

如何提取Word文档表格保存到Excel
描述
一.项目背景
日常工作中,我们不免会遇到接收大量相似的word文档,并需要把这些文档中的数
据提取到Excel表中。例如,提取word文档中的财务数据、考勤数据等,将数据存储到
Excel表中,本次项目我们专门针对word文档中的表格数据进行解析与提取。
原始数据文件(word文档)
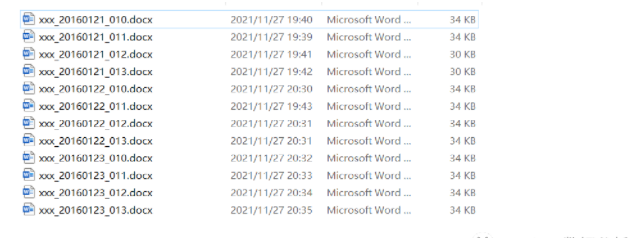
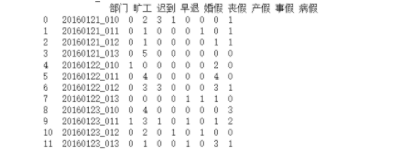
word文档内容
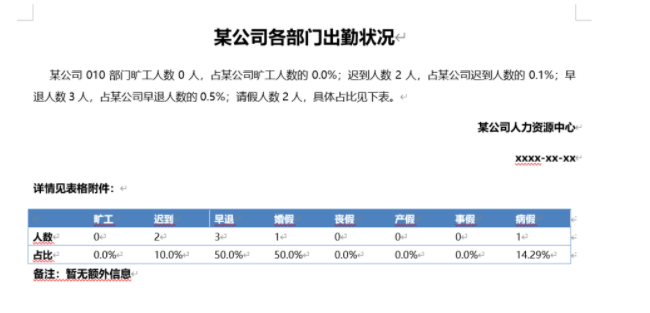
本次我们的目标是提取表格列名称和人数这一行,最后存储为Excel文件。
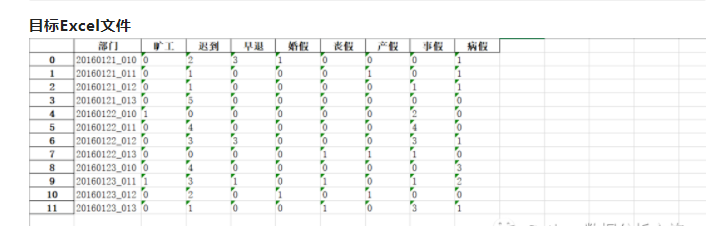
目标Excel文件
二.实现步骤
import pandas as pd
import docx
import os
#提取word文档表格
def DocParsing(path_para):
#获取文件列表
file_list = os.listdir(path_para)
#创建存储所有数据的列表
list_combine = []
#遍历word文件列表
for file in file_list:
#读取word文档
doc = docx.Document(path_para + '/' + file)
#创建存储单个word文档数据的列表,key存储值,col存储列名称
key, col = [], []
#获取word文档的表格
tb = doc.tables[0]
#row_index 表示表格的行数
row_index=0
#遍历表格的行
for row in tb.rows:
#记录行数
row_index += 1
#不提取占比这行
if row_index == 3:
continue
else:
#遍历每行的单元格
for cell in row.cells:
text = ""
#解析每一个单元格的数据
for p in cell.paragraphs:
text += p.text
#提取列名称
if row_index == 1 :
#提取人数数据
col.append(text)
else:
key.append(text)
#修改列表'col'的第一个元素为‘部门’
col[0] = '部门'
#修改列表‘key’的第一个元素为具体部门名称
key[0] = file[4:16]
#将提取的数据转化为单行DataFrame对象
data = pd.DataFrame({i: j for i, j in zip(col, key)}, index=[0])
print(data)
#将DataFrame对象存储到列表
list_combine.append(data)
#合并数据并重建索引
df = pd.concat(list_combine, ignore_index=True)
#输出数据
print(df)
#保存数据为Excel文件
df.to_excel('考勤汇总表.xlsx')
DocParsing('./task/')
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
向word和excel表格指定位置写2012-06-25 22369
-
LabVIEW读取EXCEL中的数据并复制到Word中生存报表2013-03-30 25177
-
labview 自动保存到excel 的的程序 打包成exe ,会有问题2014-07-09 2974
-
EXCEL数据保存加急2018-05-12 1984
-
面板怎么保存到两个excel电子表格中2018-10-25 2726
-
Labview写入Excel保存到本地后打开该文档会报错呢?如下图2019-04-23 6018
-
串口数据保存到excel 换列2019-11-21 3334
-
Microsoft Office Word、Excel 和2009-02-12 1364
-
Office Word、Excel和PowerPoint 文2010-07-06 1594
-
word表格小技巧2008-01-08 1986
-
如何使用labview读写word模板表格的内容2018-10-22 3298
-
使用Python操作excel表格的xlrd介绍2020-07-02 933
-
如何从Word、PPT或Excel等提取所有图片并保存在其他地方?2020-09-29 4791
-
Spire.Cloud.Word云端Word文档处理SDK介绍2025-02-11 1291
-
Spire.Cloud.Excel云端Excel文档处理SDK2025-02-13 1175
全部0条评论

快来发表一下你的评论吧 !
