

使用MAXQ2000进行音频滤波
描述
乘法累加单元(MAC)和单周期内核的组合使MAXQ2000成为多功能微控制器(μC)。MAXQ2000具有性能和I/O外设,非常适合许多应用:闹钟、手持医疗设备、数字读数——任何需要低功耗、高性能和大量I/O的应用。通过集成MAC,MAXQ2000进入DSP (μC)领域。
MAXQ2000能从MAC中得到多少性能?本应用笔记通过音频滤波示例探讨了这个问题,并给出了MAXQ2000支持的性能的定量指导。
软件和硬件要求
本应用笔记简单演示了音频滤波器。音频数据是作者预先录制的消息,说“管道在新的时开始生锈”。此文本不是随机选择的 - 它提供了不错的频率分量组合,突出了简单滤波器的可听效果。录音可以用任何适当长度的8kHz录音代替,但不是必需的。
本应用笔记所需的硬件包括MAXQ2000评估板和用于连接计算机扬声器的小电路。
MAXQ2000评估板是探索MAXQ2000功能的好工具。它包括一个LCD面板、LED组,并可访问MAXQ2000 μC的所有I/O引脚。它还包括一个MAX1407 ADC/DAC,可用于音频输出。
所需的第二件硬件可以很容易地进行面包板测试。用于本演示的电路如图1所示。它要求一个1 x 8的母头接头连接到J2000的MAXQ7评估板,另一个连接到任何接地(MAXQ1评估板上的TP2000是一个不错的选择)。扬声器连接器可以是任何类型 — 显示的是 3.5 毫米立体声插孔,这使得连接到典型的计算机扬声器变得简单。请注意,两个输入通道是连接在一起的,因为我们的演示应用程序只显示一个音频通道(单声道)。
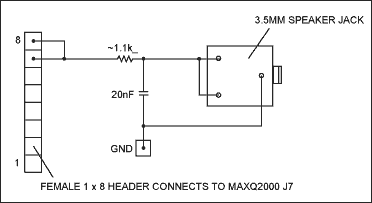
图1.音频播放所需的其他硬件。
运行此演示所需的软件是使用 IAR 嵌入式工作台构建和调试的。它利用MAXQ2000的硬件调试支持,提供了良好的调试环境。您可以在实际硬件上运行时设置断点、设置和读取寄存器和内存,并查看调用堆栈。
运行演示应用程序
MAXQ2000评估板上的按钮用于选择滤波器,并播放通过该滤波器的音频样本。使用按钮 SW4 选择滤波器 - 滤波器的名称将显示在 LCD 屏幕上(HI 表示高通,LO 表示低通,BP 表示带通,ALL 表示所有通)。使用 SW5 按钮开始通过所选过滤器播放音频。可以在播放过程中更改过滤器。
设计简单的FIR滤波器
我开发了一个Java™小程序,可以让我轻松创建新的过滤器。我没有使用给定滤波器参数的标准窗口技术,而是选择通过在极点零图中放置零来粗略地“设计”我的滤波器,如图 2 所示。该小程序允许在坐标平面的任何位置放置零点,并不断更新演示应用所需的FIR滤波器系数。但请注意,该演示仅支持全零筛选器。支持 IIR 滤波器不会太困难 — 更多说明在支持 IIR 滤波器部分。
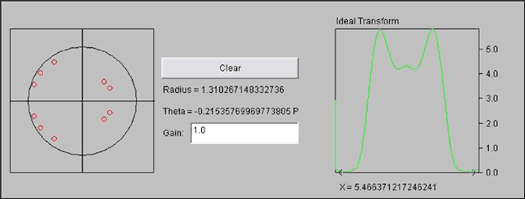
图2.使用零极点图生成简单的FIR滤波器。
通用滤波器采用线性方程的形式:
y(n) + ΣbKy(k) = ΣaJx(j)
其中 k 表示滤波器反馈部分的顺序,j 表示滤波器前馈部分的顺序。
示例 IIR 滤波器可以像以下这样简单:
y(n) = 0.5y(n-1) + x(n) - 0.8x(n-1)
某些滤波器被归类为FIR滤波器。它们不包含反馈部分。换句话说,特征滤波方程中没有 y 部分:
y(n) = ΣaJx(j) y(n) = x(n) - 0.2x(n - 1) + 0.035x(n - 3)
在任何一种情况下,滤波器都归结为一个特征方程,该方程本质上是过去输入和输出值的加权平均值。滤波器设计的工作是产生那些 Aj和乙k值。为了有效地计算滤波器的输出,我们需要能够快速相乘和求和有符号数的硬件支持。输入MAXQ2000的乘法累加单元。
使用乘法累加 (MAC) 单元实现筛选器
上一节中的小程序通过计算给定图中零坐标的滤波器系数来工作。但是,计算的系数是浮点数,而我们的 MAC 使用纯 16 位整数数学。为了纠正此问题,演示应用程序使用定点数字系统,其中系数的 0 到 15 位位于小数点右侧(第 16 位表示符号幅度)。一旦操作结束,MAC累加器中的48位结果将移动到足够的位置以去除任何分数。
此解决方案是精度与速度的权衡。在许多情况下,这种方法的错误可以忽略不计。出于诊断目的,小程序显示了计算滤波器的三个图。第一个图显示了使用 64 位浮点数的理想滤波器行为。该图标记为“理想变换”,如图2所示。
图 3 显示了小程序生成的其余绘图。图3中的第一个图显示了使用16位定点数的有效滤波器。在许多情况下,误差并不明显,因此最后一个图是一个误差指示器,显示理想行为除以实际频率响应。理想情况下,这是 Y = 1 时的直线。
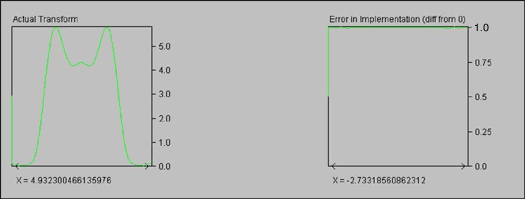
图3.滤波器 16 位实现的实际变换和舍入误差(几乎没有误差)。
为简单起见,小程序生成MAXQ®应用所需的浮点系数,因此可以将新的滤波器简单地剪切并粘贴到滤波器应用的源中(粘贴到文件data.asm中)。小程序还会生成另外两个值 — 筛选器的顺序(系数数)和偏移计数,因此应用程序可以适当地移动最终结果。此数据显示在小程序底部的文本框中,可能如下所示:
Zeroes:
dc16
dc16 12, 11, 0x1000, 0x26d3, 0x1e42, 0xf9a3, 0xecde, 0xff31, 0xa94,
0x2ae, 0xfd0c, 0xff42, 0xde
Shift amount: 12
在MAXQ汇编语言中实现滤波器
为了获得最佳性能并执行准确的性能分析,实际的过滤器将以汇编语言实现。这将使我们能够准确计算生成一个输出值所需的周期数,从而估计其他数据集的性能。
MAX1407具有12位ADC。但是,输入数据是 16 位宽的,我们的过滤器产生 16 位的结果。因此,虽然这 4 个最低有效位 (LSB) 被浪费在此应用中,但我们可以安全地分析我们的性能,就像处理和生成 16 位值(CD 质量的音频为 16 位)一样。
在此示例中,滤波器系数存储在表中的代码空间中。选择筛选器后,应用程序将查找相应的筛选器,读取移位量和抽头次数,然后准备好开始筛选数据。以下代码应用筛选器系数:
move MCNT, #22h ; signed, mult-accum, clear regs first
zeroes_filterloop:
move A[0], DP[0] ; let's see if we are out of data
cmp #W:rawaudiodata ; compare to the start of the audio data
lcall UROM_MOVEDP1INC ; get next filter coefficient
move MA, GR ; multiply filter coefficient...
lcall UROM_MOVEDP0DEC ; get next filter data
move MB, GR ; multiply audio sample...
jump e, zeroes_outofdata ; stop if at the start of the audio data
djnz LC[0], zeroes_filterloop
zeroes_outofdata:
move A[2], MC2 ; get MAC result HIGH
move A[1], MC1 ; get MAC result MID
move A[0], MC0 ; get MAC result LOW
在执行此代码之前,LC[0] 设置为滤波器的抽头数,DP[0] 设置滤波器的当前输入字节地址,DP[1] 指向滤波器系数的开头。因此,DP[1] 以递增的方式处理滤波器系数,DP[0] 以递减的方式处理输入数据(首先处理最近的输入)。
由于MAC在一个周期内工作,因此这里没有很多代码来处理它。MCNT 设置为 22h 表示使用有符号整数。在主循环中,连续写入 MA,然后 MB 触发乘法累加运算 — 结果在下一个时钟周期中准备就绪。由于我们的累加器是 48 位(我们的乘法结果是 32 位),我们不必担心任何溢出(除非我们的过滤器中有 64,000 个抽头!
性能
该示例应用采用以 16kHz 输出的单声道 8 位音频数据,不足以使 μC 疲惫不堪。因为我们用汇编语言编写了滤波器,所以我们可以很容易地计算用于提出长度为 N 的 FIR 滤波器计算所需的时间的表达式的周期。然后,我们可以使用此表达式使用前面列出的算法找到最大过滤率。
我们可以将用于生成音频样本的函数分为三个部分:初始化、滤波器计算循环和结果修复。在我们发布的示例中,初始化需要 38 个周期,滤波器计算循环每个滤波器系数需要 17 个周期,结果修复需要 9 + (6 x S) 个周期,其中 S 是偏移量。通常,偏移量约为 12,因此我们可以估计结果固定在 81 个周期。因此,产生一个滤波输出值需要 119 + (17 x N) 个周期。在20MHz时,MAXQ2000可以运行接近100kHz的11抽头滤波器,这对于语音数据来说已经足够好了。
让我们回过头来重新分析我们的应用程序,看看我们可以在哪里收紧它。我们将专注于过滤器循环,因为这是我们大多数循环发生在除最微不足道的过滤器之外的任何过滤器上的地方。
我们可以对循环代码进行一些关键的改进以提高效率。请记住,我们使用存储在代码空间中的预先录制的音频样本。由于MAXQ的哈佛架构,代码空间的查找比数据空间中的查找需要更多的时间。调用UROM_MOVEDP1INC和UROM_MOVEDP0DEC的函数各需要 5 个周期(LCALL 为 2 个周期,然后在函数内需要 3 个周期)。如果我们将过滤器存储在 RAM 中(一个周期用于选择指针,一个周期用于从中读取),并且如果我们提供存储在 RAM 中的实时输入数据,则每个周期都可以替换为两个周期。如果我们愿意向过滤器捐赠 256 个单词的 RAM,我们可以使用 BP[Offs] 实现一个循环缓冲区来存储输入数据。这些更改将循环时间从 11 个周期减少到 17 个周期。我们的过滤器循环现在如下所示(周期计数列在注释中的第一个):
zeroes_filterloop:
move A[0], DP[0] ; 1, let's see if we are out of data
cmp #W:rawaudiodata ; 2, compare to the start of the audio data
move DP[1], DP[1] ; 1, select DP[1] as our active pointer
move GR, @DP[1]++ ; 1, get next filter coefficient
move MA, GR ; 1, multiply filter coefficient...
move BP, BP ; 1, select BP[Offs] as our active pointer
move GR, @BP[Offs--] ; 1, get next filter data
move MB, GR ; 1, multiply audio sample...
jump e, zeroes_outofdata ; 1, stop if at the start of the audio data
djnz LC[0], zeroes_filterloop ; 1
一旦我们在RAM中有了滤波器和输入数据,我们就可以使用MAXQ架构的另一个技巧。MAXQ指令集是高度正交的——对于在任何操作中可以用作源的内容几乎没有限制。因此,我们可以将其直接写入MAC寄存器,而不是将滤波器数据和输入数据读取到GR中。这使循环减少到 9 个周期。 最后一项改进可以使这段代码真正飞起来。每次通过循环时,我们将当前数据指针与音频输入数据的开头进行比较,以查看我们是否越界(MOVE A[0]、DP[0] 语句、CMP 比较语句和 JUMP E 语句)。如果我们将初始音频数据(我们现在使用 BP[Offs] 指向的循环缓冲区读取)设置为全部零,我们可以简单地删除这些检查。将 RAM 初始化为 0 的成本可以忽略不计,而接下来几千个样本节省的 4 个周期可以忽略不计。我们的新循环代码是纤细的 5 个周期。 在回到性能方程之前,让我们看一下结果计算。我们目前将 48 位结果向下移动的方式似乎很浪费。 一种可能的解决方案是再次使用我们的MAC。与其向右移动 12(或 0 到 16 之间的任何值),我们可以向左移动 16 减去该量(即左移 4)。这会将我们的结果放在 MAC 寄存器的中间 16 位字中。请注意,我们的左移实际上是通过乘以 2 到某个幂
zeroes_filterloop:
move A[0], DP[0] ; 1, let's see if we are out of data
cmp #W:rawaudiodata ; 2, compare to the start of the audio data
move DP[1], DP[1] ; 1, select DP[1] as our active pointer
move MA, @DP[1]++ ; 1, multiply next filter coefficient
move BP, BP ; 1, select BP[Offs] as our active pointer
move MB, @BP[Offs--] ; 1, multiply next filter data
jump e, zeroes_outofdata ; 1, stop if at the start of the audio data
djnz LC[0], zeroes_filterloop ; 1
zeroes_filterloop:
move DP[1], DP[1] ; 1, select DP[1] as our active pointer
move MA, @DP[1]++ ; 1, multiply next filter coefficient
move BP, BP ; 1, select BP[Offs] as our active pointer
move MB, @BP[Offs--] ; 1, multiply next filter data
djnz LC[0], zeroes_filterloop ; 1
move A[2], MC2 ; get MAC result HIGH
move A[1], MC1 ; get MAC result MID
move A[0], MC0 ; get MAC result LOW
move APC, #0C2h ; clear AP, roll modulo 4, auto-dec AP
shift_loop:
;
; Because we use fixed point precision, we need to shift to get a real
; sample value. This is not as efficient as it could be. If we had a
; dedicated filter, we might make use of the shift-by-2 and shift-by-4
; instructions available on MAXQ.
;
move AP, #2 ; select HIGH MAC result
move c, #0 ; clear carry
rrc ; shift HIGH MAC result
rrc ; shift MID MAC result
rrc ; shift LOW MAC result
djnz LC[1], shift_loop ; shift to get result in A[0]
move APC, #0 ; restore accumulator normalcy
move AP, #0 ; use accumulator 0
在我们原来的右移应该是 12 的情况下)。 这将让我们将结果计算提高到 12 个周期,而不是 9 + (6 x S) 个周期。
;
; don't care about high word, since we shift left and take the
; middle word.
;
move A[1], MC1 ; 1, get MAC result MID
move A[0], MC0 ; 1, get MAC result LOW
move MCNT, #20h ; 1, clear the MAC, multiply mode only
move AP, #0 ; 1, use accumulator 0
and #0F000h ; 2, only want the top 4 bits
move MA, A[0] ; 1, lower word first
move MB, #10h ; 1, multiply by 2^4
move A[0], MC1R ; 1, get the high word, only lowest 4 bits significant
move MA, A[1] ; 1, now the upper word, we want lowest 12 bits
move MB, #10h ; 1, multiply by 2^4
or MC1R ; 1, combine the previous result and this one
;
; result is in A[0]
;
现在让我们回到前面的等式。我们的新方程使用40个开销周期和每个循环迭代5个周期的保守估计。使用与之前相同的100抽头滤波器示例,MAXQ2000可以处理16kHz的37位单声道音频数据,如表1所示。
表 1.最大FIR滤波器采样速率(20MHz MAXQ2000,环路)
| 过滤器长度(抽头) | 最大速率(赫兹) |
| 50 | 68965.51724 |
| 100 | 37037.03704 |
| 150 | 25316.4557 |
| 200 | 19230.76923 |
| 250 | 15503.87597 |
| 300 | 12987.01299 |
| 350 | 11173.18436 |
对于需要更高采样率且可能牺牲代码空间的应用程序,我们可以实现另一项性能改进。我们可以“内联”滤波器系数,这消除了选择活动指针的需要和循环的需要(这种技术也称为循环展开)。此更改的代价是增加了代码空间 - 以前,我们的 100 点过滤器需要 100 个单词才能存储;现在需要存储 300 个单词(每个系数移动 2 个单词,每个数据值移动 1 个单词)。在 16 千字的设备中,对于性能优势来说,这可能是微不足道的代价。新代码可能如下所示: 为了计算此更改的性能优势,我们再次假设开销为 40 个周期,但现在每个循环迭代有 3 个周期,尽管我们已经真正消除了循环。100抽头的性能限制现在为58kHz(见表2)。
move BP, BP ; select BP[Offs] as our active pointer
zeroes_filtertop:
move MA, #FILTERCOEFF_0 ; 2, multiply next filter coefficient
move MB, @BP[Offs--] ; 1, multiply next filter data
move MA, #FILTERCOEFF_1 ; 2, multiply next filter coefficient
move MB, @BP[Offs--] ; 1, multiply next filter data
move MA, #FILTERCOEFF_2 ; 2, multiply next filter coefficient
move MB, @BP[Offs--] ; 1, multiply next filter data
. . .
move MA, #FILTERCOEFF_N ; 2, multiply next filter coefficient
move MB, @BP[Offs--] ; 1, multiply next filter data
;
; filter calculation complete
;
表 2.最大FIR滤波器采样速率(20MHz MAXQ2000,展开环路)
| 过滤器长度(抽头) | 最大速率(赫兹) |
| 50 | 105263.1579 |
| 100 | 58823.52941 |
| 150 | 40816.32653 |
| 200 | 31250 |
| 250 | 25316.4557 |
| 300 | 31250 |
| 350 | 27027.02703 |
支持 IIR 滤波器
本应用笔记不演示IIR滤波器的使用,但MAXQ2000没有理由不支持IIR滤波器。涉及的更改将是:
将一段 RAM 专用于存储最新的输出样本(这将最有效地实现为循环缓冲区,使用 BP[Offs] 寄存器的方式类似于前面描述的方式)
包括滤波器反馈(“y”部分)的特征滤波器系数
添加另一个循环,继续累积作为过滤器反馈部分结果的产品
虽然添加另一个循环听起来像是性能下降,但不一定是。虽然计算滤波器的一个输出需要更多时间,但IIR滤波器通常需要较少的抽头(N的值较小)来计算输出值。
结论
MAXQ2000的性能和外设使其成为出色的通用μC。它可用于任何需要快速、多功能μC的地方,特别是在需要用户交互的应用中。MAC的有效利用使MAXQ2000具有一定的数字滤波功能,使MAXQ2000成为目前最通用的μC之一。
-
如何将MAXQ2000用作电压表2023-03-03 1585
-
使用MAXQ2000微控制器进行基于温度的风扇控制2023-03-02 2036
-
使用MAXQ2000进行安全系统控制2023-02-07 1602
-
使用MAXQ2000和MAX7312进行LED打靶练习游戏2023-01-14 1710
-
MAXQ2000微控制器与MAX4397是如何连接的?2021-06-04 1514
-
MAXQ2000 SPI模块与MAX6951/MAX6950怎么配合使用?2021-05-31 1174
-
利用MAXQ2000设计电压表2009-04-23 1072
-
MAXQ2000 Low-Power LCD Microco2009-02-06 819
-
采用MAXQ2000 USB “拇指”评估套件进行设计2009-01-13 979
-
MAXQ2000中文资料pdf2008-06-30 1249
全部0条评论

快来发表一下你的评论吧 !
