

AIGC可编辑的图像生成方案
描述
ControlNet给出的实验结果实在是过于惊艳了,近期视觉领域最让人兴奋的工作。可编辑图像生成领域异常火热,看了一些相关文章,选出几篇感兴趣的文章记录一下。
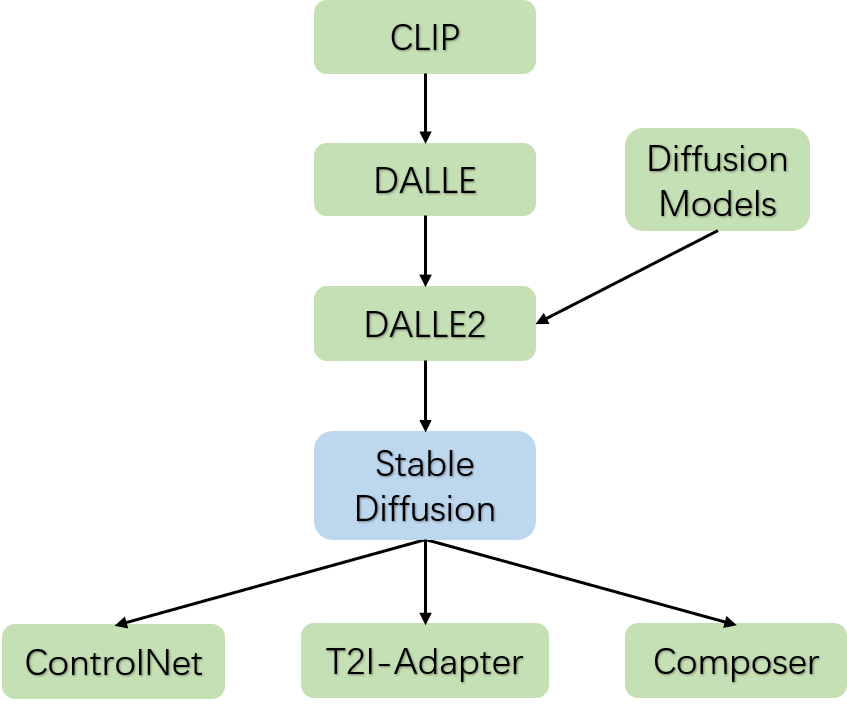
从CLIP模型开始,OpenAI走通了大规模图文对预训练模型的技术路径,这代表着文字域和图片域是可以很好的对齐;紧随其后,OpenAI在CLIP的技术基础上,发布了DALLE文字生成图片的模型,生成图片的质量远超之前的模型,这主要得益于大规模图文对预训练的CLIP模型;
与此同时,Diffusion Models的图像生成方法的图像生成质量也超越了以往的GAN、VAE等模型,并且随着算法的精进,推理速度不断加快,预示着Diffusion Models即将全面替代GAN、VAE等生成模型;果不其然,OpenAI将DALLE模型和Diffusion Models结合发布了DALLE2模型,生成图片的质量进一步提高。
在DALLE2这个阶段,虽然图像生成质量相比以往有了质变,但是图像生成的过程是不可控,这导致各种绘画设计行业无法在工作中使用,况且DALLE2还没有开源。随着Stable Diffusion模型的发布和开源,可编辑图像生成领域变得空前火热,出现了各种各样DIY的产物,Stable Diffusion模型算是一个关键的时间节点。
而在2023年2月份大概1周之内同时涌现出了ControlNet、T2I-Adapter和Composer三个基于Stable Diffusion的可编辑图像生成模型,其中ControlNet再一次带热了AI绘画设计。
下面主要介绍一下Stable Diffusion、ControlNet、T2I-Adapter和Composer四篇文章,最后谈谈图像结构化和图像生成之间的关系。
Stable Diffusion
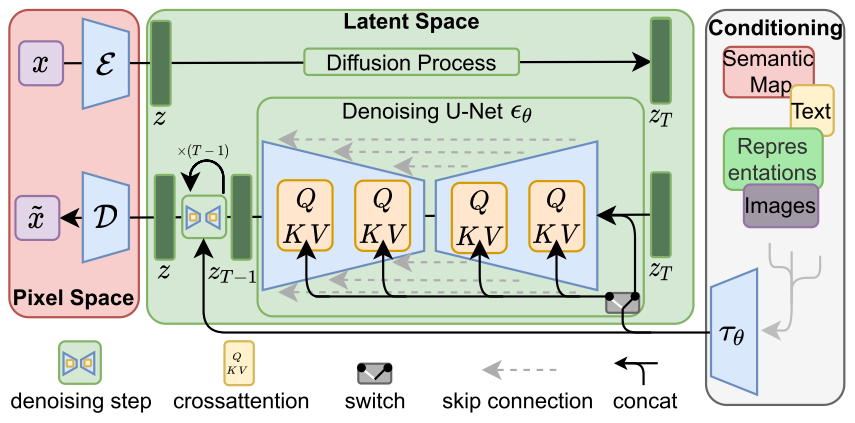
Stable Diffusion模型在Diffusion Models(DM)的基础上,增加了conditioning机制。
通过conditioning机制,可以将semantic map、text、representations和images等信息传递到DM模型中,通过cross-attention机制进行信息的融合,通过多个step进行扩散生成图片。


如上面两个结果图所示,Stable Diffusion可以通过版面结构图或者语义分割图来控制图像的生成。
ControlNet
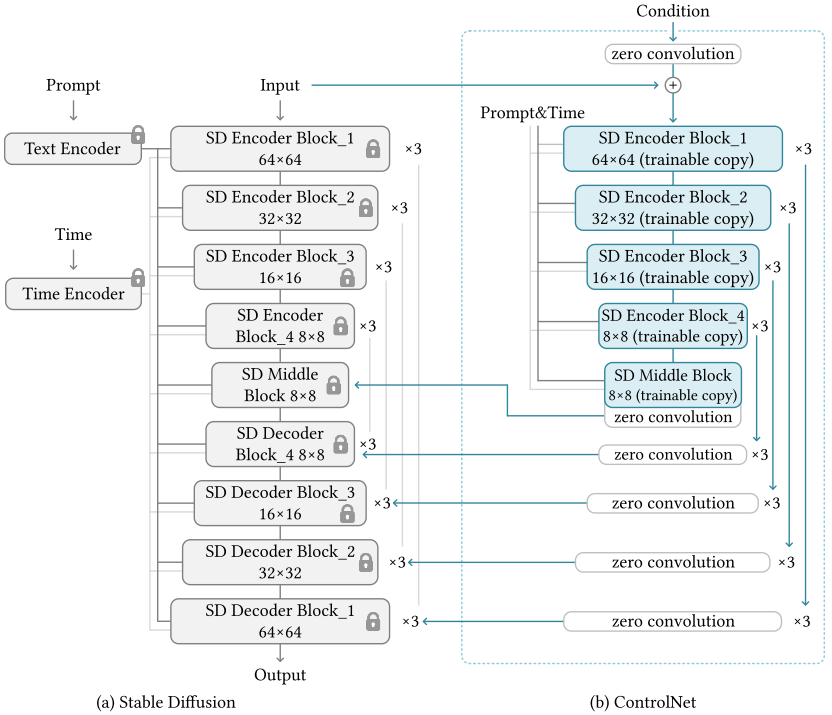
ControlNet在Stable Diffusion(SD)的基础上,锁住SD的参数,并且增加了一个可学习的分支,该分支的开头和结尾都增加zero convolution(初始化参数为0),保证训练的稳定性,并且Condition的特征会叠加回SD的Decoder特征上,进而达到控制图像生成的目的。
相比于SD模型,ControlNet有两点区别:
ControlNet相比于SD,丰富了Condition的种类,总共9大类,包括Canny Edge、Canny Edge(Alter)、Hough Line、HED Boundary、User Sketching、Human Pose(Openpifpaf)、Human Pose(Openpose)、Semantic Segmentation(COCO)、Semantic Segmentation(ADE20K)、Depth(large-scale)、Depth(small-scale)、Normal Maps、Normal Maps(extended)和Cartoon Line Drawing。
ControlNet不需要重新训练SD模型,这极大的降低了可编辑图像生成领域的门槛,减少二次开发的成本。

从上图可以看到,ControlNet可以先提取出动物的Canny edge,然后再在Canny edge的基础上渲染出不同风格环境色彩的动物图片,amazing!





上图是一些ControlNet图像生成的例子,更多的例子可以阅读原文。
T2I-Adapter
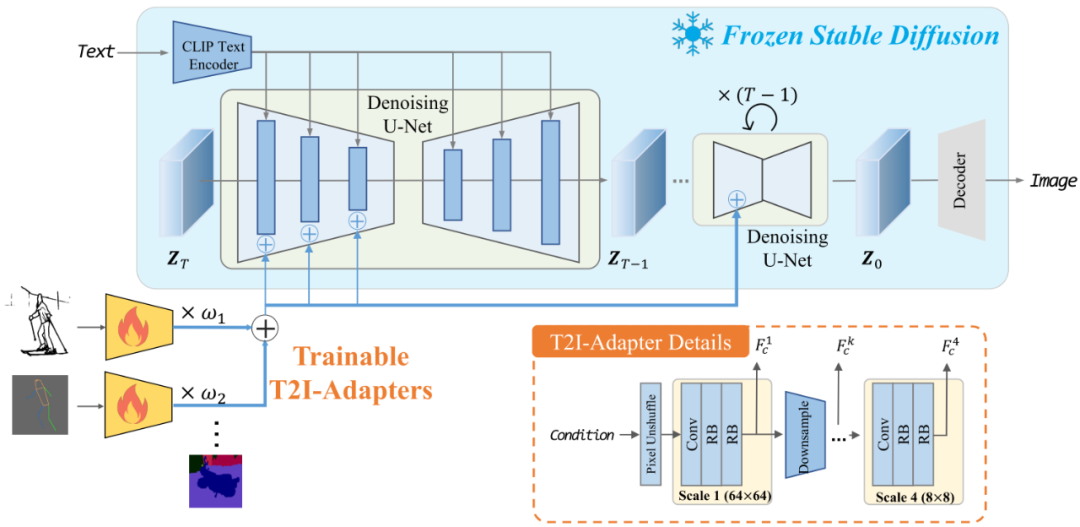
T2I-Adapter跟ControlNet非常类似,主要不同有以下几点区别:
T2I-Adapter可以同时组合输入多种类型的Condition
T2I-Adapter是从SD的Encoder部分传入Condition的
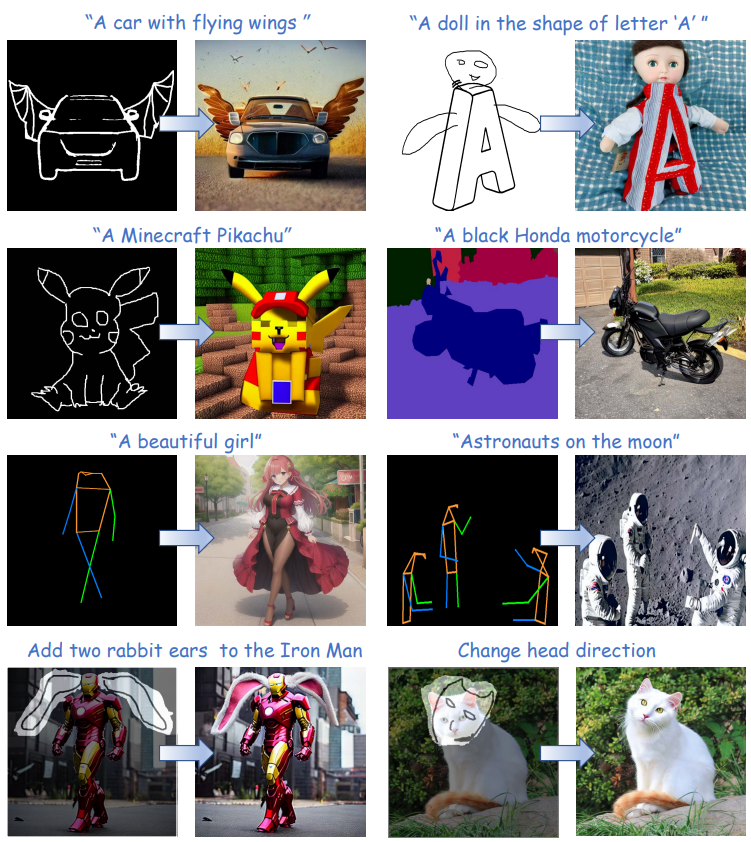
可以看到T2I-Adapter生成的图像有着类似ControlNe的可编辑效果。
Composer
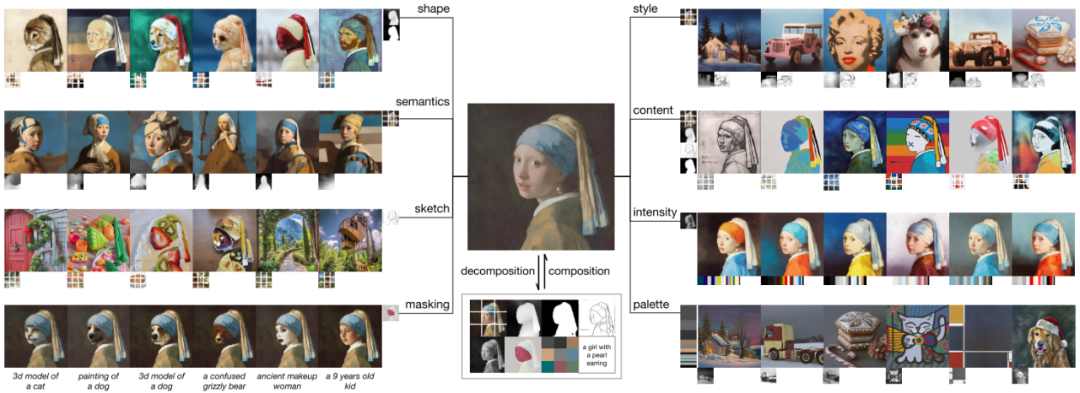
Composer跟ControlNet和T2I-Adapter的思路也是类似的,但是Composer提出了一个有意思的点,就是可编辑图像生成其实就是对图像各种元素的组合,Composer先用各种不同的模型将各种不同的图片分解成各种元素,然后将不同图片的元素进行重组。比如上图的戴珍珠耳环的少女,可以分解成shape、semantics、sketch、masking、style、content、intensity、palette、文字等等元素,然后跟其他不同图片的元素进行想要的重组。
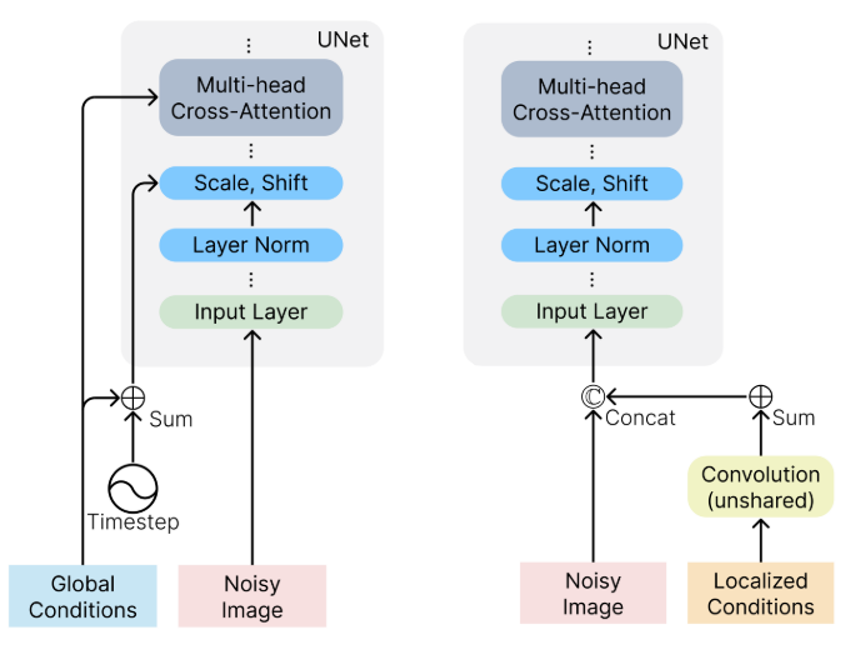
Composer将各种元素区分成两类,一类是Global Conditions,另一类是Localized Conditions。其中Global Conditions包括sentence embeddings, image embeddings, and color histograms,并且需要添加到Timestep中;Localized Conditions包括segmentation maps, depthmaps, sketches, grayscale images, and masked images,并且需要添加到Noisy Image中。


上面图像生成的结果,充分表现出了Composer模型可编辑的多样性和丰富性。
图像结构化和图像生成
我在这里将图像检测、图像分割、深度估计等任务统称为图像结构化。从某种意义上来说,图像结构化其实可以认为是一种特殊的图像生成,只不过生成的图片是某个单一维度的特征,比如是深度图、mask图、关键点图等等。ControlNet和Composer某种意义上就是将结构化图片通过文字控制来丰富细节进而生成想要的图片;而图像结构化其实就是把维度复杂、细节丰富的图片生成维度单一、细节简单的结构化图片。
图像结构化和图像生成其实也就是对应着Composer文章里面提到的分解和合成两个过程。我对于可编辑图像生成领域未来的想法是,尽可能准确丰富的提取图像中各个维度的结构化信息(包括文字信息),然后通过Stable Diffusion模型组合融入想要的结构化信息,进而达到完全自主可控的图像生成。
总结
可编辑的图像生成其实蕴含着人机交互的思想,人的意志通过输入的文字提示和图片提示传递给模型,而模型(或者说是机器)生成的图片恰好反映出了人的思想。可编辑图像生成会改变绘画设计等领域的创作模式(比如公仔服装周边等等,可以无限压缩设计绘画的时间),进而孕育出新的更有活力的创业公司,互联网行业可能会迎来第二增长曲线。
审核编辑:刘清
-
AIGC入门及鸿蒙入门2025-01-13 983
-
AIGC是什么及其应用 AIGC的定义和工作原理2024-11-22 9135
-
AIGC与传统内容生成的区别2024-10-25 3093
-
微软AI新成果:将不可编辑PDF转化为可编辑文档2024-05-30 1881
-
伯克利AI实验室开源图像编辑模型InstructPix2Pix,简化生成图像编辑并提供一致结果2023-08-28 1745
-
基于扩散模型的图像生成过程2023-07-17 4589
-
AIGC最新综述:从GAN到ChatGPT的AI生成历史2023-03-13 4378
-
RTthread移植代码自动生成方案2022-02-11 925
-
基于图像驱动的三维人脸自动生成与编辑算法2021-06-25 966
-
GAN图像对抗样本生成方法研究综述2021-04-28 1092
-
基于模板、检索和深度学习的图像描述生成方法2021-04-23 1783
-
一种全新的遥感图像描述生成方法2021-04-20 1431
全部0条评论

快来发表一下你的评论吧 !
