

如何高效训练Transformer?
描述
近期,微软亚洲研究院从深度学习基础理论出发,研发并推出了 TorchScale 开源工具包。TorchScale 工具包通过采用 DeepNet、Magneto 和 X-MoE 等最先进的建模技术,可以帮助研究和开发人员提高建模的通用性和整体性能,确保训练模型的稳定性及效率,并允许以不同的模型大小扩展 Transformer 网络。
如今,在包括语音、自然语言处理(NLP)、计算机视觉(CV)、多模态模型和 AI for Science 等领域的研究中,Transformer 已经成为一种通用网络结构,加速了 AI 模型的大一统。与此同时,越来越多的实践证明大模型不仅在广泛的任务中能产生更好的结果、拥有更强的泛化性,还可以提升模型的训练效率,甚至衍生出新的能力。因此,学术界和产业界都开始追求更大规模的模型。
然而随着模型的不断扩大,其训练过程也变得更加困难,比如会出现训练不收敛等问题。这就需要大量的手动调参工作来解决,而这不仅会造成资源浪费,还会产生不可预估的计算成本。
与其扬汤止沸,不如釜底抽薪。微软亚洲研究院从深度学习基础理论出发,创新推出了 TorchScale 工具包,并已将其开源。TorchScale 是一个 PyTorch 库,允许科研和开发人员更高效地训练 Transformer 大模型。同时,它有效地提升了建模的性能和通用性,提高了 Transformer 的稳定性和训练效率。
TorchScale GitHub 页面:
https://github.com/microsoft/torchscale
“我们希望通过 TorchScale 的系列工作从更底层出发做一些基础性的研究创新,通过数学或者理论上的指导和启发,在 Transformer 模型扩展的工作中取得更好的效果,而不是单纯的调参或仅从工程层面部分缓解某些问题。TorchScale 能够支持任意的网络深度和宽度,实验验证它可以轻松扩大模型规模,而且只需要几行代码就能够实现多模态模型的训练。”微软亚洲研究院自然语言计算组首席研究员韦福如表示。
据了解,TorchScale 主要从三个方面帮助科研人员克服了扩展 Transformer 大模型时的困难:
DeepNet:提升模型的稳定性。
Magneto:提升模型的通用性。
X-MoE:提升模型训练的高效性。
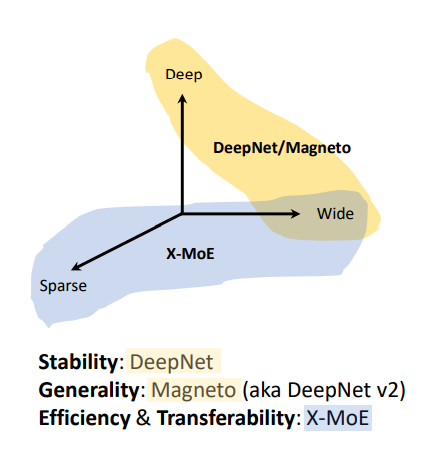
图1:TorchScale 解决大模型在
稳定性、通用性、高效性上面临的问题
DeepNet:让Transformer训练深度超过1000层
尽管近年来模型参数的数量越来越大,已经从百万级扩展到万亿级,但参数的深度却一直受限于 Transformer 训练的不稳定性。为了解决这一问题,一些科研人员尝试通过更好的初始化或架构来提升 Transformer 的稳定性,但这也只能让 Transformer 在百层级别的深度下保持稳定。
微软亚洲研究院的研究员们发现,模型输出的剧烈变化是导致模型不稳定的重要原因。为此,研究员们在残差连接处使用了一种新的归一化函数——DeepNorm。新的函数由理论推导而来,可以把模型输出的变化限制在常数范围内。这种方法只需要改变几行代码,就可以大幅提升 Transformer 的稳定性。通过引入新的 DeepNorm 函数,研究员们训练了超深的 Transformer 网络 DeepNet,在保证模型稳定的同时,可以将模型深度扩展到1000层以上。
DeepNorm 同时具备 Post-LN 的性能和 Pre-LN 的训练稳定性。这个新方法或将成为 Transformer 的首选替代方案,它不仅适用于深模型,更适用于大模型。值得一提的是,与具有120亿参数的48层模型相比,微软亚洲研究院32亿参数的200层模型在100多个语言、超10000个语言对和130亿个文本对的多语言机器翻译实验中实现了5 BLEU 的提升。在大规模多语言翻译任务上,随着 DeepNet 模型深度从10层扩展至100层和1000层,模型也获得了更高的 BLEU 值。
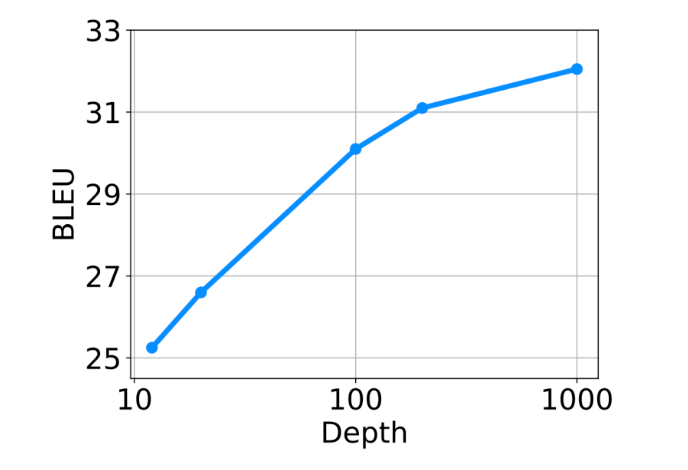
图2:随着模型深度从10层扩展至100层和1000层,DeepNet 有效提升了多语言翻译结果
韦福如说,“此前,科研人员在训练更大规模的模型时,往往需要投入大量的精力在模型调参上,无形中增加了实验成本,有的模型在训练中途就无法继续下去了,即使给模型打上补丁也还是会影响模型性能。DeepNet 可以帮助科研人员大幅降低调参的负担,在提升模型性能的同时降低实验成本。”
Magneto:真正实现多模态模型架构统一
跨语言、视觉、语音和多模态的模型在模型结构上走向大一统的趋势如今已经愈发明显。具体而言,从 NLP 领域开始,Transformer 已成为 AI 各领域的主流结构。然而,尽管都使用了 Transformer,但不同模态任务的模型结构在具体实现时仍存在显著差异。例如,GPT 和 ViT 模型采用了 Pre-LN Transformer,而 BERT 和机器翻译模型使用的是 Post-LN 来获得更好的性能。更重要的是,对于多模态模型,不同输入模态的最优 Transformer 变体通常是不同的。以微软亚洲研究院推出的多模态预训练模型 BEiT-3为例,其使用 Post-LN 对于视觉部分是次优的,而 Pre-LN 对于语言部分是次优的。
要想让多模态预训练真正实现大一统就需要一个统一的架构,该架构需要在不同任务和模态上都能有良好的性能表现。另外,如之前所述,Transformer 架构训练的稳定性也是一个痛点。微软亚洲研究院的研究员们意识到,通用模型的开发需要更基础的 Transformer,即 Foundation Transformer。首先它的建模能够作为各种任务和模式的统一架构,这样就可以使用相同的主干而无需反复魔改。其通用的设计原则也应该支持多模态基础模型的开发,在不牺牲性能的前提下将统一的 Transformer 用于各种模态。其次,它的网络结构应能够保障训练的稳定性,从而降低基础模型大规模预训练的难度。
为了实现这些目标,微软亚洲研究院的研究员们提出了一个 Foundation Transformer——Magneto。在 Magneto 中,研究员们引入了 Sub-LN,为每个子层(即多头自注意力和前馈网络)添加了额外的 LayerNorm,并且提出了一种新的初始化方法,为从根本上提高训练的稳定性提供了理论保证。
通过对 Magneto 在不同任务和模态上的评测,包括掩码语言建模(即BERT)、因果语言建模(例如GPT)、机器翻译、掩码图像建模(即BEiT)、语音识别和视觉语言预训练(即BEiT-3),结果显示在下游任务上,Magneto 显著优于各种 Transformer 变体。此外,得益于训练稳定性的提高,Magneto 还允许使用更高的学习率来进一步提高结果。
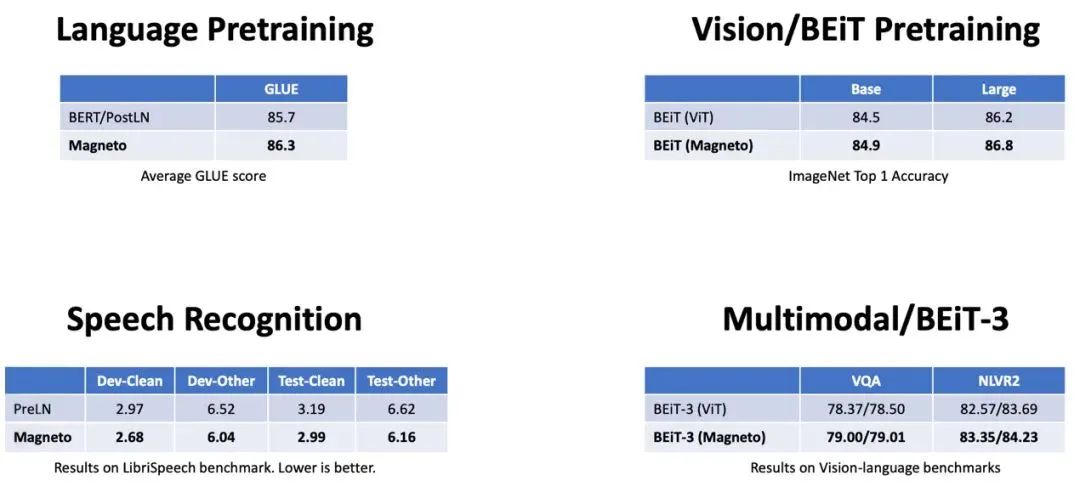
图3:Magneto 在语言、图像、
语音和多模态任务上的实验结果
X-MoE:优于基线SMoE模型,助力模型高效训练
在有关大模型训练的研究中,除了将网络深度做得更深和将宽度即隐藏维度扩大以外,还可以利用混合专家系统(Mixture of Experts, MoE)。尽管 MoE 可以在诸如语言模型和视觉表示学习等广泛问题上获得更好的性能,但也会导致更高的计算成本,这促使越来越多的科研人员开始探索稀疏混合专家模型(Sparse Mixture-of-Experts, SMoE)。SMoE 主要通过构建稀疏激活的神经网络来增加模型容量。在不显著增加计算开销的情况下 SMoE 模型在各种任务(包括机器翻译、图像分类和语音识别)上的性能都优于稠密模型。
在 SMoE 模型中,路由机制发挥着重要的作用。给定输入 token,路由机制会测量每个 token 与专家之间的相似度分数,然后再根据路由得分将 token 分配给最匹配的专家。因此,近年来许多研究都集中在如何设计 token 专家分配算法上。然而,微软亚洲研究院的研究员们发现,当前的路由机制倾向于以专家为中心来推动隐藏表示聚类,这容易引起表征坍塌(Representation Collapse),损害模型性能。
为了缓解现有的路由机制引起的表征坍塌问题,微软亚洲研究院的研究员们提出了新的方法 X-MoE,为 SMoE 模型引入了一种简单而有效的路由算法。具体来说,区别于现有 SMoE 模型直接使用隐藏向量进行路由,X-MoE 先将隐藏向量投射到低维空间中,再对 token 表示和专家表示进行 L2 归一化,来测量低维超球面上的路由分数。此外,研究员们还提出了软专家门(soft expert gate),以学习控制专家的激活。
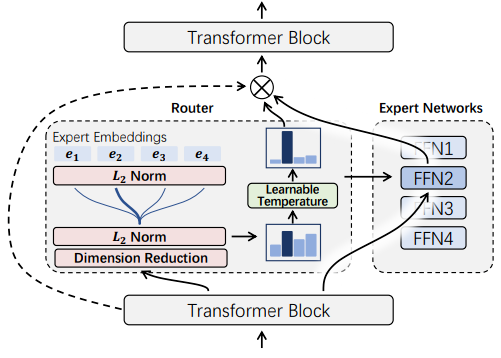
图4:X-MoE 流程图
微软亚洲研究院的研究员们对这一新方法在跨语言模型预训练任务上进行了评测。实验结果表明,在语言建模和微调性能方面,基于 X-MoE 的模型始终优于基线 SMoE 模型。实验分析还表明,与 SMoE 基线相比,X-MoE 方法有效缓解了表征坍塌问题。该方法在预训练和微调期间也实现了更一致的路由行为,证实了 X-MoE 路由算法的有效性。
“随着技术的持续演进,大模型的训练不仅仅是工程层面的工作。我们应该从基础研究的角度出发,探索下一代 Transformer 网络架构。与此同时,在 AI 模型大一统趋势的推动下,我们更应该追求同一结构来支持不同模态的输入,并在不同语言和模态的任务上获得良好的性能。通过理论指导让模型变得更大、更稳定、更通用。”韦福如说。
审核编辑 :李倩
-
Transformer在下一个token预测任务上的SGD训练动态2023-06-12 1613
-
PyTorch教程11.9之使用Transformer进行大规模预训练2023-06-05 1034
-
基于Transformer做大模型预训练基本的并行范式2023-05-31 4665
-
探索一种降低ViT模型训练成本的方法2022-11-24 1536
-
基于Transformer架构的文档图像自监督预训练技术2022-11-15 2611
-
如何进行高效的时序图神经网络的训练2022-09-28 3200
-
基于DINO知识蒸馏架构的分层级联Transformer网络2022-07-25 1781
-
英伟达H100 Transformer引擎加速AI训练 准确而且高达6倍性能2022-04-01 5887
-
用于语言和视觉处理的高效 Transformer能在多种语言和视觉任务中带来优异效果2021-12-28 2720
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4047
-
超大Transformer语言模型的分布式训练框架2021-10-11 4929
-
Transformer的复杂度和高效设计及Transformer的应用2021-09-01 7780
-
视觉新范式Transformer之ViT的成功2021-02-24 7786
-
教你如何使用Python搭一个Transformer2019-04-24 7959
全部0条评论

快来发表一下你的评论吧 !
