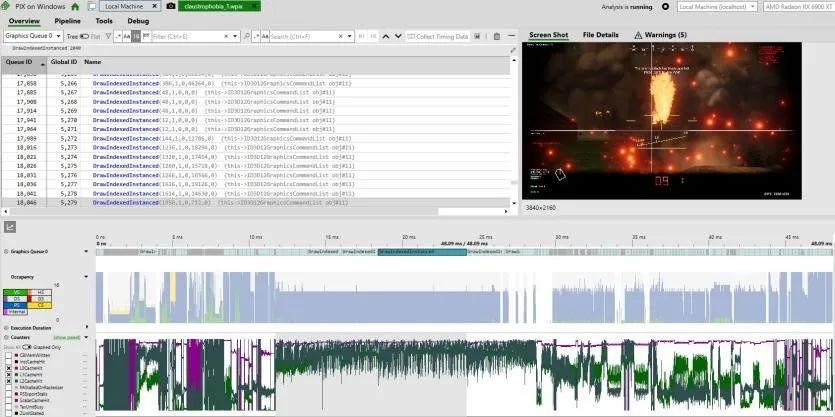
GHPC 运行时间最长的像素着色器比 THG 的缓存友好得多。我们看到超过 90% 的 L0 命中率。L1 命中率最终在 70-80% 之间非常出色,L2 命中率在 90% 以上和 60% 左右之间波动。标量和指令缓存命中率基本上是 100%。不幸的是,PIX 没有显示有关执行单元利用率的指标,但我希望它非常好。那是因为游戏往往会使卡产生大量热量,即使在低于标准时钟速度时也是如此。幸运的是,PIX 确实公开了比 RGP 多得多的计数器,因此我们可以研究光栅化管道的其他方面。
长时间运行的像素着色器受计算限制,似乎要处理绘制烟雾效果。框架早期的调用主要处理绘图对象,如房屋和道路。因为这些调用很短,而且经常相互重叠,所以我们看到一些光栅化瓶颈出现了。“PAStalledOnRasterizer”意味着图元组装器生成图元的速度快于光栅化器处理它们的速度。这可能表明光栅化器或之后的任何地方存在瓶颈。
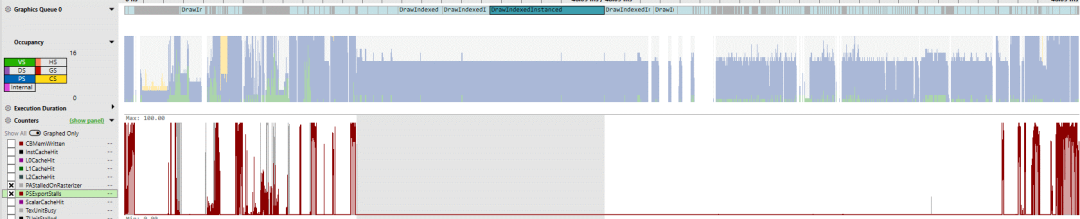
PAStalledOnRasterizer 为灰色,PSExportStalls 为红色
另一个指标是“PSExportStalls”,它表示像素着色器程序何时计算了颜色信息,但光栅化管道中的最后阶段还没有准备好接受数据。罪魁祸首之一是Z单元,它进行深度测试以确保只显示未被遮挡的像素。例如,如果坦克的一半位于房屋后面,则 Z 单元部分将确保房屋的像素显示在最终帧中。如果来自许多不同对象的大量像素必须经过这种深度测试,Z 单元可能很难跟上。
但回过头来看,最大的性能罪魁祸首肯定是烟雾和阴霾效果。绘制这些效果占用的 GPU 时间最多,并且像素着色器操作非常繁重。在这些着色器期间,纹理单元几乎一直处于活动状态,因此也可能存在纹理瓶颈。
缓存评论
长期以来,GPU缓存一直落后于 CPU 缓存。在 2000 年代初期,GPU 没有通用缓存层次结构。他们确实有专门的缓冲区,但在大多数情况下,他们依赖于显式并行和高带宽内存设置。到 2000 年代后期,内存带宽限制促使 GPU 采用缓存。这些往往比 CPU 缓存小得多,两级缓存设置是常态。CPU 大约在那个时候转向三级设置,以便通过高核心数和大型共享缓存保持性能。

曾几何时,在 Geforce 4 时代,GPU 缓存是不切实际的。哦,时代变了……
RDNA 2 通过采用比我们在大多数 CPU 上看到的更复杂和更高容量的缓存层次结构来扭转一切。它使用令人难以置信的四级缓存,最后一级缓存有 128 MB 的容量。相比之下,即使是 AMD 的 VCache CPU 也只有 96 MB 的末级缓存,并且使用三级缓存设置。
就像 CPU 一样,DRAM 技术也在努力跟上 GPU 性能的提升。但与 CPU 不同的是,GPU 对延迟不太敏感,这使得这种缓存设置变得实用(延迟似乎是 L4 缓存不受 CPU 欢迎的主要原因)。很高兴看到 GPU 全面发展并比 CPU 更频繁地使用缓存。
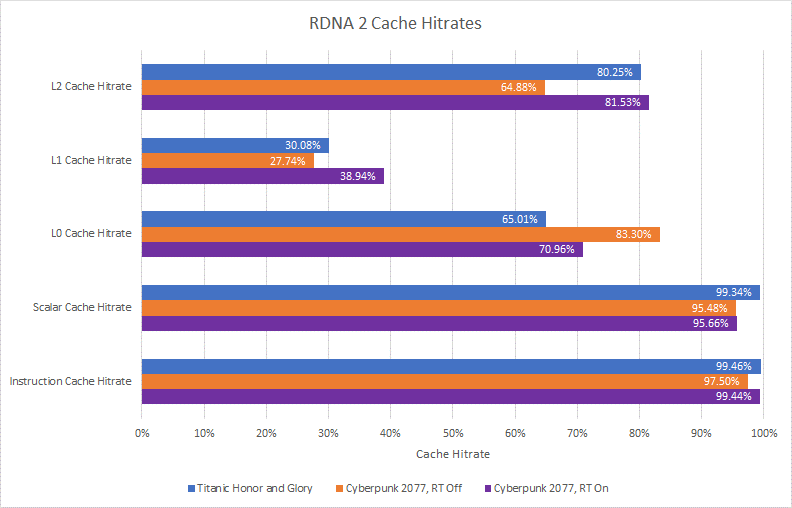
整体命中率,对于整个帧的所有访问
但是更复杂的缓存设置不一定好。更多级别的缓存意味着您可能会检查更多标签的命中。如果缓存级别没有捕获大量内存访问,它最终可能会延迟对数据最终来自何处的访问。因此,RDNA 2 的 L1 缓存令人失望,与其他缓存级别相比命中率较低。它要么需要变得更大,要么应该放弃以支持更大的 L0 缓存。
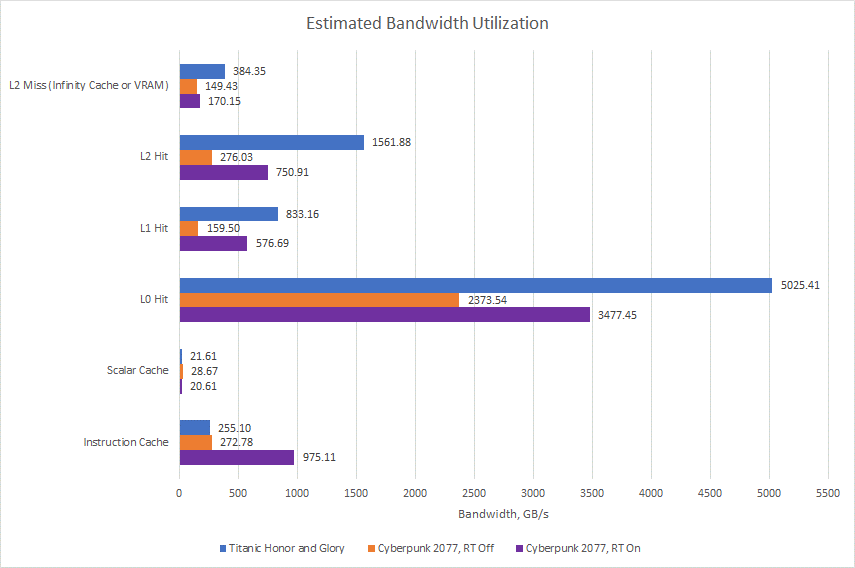
假设每个标量缓存访问都获得一个 64 位值。让我们暂停片刻,欣赏 GPU 缓存必须处理的海量数据。
缓存还有助于提高带宽,这对 GPU 来说更为重要。L1 缓存确实减少了进入 L2 的流量,但我怀疑 L2 是否需要这种帮助。AMD 的 RX 6900 XT 已经拥有大量的 L2 带宽,甚至与 Nvidia 更大的 RTX 3090 相比也是如此。因此,L1 最终仅用于整合来自多个 WGP 的请求,从而简化了 L2 路由。
缩小范围,我们可以查看请求计数,乘以请求大小,然后乘以实现的帧率,以估计 GPU 从其缓存中提取了多少数据。L0 缓存每秒提供数 TB 的数据,如果我以标准时钟运行我的 6900 XT 而不是将其限制在 1800 MHz,这个数字会更高。即使在 L2,我们也看到超过 1.5 TB/s 的带宽需求。没有数兆字节缓存的现代 GPU 将非常缺乏带宽,即使我们为它提供像 Nvidia A100 上那样的六堆栈 HBM2E 设置。
游戏趋势
从我看过的一小部分游戏来看,计算似乎正在发挥更大的作用。计算着色器在 Cyberpunk 2077 中尤为突出,这是一款以大量预算开发的现代 AAA 游戏。我将光线追踪视为一种计算形式。RDNA 2 将光线追踪视为计算。我不确定 Nvidia 做了什么,但 Pascal 使用计算着色器处理光线追踪。即使没有光线追踪,赛博朋克也会在传统光栅化的同时使用大量计算。
预算较小的独立游戏往往更强调光栅化管道,但仍会利用计算。他们这样做的程度可能在很大程度上取决于游戏引擎,因为独立开发者通常没有时间从头开始创建自己的游戏引擎。Titanic Honor and Glory 使用的 Unreal Engine 具有大量计算能力。GHPC 使用 Unity 引擎,计算量很小。虽然传统的光栅化管道仍然非常重要,但我们可能会看到它越来越多地在新游戏中得到计算的补充。
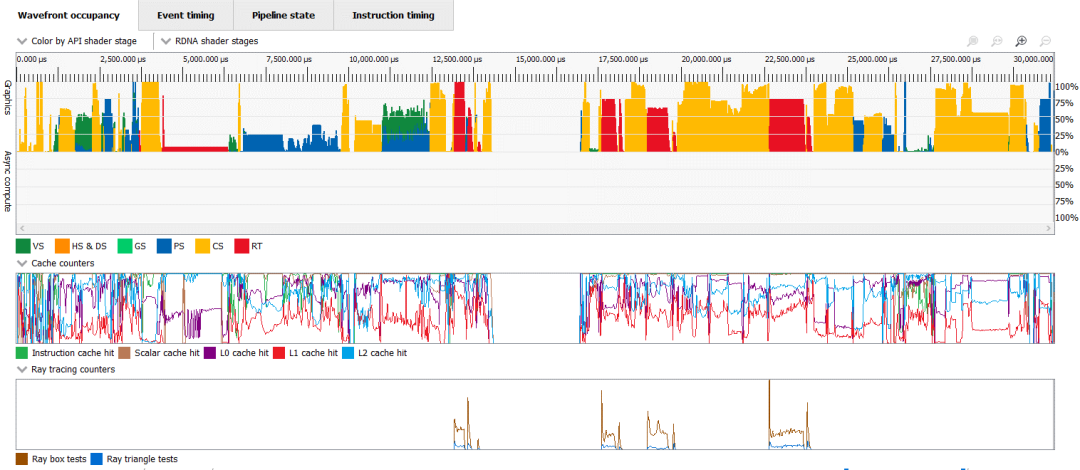
对虚幻引擎的城市演示中的帧进行分析,显示大量使用计算和光线追踪
因此,现代视频卡需要具有良好的计算能力,而 RDNA 2 不会让人失望。它可能没有 Nvidia 的 Ampere 架构的大量 FP32 吞吐量,但它处于更好地利用其现有执行单元的有利位置。
结论
RDNA 2 对 AMD 来说是一个重要时刻。在过去十年左右的时间里,Nvidia 普遍主导着高性能 GPU 市场。AMD(和 ATI)偶尔会生产出可以与 Nvidia 的最佳产品正面交锋的显卡,但这种情况似乎永远不会持续很长时间。基于 RDNA 2 的 RX 6900 XT 就是其中之一,其重要性与基于 Terascale 2 的 HD 5800 相同。Terascale 2 提供了 Nvidia Fermi 卡的大部分性能,但功耗要低得多。同样,RDNA 2 提供了 Ampere 的大部分性能,但电源效率更高。至少部分原因在于 RDNA 2 对缓存的使用,而不是大型 GDDR6X 设置。因此,RDNA 2 代表了 GPU 缓存策略的转折点。
该缓存设置以另一种方式使 RDNA 2 具有重要意义。它代表了 GPU 缓存策略向优先考虑一般计算性能的转折点。滥发更多的着色器,然后构建一个巨大的 VRAM 子系统来提供它的日子似乎已经一去不复返了。这同样适用于基于图块的渲染,它试图通过优化光栅化顺序来优化缓存占用空间。随着计算变得越来越重要,基于光栅化的技巧开始产生较小的影响。与 CPU 一样,答案似乎是更多缓存。AMD的下一代GPU架构,RDNA 3采用了类似的四级缓存子系统。Nvidia 同样正在摆脱对巨大 VRAM 配置的依赖。Ada Lovelace大大增加了 L2 缓存容量,RTX 4090 获得了 72 MB 的 L2。即使更大的 GDDR6X 设置或 HBM 可以提供足够的带宽来仅使用 4 MB 或 6 MB 的缓存,这样的解决方案也会太耗电或太昂贵。
RDNA 2 还为 AMD 的 GPU 阵容带来了硬件光线追踪加速。与 Nvidia 的全力以赴的方法相反,AMD 可能试图以最低的硬件成本获得可接受的性能。我认为这是一个明智之举,因为常规计算和光栅化仍然主导着很多工作负载,并且绝对不需要光线追踪来产生良好的视觉效果。此外,即使 GPU 功率和裸片面积达到极限,未来的光线追踪工作负载也不太可能通过当今的技术实现。那是因为我们离使用纯光线追踪渲染 AAA 标题还差得很远,即使是有限的光线追踪效果也会带来如此大的性能损失,以至于 Nvidia 和 AMD 求助于使用升级技术。
但重要的是,RDNA 2 的光线追踪实现为 AMD 提供了一些可以构建的东西。缓存设置也是如此。在为未来的成功奠定基础方面,RDNA 2 几乎与 RDNA 1 相似。
审核编辑 :李倩
-
详解AMD RDNA2 GPU架构设计方案2023-03-08 3049
-
AMD RDNA2 GPU架构扩展技术详解2023-02-23 4884
-
AMD的RDNA3架构详细细节2021-01-24 4983
-
AMD即将推出RDNA3架构显卡2021-01-05 2802
-
RDNA2架构的6900XT下个月即将发布2020-11-20 5804
-
特斯拉盯上AMD,欲把RDNA2架构用于车载系统2020-11-10 2331
-
AMD宣布了Ryzen ZEN3处理器和Radeon RDNA2 GPU的主题演讲日期2020-09-27 2880
-
AMD首个RDNA 2 架构 GPU市场成为AI必争地2020-03-21 5278
-
AMD模糊RDNA3架构显卡工艺的说法2020-03-11 2863
-
AMD确认索尼和微软新主机均支持基于RDNA2架构的光追2020-03-07 2685
-
AMD苏姿丰宣布采用RDNA2构架能效比将获大幅提升2020-03-06 2422
-
AMD或在CES2020展会上宣布RDNA2架构 再次用上HBM2显存2019-11-19 1286
全部0条评论

快来发表一下你的评论吧 !
