

什么是神经网络应用-2
描述
一.项目背景
本项目在之前项目分类模型基础上神经网络应用(一)进一步拓展神经网络应用,相比之前本项目增加了新的知识点,比如正则化,softmax函数和交叉熵损失函数等。
二.前期准备
1.正则化
1)解释:在机器学习中为了防止模型过拟合(简单说就是在训练集上样本表现的
很好,在测试集上表现的很差),经常需要进行正则化,所谓正则化简单来说就是让模
型系数变得相对小一点,防止数据稍微变化引起模型图形曲线较大波动,总之一句话,
让模型曲线表现更加平稳。
2)分类:正则化总体分类为L1正则化和L2正则化。两者区别在于范数级别不同,
L2正则化是||w||2,L1正则化是||w||1范数,并且L2正则倾向于系数W尽量均衡(非
零分量个数尽量多),L1正则化使W分类尽量稀疏(非零分量个数尽量少),我们以线
性回归为例,简单说明一下。


【注】正则项不包括截距项。
2.Softmax函数
1)Softmax经常被应用在多分类任务的神经网络中的输出层,简单理解可以认为
Softmax输出的是几个类别选择的概率。比如我有一个二分类任务,Softmax函数可以
根据它们相对的大小,输出二个类别选取的概率,并且概率和为1。表达式如下,Si代
表的是第i个神经元的输出。
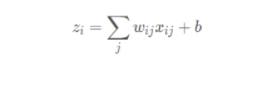
softmax函数
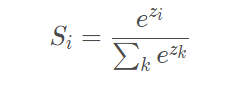
3.交叉熵损失函数
在神经网络反向传播中需要损失函数,损失函数其实表示的是真实值与网络的估计
值的误差,有了这个误差我们才能知道怎样去修改网络中的权重。损失函数可以有很多
形式,这里用的是交叉熵函数,主要是由于这个求导结果比较简单,易于计算,并且交
叉熵解决某些损失函数学习缓慢的问题,函数表达式如下
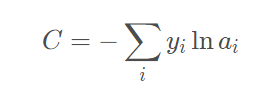
它的导数推到过程我们就不再说明,网上有很多资料大家可以参考,针对本项目分类
模型,我们最终结果为如下,也就是我们的预测概率值减去目标值。
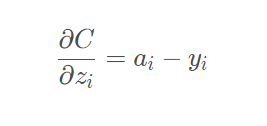
三.实现过程
1.生成数据
#生成数据
def generate_data():
#设定种子数,保定生成数据相同
np.random.seed(0)
#生成数据集和标签,noise表示产生噪音
X, y = datasets.make_moons(200, noise=0.20)
#返回数据集
return X, y
2.构建模型
#计算损失函数
def calculate_loss(model, X, y):
#训练样本个数
num_examples = len(X) # training set size
#加载模型参数
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
#前向传播
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
#softmax函数归一化
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
#定义交叉熵损失函数
corect_logprobs = -np.log(probs[range(num_examples), y])
#计算总的损失函数
data_loss = np.sum(corect_logprobs)
#L2正则化,防止过拟合
data_loss += Config.reg_lambda / 2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
#除以样本总数
return 1. / num_examples * data_loss
#构建模型
def build_model(X, y, nn_hdim, num_passes=20000, print_loss=False):
#样本个数
num_examples = len(X)
#记录随机中子数
np.random.seed(0)
#初始化神经网络参数
W1 = np.random.randn(Config.nn_input_dim, nn_hdim) / np.sqrt(Config.nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, Config.nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, Config.nn_output_dim))
#存储模型参数
model = {}
#遍历每一轮
for i in range(0, num_passes):
#前向传播
z1 = X.dot(W1) + b1
#函数表达式(e(z)-e(-z))/(e(z)+e(-z))
#隐藏层输出
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
#输出层输出
exp_scores = np.exp(z2)
#计算概率
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
#反向传播
delta3 = probs
#计算损失函数导数
delta3[range(num_examples), y] -= 1
#计算w2梯度
dW2 = (a1.T).dot(delta3)
#计算b2梯度
db2 = np.sum(delta3, axis=0, keepdims=True)
#计算输入层到隐藏层总误差
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
#计算w1梯度
dW1 = np.dot(X.T, delta2)
#计算b1梯度
db1 = np.sum(delta2, axis=0)
#正则化系数w(只对w进行正则化,b不改变)
dW2 += Config.reg_lambda * W2
dW1 += Config.reg_lambda * W1
#更新参数
W1 += -Config.epsilon * dW1
b1 += -Config.epsilon * db1
W2 += -Config.epsilon * dW2
b2 += -Config.epsilon * db2
#存储模型参数
model = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
#输出损失函数
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" % (i, calculate_loss(model, X, y)))
#返回模型参数
return model
3.预测样本
#预测样本
def predict(model, x):
#加载模型参数
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
#前向传播
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
#计算总体输出
exp_scores = np.exp(z2)
#softmax函数
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
#返回预测概率最大值对应标签
return np.argmax(probs, axis=1)
4.绘制图形可视化
#绘制边界线
def plot_decision_boundary(pred_func, X, y):
#分别设置间隔
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
#步长
h = 0.01
#生成网格数据
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
#预测整个网格z值
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
#绘制分割线
plt.contourf(xx,
yy,
Z,
cmap=plt.cm.Spectral)
#绘制散点图
plt.scatter(X[:, 0],
X[:, 1],
c=y,
cmap=plt.cm.Spectral)
#显示图形
plt.show()
#可视化函数
def visualize(X, y, model):
#绘制图形
plot_decision_boundary(lambda x:predict(model,x), X, y)
#设置标题
plt.title("Neural Network")
#主函数
def main():
#生成数据
X, y = generate_data()
#构建模型
model = build_model(X, y, 3, print_loss=True)
#可视化
visualize(X, y, model)
#预测准确样本数
accuracy=0
#设定种子数,保定生成数据相同
np.random.seed(1)
#生成数据集和标签,noise表示产生噪音
X_test, y = datasets.make_moons(200, noise=0.20)
#验证测试集
for i in range(len(X_test)):
#预测测试集
if y[i]==predict(model,X_test[i]):
#预测准确数目
accuracy+=1
#输出准确率
print("Accuracy:",float(accuracy)/len(X_test))
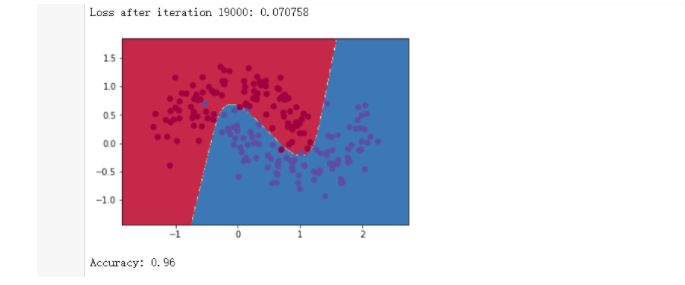
结论:准确率为96%(这里测试集数据我们添加了噪音),如果在产生测试集数据时取掉
noise参数(也就是说取掉噪音数据),准确率会更高。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
RBF神经网络(2)#人工智能未来加油dz 2023-07-27
-
初识神经网络(2)#人工智能未来加油dz 2023-07-25
-
6 实现多层神经网络(2)#神经网络未来加油dz 2023-05-17
-
1 LeNet神经网络(2)#神经网络未来加油dz 2023-05-16
-
用Python从头实现一个神经网络来理解神经网络的原理22023-02-27 1381
-
人工神经网络(2)#人工智能jf_49750429 2022-11-29
-
卷积神经网络(2)#人工智能jf_49750429 2022-11-28
-
[11.2.2]--神经网络2学习电子知识 2022-11-25
-
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速2018-12-19 3984
全部0条评论

快来发表一下你的评论吧 !
