

什么是FM模型对用户分类
描述

一.项目背景
新零售时代背景下,商家要提升顾客的价值,让20%的顾客贡献80%的业绩(二八定律),这就是超级用户思维。超级用户,是指对品
牌认可、购买频次多、购买金额大且能给商家反馈意见、并能把产品推荐别人购买,对商家具有较高忠诚度、与商家建立起强关系的用户。
该项目寻找的是准超级用户(FM模型,也即购买频次多和购买金额大的客户),为将来转化为超级用户打好基础。
二.理论基础
1.购买频次筛选标准
通过分组法,按买家账号进行分组,确定每个买家的购买频次。然后按购买频次进行等距分组,统计每个频次区间内买家数量,找出人数差最大的两个相邻频次区间并把这两个相邻区间的中间值作为购买频次的筛选标准。
比如这两个相邻频次区间是[3, 7), [7, 10), 选择7作为购买频次筛选标准。>=7的购买频次被认定为高购买频次。该方法的思想是寻找第一个异常点,特别适合随着频次区间数值上的增加,人数递减的情况,比如这样的人数分布:
{[1, 3):1000, [3, 5):550, [5, 7):230, [7, 9):96, [9, 11):22, [11, 13):6}
2.购买金额筛选标准
通过箱线图法,将购买金额排序,然后进行四分位,得到三个分位数:Q1,Q2,Q3。接着按下面公式计算购买金额筛选标准:
V(购买金额筛选标准)=Q3+IQR_coefficient*IQR,其中IQR=Q3-Q1,IQR_coefficient的值可以自定义,一般选为1.5或3。
>=V的购买金额为高购买金额
三.实现步骤
1.获取数据
import pandas as pd
import numpy as np
#获取数据
def get_data(file_path):
#读取数据
df=pd.read_excel(file_path,index=0)
#筛选数据
data=df[['买家账号','已付金额']]
#返回数据
return data
#获取数据
data=get_data('./data.xlsx')
#查看数据
data.head()
2.处理数据
#处理数据
def process_data(df):
#判断是否有重复值
if df.duplicated().sum()==0:
print('没有重复值')
else:
#计算重复数据数量
len_dup=len(df[df.duplicated()==True])
print(f'重复数据有{len_dup}条')
#删除重复值
df.drop_duplicates(inplace=True)
#判断是否有缺失值
if df.isnull().any().sum()==0:
print('没有缺失值')
else:
#计算缺失数据数量
len_null=len(df[df.isnull().T.any()])
print(f'缺失数据有{len_null}条')
#删除数据
df.dropna(inplace=True)
#返回数据
return df
#处理数据
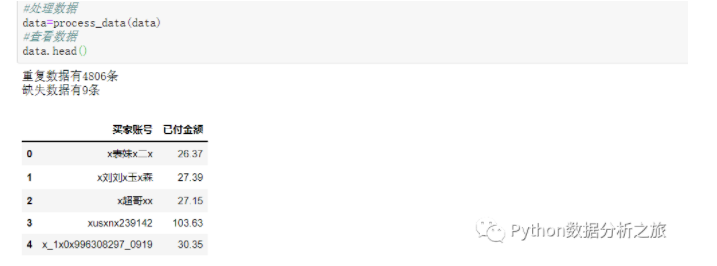
data=process_data(data)
#查看数据
data.head()
3.按照分组标准对用户分类
#获取准超级用户
def before_superCustomer(data,coeff,bin_num):
#统计客户购买次数
df1=data['买家账号'].value_counts().reset_index().rename(columns={'index':'买家账号','买家账号':'购买频次'})
#统计客户购买金额
df2=data.groupby(['买家账号'])['已付金额'].sum()
#通过买家账号连接数据,
df=pd.merge(df1,df2,on='买家账号')
#筛选所需数据
df_res=df[['买家账号','购买频次','已付金额']]
#对购买频词进行切分
cut = pd.cut(df['购买频次'], bins=bin_num)
#统计购买频词
top = pd.value_counts(cut)
#获取高度差值最大的两个分组区间,前一个分组区间的右区间值用于高购买频次客户的评判标准
top_index = top.diff().abs().values.argmax()
#获取四分之三分位数
Q3 = df_res.describe()['已付金额'][6]
#获取四分之一分位数
Q1 = df_res.describe()['已付金额'][4]
#计算IQR
IQR = Q3-Q1
#获取准超级用户购买金额最小值
min_value = Q3 + 1.5* IQR
# 根据高购买金额和高购买频次用户标准过滤用户
df_res=df_res[(df_res['购买频次'] >top.index[top_index].right) & (df_res['已付金额'] >min_value)]
#按照已付金额进行降序排序
df_res.sort_values('已付金额',ascending=False,inplace=True)
#返回数据
return df_res
#对用户进行分类
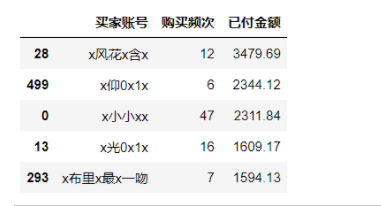
df_res=before_superCustomer(data,3,16)
#查看数据
df_res.head()
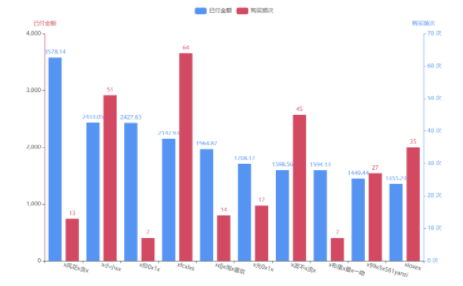
4.对Top10用户进行可视化
import pyecharts.options as opts
from pyecharts.charts import Bar
#设置颜色
colors = ["#5793f3", "#d14a61"]
#x轴数据买家账号
x_data = df_res.iloc[:10]['买家账号'].tolist()
#设置图例
legend_list = ["已付金额", "购买频次"]
#y轴已付金额
customer_buy =df_res.iloc[:10]["已付金额"].round(2).tolist()
#y轴购买频次
customer_count=df_res.iloc[:10]["购买频次"].tolist()
#初始化
bar = (
Bar(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="已付金额",
yaxis_data=customer_buy,
yaxis_index=0,
color=colors[1],
)
.add_yaxis(
series_name="购买频次",
yaxis_data=customer_count,
yaxis_index=1,
color=colors[0]
)
.extend_axis(
yaxis=opts.AxisOpts(
name="购买频次",
type_="value",
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color=colors[0])
),
axislabel_opts=opts.LabelOpts(formatter="{value} 次"),
)
)
.extend_axis(
yaxis=opts.AxisOpts(
name="已付金额",
type_="value",
position="left",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color=colors[1])
),
axislabel_opts=opts.LabelOpts(),
)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
)
)
#加载显示图形
bar.render_notebook()
结论:应加强和这些客户沟通,尽可能提供个性化服务,让它们发展为我们超级用户
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FM8302 API用户手册2023-09-14 764
-
PyTorch教程4.3之基本分类模型2023-06-05 919
-
OpenCV中支持的非分类与检测视觉模型2022-08-19 2305
-
Edge Impulse的分类模型浅析2021-12-20 1798
-
基于LSTM的表示学习-文本分类模型2021-06-15 1313
-
依据待分类实例显著局部特征的懒惰式分类模型2021-03-31 995
-
怎么设计FM天线?2019-08-13 4057
-
Hadoop云平台用户动态访问控制模型2018-01-10 1189
-
基于非参数方法的分类模型检验2017-12-08 796
-
系统模型及其分类.zip2017-10-04 2084
-
基于隐马尔可夫模型的音频自动分类2011-03-06 1936
-
DNA序列的分类模型2009-09-16 1091
-
系统模型及其分类2009-09-08 1147
全部0条评论

快来发表一下你的评论吧 !
