

有关中位数计算是什么
描述
一.项目背景
中位数是数理统计中一个重要的指标,它可以自动忽略数据极差带来的影响,
能够很好的评估数据,在数理统计中很常用。本文主要介绍在Python中和Mysql
中如何来求中位数,重点让大家掌握SQL计算中位数,也是面试常考题目之一。
二.实现过程
1.Python实现
》》创建DataFrame
》》分组计算中位数
import pandas as pd
#创建DataFrame
data=pd.DataFrame(
{ 'company':['A','A','A','A','B','B','B','B','B'],
'salary':[1057,1874,2059,2268,6587,6637,6932,7415,7654]
})
#输出分组统计值
print(data.groupby('company')['salary'].median().reset_index().rename({'salary':'median_salary'},axis=1))
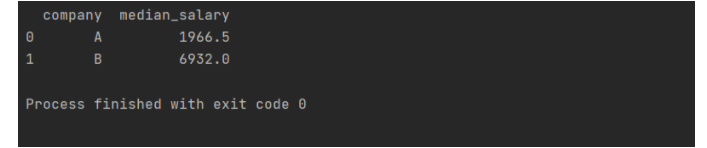
2.SQL实现
》》统计字段长度
》》按照奇偶长度分别计算字段一半
》》按照字段排序统计顺序
》》筛选所需字段并计算
建表语句:
mysql> create table median_val(
-> company varchar(20),
-> salary int)
-> engine=innodb default charset=utf8;
Query OK, 0 rows affected, 1 warning (0.07 sec)
插入数据:
mysql> insert into median_val(company,salary) values("A",1057),("A",1874),("A",2059),("A",2268),("B",7415),("B",7654),("B",6932),("B",6587),("B",6637);
Query OK, 9 rows affected (0.06 sec)
Records: 9 Duplicates: 0 Warnings: 0
计算中位数:
mysql> select
-> company,
-> round(avg(salary),1) as median_salary
-> from
-> (select
-> company,
-> salary,
-> count(*) over(partition by company) as num_length,
-> row_number() over(partition by company order by salary) as ranking,
-> count(*) over(partition by company) /2 as num_company_even,
-> ceil(count(*) over(partition by company) /2) as num_company_odd
-> from
-> median_val)a
-> where
-> (mod(num_length,2)=0 and ranking in (num_length/2,num_length/2+1))
-> or
-> (mod(num_length,2)=1 and ranking=ceil(num_length/2))
-> group by
-> company;
+---------+---------------+
| company | median_salary |
+---------+---------------+
| A | 1966.5 |
| B | 6932.0 |
+---------+---------------+
2 rows in set (0.00 sec)
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
TC377波特率计算是否与帧大小有关?2024-01-22 597
-
ads1256有效位数怎么计算?2024-11-22 716
-
有关中断代码的疑问2009-06-14 3724
-
请问能否讲解有关中断向量表的知识?2019-05-17 1752
-
边缘计算是指什么?边缘计算的最大优势是什么2021-07-12 1764
-
量子计算是什么2018-11-04 29276
-
巨头们开始角逐边缘计算是出于怎样的目的2019-09-20 1010
-
边缘计算是什么?与ARM和云计算有什么关系2019-11-06 4863
-
云计算是保护数据的关键吗?2020-06-20 1029
-
AI边缘计算是什么,为什么5G的发展离不开它2022-05-07 1144
-
边缘计算是个啥东西2023-05-18 703
-
介绍一种基于中位数的离群值检测方法2023-06-20 3592
-
AI边缘计算是什么意思?边缘ai是什么?AI边缘计算应用2023-08-24 4209
-
SOLIDWORKS仿真计算是什么意思?2023-09-06 3274
-
大数据与云计算是干嘛的?2025-02-20 1700
全部0条评论

快来发表一下你的评论吧 !
