

MAXQ指令集架构与RISC竞争对手的基准比较
描述
本文将MAXQ指令集与竞争微控制器进行比较,包括PIC16CXXX(中端器件)、AVR和MSP430。下表详细介绍了每个指令集和体系结构的优缺点。我们将使用选定的代码算法和操作来判断代码密度和代码性能。最后一节介绍并重点介绍了每个代码示例的MIPS(每秒数百万条指令)/mA比率。
MAXQ指令集概述
MAXQ指令集建立在传递-触发概念之上。指令字仅由源操作数和目标操作数组成。虽然这些源和目标操作数可能表示物理寄存器,但编码也可以表示数据存储器、堆栈存储器和工作累加器的间接访问点,和/或可能隐式触发硬件操作。特定MAXQ器件的源和目的编码在与MAXQ器件相关的MAXQ用户指南中定义。虽然有些源和目的编码可能是特定于器件的,例如指定用于外设硬件功能的编码,但某些固定编码用于构建MAXQ基本指令集。图1给出了MAXQ指令字和指令集助记符。

| 记忆 | 描述 | 记忆 | 描述 |
| 位操作 | 逻辑 | ||
| MOVE C, #0/#1 | 清除/设置进位 | AND | 逻辑和 |
| CPL C | 补体进位 | OR | 逻辑或 |
| AND Acc. | 逻辑和带累加器位的进位 | XOR | 逻辑异或 |
| OR Acc. | 逻辑或带累加器位的进位 | CPL, NEG | One's, Two's Complement |
| XOR Acc. | 带累加器位的逻辑异或进位 | SLA, SLA2, SLA4 | 算术左移 1,2,4 |
| MOVE C, Acc. | 移动累加器钻头进行携带 | SRA, SRA2, SRA4 | 算术右移 1,2,4 |
| MOVE Acc.,C | 将进位移至累加器钻头 | SR | 逻辑右移 |
| MOVE C, src. | 移动寄存器位进行携带 | RR, RRC | 旋转右进位(防/进)独占 |
| MOVE dst., #0/#1 | 清除/设置寄存器位 | RL, RLC | 旋转左携带(防/入)独占 |
| 数学 | 数据传输 | ||
| ADD, ADDC | 添加进位(防/入)独占 | XCHN | 交换累加器数据半字节 |
| DJNZ LC[n], src | 减去进位(前/内)排除 | XCH (MAXQ20) | 交换累加器数据字节 |
| 流量控制和分支 | MOVE dst, src | 将源移动到目标 | |
| JUMP {C/NC/Z/NZ/E/NE/S} | 跳跃 - 无条件或有条件,相对或绝对 | PUSH/POP | 推/弹出堆栈 |
| DJNZ LC[n], src | 递减计数器,跳跃不为零 | POPI | 弹出堆栈并启用中断 (INS<0) |
| CALL | 调用 - 相对或绝对 | 其他 | |
| RET {C/NC/Z/NZ/S} | 返回 - 无条件或有条件 | NOP | 无操作 |
| RETI {C/NC/Z/NZ/S} | 从中断返回 - 无条件或有条件 | CMP | 与蓄能器比较 |
图1.MAXQ指令字所示的源到目的地传输产生一个小但非常强大的指令集。
| 国际海底管理局 | 强度 | 弱点 |
| AVR |
32个通用工作寄存器(累加器) 数据指针是直接可寻址工作寄存器的一部分;允许对高/低指针字节进行轻松屏蔽和位操作。 从指针读取 + 位移(0 到 63 字节位移) 堆栈仅受内部 RAM 限制(没有 RAM 的 90S1200 除外,则堆栈深度 = 3) 单周期操作 相对跳跃 ±2k(双周期) 所有AVR都有数据EEPROM 设置/清除每个状态寄存器标志的明确说明;大量位操作指令 分离的间向量 |
流水线指令提取 超过 32 个注册,负载 (LD)/存储 (ST) 开销成为 LD/ST 的一个因素 @X,Y,Z = 两个周期,LPM = 3 个周期 减少了对文字操作的支持/范围(没有ADDC,EORI;只有CPI,ORI,ANDI,SUBI,SBCI,LDI在R16-R31上的工作) 无旋转指令,不包括携带 条件跳跃范围仅 +63/-64(双周期) 呼叫/重新/重新输入 = 四个周期 |
| 图16CXXX |
源,编码为 ALU 操作的目标位 直接数据访问(符号寻址模式)可以产生密集的代码,有利于数据叠加 |
四时钟内核导致执行速度差 流水线指令提取 访问上层数据存储器组需要分页 (RP1:0银行选择) 需要间接数据访问 INDF、FSR 寄存器 无法直接加载W(累加器) 无 ADDC, SUBB 堆栈深度 = 8 没有相对跳转/分支 - 只有绝对跳跃(CALL,GOTO)或条件跳跃(BTFSx) 用于代码存储器读取的 RETLW = 浪费的代码空间,并且不允许代码空间的 CRC CALL/GOTO/RET/RETFIE/RETW 都需要八个时钟周期(两个指令周期) 单中断向量 |
MAXQ与其他指令集架构的比较
可以尝试将MAXQ指令助记符与其他架构的指令助记符进行比较,但这种分析既困难又不合理,因为每个指令集都是围绕特定的器件资源和寻址模式构建的。因此,指令集和器件架构(指令周期、存储器模型、寄存器集、寻址模式等)是不可分割的,必须一起考虑。表1总结了所比较的指令集架构的优缺点。
代码示例
比较指令集架构的最佳方法是定义一组任务并编写代码来执行这些任务。以下各节描述了要执行的某些任务,并总结了每个指令集体系结构的代码密度和性能结果。第一个例程的示例代码包含在文档中,而随后的例程将仅用图形和文本进行汇总。Maxim可根据要求提供与每组统计数据对应的代码例程。
| 国际海底管理局 | 强度 | 弱点 |
| MSP430 |
广泛的源,目标寻址模式在操作码中编码 - 可以产生密集代码 16 位内部路径 内部存储器可作为字或字节访问 常量发电机 (CG) 用于 -1, 0, 1, 2, 4, 8 单周期操作 堆栈仅受内部 RAM 限制 条件/相对跳转目标范围 = ±512(双周期) 单独的中断向量,自动清除单源标志 |
冯·诺依曼记忆图+精心设计的寻址模式=多个周期。唯一的单周期指令是那些专门处理Rn的指令。 外设寄存器访问 = 三到六个周期 CG不支持的文字需要额外的单词 目标操作数不能注册间接或注册间接自动增量 寄存器间接不支持自动递减 符号寻址限制了重用代码例程的能力 |
| MAXQ |
系统和外设寄存器可作为同一逻辑存储器空间中的源或目标进行访问,从而实现最快的数据传输 单循环运行,无流水线 单周期条件跳转(+127/-128)或双周期绝对跳转(0-65,535) 单周期呼叫/重新/重新输入 自动递减环路计数器寄存器消除了维护计数器时通常浪费的开销 累加器(工作寄存器)文件的自动递增/递减/模控制 每个数据指针的可选字或字节访问模式 可前缀的操作代码允许简单的指令集扩展或增强方法 |
主动累加器始终是 ALU 操作的隐式目标 单端口、同步、SRAM 数据存储器要求在使用前激活(选择)数据指针 默认堆栈深度 = 16,但是,数据指针硬件非常适合在数据存储器中实现软堆栈 |
内存副本 (MemCpy64)
存储器复制示例演示了微控制器间接操作数据存储器块的能力。任务是将 64 个字节从数据存储器源位置复制到不重叠的数据存储器目标。以下页面提供了每个微控制器的代码例程,以及汇总复制操作的周期计数和字节计数的图表。这些例程假定在复制操作之前已经定义了指针和字节计数,并且要复制的字节在存储器中是字对齐的,因此可以使用MSP430和MAXQ20的字访问模式。
;======================================AVR======================================
; ramsize=r16 ;size of block to be copied
; Z-pointer=r30:r31 ;src pointer
; Y-pointer=r28:r29 ;dst pointer
; USES:
; ramtemp=r1 ;temporary storage register
loop: ; cycles
ld ramtemp,Z+ ; 2 @src => temp
st Y+,ramtemp ; 2 temp => @dst
dec ramsize ; 1
brne loop ; 2/1
ret ; 4/5
;---------
;(7*bytecount) + return - 1(last brne isn't taken).
; WORD COUNT = 5 ; CYCLE COUNT = 451>
;=====================================MAXQ10====================================
; DP[0] ; src pointer (default WBS0=0)
; DP[1] ; (dst-1) pointer (default WBS1=0)
; LC[0] ; byte count (Loop Counter)
loop: ;words & cycles
move DP[0], DP[0] ; 1 implicit DP[0] pointer selection
move @++DP[1],@DP[0]++ ; 1
djnz LC[0], loop ; 1
ret ; 1
;----------
; 4 / (3*bytecount) +1
; WORD COUNT = 4 ; CYCLE COUNT = 193
;====================================MAXQ20=====================================
; Assuming bytes are word aligned (like MSP430 code) for comparison
; DP[0] ; src pointer (default WBS0=1)
; DP[1] ; (dst-1) pointer (default WBS1=1)
; LC[0] ; byte count / 2 (Loop Counter)
loop: ;words/cycles
move DP[0], DP[0] ; 1 implicit DP[0] pointer selection
move @++DP[1],@DP[0]++ ; 1
djnz LC[0], loop ; 1
ret ; 1
;----------
; 4 / (3*bytecount/2) +1
; WORD COUNT = 4 ; CYCLE COUNT = 97
;====================================MSP430=====================================
; MSP430 has a 16-bit data bus
; assuming bytes are word aligned, only requires (blocksize/2 transfers).
; R4 ;src pointer
; R5 ;dst pointer
; R6 ;size of block to copy
loop: ;words/cycles
mov @R4+, 0(R5) ;2 / 5 @src++ => dst
add #2, R5 ;1 / 1 const generator makes this 1/1
decd.b R6 ;1 / 1 really sub #2, R6
jz loop ;1 / 2
ret ;1 / 3
;----------
;6 / (9*(bytecount/2)) + return
; WORD COUNT = 6 ; CYCLE COUNT = 291
;===================================PIC16CXXX===================================
; a ; src pointer base
; b ; dst pointer base
; i ; byte count held in reg file
; USES:
; temp ; temp data storage
loop: ; cycles
decf i, W ; 1 i-- => W
addlw a ; 1 (a+i--) => W starting at end
movwf FSR ; 1 W => FSR
movfw INDF ; 1 W <= @FSR get data
movwf temp ; 1 W => temp
movlw (b-a) ; 1 diff in dest-src
addwf FSR, F ; 1 (b+i--) => W
movfw temp ; 1 temp => W
movwf INDF ; 1 W => @FSR store data
decfsz i, F ; 2/1 i--
goto loop ; 2
return ; 2
;----------
;11 / (12*bytecount) +1 (ret instead of goto, +1 on decfsz)
; WORD COUNT = 12 ; CYCLE COUNT = 769 (*4clks/inst cycle = 3076)
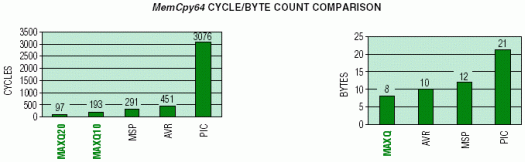
MAXQ器件提供最佳的代码密度,在执行速度方面是明显的赢家。MAXQ10执行复制操作的速度比MAXQ20慢,因为它对数据指针使用默认的字节访问模式。对于MAXQ10应用,如果认为执行速度比代码密度更重要,并且要复制的数据存储器是字对齐的(MSP430和MAXQ20示例已经假设),则可以对源和目标数据指针使用字访问模式。启用字模式允许将MAXQ10复制环路切成两半,但需要额外的指令来启用/禁用字访问模式。MAXQ器件相对于竞争产品所表现出的压倒性性能优势可归因于以下架构优势:
| 1. | 无流水线 - 分支不会像其他设备那样产生刷新指令预取的开销。 |
| 2. | 自动递减循环计数器 - 减轻了手动执行此操作的需要。 |
| 3. | 哈佛内存映射 - 程序和数据不共享相同的物理空间,允许同时获取程序和数据访问。 |
| 4. | 预递增/递减间接目标指针 - 简化并加快目标指针的前进速度。这是 MSP430 的一个弱点,它使用 0(R5) 表示@R5,然后必须使用另一条指令推进该目标指针。 |
存储器复制示例中所示的MAXQ优势转化为类似的增益,适用于需要在数据存储器中进行频繁输入/输出缓冲的应用。在性能方面,最接近的竞争对手是 MSP430。例如,可能需要数据存储器缓冲,假设我们有一个MSP430器件,该器件配备了具有16位输出寄存器的ADC外设。将数据从外设输出寄存器传输到数据存储器并递增指针以准备下一个ADC输出样本,可以使用如下代码进行处理:
; words/cycles
mov.w &ADAT,0(R14) ; 3 / 6 Store output word
incd.w R14 ; 1 / 1 Increment pointer
; 4 / 7
在MAXQ20上,相同的传递操作如下所示:
move @++DP[0], ADCOUT ; 1 / 1
气泡排序(气泡排序))
冒泡排序例程不仅展示了有效访问数据存储器的能力,而且还在数据字节之间执行算术和/或比较运算,并有条件地对字节进行重新排序。代码例程对 32 个数据存储器字节进行排序,以便它们按升序或降序排列。周期计数假定字节重新排序大约有一半时间是相邻字节比较的结果。下图总结了每个微控制器上排序操作的周期计数和字节计数。
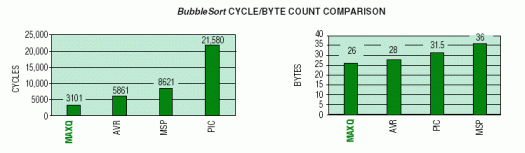
MAXQ器件再次产生最佳的码密度,是以下领域的明显赢家。 执行速度。MAXQ的优势可以归因于存储器复制示例中讨论的相同架构优势。
十六进制到 ASCII 转换 (十六进制2Asc)
此转换例程测试微控制器的算术和逻辑运算范围。它还在转换和扩展单个字节中包含的数据时测试它们对文本字节数据的支持。周期计数表示一个平均值,假设每个半字节可以是 16 个十六进制值之一 - 0 到 9,Ato F。下图总结了每个微控制器上转换操作的周期计数和字节计数。
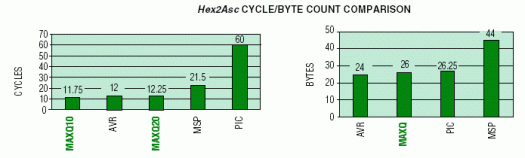
对于这个测试例程,AVR需要的字更少,因为它的工作寄存器可以直接访问,而MAXQ最有效的方法需要手动更新累加器指针。MSP 代码密度受到影响,因为它缺少操作半字节的操作,并且常量生成器不支持的文本 (#nnnnh) 必须用单独的单词进行编码。MAXQ器件和Atmel AVR在性能方面取得了类似的结果,而其他器件则落后。MSP430 的性能受到执行操作的额外码字的影响。
算术右移 2 个位置(向右)
此例程演示了微控制器支持 16 位字数据存储器访问和 ALU 操作的能力。所需的操作是以算术方式移位(即保留最高有效位)驻留在数据存储器中的 16 位字。假设字驻留在数据存储器的前 256 个字节中,并在存储器中对齐,以便由具有该功能的微控制器进行字寻址。下图总结了每个微控制器上移位操作的周期计数和字节计数。
支持16位ALU操作的微控制器MAXQ20和MSP430提供 代码密度明显提高。除PIC外,所有8位计算机都需要至少两倍的代码字数才能完成相同的算术移位。MAXQ20提供最佳性能,MAXQ10虽然仅支持8位ALU操作,但性能接近16位MSP430。
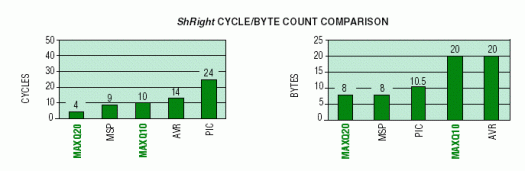
MAXQ20和MSP430表现出更高的ODE密度,因为它们能够比16位机器更有效地处理8位数据。但是,每种方法都以略有不同的方式这样做。MAXQ20将要移位的16位字传输到工作寄存器(累加器),在那里可以使用多位算术移位。MSP430 使用寄存器间接寻址模式 (RRA @R5) 执行单位算术移位运算,并且不会从其存储器位置显式传输字。在提供更高性能的同时,当20位字的算术移位可以使用多位算术移位操作码(SRA430、SRA16、SLA2、SLA4)时,MAXQ2可以提供与MSP4相同或更好的码密度。
位爆炸端口引脚(位爆炸)
此示例测试指令集体系结构通过直接位操作或通过移位/旋转分解字节并将各个位发送到端口引脚(“位敲击”)的能力。端口引脚输出分别表示时钟和数据,要求数据在时钟的上升沿必须有效。由于代码直接操作端口引脚,因此此测试还演示了访问I/O端口寄存器的难易程度。下图总结了每个微控制器上端口位爆炸操作的周期计数和字节计数。
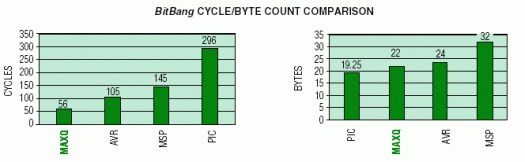
MAXQ器件显然是性能最好的器件。由于底层 4 周期内核架构,PIC 性能在这里受到限制(与其他示例一样)。MSP430的性能较差,可归因于其冯诺依曼存储器架构和需要使用绝对寻址来访问端口输出寄存器。
在码密度方面,MAXQ和PIC具有相同的字数。然而,PIC在RISC机器中优于MAXQ,因为它的14位程序字与MAXQ的16位程序字相比。MSP430代码密度受到影响,因为它必须使用至少两个字来访问具有绝对寻址模式(即和寄存器)的外设寄存器,或者当使用常量生成器无法减少的文字(例如,#3h)时。
MSP430访问其外设寄存器的方法值得进一步评论。微控制器的主要职责是以某种方式与外界接口。因此,它必须控制、监视和处理 I/O 引脚上发生的活动。如果微控制器嵌入很少的外设硬件模块,则此活动的负担留给软件。要使软件执行任何有意义的操作,它必须读取和写入端口引脚。在 MSP430 上,这些端口引脚寄存器驻留在需要使用绝对访问模式的外设寄存器空间中。现在考虑一个具有丰富“智能”外设的微控制器。毫无疑问,在使用片上专用硬件执行必要功能的过程中,必须配置、控制和访问更多的外设寄存器。在 MSP430 上,这些寄存器位于需要使用绝对访问模式的外设寄存器空间中。因此,与 MSP430 绝对寻址模式相关的代码密度和性能损失是无法逃避的。
“MIPS/mA”指标
功耗通常是选择处理器或内核架构的重要因素。给定系统的总体功耗取决于许多因素,例如电源电压和工作频率,以及尽可能使用低功耗模式的能力。降低电源电压和/或工作频率,以及频繁使用低功耗模式,可以大大降低系统总功耗。虽然给定微控制器的最小电源电压在很大程度上取决于器件制造工艺技术,但降低工作频率和使用低功耗模式的能力在很大程度上取决于系统设计人员可以确定的应用要求。MIPS/mA指标提供了一种简单的方法来评估微控制器的代码效率,同时考虑有功电流消耗。应选择通用电源电压,以便在不同器件之间创建有意义的MIPS/mA比较。对于即将到来的比较,假设为3V电源电压。为了考虑所比较的指令集架构(即AVR、MSP430、PIC16、MAXQ)的差异和效率,还需要为生成的每个代码示例生成单独的MIPS/mA比率。
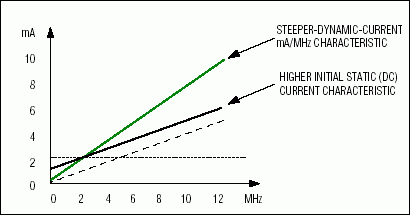
图2.这个IccActive与MHz的例子说明了静态和动态电流增加的影响。
为了确定MIPS/mA比率的“mA”部分,我们检查了器件的数据手册。大多数微控制器供应商都规定了与器件最大工作频率相关的典型和最大有功电流。假设静态(DC)电流非常小,这些数据点允许得出典型和最大mA/MHz近似值,用于在任何时钟频率下外推有功电流。如果供应商提供有功电流与温度/频率特性数据,则可以相对于特定系统环境条件更好地量化和定义mA/MHz比。否则,我们必须简单地依靠离散数据点和我们对非常小的静态电流的假设。静态(DC)电流的增加会改变mA与MHz特性曲线的起点,从而限制系统设计人员在降低时钟频率(降低动态电流)时看到的总增益。图2给出了一个IccActive vs. MHz图示例。表2比较了各种内核的mA/MHz数字,并引用了信息来源。当以后的计算中需要此术语时,将使用每个架构的突出显示的 mA/MHz 数。
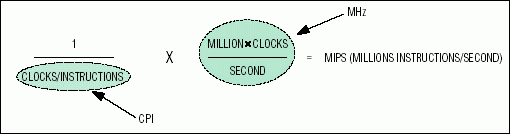
图3.MAXQ架构通过每条指令在一个时钟上执行几乎所有指令来实现高MIPS性能比。
MIPS/mA 指标的“MIPS”部分用于量化性能差异。我们将首先给出图3中MIPS的简单公式。
在评估给定架构的MIPS时,每条指令的时钟数(CPI)非常重要。例如,Microchip PIC等架构要求每个指令周期有多个时钟。此外,架构通常需要多个指令周期来执行某些指令,或者在执行跳转/分支时需要周期来刷新指令管道。在比较架构时,MIPS的平均性能通常远低于峰值性能(MIPS),并且因指令组合而异。
| 装置 | 典型毫安/兆赫 | 最大毫安/兆赫 | 源 |
| PIC16C55X | 0.7 | 1.25 | PIC16C55X 数据表:DC 表 10.1, D010 (Vcc= 3V, 2兆赫);XT 或 RC |
| PIC16C62X | 0.7 | 1.25 | PIC16C62X 数据表:DC 表 12.1, D010 (Vcc= 3V, 2兆赫);XT 或 RC |
| 图16LC71 | 0.35 | 0.625 | PIC16C71X 数据表:DC 表 15.2, D010 (Vcc= 3V, 4兆赫);XT 或 RC |
| PIC16F62X | 0.15 | 0.175 | PIC16F62X 数据表:DC 表 17.1, D010 (Vcc= 3V, 4MHz) |
| PIC16LF870/1 | 0.15 | 0.5 | PIC16F870/1 数据表:DC 表 14.1, D010 (Vcc= 3V, 4兆赫);XT 或 RC |
| AT90S1200 | 0.33 | 0.75 | AT90S1200 数据手册:EC 表 (3V, 4MHz), 图 38, 4mA/12MHz (典型值) |
| AT90S2313 | 0.50 | 0.75 | AT90S2313 数据手册:EC 表 (3V, 4MHz), 图 57, 7.5mA/15MHz (典型值) |
| MSP430F1101 | 0.30 | 0.35 | MSP430x11x1 数据表:直流规格 IccActive (Vcc= 3V, FMCLK = 1MHz) |
| MPS430C11X1 | 0.24 | 0.30 | MSP430x11x1 数据表:直流规格 IccActive (Vcc= 3V, FMCLK = 1MHz) |
| MSP430Fx12x | 0.30 | 0.35 | MSP430x12x 数据表:直流规格 (V抄送= 3V, FMCLK = 1MHz, FACLK = 32kHz) |
| MAXQ10 | 0.30 | 模拟 | |
| MAXQ20 | 0.30 | 模拟 |
为了生成一个更有用的指标并生成一个值来帮助我们达到 MIPS/mA 目标指标,我们将 MIPS 除以 MHz。MIPS/MHz比率可以解释为在单个时钟中执行的平均指令数(对于给定的代码示例)。使用MIPS/MHz数和之前计算的mA/MHz数,可以生成MIPS/mA比率。下表分别显示了每个早期代码例程比较的MIPS/MHz和MIPS/mA数字。
| 核心 | MIPS/MHz | |||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | Peak | |
| MAXQ10 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1 |
| MAXQ20 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1 |
| PIC | 0.23 | 0.20 | 0.23 | 0.25 | 0.21 | 0.25 |
| MSP | 0.44 | 0.39 | 0.64 | 0.33 | 0.61 | 1 |
| AVR | 0.57 | 0.62 | 0.90 | 0.71 | 0.61 | 1 |
| 核心 | 微弱/毫安 | |||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | ||
| MAXQ10 | 3.33 | 3.30 | 3.33 | 3.33 | 3.33 | |
| MAXQ20 | 3.33 | 3.30 | 3.33 | 3.33 | 3.33 | |
| PIC | 1.53 | 1.35 | 1.53 | 1.67 | 1.40 | |
| MSP | 1.85 | 1.62 | 2.66 | 1.39 | 1.55 | |
| AVR | 1.71 | 1.86 | 2.69 | 2.14 | 1.83 | |
为了进一步分析,我们必须通过将MIPS/mA比率除以给定代码样本实际执行的指令数来考虑核心架构和指令集效率之间的差异。这种额外计算的基本原理是,执行三个单周期指令(最高MIPS/MHz比率= 1)实际上并不比一个3周期指令(MIPS/MHz比率= 0.33)好。尽管如此,由此产生的MIPS/mA比率却大不相同。事实上,如果完成相同的任务,大多数人更喜欢一条指令而不是三条指令。通过将MIPS/mA比率除以执行的指令数,我们正在根据给定微控制器用于执行特定任务的指令组合调整MIPS/mA比率。结果值已规范化为最高性能值,如下表所示。
| 核心 | 标准化 (MIPS/mA) | ||||
| MemCpy64 | BubbleSort | Hex2Asc | ShRight | BitBang | |
| MAXQ10 | 0.50 | 1.00 | 1.00 | 0.40 | 1.00 |
| MAXQ20 | 1.00 | 1.00 | 0.96 | 1.00 | 1.00 |
| PIC | 0.06 | 0.29 | 0.39 | 0.33 | 0.38 |
| MSP | 0.42 | 0.45 | 0.68 | 0.56 | 0.48 |
| AVR | 0.19 | 0.48 | 0.88 | 0.26 | 0.48 |
结论
归一化的“MIPS/mA”指标为我们提供了 比较具有不同架构、指令集和电流消耗特性的微控制器。较高的归一化“MIPS/mA”比通常可以产生以下一个或两个好处:(1)可以降低系统时钟频率,以及(2)可以增加在低功耗或睡眠模式下花费的时间。这两种可能性都有助于降低系统的整体功耗。或者,可以在保持给定电流/功率预算的同时实现更高的整体系统性能。无论优点如何,MAXQ架构产生的高MIPS/mA比都是效率的可靠指标。
审核编辑:郭婷
-
浅谈RISC-V指令集架构的来龙去脉2020-01-24 7330
-
现代处理器的主要指令集架构2023-12-11 6963
-
CISC(复杂指令集)与RISC(精简指令集)的区别2024-07-30 316
-
RISC-V指令集的特点总结2024-08-30 1224
-
RISC-V和arm指令集的对比分析2024-09-28 1775
-
RISC-V指令集概述2024-11-30 1185
-
AMD扩展x86并行指令集2019-07-26 3282
-
解读CPU的组成指令集架构2021-07-30 2511
-
RISC-V指令集架构微控制器相关知识2021-12-16 1476
-
精简指令集架构RISC与复杂指令集架构CISC有何区别2021-12-23 2990
-
risc指令集是什么_有哪些2017-12-19 21262
-
指令集架构与开源架构2018-07-16 8075
-
简单讲讲RISC-V指令集CPU的参数2022-08-07 5137
-
一个基于精简指令集原则的开源指令集架构RISC-V2023-01-30 4828
-
复杂指令集和精简指令集有什么区别2024-08-22 8172
全部0条评论

快来发表一下你的评论吧 !
