

什么是集成学习算法-1
描述
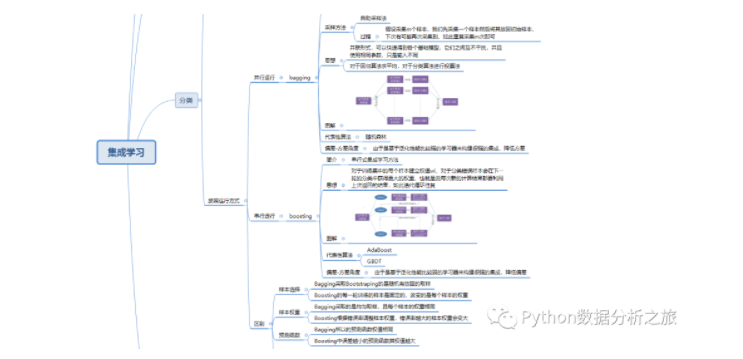
一.集成学习简介
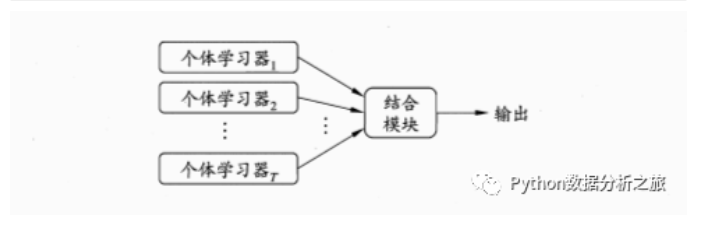
简介:构建并结合多个学习器来完成任务
图解:
按照个体学习器划分分类:
(1)同质集成:只包含同种类型算法,比如决策树集成全是决策树
(2)异质集成:包含不同种类型算法,比如同时包含神经网络和决策树
按照运行方式分类:
(1)并行运行:bagging
(2)串行运行:boosting
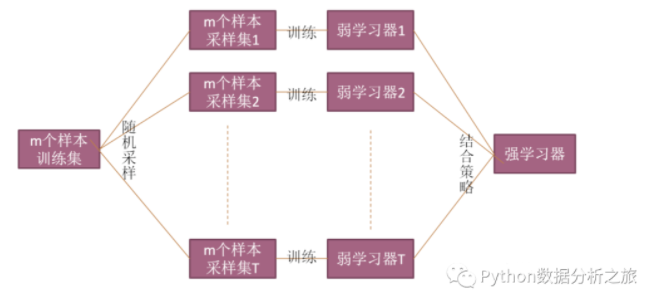
二.Bagging
简介:并行式集成学习方法
采样方法:自助采样法。假设采集m个样本,我们先采集一个样本然后将其放回初始样本,下次有可能再次采集到,如此重复采集m次即可
思想:并联形式,可以快速得到各个基础模型,它们之间互不干扰,并且使用相同参数,只是输入不同。对于回归算法求平均,对于分类算法进行投票法
代表性算法:随机森林
偏差-方差角度:由于是基于泛化性能比较强的学习器来构建很强的集成,降低方差
图解:
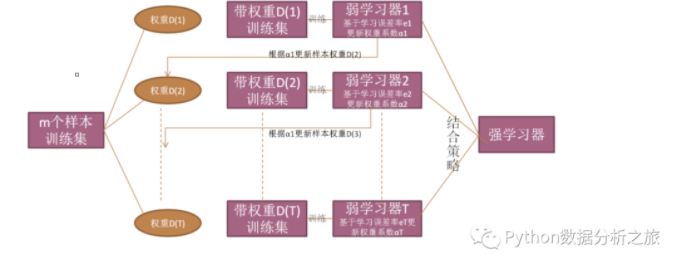
三.Boosting
简介:串行式集成学习方法
思想:对于训练集中的每个样本建立权值wi,对于分类错误样本会在下一轮的分类中获得更大的权重,也就是说每次新的计算结果都要利用上次返回的结果,如此迭代循环往复
代表性算法:AdaBoost和GBDT
偏差-方差角度:由于是基于泛化性能比较弱的学习器来构建很强的集成,降低偏差
图解:
四.Bagging与Boosting区别
1.样本选择
Bagging采取Bootstraping的是随机有放回的取样
Boosting的每一轮训练的样本是固定的,改变的是每个样本的权重
2.样本权重
Bagging采取的是均匀取样,且每个样本的权重相同
Boosting根据错误率调整样本权重,错误率越大的样本权重会变大
3.预测函数
Bagging预测函数权值相同
Boosting中误差越小的预测函数其权值越大
4.并行计算
Bagging 的各个预测函数可以并行生成
Boosting的各个预测函数必须按照顺序迭代生成
五.预测居民收入
项目背景:该数据从美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K/year。该数据集类变量为年收入是否超过,属性变量包含年龄,工种,学历,职业,人种等重要信息,14个属性变量中有7个类别型变量
import pandas as pd
import numpy as np
import seaborn as sns
%matplotlib inline
#读取文件
data_train=pd.read_csv('./income_census_train.csv')
#查看数据
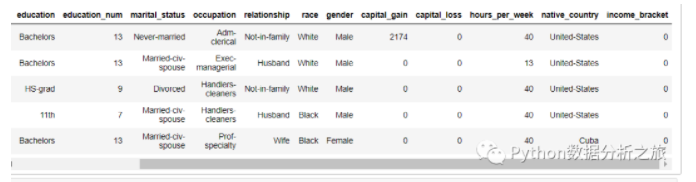
data_train.head()
#数据查看与处理
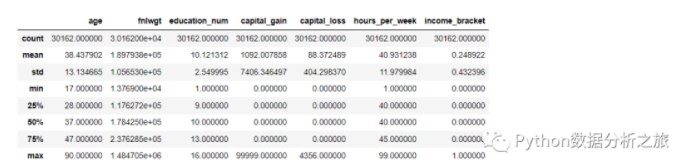
#数值型特征的描述与相关总结
data_train.describe()
#非数值型
data_train.describe(include=['O'])

#删除序列数据
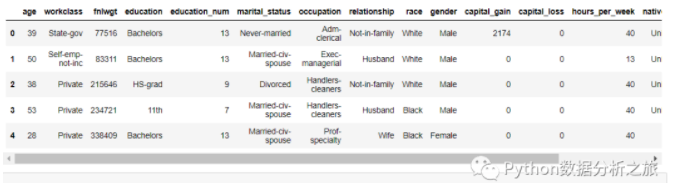
data = data_train.drop(['ID'],axis = 1)
#查看数据
data.head()
#数据转换
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 将oject数据类型进行类别编码
for feature in data.columns:
if data[feature].dtype == 'object':
data[feature] = pd.Categorical(data[feature]).codes
#标准化处理
X = np.array(X_df)
y = np.array(y_df)
scaler = StandardScaler()
X = scaler.fit_transform(X)
from sklearn.tree import DecisionTreeClassifier
from pyecharts.charts import Scatter
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.charts import Page
#初始化
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X, y)
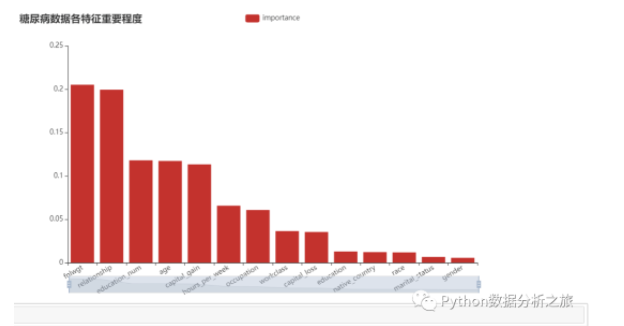
#显示每个属性的相对重要性得分
relval = tree.feature_importances_
#构建数据
importances_df = pd.DataFrame({
'feature' : data.columns[:-1],
'importance' : relval
})
importances_df.sort_values(by = 'importance', ascending = False, inplace = True)
#作图
bar = Bar()
bar.add_xaxis(importances_df.feature.tolist())
bar.add_yaxis(
'importance',
importances_df.importance.tolist(),
label_opts = opts.LabelOpts(is_show = False))
bar.set_global_opts(
title_opts = opts.TitleOpts(title = '糖尿病数据各特征重要程度'),
xaxis_opts = opts.AxisOpts(axislabel_opts = opts.LabelOpts(rotate = 30)),
datazoom_opts = [opts.DataZoomOpts()]
)
bar.render('diabetes_importances_bar.html')
bar.render_notebook()
#特征筛选
from sklearn.feature_selection import RFE
# 使用决策树作为模型
lr = DecisionTreeClassifier()
names = X_df.columns.tolist()
#将所有特征排序,筛选前10个重要性较高特征
selector = RFE(lr, n_features_to_select = 10)
selector.fit(X,y.ravel())
#得到新的dataframe
X_df_new = X_df.iloc[:, selector.get_support(indices = False)]
X_df_new.columns

from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,confusion_matrix
#标准化
X_new = scaler.fit_transform(np.array(X_df_new))
#分离数据
X_train, X_test, y_train, y_test = train_test_split(X_new,y,test_size = 0.3,random_state=0)
#随机森林分类
model_rf=RandomForestClassifier()
model_rf.fit(X_train,y_train)
#预测
model_rf.predict(X_test)
#输出准确率
print(round(accuracy_score(y_test,model_rf.predict(X_test)),2))
#总体来说不是很高,后期我们还需要再次提升

import itertools
#绘制混淆矩阵
def plot_confusion_matrix(cm, classes, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
#设置thresh值
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
#设置布局
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
#参考链接:https://www.heywhale.com/mw/project/5bfb6342954d6e0010675425/content
#计算矩阵
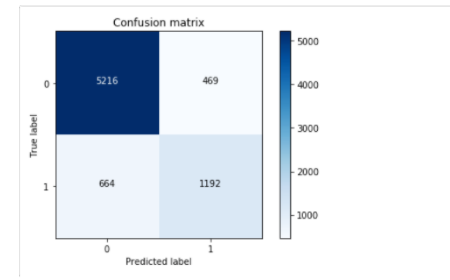
#计算矩阵
cm = confusion_matrix(y_test,model_rf.predict(X_test))
class_names = [0,1]
#绘制图形
plt.figure()
#输出混淆矩阵
plot_confusion_matrix(cm , classes=class_names, title='Confusion matrix')
#显示图形
plt.show()
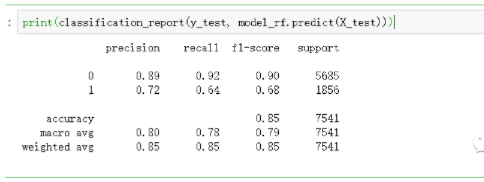
#输出预测信息,感兴趣读者可以手动验证一下
print(classification_report(y_test, model_rf.predict(X_test)))
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
深度学习算法在集成电路测试中的应用2024-07-15 2707
-
深度学习算法简介 深度学习算法是什么 深度学习算法有哪些2023-08-17 10947
-
17个机器学习的常用算法!2022-08-22 3339
-
基于改进CNN网络与集成学习的人脸识别算法2021-05-27 1303
-
基于Qualcomm DSP的算法集成案例2018-09-25 2824
-
不可错过 | 集成学习入门精讲2018-06-06 3006
-
AI应用于医疗预测 需集成机器学习与行为算法2018-01-17 1097
全部0条评论

快来发表一下你的评论吧 !
