

RDMA高性能实践之软硬件融合设计思路
存储技术
描述
王璞博士,达坦科技(DatenLord)联合创始人。王璞博士拥有多年云计算领域的经验,擅长分布式计算、海量数据处理、大规模机器学习。曾供职Google美国总部,负责Google广告部门海量数据处理平台开发。2014年回国创业,创立数人云,专注容器技术在国内的落地和推广。2018年,数人云被收购。2020年,创立达坦科技(DatenLord),致力打造新一代云原生存储平台,专注解决企业级客户在跨云、跨数据中心方面的异构存储、数据统一访问需求。王璞拥有美国George Mason大学计算机博士学位,北大计算机专业硕士学位和北航力学专业学士学位。王璞发表数十篇论文,被引用累计上千次,并拥有多项云计算专利、软著。王璞于2020年评选为腾讯云TVP。
•采用软硬件融合的方式解决混合云场景下远程数据访问的性能问题
•软硬件分层思想以及软硬件融合对系统设计带来的挑战
•引入计算模型概念,以及做软硬件设计时需要考虑的点
•并行计算模型给软硬件系统带来性能的提升,介绍常见的并行计算模型
•介绍几种常见的并行计算模型的硬件架构
•软硬件在并行场景下遇到的几类协作与冲突问题以及解决方法
•基于 RDMA 的软件系统设计思路,解决高性能存储数据传输的问题
很高兴来跟大家分享一下我们最近的工作,那天国强跟我说正好今天有两个 RDMA 相关的话题,那我就换一个角度讲,不再讲 RDMA 的很多细节了。因为可能很多朋友或多或少都有些了解,我主要从另外一个角度,就是硬件融合的角度,这个也是现在比较热门的一个话题,可能很多朋友有软件背景或者有硬件背景,但是可能软硬件都搞的人确实不多,对吧?讲一些我们在软硬件 CoDesign 方面的一些思考。
01 Geo-distributed Storage System
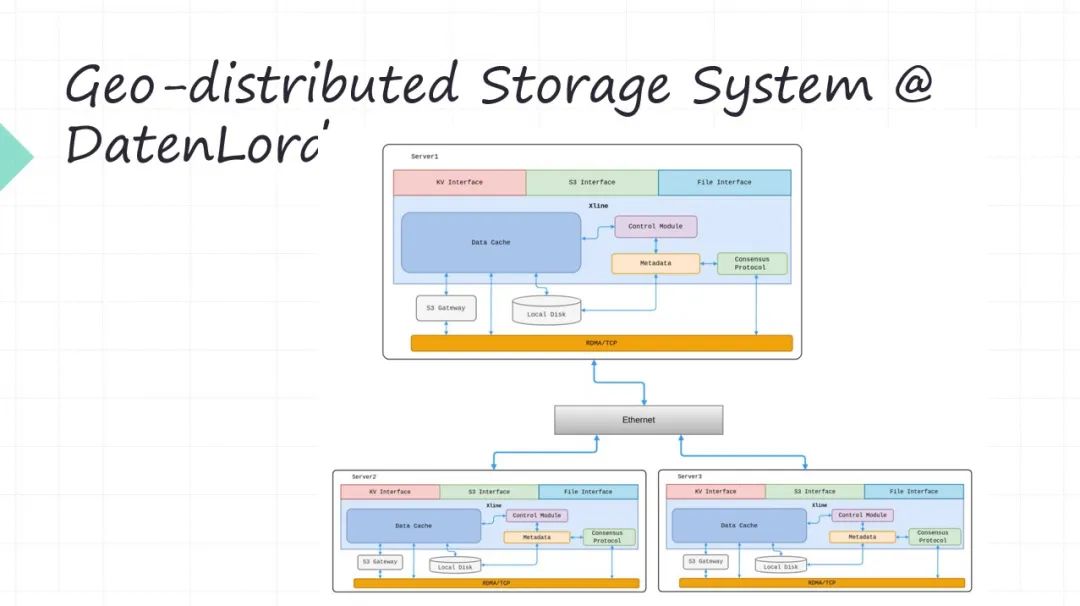
我先简单介绍一下我们为什么要搞软硬件融合。首先我们公司是 DatenLord,我们做的是叫 Geo-distributed Storage System。怎么理解 Geo-distributed Storage System ?就是说不同的节点,它是在不同的 Data Center,Data Center 之间有专线去连接(或者说这个上面是公有云,下面是私有云,中间是专线的连接)。这样的这种比如多 Data Center 或者所谓 multi cloud 这个场景,现在是很多企业客户都在关注这个场景,所谓的多云,所谓混合云等等。
这些概念里边一个很头疼的问题就是我的业务系统部署在不同的地方,跨 Data Center 最痛苦的就是上面的数据怎么办?你的业务系统,比如现在都是打包成 Docker, WebFamily 或者 Serverless 这些形式去部署,部署是很灵活的,对吧?甚至现在像Serverless 将应用部署在哪里提前都不知道的。但是部署之后你的应用程序一定是会访问数据的,对吧?数据先天又不是那么灵活的。数据绝对不是我们想放哪就放哪,想从哪访问就从哪访问。所以现在数据的远程的可访问性,这就是对于这种多云或者混合云架构带来的最大的问题,所以我们就想尝试解决这个问题。
就是你的业务系统部署在任何的地方都可以,当然也不是任意的,肯定有所谓的亲和性的部署,但是有一定的灵活性。比如你的业务可以部署在多个 Data Center,部署在多个云上。下面的数据可以远程去访问,数据去搬迁这个事是吃力不讨好的,那我们能不能让数据的远程访问的性能大幅度提升。
所以就是为了解决远程数据访问的问题,所以我们用软硬件融合的方式来把它的性能大幅度提升。因为远程数据访问单靠软件是无法解决的,单靠硬件也没办法去搞。这是我们为什么要采用软硬件融合的方式。
02 System Design Abstraction
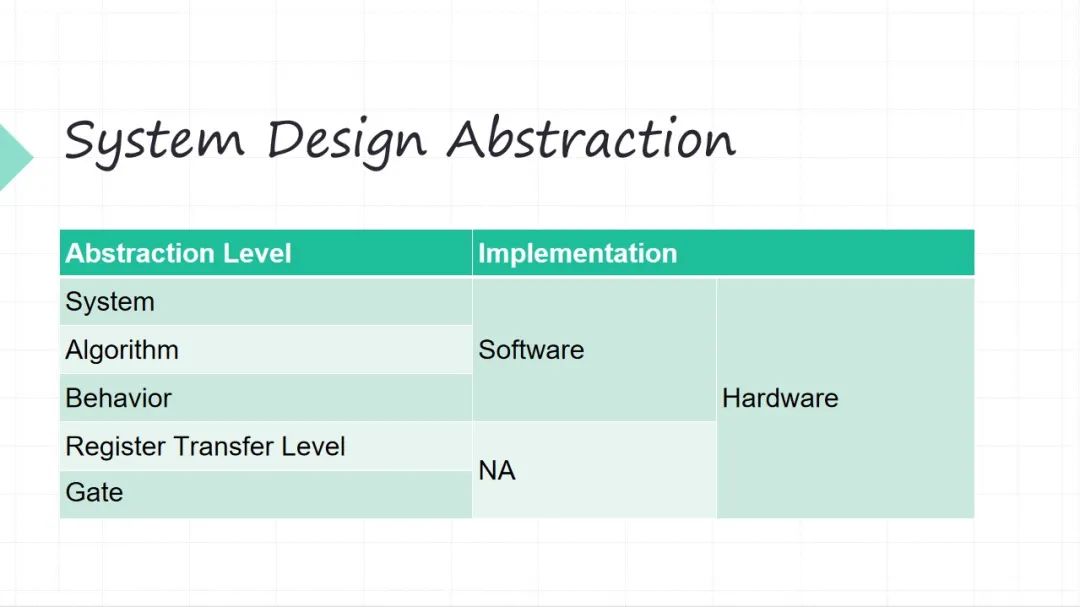
接下来简单的列一下,我们从一个软硬件系统的角度看我们设计的抽象层次。从上往下越来越细。上面系统整体的抽象层次,下面的算法层面,再往下行为级的层面(行为级这层面可能有些软件同学可能不太理解,举个例子,你的加减法操作,在软件里面你不会再关心加减法操作怎么实现了),这三个层级软件硬件都可以干(系统级、算法级和行为级)。再往下两个层级、寄存器级和门级,当然还往下还有晶体管级,这些层级只能硬件干了。
所以这是不同的抽象层级软件融合,其实比较大家一直来讲比较难的一个点就是抽象层级融合起来以后会被打破。以前我们做软件的人不会考虑硬件这么多细节,基本上不太考虑寄存器这些东西了,但是到了硬件的跨度很大,很底层的东西我得考虑,很上层的整体系统我也得考虑。所以这就是软件融合带来的一个设计上的挑战。怎么去沿着原来一致的思路?比如我做系统的时候,思路不能割裂(这个事一个思路,另外的事情又个思路,这是很痛苦的),我做这种大的工程的时候,希望我的思路是一致的。
03 Software Design

简单回顾一下软件的题材,思路是比较容易理解的,我们先做架构设计,做完架构设计看看算法怎么回事,然后去实现,去测试。软件的架构和硬件都是不一样的,软件的架构我们很多时候考虑好,比如单线程还是多线程,你是单点还是分布式等等。所以软件里的一开始先考虑架构,我们基于现在架构设计,大家去开始实现,最后测试一下。
04 Hardware Design

硬件的设计的起点,就不一定再从架构开始了,因为硬件比较 low level ,硬件的设计的起点是计算模型 Model of Computation ,计算模型之后才是架构算法等等实现, 然后是验证 Verification 。
05 Model of Computation

这个计算模型是什么?这最经典的两个计算模型:图灵机 和 Lambda 演算对吧?我们今天 CPU 都是 图灵机 这种模型,所以为什么前面讲我们做软件的时候不会上来先考虑你计算模型?是因为我们做软件大家默认底下是有 CPU 的嘛。所以 Model of Computation 对于软件来讲是定死的,但对于硬件我们可以采用不同的计算模型。
虽然 图灵机 我们用了很多,但是 图灵机 也带来了很多的问题,比如典型我们为什么要做软件硬件 Coding ?因为大家发现软件很多时候处理大量数据效率并不高,因为 图灵机 它的抽象是指令加数据,所以 图灵机 很擅长的是做控制,指令都是控制对吧,指令里面带了一点点数据。但是你做大量数据的处理的时候,其实今天看来为什么大家用 GPU 加速?其实 GPU 每一个 Core 还是 图灵机,但是 GPU 一堆并行,所以想做大量数据处理的时候一定要并行,只有并行才能加速。但是 图灵机 它是个串行模型,所以软件本质上是串行的模型。当然今天还有多核,但多核的利用效率并不高,在并行的程度上。
所以这两种计算模型,一个是基于是经典的 图灵机,我们的软件编程主要是 面向过程,从 C 开始面向过程。另一个 Lambda 演算,它后来衍生出来的就是函数式编程。函数式编程今天大家用的时候,起源就是 Lambda 开头的。所以大家看软件的发展也是。从单点到觉得单点计算能力有限,纵向扩展 scale up 的空间是很有限的,开始做横向扩展 scale out,软件不叫并行,我们叫分布式。软件分布式的时候不好搞,这个时候借鉴了很多函数式编程。 今天我们写很多高级语言的时候,比如像 RUST 之类的这些语言的时候,里面大量的采用了函数式编程的一些特性。为什么?因为这是底层的 Model of Computation 带来的不一样, Lambda Calculus 它就没有什么指令和数据,它靠的是缩减递归这些东西,所以他的演算的逻辑和图灵机是本质上的不一样。
这个是我们一直在探索的,解决不同的问题需要用不同的 Model of Computation ,这是一个很大的挑战。今天基本上几乎所有的软件都是基于 图灵机 模型,当然有这么多年积累,肯定是有很多好处,但是缺点也很明显,处理大量的数据,处理海量数据,性能跟不上了。提升性能?从软件的角度对吧,借鉴一些 函数式编程 做分布式并行,这是一个维度。但是这还不够,这还是在偏软件层面。下一步我们想更深入地去压榨性能,让硬件先天并行的。
06 Software v.s. Hardware
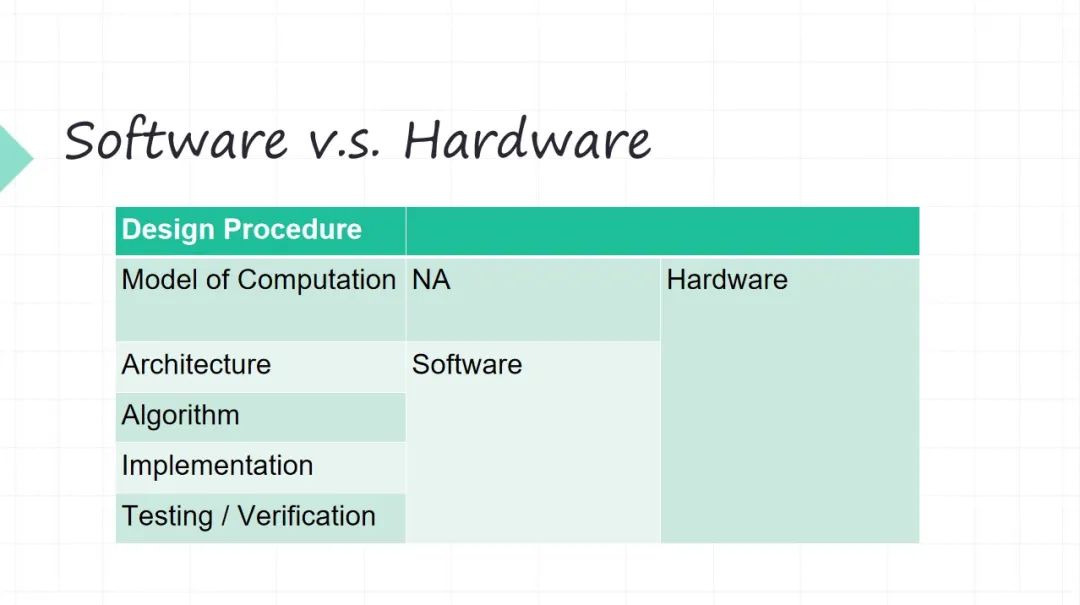
简单地回顾一下,软件的时候基本上是 Model of Computation ,我们很难去改变,即便今天用这种并行编程,但它底层还是跑到 CPU 上的,CPU 的计算模型是 图灵机 模型。
当然早期(大概上个世纪七八十年代)也有人研究基于类似 Lambda Calculus 那种所谓数据流的方式做 Data Flow 模型,也是一个当年很热的研究,但是后来输给了 图形机,还是 图形机 变成了 CPU 最主流的架构。所以硬件我们在迭代的时候,根本问题就得考虑好。软件我们没有人再去考虑, 图灵机模型就是一个前提假设,但硬件我可以突破 图灵机模型。
当然今天有很多硬件,比如 Google 做 TPU( TensorProcessing Units) 的时候用的也还是 图灵机冯诺伊曼这套模型。但是它不一样, Google 做 TPU 的时候,它的指令很少,四五条指令,指令的力度是非常非常粗的。不像 CPU x86 几千条指令, RISC-V 都得上百条指令(这肯定有的)。
所以在硬件我们再来设计的时候,我们就必须根据你要做的计算任务,从 Model of Computation 出发,才有后面的东西。如果没想清楚,后面在硬件上面,你做架构,做算法,做实现,后面无从谈起。
07 Model of Computation for Parallel
前面跟大家讲了 Model of Computation 计算模型的概念。刚才讲硬件先天并行,今天虽然有多核,但是软件来源于图灵机,它是个串行模型。我们今天所谓做性能加速,其实本质上就是把以前串行的事该变成并行的,这样速度就能快了。
刚才讲了,硬件我们设计的时候,第一步就要考虑计算模型是什么?计算模型这个东西,其实计算机系统过去几十年的研究已经研究得很透彻了。在这举了两相对常见的,对于并行场景来讲,我可以采用什么计算模型?这就不是 图灵机,也不是 Lambda Calculus。
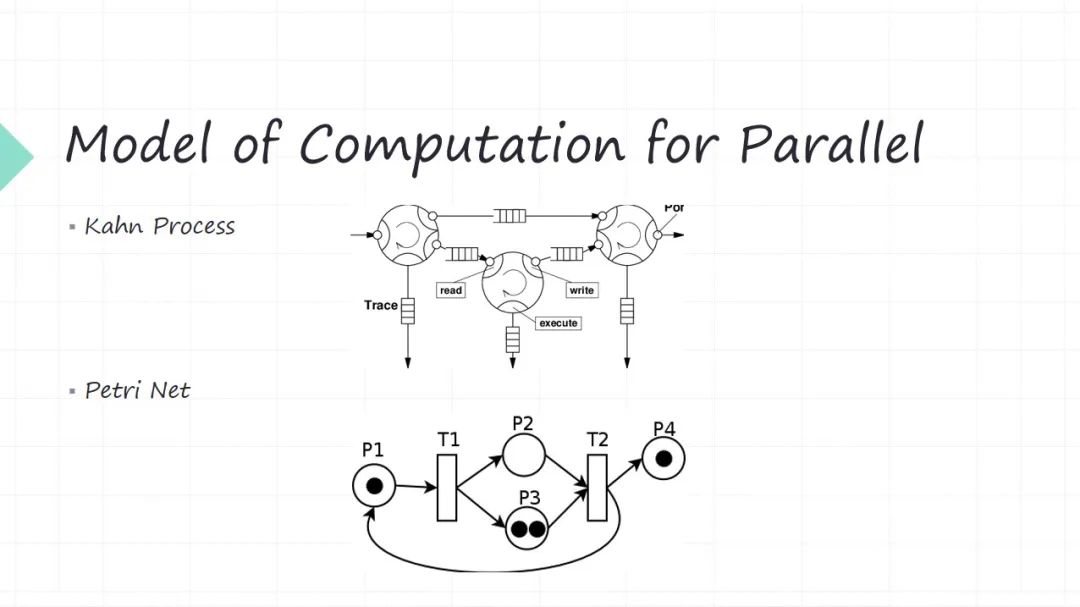
第一个模型叫做 Kahn Process,名字大家不一定那么熟悉,但是其实它的理念很简单。每个节点是我的功能模块,一个是生产者,另一个是它的消费者。生产者生产出来这些数据或者消息传给消费者,消费者可能又是别人的生产者。所以其实就是生产者消费者问题,只不过这些生产者消费者之间的逻辑关系是一个网状的,最后形成的 DAG 有向无关图。还有很重要一点,这些消息中间都有个队列给你缓冲一下。它假设是这些队列是无限长的(这是一个数学上的一个很大的假设)。所以。生产者来生产数据的时候,你队列是无限长的,所以写操作是无阻塞的。消费者在读取数据的时候,接收消息的时候是有可能阻塞的,因为你这个队列有可能是空。它就是个并行的模型。
第二个模型叫做 Petri Net,可能有的朋友听说过,这也是很常见的一个并行模型。它也是生产者和消费者模型,只不过它的建模方式和上面不一样,它中间没有所谓的缓冲队列了,通过 transition 的关系来建模。圆圈代表不同的功能模块(代表生产者),黑点代表生产资料。比如生产者(P1)黑点经过 transition 或者一个动作,它可以生产出两个数据分别给到两个消费者( P2 P3),这两个数据是相同的数据,这两个消费者( P2 P3)他拿分别拿到不同数据,他就可以变成生产者( P2 P3)。这两个生产者都得生产出来数据才能给到后面的消费者(T2)。
并行模型中每一个功能模块可以同时工作,只不过有的时候你上游数据不 ready,你这时候没有数据让你去处理。这种模型在于硬件建模是非常方便的,因为硬件它先天就是并行的。但是又不是那种 free parallel,并行工作时候你要定期去 sync ,比如模块都是生产者也同时都是消费者,你什么时候有数据可以消费,你什么什么时候生产数据,你下游不 ready,你生产出来数据会不会丢掉等等各种各样配合的问题。
这就是计算模型就把这些问题给你抽象出来,大家并行的时候提升性能,但是并行不是代表大家各自去自由地去跑,一定要有中间的协同,这些就是 Model of Computation 带来的。所以这就是我们做软件融合系统的时候,一定第一步把这个问题要想清楚,你到底解决这个问题,它是用什么样的一个计算模型来跟他进行抽象。这些想明白的时候,剩下的东西就变得相对简单一些。
08 Architecture in Hardware

刚才讲的是并行的计算模型,接下来对硬件的阶段来讲,计算模型定好之后,接下来定下硬件的架构。常见的硬件架构,我这列了几个
•有限状态自动机(FSM),这是很常用的一个硬件模式,但状态机它的一个缺点是什么?状态机本质它是个串行模型(现在是第一个状态,什么时候到第二个状态,什么时候第三个状态)。
•流水线(Pipeline), 是个很经典的硬件的一个并行东西,只不过流水线的不同阶段处理不同的数据,但它们是在一起来工作的。
•Replica,你的模块想并行工作,怎么办?在硬件上我也可以搞多份。比如我的加法器和乘法器,1 个不够用,来 10 个,100 个。
•脉动阵列(Systolic Array),是现在神经网络里面用的很多。它是一个阵列的方式,数据在上面不停地流动每一个方框,这是一个处理节点。
所以大家看硬件设计的时候,对和软件就很不一样,这是常见的硬件的架构图,我们软件不会画这种架构图,因为硬件它最后你放到硅片上,在硅片上画的东西它是个二维结构
09 Single-core Issue
硬件并行带来了很大的问题,并行模块之前的协同是 Model of Computation 解决的问题。
还有一个重要的问题就是硬件并行工作,一定会导致冲突。例如两个不同模块,你去竞争的写同一个地方,或者一个读一个写,你希望先看到读的结果还是先看到写的结果等等。所以冲突管理这是并行的时候一定要解决的。
•Control 冲突,比如你指令的跳转带来的冲突问题,这因为指令是流水线,同时有多条指令在执行,你多条指令同时执行,带来的冲突。
•Data 冲突,先读后写还是先写后读。
•Resource 冲突,CPU 里边加法器,乘法器和 Cache 是有限的。那对于资源的竞争冲突访问,这也是冲突。
10 Multi-core Issue

多核带来的问题可能对于软件的同学感受比较深一些。比如多核带来了一个很头疼的问题,就是内存一致性的问题。多个核的竞争的往内存里读写,这个时候你内存的数据怎么才能称之为是一致的?定义了几种 Memory Order 的一致性的级别。
•顺序内存一致性 Sequential Consistency ,假设大家虽然是并行目的,但是顺序地来读写内存显然不会出错,但是显然 sequential 太强的要求了,你想要性能的时候 sequence 为了保证正确性,得是串行的来。这跟我们对性能的要求是冲突的。
•Total Store Order 就是 X86 的默认的 Order,先 store 后 load,可以乱序。
•Multi-copy Atomic 就是 RISC-V 的默认Order。你个核先写的东西自己可以看见,如果别的核看见,都得能看见。
在借鉴 CPU 体系结构过往的一些工程经验里边,已经有很多实践去来解决并行工作带来的数据冲突的问题。这块是个很麻烦的问题,我们做软硬件设计的时候,这些问题你都会碰到,因为你做数据处理,一旦并行的时候,这些问题自然而就来了。而且我们做计算的时候很少碰到那种场景是纯并行,完全不用考虑互相的协作,是很少很少的场景。
11 Parallel vs Distributed

不管是并行也好,还是分布式也好,是冲突的问题,我们去怎么去解决它。其实从软件和硬件角度我们都有大量的工作。
•比如 分布式一致性 算法,像 Python 算法常用的 Raft 协议等等,它们也是在解决冲突的,只不过是在一个时间维度很大的的维度上(比如毫秒级,网络传输都基本上都是毫秒)。
•到了 内存一致性 问题的时候,这个时候就到了一台服务器了,这时候它的时间维度大概是微秒或者亚微秒,大几十纳秒等等。
•到了 CPU 里头,这就是变成 Cache一致性 问题,考虑就是纳秒级的问题了。
所以其实我们在做一个复杂的系统(计算机系统或者数字系统)的时候,为了解决性能问题,大量的用并行或者用分布式来做加速做肯定快。但是并行或者分布式加速带来的问题就是冲突。其实协作还是小问题,冲突是最大的问题。冲突怎么做?其实有很多现有的方案,只不过这些方案不一定是大家每个人都天天在研究的东西。但是当我们下沉到软硬件协同设计的时候,这些问题就通通都暴露出来了,为什么会暴露出来?我们平时写软件,我们我有一定的抽象,但是当我软硬件联合迭代的时候,这些抽象就打破了,所以你只能从根上你把这个问题想明白。
12 Conflict Resolution in Hardware

怎么解决冲突这个问题?其实都有很多开源的库去解决它,每个语言里边都有。硬件里面的冲突管理怎么做的?其实 CPU 的体系结构的研究里面讲了不少,比如一个核里的流水线,各种 hazard 这些。
但是推而广之,如果一个硬件系统,特指数字硬件 IC 这种系统,如果我们造的不是 CPU,今天做软件融合的时候,大概率底下硬件系统不一定是个 CPU,这个时候怎么解决这些冲突?其实借鉴的方法跟软件的思路是一致的,本质都是个都是并行工作带来的冲突。所以解决问题的思路是一致的,只不过具体的方法不一样。
•弹性 Elastic ,软件是很灵活很弹性的,但硬件没那么弹性。硬件我在设计的时候,协议层面让大家互相的消息传递要变成弹性,对这个消息的 delay,要对 delay 变得不敏感(不要假设过多长时间,我把消息发给你),这些消息的 delay 你是不可控的,什么时候消息传递成功等等。
•保证原子性 Atomic。比如大家我们做分布式系统的时候,基本上都有一个分布式一致性的,一个节点或者一个服务保证原子性。硬件也一样,各种冲突我也得保证原子性,其实本质上就是个 transaction 的概念。怎么保证?就需要你底干上有一些东西,所以原子性是不好做的。比如软件里面大家用所谓各种无锁操作,其实本质上就是用 CPU 直接提供原子操作。
•调度 Scheduling ,本质通过优先级来解决冲突问题(冲突是不可避免的)。冲突的时候谁优先级更高,谁优先级更低。
当然这几个方法,可能弹性相对还好处理一点,有硬件协议来做,剩下的原子性,还有 Scheduling 都得我们设计硬件的都想得很清楚。
13 RDMA Software/Hardware Co-design
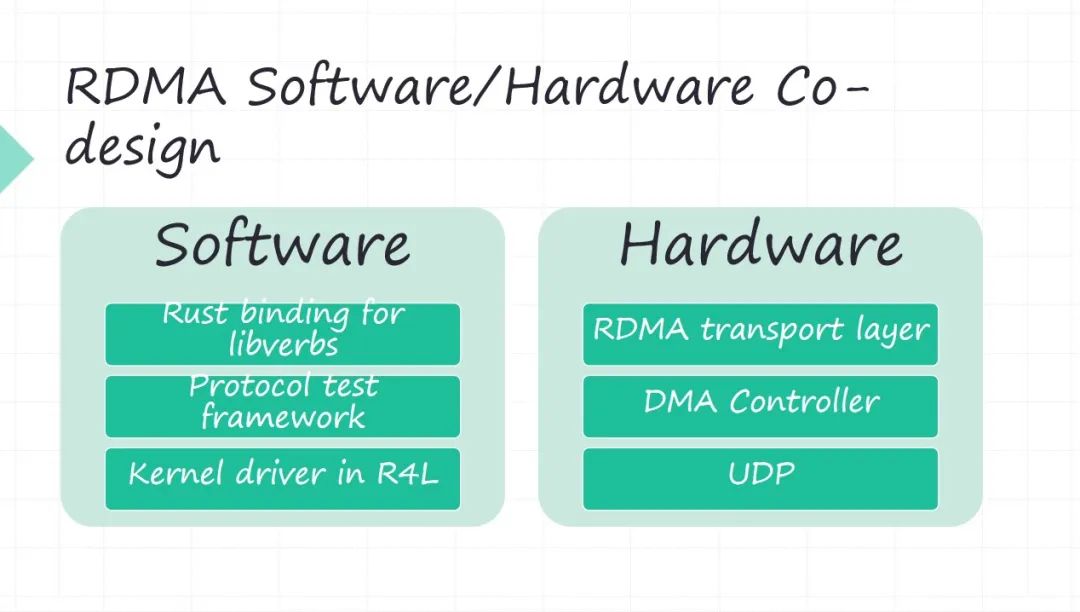
以我们做 RDMA 这样一个软件系统,给大家简单介绍一下我们的思路,就说我们用 RDMA 主要是解决高性能存储数据传输的问题。 RDMA 本质其实也是软硬件的一个系统。我们为什么自己做 RDMA 的硬件,是因为 RDMA 商用的卡里边有一些不够灵活的地方,比如 RDMA 的拥塞控制,今天基本上就两种解决方案,一种你就买 InfiniBand 的那套商用的方案。
但是当今数据中心我们大量用的交换机路由器还是以太网的。你要用 InfiniBand 的解决方案,那跟以太网的交换记录器的协议都不一样,虽然也可以融合,但是肯定不是个很优的方案,再加上成本的考虑。
今天 RDMA 落地数据中心大部分都是 RoCE 方案,所以我们也是采用 RoCE 方案, RDMA 跟以太网融合。但 RoCE 方案最大的问题是什么?流量控制对他来讲是黑洞。为什么这么讲?你看,比如像 InfiniBand 它解决 RDMA 的流量控制问题,他从他的链路层,网络层,传输层,每一层都要去解决这个问题。但是到 RoCE 的时候就没那么容易了。
RoCE 是把 RDMA 的传输层嫁接到了 UDP 上, UDP 根本没有任何的流量控制和拥塞控制的管理能力,只用 RDMA 的传输层, RDMA 传输层只有很少的流量控制,而且 RDMA 传输层没有拥塞控制能力。今天所有的 RDMA 的流量控制和拥塞控制,都是靠额外的算法在外层去来解决这个问题。
我们为了实现高性能传输的时候,就要流量控制和拥塞控制,特别是拥塞控制。我们觉得这个问题对我们是非常关键的,所以我们自己去搞硬件。而且拥塞控制这个东西,它还不是纯硬件能解决的,上面还有软件的很多东西。当然这些问题我们今天还没有解决完。所以我这列的时候没有提很多流量空投有所控制的问题。但是如果感兴趣,是网络研究的一个很大的热点。
我们做 RDMA 软件和硬件的时候,其实功能模块还是比较容易理解的。
•软件首先就是 RDMA 的 API,因为我们软件有 Rust,我们把它做了一套 RDMA 的 API 的 Rust binding forlibverbs。再一个 RDMA 的测试是没有什么开源的方案,所以我们自己搞了一套协议的一个测试框架。再一个还有驱动的部分(硬件必然会有驱动),今天我们看 Linux 内核已经开始采用 Rust,我们正在看用 Rust for Linux 怎么来做一个驱动,前期做了一些调研,但目前还不太成熟,所以我们还没有真正上手在干。回到硬件这端 RDMA 的传输层,是要硬件实现好。
•硬件里边 DMA 基本是 RDMA的性能瓶颈, DMA 系统的最大的 delay 都是 PCIE 带来的。基于 PCIE的 DMA controller 怎么做高性能的 DMA 操作。包括现在新出 CXL 协议出来之后,会很大程度上解决 DMA 的性能问题, CPU 和你的外设是在同一个地址空间,再也不需要做什么内存的地址空间和 PCIE 地址空间 mmap 的问题了。
•再一个就是 RoCE 方案,是用 UDP 来传输的。 UDP 也搬到硬件上去实现,需要实现的这些组件。
14 RDMA Software
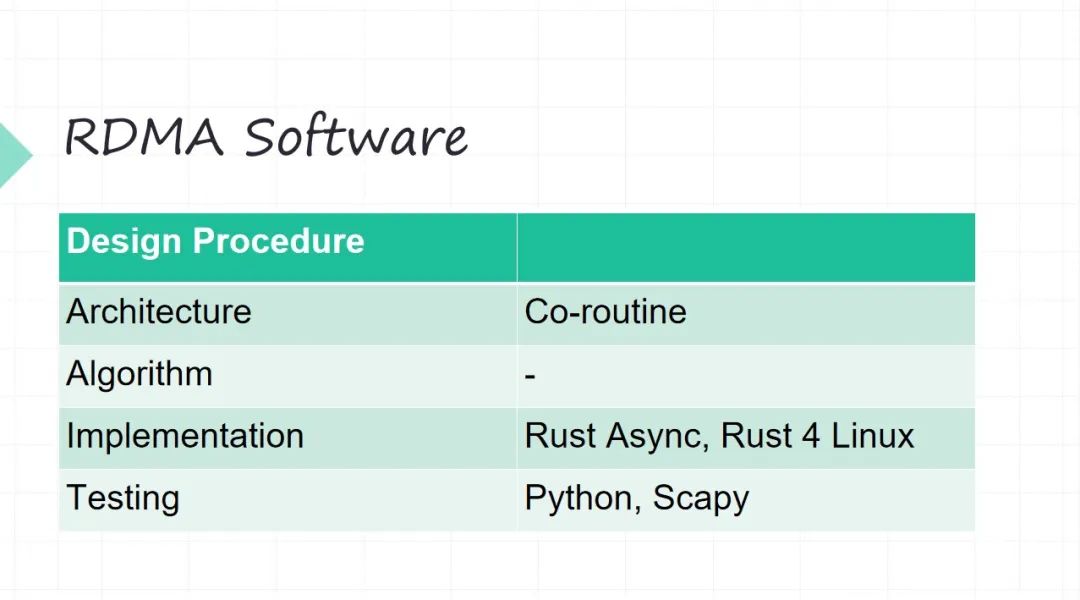
但是在实现的时候,几个底层的抽象就不一样。软件可能相对好想一些,你不需要考虑 Model of Computation ,你软件是 图灵机 模型。
•软件的架构。这个时候我们选一个架构,比如上面 RDMA 的这些 API 等等,我们都用协程的方式(不希望用线程这种模型,因为线程要内核来调度,我们不希望做很多的上下文切换)。
•算法不太涉及, RDMA 网络协议不太涉及太多算法。
•软件我们主要是用 Rust,Rust 里面就是Rust Async。驱动在内核里面用 Rust for Linux 。
•测试我们主要用 Python,在 Python 里面主要用 Scapy做网络包的一个测试,很常见的框架。
15 RDMA Hardware
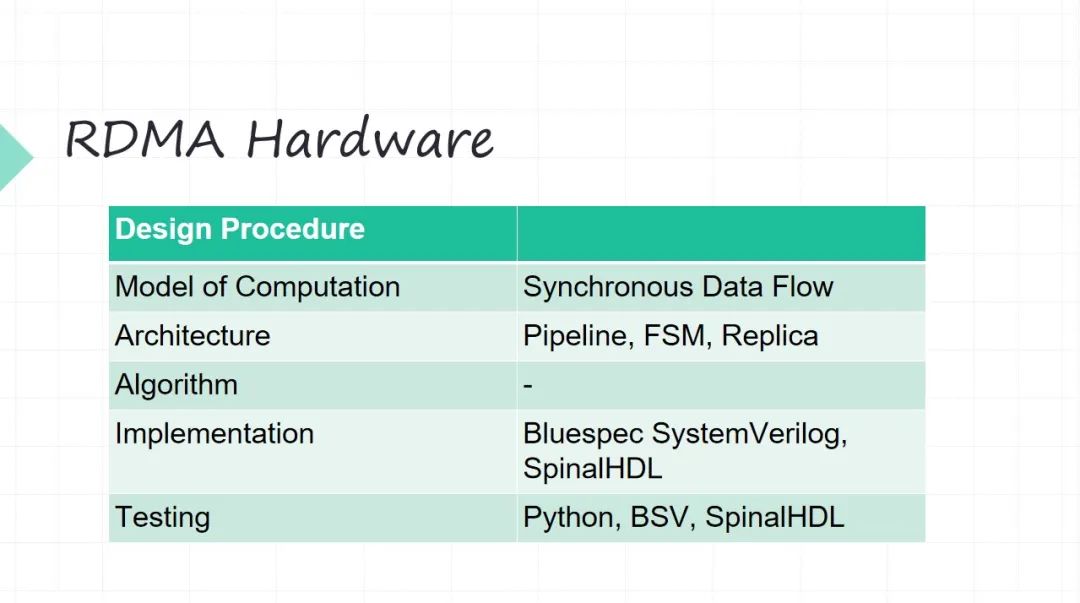
硬件的设计要从 Model of Computation 开始了。因为 RDMA 它是个网络协议不是 CPU ,网络协议主要是做数据传输。
•它的 Model of Computation 我们选择的是叫作同步数据流模型。其实它本质上是一个前面介绍 Kahn Process的简化。最大的简化在于好我不同的生产者、消费者中间之间缓冲 FIFO,我这是要管理的(它不可能是无限的,硬件没有那么多无限的资源)。同步数据的模型 它的一个很大的优点就是做了比较强的一些假设,就是每个生产者每个时刻产生一个数据,每个消费者每个时刻接收一个数据,这样有了很强的一个假设之后,好我中间缓冲,我就可以精确地算出来了。有了 同步数据流模型之后,你的这些并行之间的调度问题也可以提前做一些安排。
•架构层面这就是用一些硬件经典的架构,比如 pipeline 流水线架构。像网络数据进来之后,很长的一个流水线,我们最长的流水线也大概十七八级了。状态机也少不了。整体的并行控制等等。比如 RDMA 它不同的队列对吧?不同的 QP(Queue Pair),预先设好有多少个 QP,靠不停地去在硬件上去复制它。
•算法不涉及。
•Implementation 的时候,我们没有采用 Verilog 传统的硬件开发语言。用一些比较新的 Implementation 的硬件描述,主要的考虑也在于尽可能提高开发的效率。用两个东西,一个是 Bluespec SystemVerilog,一个是 SpinalHDL。
•测试的时候,我们现在做一些基于 Python 来做硬件的 Verification。当然这两个开发语言本质它也要写很多测试验证的问题。
这个是我们整个迭代硬件的一些思考和价值。
编辑:黄飞
-
RDMA设计12:融合以太网协议栈设计12025-12-25 1693
-
KubeCASH:基于软硬件融合的容器管理平台2024-01-08 2916
-
软硬件融合的概念和内涵2023-10-17 3266
-
浪潮云海新一代超融合发布 全栈RDMA焕发优质性能2023-06-05 1855
-
为什么要从“软硬件协同”走向“软硬件融合”?2022-12-07 4137
-
软硬件协同设计是系统芯片的基础设计方法学2022-08-12 4803
-
软硬件分离编程的相关资料下载2021-12-16 1135
-
STM32学习笔记1——软硬件基础之keil5编程与GPIO开发2021-11-30 1354
-
2021 OPPO开发者大会主会场:软硬件融合技术升级2021-10-27 2147
-
基于FPGA芯片的软硬件平台的使用2021-07-01 2411
-
FOC电机控制软硬件设计及动手实践的资料合集免费下载2021-02-02 2201
-
基于FPGA的软硬件协同测试设计影响因素分析与设计实现2017-11-18 2497
-
USB的串行通信软硬件设计2017-09-04 1208
-
支持过程级动态软硬件划分的RSoC设计与实现2010-05-28 2013
全部0条评论

快来发表一下你的评论吧 !
