

从计算机图形学到人工智能
描述
1. 引言
多年以后,面对图形处理器(GPU)在人工智能、加密货币、高性能计算、自动驾驶等多研究领域的广泛应用,如今的游戏发烧友们是否会回想起,1999年Nvidia发布专业游戏显卡GeForce256时那个炎热的夏天?
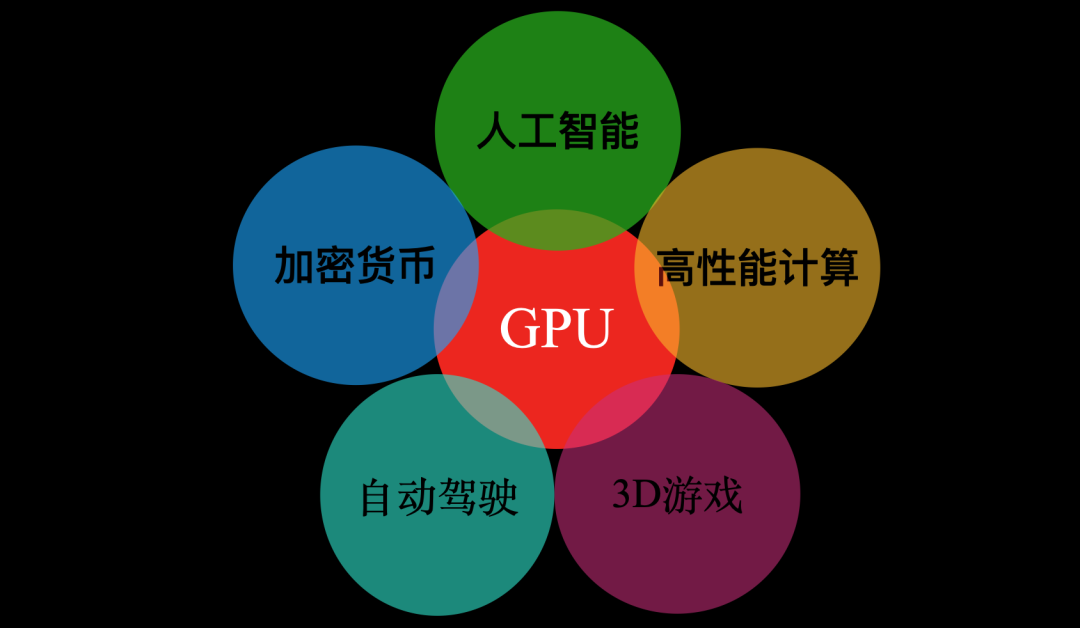
GPU应用
GeForce256发布以后GPU一词才被大众所接受,实际上1994年索尼发布PS1的时候就提出了GPU的概念,当时使用的是由东芝为索尼设计的GPU。
而后来在2002年ATI(已被AMD收购)提出的VPU(Visual Processing Unit)一词则在时代的浪潮中消失无踪。
从GeForce256发布至今的21年时间,GPU实现了从PC游戏时代到AI时代的巨大跨越。本文将和大家一起揭秘GPU为何能够撬动计算机图形学和人工智能这两个博大精深的领域。
2. GPU与计算机图形学
今年3月18日,国际计算机学会ACM官方公布了2019年度图灵奖(计算机界的诺贝尔奖)获得者Hanrahan和Catmull,以表彰他们对3D计算机图形学的贡献。
Hanrahan提出的renderMan很大程度上对GPU产生了影响。例如着色器(Shader)一词的出现,最先是由Pixar与1988年五月发布的renderMan接口规范中提出。
renderMan技术制作了一系列成功电影,其中包括《阿凡达》、《玩具总动员》、《泰坦尼克号》等。

renderMan渲染的阿凡达
另外,Hanrahan和他的学生还开发了一种用于 GPU 的语言:Brook,并最终催生了 NVIDIA的CUDA。
事实上,计算机图形学是一个广泛的学科,其中包括:
- 物理模拟:涉及各个物理分支相关数学。
- 模型处理:微积分,线性代数、微分几何、优化理论。
- 渲染:微积分、概率、光学中相关数学。
而我们的GPU,正是用来为计算机图形学中实时图像渲染加速的。
GPU的硬件设计上引入了图形管线,使得各任务可以通过流水线进行并行处理。
同时通过可编程的着色器,使得GPU硬件能够根据图形学算法更好的被使用。
通过下一节我们可以详细的了解到什么是GPU图形管线和可编程着色器。
2.1 GPU图形管线
GPU图形管线共分为三个部分,分别是应用程序阶段、几何阶段、光栅化阶段。
我们在最终在屏幕上看到的画面,就是3D模型经过这三个阶段渲染后得到的。

GPU图形管线
- 应用程序阶段
图形渲染管线概念上的第一个阶段,开发者通过程序的方式对图元数据等信息进行配置和调控,最后传输到下个阶段。
- 几何阶段
几何阶段分为模型视点变换、顶点着色、裁剪、屏幕映射等步骤。
模型视点变换 :由每个模型自己的局部坐标系转换到世界坐标系,然后到视觉空间,通过将每个模型的各顶点坐标与相应的变换矩阵相乘来实现。
下图是一个模型视点变换的实例,每个建模好的立方体的坐标是以原点为中心的局部坐标系,可以通过矩阵变换将各模型放到同一个世界坐标系中。
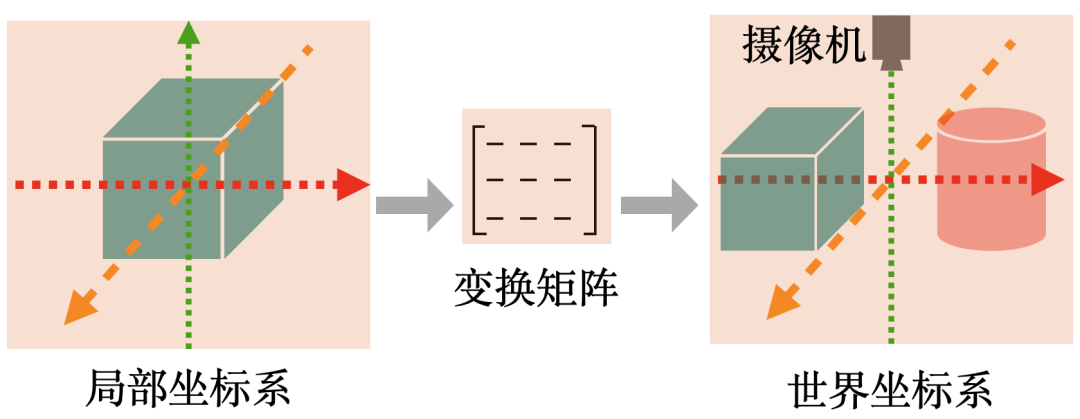
模型视点变换
顶点着色:着色是指确定材质的颜色,材质的颜色实际上和光照有关。目前常用的光照模型是冯氏光照模型,包括环境、漫反射和镜面光照。
裁剪 :对于在屏幕空间外的物体,我们并没有必要去计算它的颜色等信息
屏幕映射:是将之前步骤得到的坐标映射到对应的屏幕坐标系上。
- 光栅化阶段
给定经过变换和投影之后的顶点,颜色以及纹理坐标(均来自于几何阶段),给每个像素正确配色,以便正确绘制整幅图像,这个过程叫光栅化。
光栅化包括三角形设定、三角形遍历、像素着色、融合阶段(如下图所示)。

光栅化阶段
三角形设定阶段:计算三角形表面的差异和三角形表面的其他相关数据。
三角形遍历阶段:到那些采样点或像素在三角形中的过程通常叫三角形遍历。
像素着色阶段:主要目的是计算所有需要逐像素计算操作的过程。
融合阶段:合成当前储存于缓冲器中的由之前的像素着色阶段产生的片段颜色。
2.2 可编程着色器
可编程着色器(shader),简单来说就是可以运行在GPU上的程序,这种程序会使用特定的着色语言(类似于C语言)。
2.2.1 着色器语言
不同图形编程接口对应不同的着色语言,Windows平台上的图形编程接口DirectX使用的是HLSL,而跨平台的图形编程接口OpenGL则是使用的GLSL,HLSL与GLSL的语法与C语言十分相似。而新一代图形编程接口Vulkan则是直接定义了一套二进制中间语言SPIR-V。
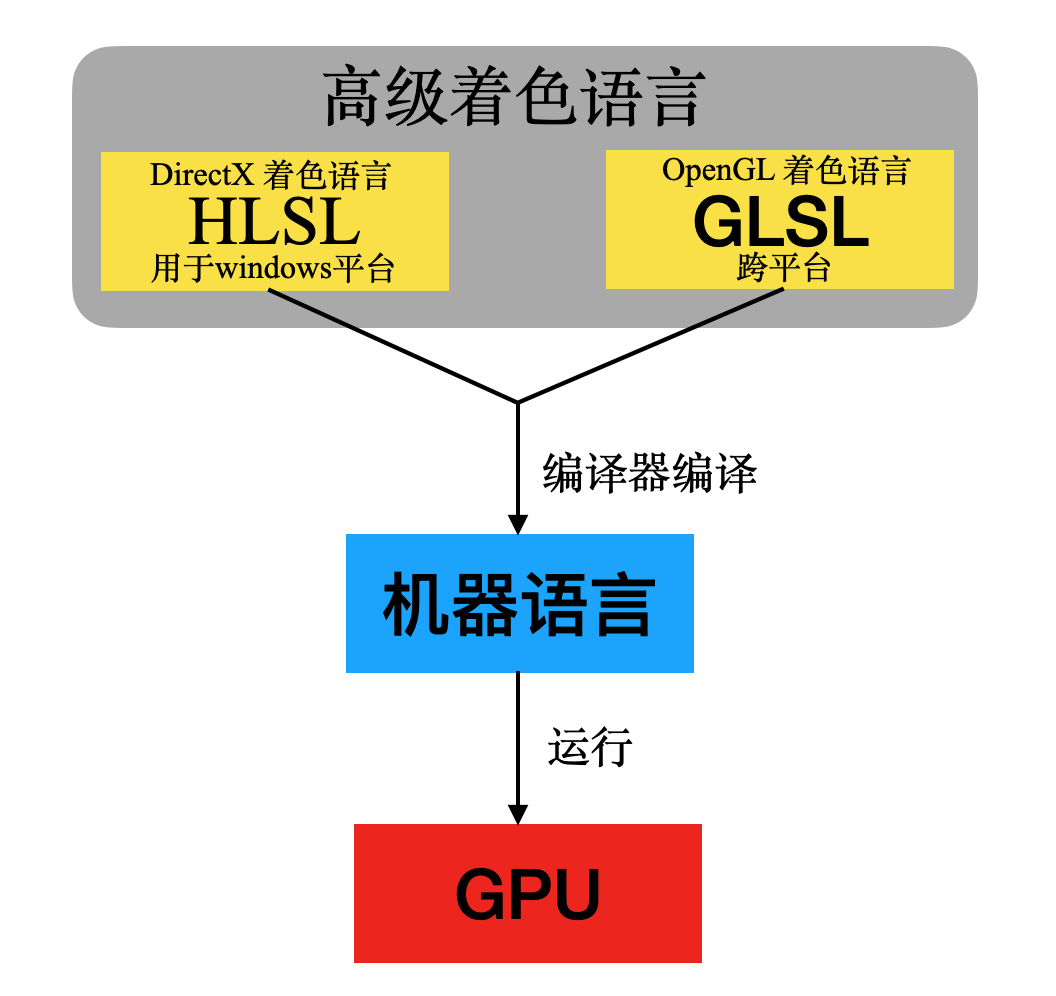
HLSL与GLSL都可以编译成独立于机器的中间语言(SPIR-V本身就是中间语言),然后在驱动中通过编译器转换成实际的机器语言。这样可以实现对不同硬件的兼容,因为不同厂商可以在驱动中调用自己的编译器生成自家GPU识别的指令。
有了着色语言以后,我们的工程师就可以通过高级语言来控制GPU对图形进行实时渲染。
但实际上我们的GPU一开始支持的Shader并没有那么多。这与GPU硬件的可编程渲染架构发展有关。
GPU可编程渲染架构经历了分离渲染架构到统一渲染架构的进化过程。
如下图所示,左边是分离渲染架构,右边是统一渲染架构。
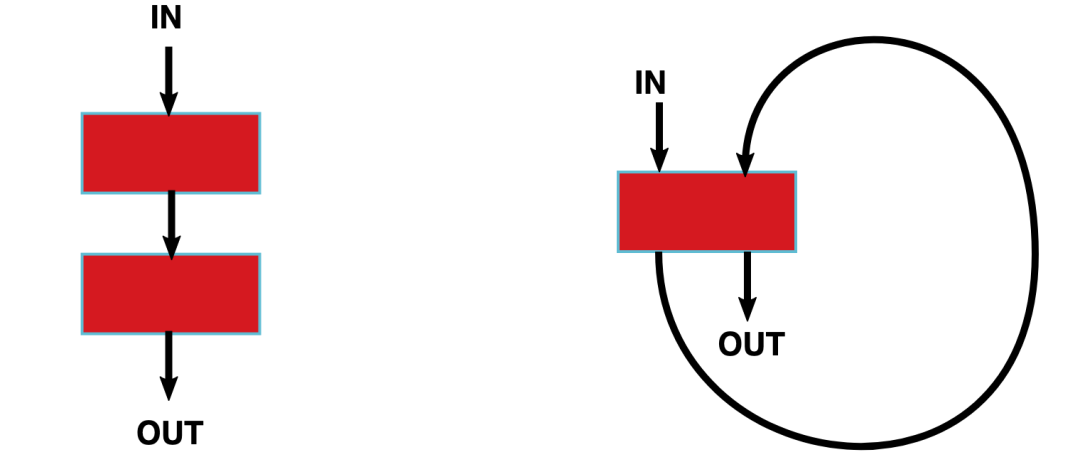
分离架构 vs 统一渲染架构
分离渲染架构:顶点着色器与像素着色器在两个不同的着色器核(红色部分)上运行。
统一渲染架构:所有的着色器程序都可以在同一个着色器核上运行。
与分离渲染架构相比,统一渲染架构更加灵活且利用率更高。
下面以DirectX(openGL也有对应的版本)发布为线索,分别介绍分离渲染架构与统一渲染架构的发展历史。
2.2.2 分离渲染架构

- 1999年微软DirectX7提供了硬件顶点变换的编程接口,NV的Geforc256对此进行了支持,从此NV公司从众多显卡制造商中杀出重围,逐渐占据了龙头老大的地位。
- 2001年DirectX8发布,包含Shader Model 1.0标准。遵循这一模型的GPU可以具备顶点和像素的可编程性。同年,NVIDIA发布了Geforce3,ATI发布了Radeon8500,这两种GPU支持顶点编程。但是这一时期的GPU都不支持像素编程,只是提供了简单的配置功能。
- 2002年,DirectX9.0公布,包含Shader Model 2.0。此模型是真正的可编程顶点着色器及像素着色器。顶点着色器主要执行顶点的变换、完成光照与材质的运用及计算等相关操作。
- 2003年,NVIDIA和ATI发布的新产品都同时具备了可编程顶点处理和可编程像素处理器。从此,GPU具备了可编程属性,也叫做可编程图形处理单元。
2.2.3 统一渲染架构
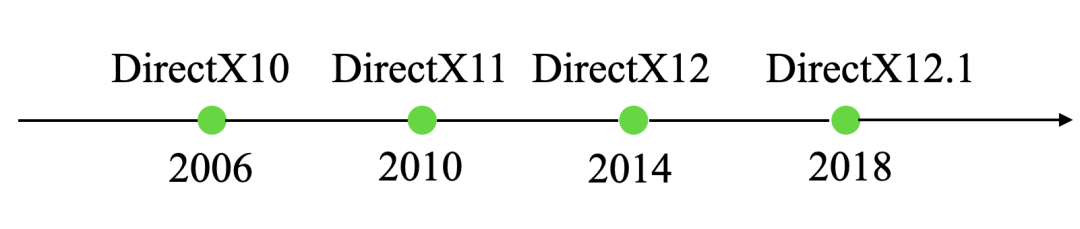
- 2006年包含DirectX10的 Shader Model4.0发布,采用统一渲染架构,使用统一的流处理器。这一时期,比较有代表性的GPU有NVIDIA的Geforce9600和ATI的Radeon 3850。
- 2010年,包含DirectX11的Shader Model 5.0 发布,增加了曲面细分着色器、外壳着色器、镶嵌单元着色器、域着色器、计算着色器。这一时期比较有代表性的GPU是GeForece405
- 2014年,DirectX 12发布,主要特性有轻量化驱动层、硬件级多线程渲染支持、更完善的硬件资源管理,比较有代表性的GPU有GeForceGT 710
- 2018,DirectX 12.1发布,代表性GPU是TITAN RTX,拥有1770MHz主频,24G显存,384位带宽,支持8K分辨率。
以上仅列举了部分Shader Model的特性,如要查看完整特性,有兴趣的同学可以参考这个链接Shader Model
2.3 小结
上一节介绍了GPU渲染架构发展历史、GPU图形管线、以及能够在GPU上运行的高级着色语言。
可以看到,GPU对图形渲染的过程需要并行处理海量数据,涉及大量矩阵运算,这一特性使得GPU能够在人工智能应用中发挥巨大的作用。
下一节我们将看到GPU的这些特性是如何为深度学习加速的。
3. GPU与人工智能
2018年,国际计算机学会将图灵奖颁发给了深度学习领域的三位大师Hinton,LeCun 和 Bengio。
深度学习刚被提出的时候曾经遭到学术届的质疑,而如今却成为了人工智能领域的热点。
人工智能的三大要素:算法、算力、大数据。
深度学习被质疑的一部分原因正是因为当时的计算能力无法满足深度学习的要求,而如今异构计算则成为了深度学习的重要支柱。
使用不同的类型指令集、不同的体系架构的计算单元,组成一个混合的系统,执行计算的特殊方式,就叫做异构计算。
3.1 异构计算
目前关于深度学习流行的异构解决方案共三种,分别是ASIC、FPGA、GPU。
但是从开发人员数量和受欢迎程度以及生态系统来说,GPU无疑是最有优势的。
通过下面三种方案的对比,我们可以看到这三种方案各自的优缺点。
- CPU+ASIC
ASIC即专用集成电路,是指应特定用户要求和特定电子系统的需要而设计、制造的集成电路。
优点::体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。
缺点:算法固定,一旦算法变化就无法使用。目前人工智能算法远没有到算法平稳期,ASIC专用芯片如何做到适应各种算法是个最大的问题。
实例:寒武纪的NPU、地平线的BPU、Google的TPU都是属于ASIC。如图是Google的TPU,兼具了CPU与ASIC的特点。

Google TPU
- CPU+FPGA
FPGA是一种硬件可重构的体系结构。它的英文全称是Field Programmable Gate Array,中文名是现场可编程门阵列。

CPU+FPGA
优点:灵活性高、无需取指令、译码,执行效率高。FPGA中的寄存器和片上内存由各自的逻辑进行控制无需仲裁和缓存。多个逻辑单元之间的通信已经确定,无需通过共享内存进行通信。
缺点:总体性价比和效率不占优势。FPGA的大规模开发难度偏高,从业人员相对较少,生态环境不如GPU。
实例:微软使用FPGA为Bing搜索智能化进行加速。
- CPU+GPU

CPU+GPU
GPU具有更好的生态环境,例如具备CUDA支持的GPU为用户学习Caffe、Theano等研究工具提供了很好的入门平台。为初学者提供了相对更低的应用门槛。
除此之外,CUDA在算法和程序设计上相比其他应用更加容易,通过NVIDIA多年的推广也积累了广泛的用户群,开发难度更小。
最后则是部署环节,GPU通过PCI-e接口可以直接部署在服务器中,方便快速。得益于硬件支持与软件编程、设计方面的优势,GPU才成为了目前应用最广泛的平台。
3.2 GPU与深度学习
与大多机器学习算法一样,深度学习依赖于数学和统计学计算。人工神经网络(ANN),卷积神经网络(CNN)和循环神经网络(RNN)是一些现代深度学习的实现。
这些算法都有以下基本运算:
- 矩阵相乘:所有的深度学习模型中都包括这一运算,计算十分密集。
- 卷积:也是深度学习中常用的运算,占用了模型中大部分的浮点运算。
上节中提到,GPU在进行图像渲染时间需要处理每秒大量的矩阵乘法运算,
下图是一个简单直观的例子:将一幅图像倒置,在我们肉眼看来是一幅连续的图形,在GPU看来实际上是由多个离散的像素组成,将图像倒置实际上对每个像素做矩阵乘法。
当然这只是一个简单的例子,实际上的3D渲染处理的数据比这更多也更加复杂。

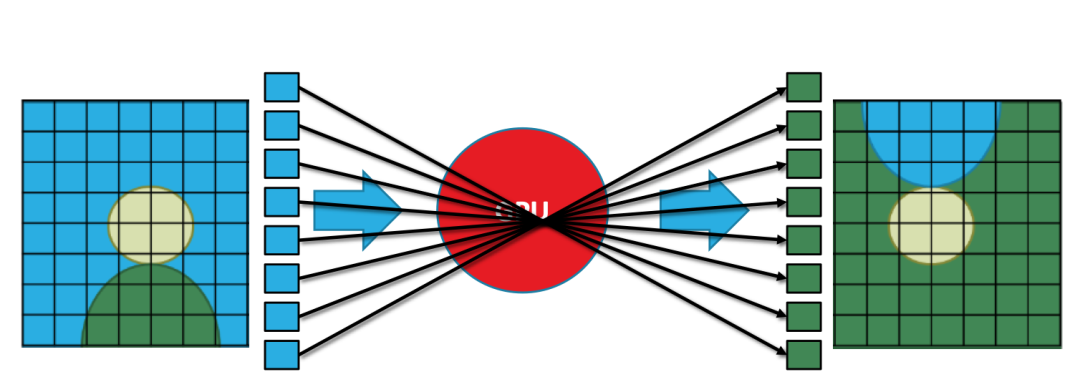
GPU并行处理
深度学习同样需要并行处理,因为神经网络是一种典型的并行结构,每个节点的计算简单且独立,但是数据庞大,通常深度学习的模型需要几百亿甚至几万亿的矩阵运算。
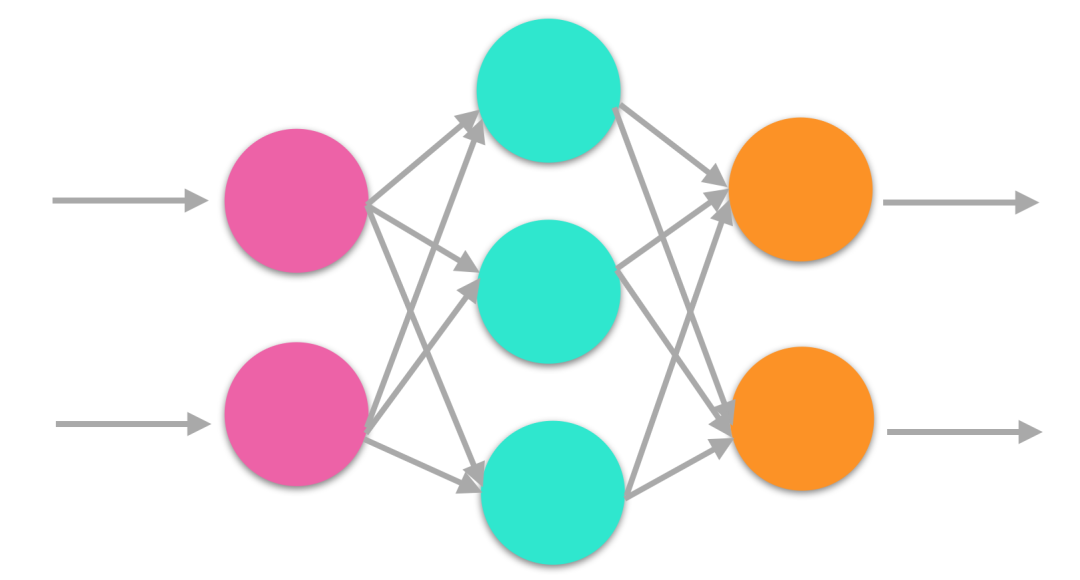
神经网络结构
可以看到,图形渲染与深度学习有着相似之处。这两种场景都需要处理每秒大量的矩阵乘法运算。
而GPU拥有数千个内核的处理器,能够并行执行数百万个数学运算。
因此GPU完美地与深度学习技术相契合。使用GPU做辅助计算,能够更快地提高AI的性能。
总的来说,GPU做深度学习有三大优势:
- 每一个GPU拥有大量的处理器核心,允许大量的并行处理。
- 深度学习需要处理大量的数据,需要大量的内存带宽(最高可达到750GB/S,而传统的CPU仅能提供50GB/S),因此GPU更适合深度学习。
- 更高的浮点运算能力。浮点运算能力是关系到3D图形处理的一个重要指标。现在的计算机技术中,由于大量多媒体技术的应用,浮点数的计算大大增加了,比如3D图形的渲染等工作,因此浮点运算的能力是考察处理器计算能力的重要指标。
3.3 小结
本节介绍了异构计算对深度学习加速的优缺点,主要包括FPGA、ASIC、GPU三种硬件解决方案。
最后通过比较GPU进行图形渲染与深度学习计算时的相似之处,解释了GPU为何能够加速深度学习,以及GPU加速深度学习的优势。
4. 总结
计算机图形学与人工智能是两个博大精深的领域,本文仅从GPU实时渲染与GPU并行加速的角度进行了阐述。
写这篇文章的初衷是因为联想到GPU与近三年来的图灵奖领域息息相关。
2019年图灵奖授予了计算机图形学领域、2018年授予了深度学习领域,2017年授予了计算机体系结构领域。
GPU实时渲染、GPU并行加速、GPU架构分别与这三个领域有着千丝万缕的联系,因此想到了写这样一篇GPU探秘的文章。
5. 推荐阅读
-
计算机图形学:探索虚拟世界的构建之道2024-05-07 1480
-
计算机图形学定义2021-08-31 1577
-
计算机图形学 数字图像处理和计算机视觉是什么?2020-04-04 5828
-
计算机图形学年鉴:研究现状、应用和未来2019-01-03 1657
-
2018计算机图形学AMiner的研究报告详细资料免费下载2018-12-25 1110
-
计算机图形学总览:图像和图像的概念辨析2018-08-21 7621
-
清华AMiner团队发布计算机图形学研究报告2018-08-20 4001
-
NVIDIA将人工智能引入计算图形学 NVIDIA GPU渲染加速视觉特效2018-01-04 9544
-
计算机图形学的非线性投影研究2017-11-11 1059
-
MFC编程基础-图形学2016-09-01 749
-
计算机图形学讲义2016-03-22 1119
-
基于OpenGL的计算机图形学教学改革探索2012-07-27 1015
-
什么是计算机图形学2009-05-24 3608
-
计算机图形学原理教程(Visual+C++版)2008-07-15 729
全部0条评论

快来发表一下你的评论吧 !
