

如何试用MediaPipe实现人脸3D点云数据提取
触控感测
211人已加入
描述
模型与流程
上一篇文章介绍了MediaPipe中手势关键点检测与简单的手势识别,本文介绍如何试用MediaPipe实现人脸3D点云数据提取,提取的数据为人脸468点位。
整个流程如下:
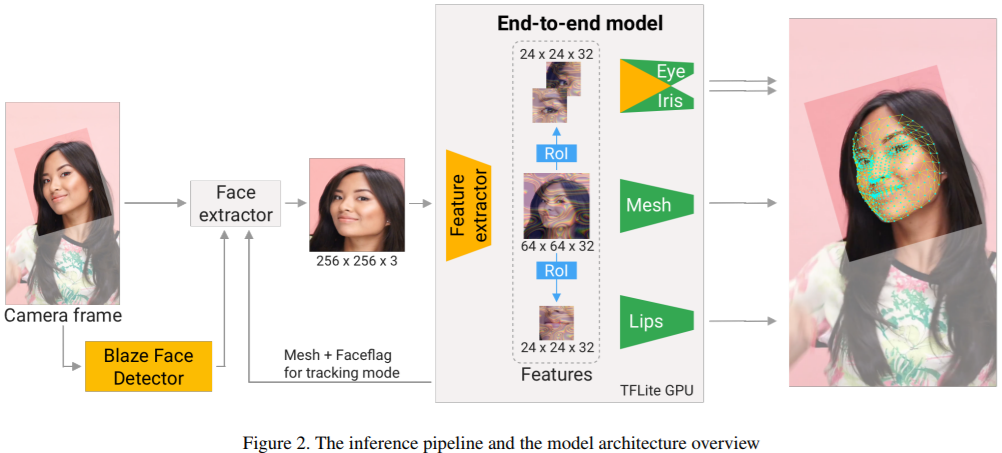


输的468点是3D坐标,值在0~1之间,其中z表示深度,Python函数支持下面的参数配置:
max_num_faces 默认为1,表示支持最大人脸检测数目 min_detection_confidence 最小检测置信度,默认0.5 min_tracking_confidence 最小跟踪置信度,默认0.5
人脸3D点云提取
基于MediaPipe的python版本函数,在官方教程的基础上,我稍微修改了一下,代码如下:
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_face_mesh = mp.solutions.face_mesh
# For webcam input:
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
cap = cv2.VideoCapture("D:/images/video/face_mesh.mp4")
with mp_face_mesh.FaceMesh(
max_num_faces=4,
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as face_mesh:
while cap.isOpened():
success, frame = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
break
h, w, c = frame.shape
image = cv2.resize(frame, (w //2, h//2))
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = face_mesh.process(image)
# Draw the face mesh annotations on the image.
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks)
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks)
mp_drawing.draw_landmarks(
image=image,
landmark_list=face_landmarks
)
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Face Mesh', image)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
运行结果如下:

编辑:黄飞
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
基于3D点云的多任务模型在板端实现高效部署2023-12-28 3397
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2768
-
如何同时获取2d图像序列和相应的3d点云?2018-11-13 3036
-
面向3D机器视觉应用并采用DLP技术的精确点云生成参考设计2022-09-22 2653
-
3D点云技术介绍及其与VR体验的关系2017-09-15 1614
-
点云问题的介绍及3D点云技术在VR中的应用2017-09-27 1560
-
从荣耀角度解读3D识别的结构光、TOF及双目立体成像方案2017-12-12 33727
-
国内大新闻 云从科技 突破3D结构光人脸识别技术2018-04-14 4345
-
3D动态人脸识别技术分析——世纪晟人脸识别实现三维人脸建模2018-07-23 1410
-
3d人脸识别和2d人脸识别的区别2022-02-05 54383
-
何为3D点云语义分割2022-07-21 10659
-
自动驾驶3D点云语义分割数据标注2023-06-06 895
-
3D相机点云数据“如何读取”2023-07-12 4765
-
基于深度学习的3D点云实例分割方法2023-11-13 3959
-
C#通过Halcon实现3D点云重绘2025-01-05 503
全部0条评论

快来发表一下你的评论吧 !
