

如何测算ChatGPT算力需求?
人工智能
描述
ChatGPT发布之后,引发了全球范围的关注和讨论,国内各大厂商相继宣布GPT模型开发计划。以GPT模型为代表的AI大模型训练,需要消耗大量算力资源,主要需求场景来自:预训练+日常运营+Finetune。以预训练为例,据测算,进行一次ChatGPT的模型预训练需要消耗约27.5PFlop/s-day算力。基于此,随着国产大模型开发陆续进入预训练阶段,算力需求持续释放或将带动算力基础设施产业迎来增长新周期。产业链相关公司包括:
❶算力芯片厂商:景嘉微、寒武纪、海光信息、龙芯中科、中国长城等;
❷服务器厂商:浪潮信息、中科曙光等;
❸IDC服务商:宝信软件等。
ChatGPT:大模型训练带来高算力需求
训练ChatGPT需要使用大量算力资源。据微软官网,微软Azure为OpenAI开发的超级计算机是一个单一系统,具有超过28.5万个CPU核心、1万个GPU和400 GB/s的GPU服务器网络传输带宽。据英伟达,使用单个Tesla架构的V100 GPU对1746亿参数的GPT-3模型进行一次训练,需要用288年时间。此外,算力资源的大量消耗,必然伴随着算力成本的上升,据Lambda,使用训练一次1746亿参数的GPT-3模型所需花费的算力成本超过460万美元。我们认为,未来拥有更丰富算力资源的模型开发者,或将能够训练出更优秀的AI模型,算力霸权时代或将开启。
具体来看,AI大模型对于算力资源的需求主要体现在以下三类场景:
1、模型预训练带来的算力需求
模型预训练过程是消耗算力的最主要场景。
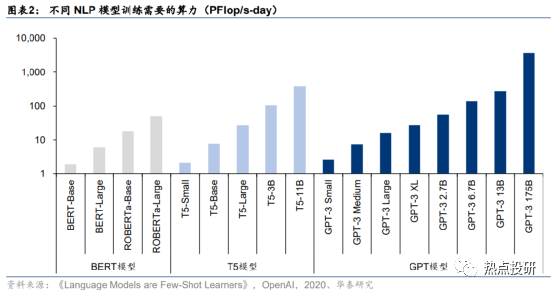
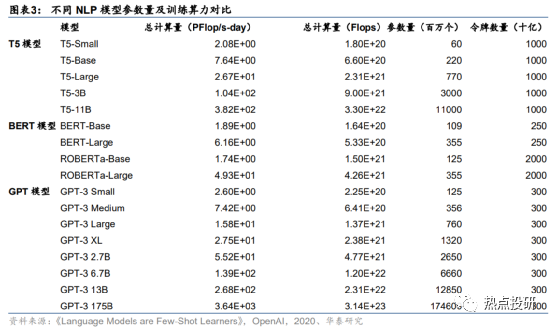
预计,训练一次ChatGPT模型需要的算力约27.5PFlop/s-day。据OpenAI团队发表于2020年的论文《Language Models are Few-Shot Learners》,训练一次13亿参数的GPT-3 XL模型需要的全部算力约为27.5PFlop/s-day,训练一次1746亿参数的GPT-3模型需要的算力约为3640 PFlop/s-day。考虑到ChatGPT训练所用的模型是基于13亿参数的GPT-3.5模型微调而来,参数量与GPT-3 XL模型接近,因此我们预计训练所需算力约27.5PFlop/s-day,即以1万亿次每秒的速度进行计算,需要耗时27.5天。
 此外,预训练过程还存在几个可能的算力需求点:
此外,预训练过程还存在几个可能的算力需求点:
1)模型开发过程很难一次取得成功,整个开发阶段可能需要进行多次预训练过程;
2)随着国内外厂商相继入局研发类似模型,参与者数量增加同样带来训练算力需求;
3)从基础大模型向特定场景迁移的过程,如基于ChatGPT构建医疗AI大模型,需要使用特定领域数据进行模型二次训练。
 2、日常运营带来的算力需求
2、日常运营带来的算力需求
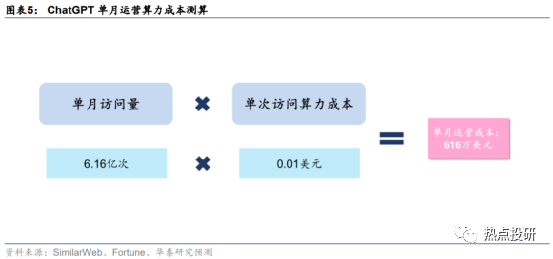
ChatGPT单月运营需要算力约4874.4PFlop/s-day,对应成本约616万美元。
在完成模型预训练之后,ChatGPT对于底层算力的需求并未结束,日常运营过程中,用户交互带来的数据处理需求同样也是一笔不小的算力开支。据SimilarWeb数据,2023年1月ChatGPT官网总访问量为6.16亿次。据Fortune杂志,每次用户与ChatGPT互动,产生的算力云服务成本约0.01美元。基于此,我们测算得2023年1月OpenAI为ChatGPT支付的运营算力成本约616万美元。据上文,我们已知训练一次1746亿参数的GPT-3模型需要3640 PFlop/s-day的算力及460万美元的成本,假设单位算力成本固定,测算得ChatGPT单月运营所需算力约4874.4PFlop/s-day。
3、Finetune带来的算力需求
模型调优带来迭代算力需求。从模型迭代的角度来看,ChatGPT模型并不是静态的,而是需要不断进行Finetune模型调优,以确保模型处于最佳应用状态。这一过程中,一方面是需要开发者对模型参数进行调整,确保输出内容不是有害和失真的;另一方面,需要基于用户反馈和PPO策略,对模型进行大规模或小规模的迭代训练。因此,模型调优同样会为OpenAI带来算力成本,具体算力需求和成本金额取决于模型的迭代速度。
需求场景:预训练+日常运营+Finetune
具体来看,AI大模型对于算力资源的需求主要体现在以下三类场景:
1)模型预训练:ChatGPT采用预训练语言模型,核心思想是在利用标注数据之前,先利用无标注的数据训练模型。据我们测算,训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day;
2)日常运营:用户交互带来的数据处理需求同样也是一笔不小的算力开支,我们测算得ChatGPT单月运营需要算力约4874.4PFlop/s-day,对应成本约616万美元;
3)Finetune:ChatGPT模型需要不断进行Finetune模型调优,对模型进行大规模或小规模的迭代训练,预计每月模型调优带来的算力需求约82.5~137.5 PFlop/s-day。
算力芯片+服务器+数据中心,核心环节率先受益
随着国内厂商相继布局ChatGPT类似模型,算力需求或将持续释放,供给端核心环节或将率先受益:
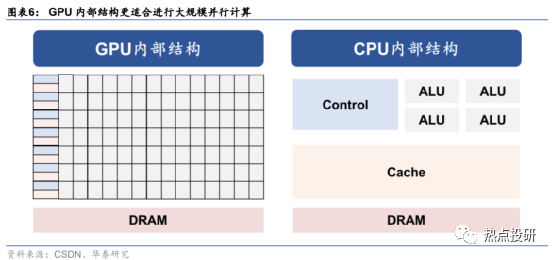
1)算力芯片:GPU采用了数量众多的计算单元和超长的流水线,架构更适合进行大吞吐量的AI并行计算;
2)服务器:ChatGPT模型训练涉及大量向量及张量运算,AI服务器具备运算效率优势,大模型训练有望带动AI服务器采购需求放量;
3)数据中心:IDC算力服务是承接AI计算需求的直接形式,随着百度、京东等互联网厂商相继布局ChatGPT类似产品,核心城市IDC算力缺口或将加大。
算力芯片:AI算力基石,需求有望大规模扩张
GPU架构更适合进行大规模AI并行计算,需求有望大规模扩张。从ChatGPT模型计算方式来看,主要特征是采用了并行计算。对比上一代深度学习模型RNN来看,Transformer架构下,AI模型可以为输入序列中的任何字符提供上下文,因此可以一次处理所有输入,而不是一次只处理一个词,从而使得更大规模的参数计算成为可能。而从GPU的计算方式来看,由于GPU采用了数量众多的计算单元和超长的流水线,因此其架构设计较CPU而言,更适合进行大吞吐量的AI并行计算。基于此,我们认为,随着大模型训练需求逐步增长,下游厂商对于GPU先进算力及芯片数量的需求均有望提升。
 单一英伟达V100芯片进行一次ChatGPT模型训练,大约需要220天。我们以AI训练的常用的GPU产品—NVIDIA V100为例。V100在设计之初,就定位于服务数据中心超大规模服务器。据英伟达官网,V100 拥有 640 个 Tensor 内核,对比基于单路英特尔金牌6240的CPU服务器可以实现24倍的性能提升。考虑到不同版本的V100芯片在深度学习场景下计算性能存在差异,因此我们折中选择NVLink版本V100(深度学习算力125 TFlops)来计算大模型训练需求。据前文,我们已知训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day,计算得若由单个V100 GPU进行计算,需220天;若将计算需求平均分摊至1万片GPU,一次训练所用时长则缩短至约32分钟。
单一英伟达V100芯片进行一次ChatGPT模型训练,大约需要220天。我们以AI训练的常用的GPU产品—NVIDIA V100为例。V100在设计之初,就定位于服务数据中心超大规模服务器。据英伟达官网,V100 拥有 640 个 Tensor 内核,对比基于单路英特尔金牌6240的CPU服务器可以实现24倍的性能提升。考虑到不同版本的V100芯片在深度学习场景下计算性能存在差异,因此我们折中选择NVLink版本V100(深度学习算力125 TFlops)来计算大模型训练需求。据前文,我们已知训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day,计算得若由单个V100 GPU进行计算,需220天;若将计算需求平均分摊至1万片GPU,一次训练所用时长则缩短至约32分钟。
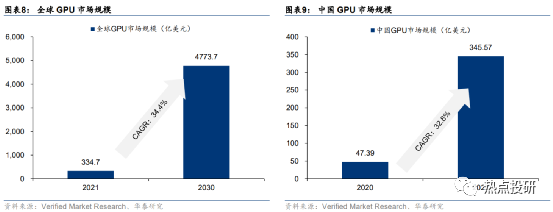
 全球/中国GPU市场规模有望保持快速增长。据VMR数据,2021年全球GPU行业市场规模为334.7亿美元,预计2030年将达到4773.7亿美元,预计22-30年CAGR将达34.4%。2020年中国GPU市场规模47.39亿美元,预计2027年市场规模将达345.57亿美元,预计21-27年CAGR为32.8%。
全球/中国GPU市场规模有望保持快速增长。据VMR数据,2021年全球GPU行业市场规模为334.7亿美元,预计2030年将达到4773.7亿美元,预计22-30年CAGR将达34.4%。2020年中国GPU市场规模47.39亿美元,预计2027年市场规模将达345.57亿美元,预计21-27年CAGR为32.8%。
服务器:AI服务器有望持续放量
ChatGPT主要进行矩阵向量计算,AI服务器处理效率更高。从ChatGPT模型结构来看,基于Transformer架构,ChatGPT模型采用注意力机制进行文本单词权重赋值,并向前馈神经网络输出数值结果,这一过程需要进行大量向量及张量运算。而AI服务器中往往集成多个AI GPU,AI GPU通常支持多重矩阵运算,例如卷积、池化和激活函数,以加速深度学习算法的运算。因此在人工智能场景下,AI服务器往往较GPU服务器计算效率更高,具备一定应用优势。
 单台服务器进行一次ChatGPT模型训练所需时间约为5.5天。我们以浪潮信息目前算力最强的服务器产品之一—浪潮NF5688M6为例。NF5688M6是浪潮为超大规模数据中心研发的NVLink AI 服务器,支持2颗Intel最新的Ice Lake CPU和8颗NVIDIA最新的NVSwitch全互联A800GPU,单机可提供5PFlops的AI计算性能。据前文,我们已知训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day,计算得若由单台NF5688M6服务器进行计算,需5.5天。
单台服务器进行一次ChatGPT模型训练所需时间约为5.5天。我们以浪潮信息目前算力最强的服务器产品之一—浪潮NF5688M6为例。NF5688M6是浪潮为超大规模数据中心研发的NVLink AI 服务器,支持2颗Intel最新的Ice Lake CPU和8颗NVIDIA最新的NVSwitch全互联A800GPU,单机可提供5PFlops的AI计算性能。据前文,我们已知训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day,计算得若由单台NF5688M6服务器进行计算,需5.5天。
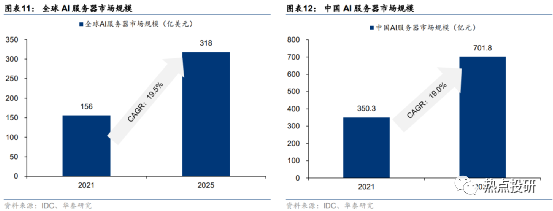
大模型训练需求有望带动AI服务器放量。随着大数据及云计算的增长带来数据量的增加,对于AI智能服务器的需求明显提高。据IDC数据,2021年全球AI服务器市场规模为156亿美元,预计到2025年全球AI服务器市场将达到318亿美元,预计22-25年CAGR将达19.5%。
数据中心:核心城市集中算力缺口或将加剧
IDC算力服务是承接AI计算需求的直接形式。ChatGPT的模型计算主要基于微软的Azure云服务进行,本质上是借助微软自有的IDC资源,在云端完成计算过程后,再将结果返回给OpenAI。可见,IDC是承接人工智能计算任务的重要算力基础设施之一,但并不是所有企业都需要自行搭建算力设施。从国内数据中心的业务形态来看,按照机房产权归属及建设方式的角度,可分为自建机房、租赁机房、承接大客户定制化需求以及轻资产衍生模式四种。
若使用某一IDC全部算力,可在11分钟完成一次ChatGPT模型训练。我们以亚洲最大的人工智能计算中心之一—商汤智算中心为例。据商汤科技官网,商汤智算中心于2022年1月启动运营,峰值算力高达3740 Petaflops。据前文,我们已知训练一次ChatGPT模型(13亿参数)需要的算力约27.5PFlop/s-day,计算得若使用商汤智算中心全部算力进行计算,仅需11分钟即可完成。
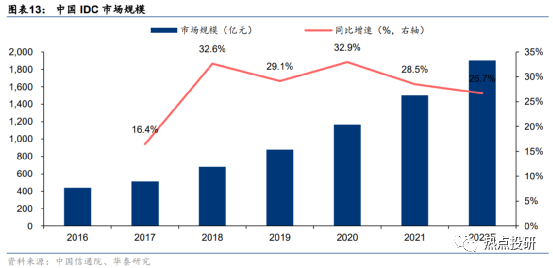
AI训练需求有望带动IDC市场规模快速增长。据中国信通院,2021年国内IDC市场规模1500.2亿元,同比增长28.5%。据信通院预计,随着我国各地区、各行业数字化转型深入推进、AI训练需求持续增长、智能终端实时计算需求增长,2022年国内市场规模将达1900.7亿元,同增26.7%。
 互联网厂商布局ChatGPT类似产品,或将加大核心城市IDC算力供给缺口。据艾瑞咨询,2021年国内IDC行业下游客户占比中,互联网厂商居首位,占比为60%;其次为金融业,占比为20%;政府机关占比10%,位列第三。而目前国内布局ChatGPT类似模型的企业同样以互联网厂商为主,如百度宣布旗下大模型产品“文心一言”将于2022年3月内测、京东于2023年2月10日宣布推出产业版ChatGPT:ChatJD。另一方面,国内互联网厂商大多聚集在北京、上海、深圳、杭州等国内核心城市,在可靠性、安全性及网络延迟等性能要求下,或将加大对本地IDC算力需求,国内核心城市IDC算力供给缺口或将加大。
互联网厂商布局ChatGPT类似产品,或将加大核心城市IDC算力供给缺口。据艾瑞咨询,2021年国内IDC行业下游客户占比中,互联网厂商居首位,占比为60%;其次为金融业,占比为20%;政府机关占比10%,位列第三。而目前国内布局ChatGPT类似模型的企业同样以互联网厂商为主,如百度宣布旗下大模型产品“文心一言”将于2022年3月内测、京东于2023年2月10日宣布推出产业版ChatGPT:ChatJD。另一方面,国内互联网厂商大多聚集在北京、上海、深圳、杭州等国内核心城市,在可靠性、安全性及网络延迟等性能要求下,或将加大对本地IDC算力需求,国内核心城市IDC算力供给缺口或将加大。
编辑:黄飞
-
大模型时代的算力需求2024-08-20 1154
-
芯科技,解密ChatGPT畅聊之算力芯片2023-12-27 2393
-
【核芯观察】ChatGPT背后的算力芯片(三)2023-06-04 4214
-
【核芯观察】ChatGPT背后的算力芯片(二)2023-05-28 4632
-
ChatGPT背后的算力芯片2023-05-21 5121
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
ChatGPT对GPU算力的需求测算与分析2023-02-21 5711
-
ChatGPT带火算力服务,智算中心建设加速!2023-02-19 4386
-
ChatGPT大火!庞大的AI算力需求面临巨大挑战2023-02-15 765
-
【AI简报第20230210期】 ChatGPT爆火背后、为AIoT和边缘侧AI喂算力的RISC-V2023-02-12 2765
全部0条评论

快来发表一下你的评论吧 !
