

如何从GCC源码学编译原理
描述
1.前言
公司的一款编译器是基于GCC写的,最近测试发现了一个小bug。为了解决这个bug不得不对GCC源码进行Debug,因此有了这篇文章。
本文结合编译原理理论和GCC实践做了一个总结,希望能给需要了解编译原理和底层知识的同学一个更快的学习路径。
除了GCC的文章之外,后续也会写一些LLVM的文章,如果再有时间的话争取将GCC中的编译器算法和LLVM中的编译器算法做一个对比总结。
希望看到这篇文章的朋友能持续关注本公众号,如果没有更新,肯定是研究代码去了,研究完之后的心得会第一时间在公众号分享出来,也希望能和更多的朋友一起交流,共同进步。
2. 编译原理基础
2.1 编译原理的重要性
了解事物的本质,是一件非常愉快的事情。
学习编译原理好处:
- 可以更加容易理解在一个语言中哪些写法是等价的,哪些是有差异的。
- 可以更加客观的比较不同语言的差异
- 不容易被某个特定语言的宣扬者忽悠
- 学习更新的语言效率更高
- 从语言a到语言b是一个通用的需求,学好编译原理会更加游刃有余
- 用编译原理的眼光看自己的代码,能够写出优秀的单元测试。
- 自己写的程序更优效率跟高
- 自创一门新的语言
编译原理可以说是一个计算机科学的缩影,在学习寄存器分配中会使用到贪心算法,死代码消除中会用到图论算法,数据流分析中使用到Fixed-Point Algorithm,词法分析和语法分析中会使用到有限状态机和递归下降等重要思想。可见编译原理是值得学习的。
2.2 编译原理理论
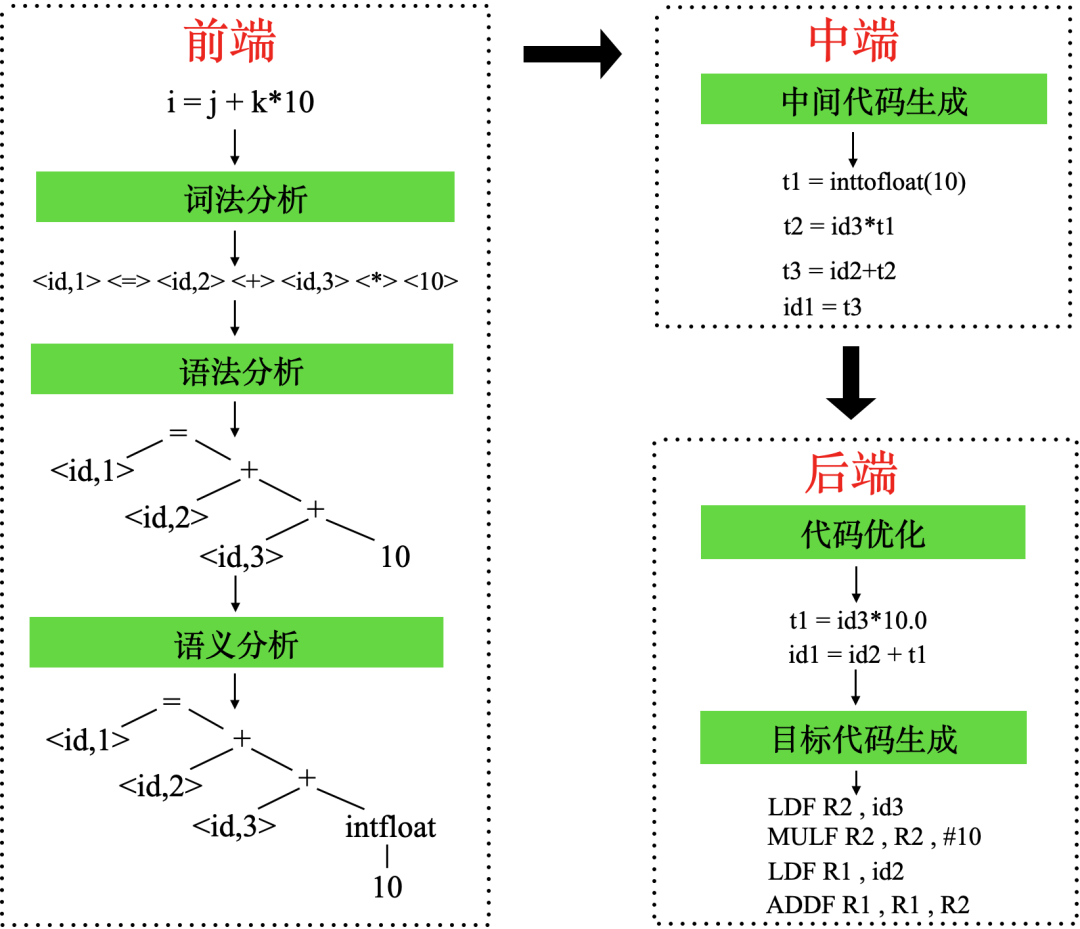
源程序到目标代码的过程要经历如下四个步骤:

首先是源程序到抽象语法树:
需要经历词法分析,也就是将程序中的一个一个字符按照单词识别出来。
然后是语法分析,将词法分析阶段的单词构成短语,将短语以抽象语法树的形式存储起来。
接下来是语义分析,语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。
从源程序到抽象语法树的过程称为编译器前端。
中间代码生成:中间代码是与体系结构无关的一种中间表示,形式接近于汇编代码,中间代码的目的是为了能生成各种体系结构相关的目标代码但是只需要一套前端代码。
目标代码生成:中间代码到目标代码会经过大量的代码优化,例如死代码删除、指令调度等。这个过程称为编译器后端。
编译器后端是整个编译器中最精华的地方,如果想要提升程序性能,研究编译器后端算法绝对会让你受益良多。
下面是一条语句 i = j + k*10 编译过程的具体实例:
3.GCC实践
3.1 源码阅读心得
程序 = 数据结构 + 算法
相信很多关心程序效率的同学都有这样的体验:
算法和数据结构密不可分,一个高效的算法必然有合适的数据结构作为支撑。高效的算法与合理的数据结构同样重要。
对于算法,通常仔细读一读论文就可以弄清楚原理,但是去看一些开源代码具体实现的时候往往又一头雾水。
那是因为我们刚接触开源代码的时候并不清楚它的数据结构是如何设计的。
本文从GCC的数据结构开始入手,为想要快速上手GCC的同学提供一个捷径。
即使不关心GCC源码,也可以从数据结构设计中获得启发,毕竟合理的数据结构和高效的算法一样重要。
3.2 GCC整体结构
我们通常认为GCC是一个编译器,然而官方的解释是这样的:
GCC is not a compiler.
GCC is a compiler collection that consists of three components.
A front end for each programming language, a middle end, and a back end for each architecture.
也就是说GCC是一个编译器集合,支持多种语言和多种硬件架构。
下图是GCC的一个整体结构图
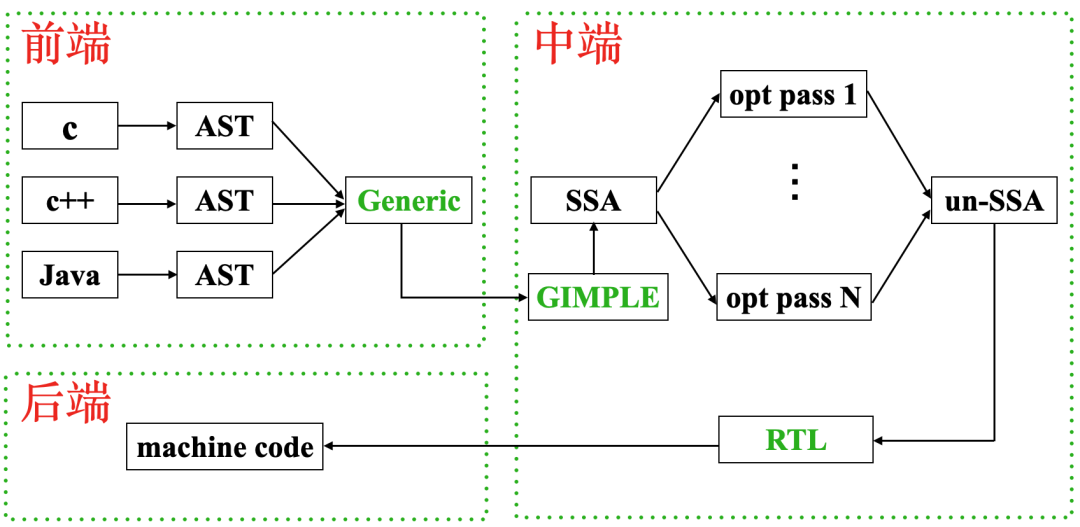
GCC整体结构图
图中的绿色的部分Generic、GIMPLE、RTL是本文要介绍的,看懂这三个数据结构之后离看懂GCC源码基本就成功了一半。
3.3 GCC中的Generic
GCC中的Generic其实也是一种抽象语法树(AST)。
从GCC整体结构图中我们可以看到,在Generic前面已经生成了AST,为啥这儿的Generic也是一种AST呢?
原因是这样的,从GCC整体结构图中我们可以看到,C语言会生成一种AST,C++也会生成一种AST,Java还会生成一种AST。这三种AST其实还是会有一些细微的差别,因此设计了一种通用的AST去统一所有的语言生成的AST,这个通用的AST就是Generic。
有了统一的AST后,就不用针对多种语言的AST写多份code去生成目标代码。只需要针对统一的AST写一份code去生成目标代码。
GCC中的AST用联合体(union)来表示即union tree_node。这是一个非常庞大的数据结构,因为要表示各种各样的树节点(例如声明、标识符、整型常量)。
将每一种节点统一到一个联合体中的好处就是便于代码阅读和代码的编写与维护。
union tree_node
{
struct tree_base base;
struct tree_common common;
....
//用于变量声明,后面的例子中会用到
struct tree_var_decl var_decl;
//整形常量节点
struct tree_int_cst int_cst;
//标志符节点
struct tree_identifier identifier
....
}
上面的代码是GCC中表示AST的树节点。只列举了部分,实际上是一个非常庞大的数据结构。
int main()
{
int a;
int b;
}
以上面仅有两个声明的代码为例,在GCC中使用
struct tree_var_decl var_decl;
表示变量a和变量b两个声明。其具体的表示如下:
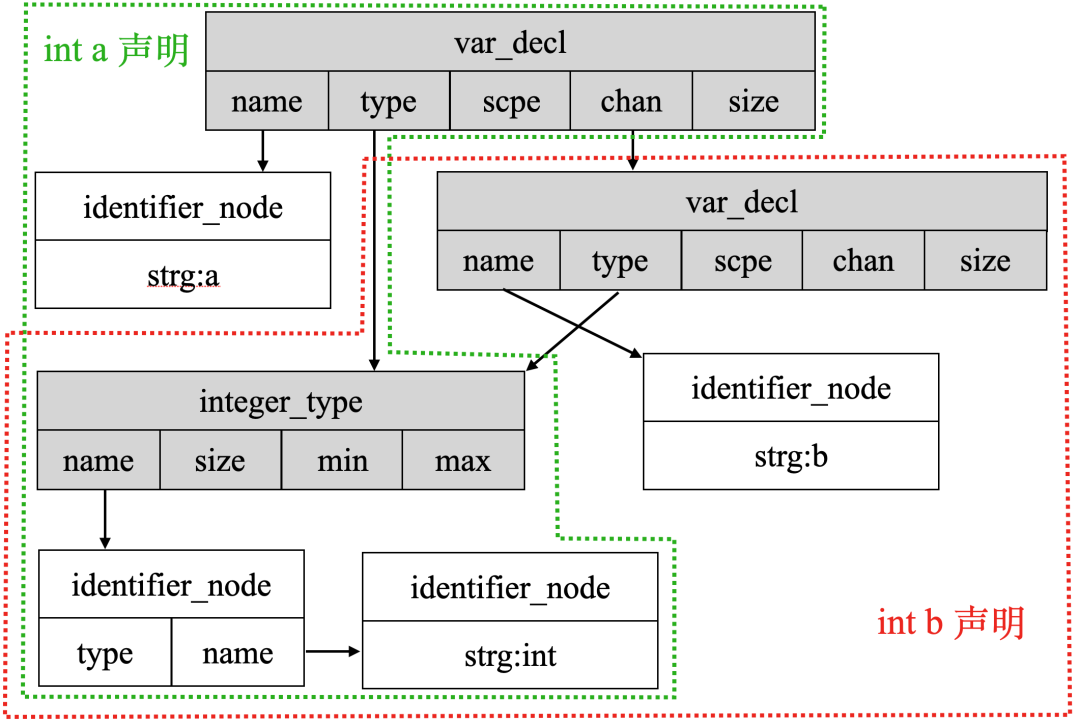
如上图所示对变量a的声明为绿色方框部分,对变量b的部分为红色方框部分。
两者交叉的部分为变量的类型,因为a与b都是int类型,所以用指针指向同一个int类型节点。
变量a与变量b通过var_decl的chan字段以链的方式连接起来。
3.4 GCC中的GIMPLE
在GCC中很多前端处理并不包含AST到GENERIC的转换,而是直接将AST转换成与语言无关的另外一种中间表示,即GIMPLE。
从GCC整体框架图可以看到,AST转换成GIMPLE之后首先进行静态单赋值(SSA), 然后进行各种优化pass。
gimplify_function_tree是生成GIMPLE的入口函数。
其作用是通过扫描函数的AST,分别对函数的返回值、函数参数、函数中的变量以及函数体的语句序列进行处理,并将其转换成对应的GIMPLE序列。
gimplify_body函数,对函数的内容进行GIMPLE转换。
gimplify_parameters对函数的参数列表进行GIMPLE转换。
gimplify_stmt,函数体的GIMPLE生成是通过调用gimplify_stmt完成的。
gimplify_expr 函数是GIMPLE生成的核心函数,由gimplify_stmt调用。
另外一个需要注意的是,对于带有操作数的GIMPLE语句,这些操作数的节点指针(类型为tree)将被连续存放在从该结构体最后一个成员tree op[1]开始的连续地址中。
对与GIMPLE的介绍仅列出了相关的函数,是为了能够快速的定位到GIMPLE生成的具体位置。想要了解更多细节,可以参考源码。
3.5 GCC中的RTL
RTL 中文叫做寄存器传输语言(Register Transfer Language)。RTL是一种非常接近汇编指令的中间表示。RTL采用了类似LISP语言的列表形式,描述了每一条指令的语义动作。
刚接触RTL的时候对其含义并不是太了解,导致代码难理解,因此在这儿对RTL的含义进行简要介绍,方便初学者能够快速入门GCC。
RTL是下面这样子的:
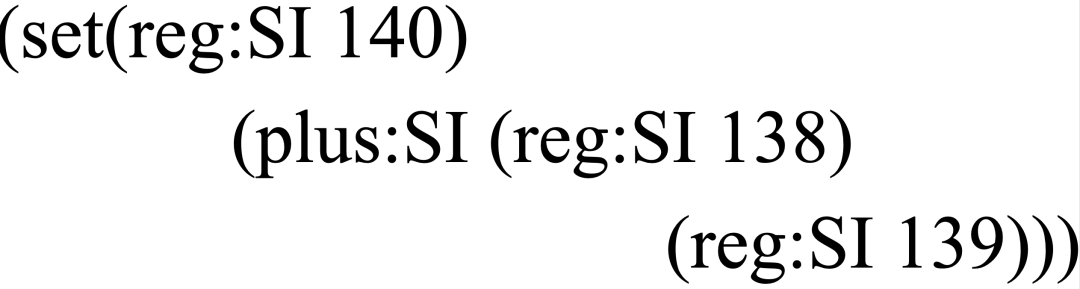
别以为是乱码,刚开始见的时候确实非常奇怪,但弄清楚之后非常简单。
其中set表示等号或者说是赋值,plus表示加法。SI表示寄存器存取的模式,SI表示该寄存器以32位整形的模式存取。
整个RTL的意思是:将寄存器139与寄存器138相加的值赋给寄存器140.
用一张图表示就是:
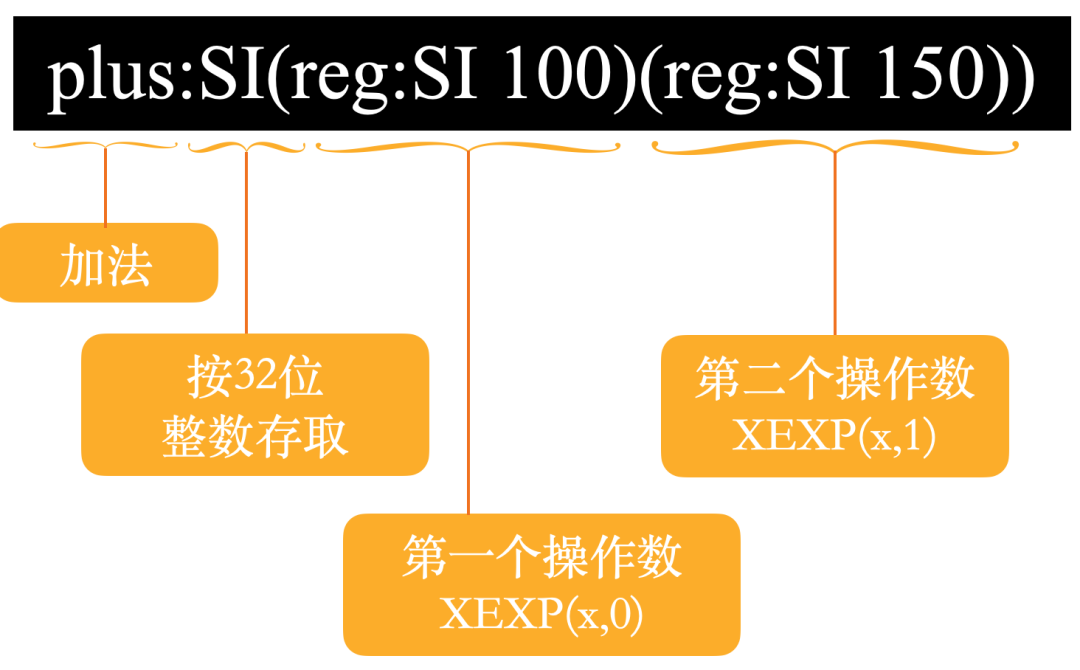
其中的XEXP(x,0)是GCC源码中用来取第一个操作数的代码。
知道了RTL表示后阅读源码就会轻松许多,当然还有一些细节没有介绍,需要了解的可以后台回复GCC,下载我收集的几份比较好的国外PPT,再配合源码看起来会方便很多。
4 总结
首先列举了学习编译原理的重要性以及编译原理理论。
然后分享了源码阅读心得。程序等于数据结构加算法,弄清楚数据结构基本上成功了一半。因此本文对GCC的整体架构和一些数据结构做了简要介绍,方便源码阅读。

最后介绍了开源编译器GCC从抽象语法树(AST)到汇编(ASM)的过程。主要是GCC用来表示抽象语法树的Generic以及两个中间表示GIMPLE和RTL。这个过程是逐渐从目标硬件无关到目标相关的过程。
-
Linux 下GCC的编译2023-09-11 3905
-
Keil MDK使用GCC编译器的方法2023-03-24 5119
-
【GCC编译运行报错】error while loading2022-08-26 9190
-
【GCC编译优化系列】-specs=kernel.specs2022-07-11 5512
-
【GCC编译优化系列】实战分析C代码遇到的编译问题及解决思路2022-07-10 2887
-
STM32 GCC编译环境搭建2021-12-22 954
-
嵌入式Linux开发环境搭建-(6)交叉编译QT4.8.7源码生成qmake工具2021-11-02 1286
-
基于GCC实现支持MISRAC的安全编译器2021-09-24 1045
-
如何在Keil MDK中使用GCC编译器工具链2020-11-20 6106
-
GCC编译器你需要知道的入门知识2018-03-13 9491
-
常见gcc编译警告整理以及解决方法2017-11-14 22404
-
Linux下C/C++编译器gcc使用指南2017-11-02 1025
-
编译UCOSII源码过程2017-10-30 1241
-
浅谈gcc编译器2017-10-18 1490
全部0条评论

快来发表一下你的评论吧 !
