

如何构建Cookie池-1
描述
一.项目背景
由于http协议是无状态的协议,简单理解为如果客户端向服务器发送两次请求,这
两次请求是独立的,,也就是说服务器根本不知道是同一个客户端发送过来的请求。所
以为了维护客户端的请求状态,Cookie技术应用而生。
Cookie是通过客户端保持状态的解决方案,它是由服务器发送给客户端的特殊信息,
而这些特殊信息以文本形式存储放在客户端,然后客户端每次向服务器发送请求时会携
带上大量这些特殊信息。
Session是通过服务器来保持状态的,客户端第一次访问时,服务器为这个客户端
创建唯一特征码,也就是SessionID,客户端再次请求时,服务器根据SessionID在服
务器数据库中查询,若有这个SessionID,则会做相应响应。
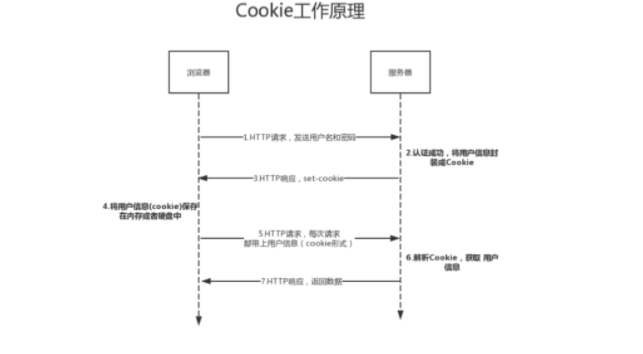
Cookie属性
》》name=value,键和值,具体的Cookie名称和内容
》》expires=xxxxx,过期时间,Cookie有效期
》》path=/,根路径,Cookie作用的具体路径位置
》》httpOnly,此Cookie只能服务器操作,JS无法操作
二.实现过程
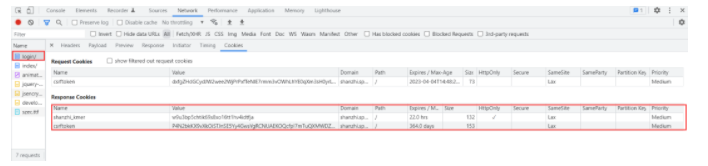
本次项目我们爬取的目标网址为闪职网,一个专门为爬虫工程师进行练习的网址,也
在此非常感谢网站后台维护人员辛勤付出,网址为:http://shanzhi.spbeen.com/,从
中可以看出Cookies有csrftoken和shanzhi_kmer以及它们各自对应的值
from selenium import webdriver
import time
import json
#用户名,此处我们注册四个用户,如果无效读者后期可自行注册
users=[
{'username':'test123456','password':'test123456'},
{'username':'wfq123','password':'123'},
{'username':'cauwfq','password':'cauwfq'},
{'username':'cauwfq1234','password':'cauwfq1234'}
]
#登录网址
def login(username,password):
#初始化url
url='http://shanzhi.spbeen.com/login/'
#初始化webdriver
driver=webdriver.Chrome()
#最大化窗口
driver.maximize_window()
#请求url
driver.get(url)
#用户名输入框
username_input=driver.find_element_by_xpath('//*[@id="username"]')
#发送用户名
username_input.send_keys(username)
#休眠1s
time.sleep(1)
#密码输入框
password_input=driver.find_element_by_xpath('//*[@id="MemberPassword"]')
#发送密码
password_input.send_keys(password)
#休眠1s
time.sleep(1)
#点击登录按钮
driver.find_element_by_xpath('/html/body/div/div/div[2]/button').click()
#休眠3s
time.sleep(3)
#获取cookies
cookie_lists=driver.get_cookies()
#获取cookie值
cookie_dict={cookie['name']:cookie['value'] for cookie in cookie_lists}
#写入文件
with open('./cookies.txt','a+',encoding='utf8') as f:
#写入文件
f.write(json.dumps(cookie_dict))
#写入换行
f.write('n')
#退出浏览器
driver.quit()
if __name__ == '__main__':
#遍历每个用户
for user in users:
#登录网站
login(user['username'],user['password'])


#测试Cookie有效性
import requests
import json
import re
#读取cookies数据
with open('cookies.txt','r',encoding='utf8') as f:
#读取存储为列表
cookies_list=f.readlines()
#存储结果
result=''
#遍历每个Cookie
for cookie_str in cookies_list:
#加载Cookie
cookie_dict=json.loads(cookie_str)
#构建会话
session=requests.session()
#加入到会话中
session.cookies=requests.utils.cookiejar_from_dict(cookie_dict)
#请求网址
response=session.get('http://shanzhi.spbeen.com/login/')
#输出响应内容
#print(response,response.text)
#存储结果
result+=response.text
#输出登录结果,发现欢迎结果为4个,四个用户登录成功
print(re.findall('欢迎',result))

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
构建便捷海外IP代理池:策略与实践2024-11-14 1118
-
如何构建Cookie池-22023-02-24 1575
-
构建一个Cookie JAR激情时钟2022-08-01 1094
-
Cookie和Session的区别总结2019-01-10 3280
-
cookie和session区别2018-12-12 106295
-
cookie的作用2018-12-10 16718
-
cookie和session的不同作用2018-01-09 2728
-
什么是Cookie2010-02-22 788
-
网络Cookie工作原理2009-08-04 4492
-
php中Cookie及其使用2009-01-11 2728
全部0条评论

快来发表一下你的评论吧 !
