

一条SQL查询语句是怎么去执行的?(中)
电子说
描述
2. 解析与优化
服务器收到客户端传来的请求之后,还需要经过查询缓存、词法语法解析和预处理、查询优化的处理。
2.1 查询缓存
如果我们两次都执行同一条查询指令,第二次的响应时间会不会比第一次的响应时间短一些?
之前使用过Redis缓存工具的读者应该会有这个很自然的想法,MySQL收到查询请求之后应该先到缓存中查看一下,看一下之前是不是执行过这条指令。如果缓存命中,则直接返回结果;否则重新进行查询,然后加入缓存。
MySQL确实内部自带了一个缓存模块。
现在有一张500W行且没有添加索引的数据表,我执行以下命令两次,第二次会不会变得很快?
SELECT * FROM t_user WHERE user_name = '蝉沐风'
并不会!说明缓存没有生效,为什么?MySQL默认是关闭自身的缓存功能的,查看一下query_cache_type变量设置。
mysql> show variables like 'query_cache_type';
+------------------------------+---------+
| Variable_name | Value |
+------------------------------+---------+
| query_cache_type | OFF |
+------------------------------+---------+
默认关闭就意味着不推荐,MySQL为什么不推荐用户使用自己的缓存功能呢?
- MySQL自带的缓存系统应用场景非常有限,它要求SQL语句必须一模一样,多一个空格,变一个大小写都被认为是两条不同的SQL语句
- 缓存失效非常频繁。只要一个表的数据有任何修改,针对该表的所有缓存都会失效。对于更新频繁的数据表而言,缓存命中率非常低!
所以缓存的功能还是交给专业的ORM框架(比如MyBatis默认开启一级缓存)或者独立的缓存服务Redis更加适合。
MySQL8.0已经彻底移除了缓存功能
2.2 解析器 & 预处理器(Parser & Preprocessor)
现在跳过缓存这一步了,接下来需要做什么了?
如果我随便在客户端终端里输入一个字符串chanmufeng,服务器返回了一个1064的错误
mysql> chanmufeng;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'chanmufeng' at line 1
服务器是怎么判断出我的输入是错误的呢?这就是MySQL的Parser解析器的作用了,它主要包含两步,分别是词法解析和语法分析。
2.2.1 词法解析
以下面的SQL语句为例
SELECT * FROM t_user WHERE user_name = '蝉沐风' AND age > 3;
分析器先会做“词法分析”,就是把一条完整的SQL语句打碎成一个个单词,比如一条简单的SQL语句,会打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
MySQL 从你输入的SELECT这个关键字识别出来,这是一个查询语句。它也要把字符串t_user识 别成“表名 t_user”,把字符串user_name识别成“列 user_name"。
2.2.2 语法分析
做完词法解析,接下来需要做语法分析了。
根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,比如单引号是否闭合,关键词拼写是否正确等。
解析器会根据SQL语句生成一个数据结构,这个数据结构我们成为解析树。
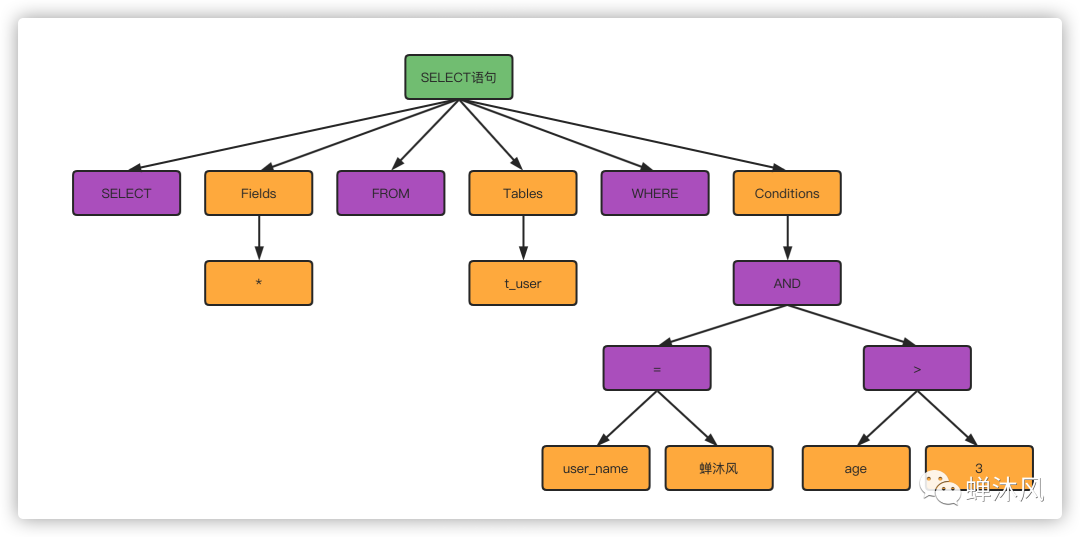 我故意拼错了
我故意拼错了SELECT关键字,MySQL报了语法错误,就是在语法分析这一步。
mysql> ELECT * FROM t_user WHERE user_name = '蝉沐风' AND age > 3;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'ELECT * FROM t_user WHERE user_name = '蝉沐风'' at line 1
词法语法分析是一个非常基础的功能,Java 的编译器、百度搜索引擎如果要识别语句,必须也要有词法语法分析功能。
任何数据库的中间件,要解析 SQL完成路由功能,也必须要有词法和语法分析功能,比如 Mycat,Sharding-JDBC(用到了Druid Parser)等都是如此。在市面上也有很多的开源的词法解析的工具,比如 LEX,Yacc等。
2.2.3 预处理器
如果我们写了一条语法和词法都没有问题的SQL,但是字段名和表名却不存在,这个错误是在哪一个阶段爆出的呢?
词法解析和语法分析是无法知道数据库里有什么表,有哪些字段的。要知道这些信息还需要解析阶段的另一个工具——预处理器。
它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。预处理之后得到一个新的解析树。
本质上,解析和预处理是一个编译过程,涉及到词法解析、语法和语义分析,更多细节我们不会探究,感兴趣的读者可以看一下编译原理方面的书籍。
2.3 查询优化器(Optimizer)与查询执行计划
到了这一步,MySQL终于知道我们想查询的表和列以及相应的搜索条件了,是不是可以直接进行查询了?
还不行。MySQL作者担心我们写的SQL太垃圾,所以有设计出一个叫做查询优化器的东东,辅助我们提高查询效率。
2.3.1 什么是查询优化器?
一条 SQL语句是不是只有一种执行方式?或者说数据库最终执行的 SQL是不是就是我们发送的 SQL?
不是。一条 SQL 语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。
举一个非常简单的例子,比如你执行下面这样的语句:
SELECT * FROM t1, t2 WHERE t1.id = 10 AND t2.id = 20
- 既可以先从表 t1 里面取出 id=10 的记录,再根据 id 值关联到表 t2,再判断 t2 里面 id 的值是否等于 20。
- 也可以先从表 t2 里面取出 id=20 的记录,再根据 id 值关联到表 t1,再判断 t1 里面 id 的值是否等于 10。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是 MySQL的查询优化器的模块(Optimizer)的工作。
查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选择一种最优的执行计划,MySQL 里面使用的是基于开销(cost)的优化器,哪种执行计划开销最小,就用哪种。
2.3.2 优化器究竟做了什么?
举两个简单的例子∶
- 当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表。
- 有多个索引可以使用的时候,选择哪个索引。
实际上,对于每一种数据库来说,优化器的模块都是必不可少的,他们通过复杂的算法实现尽可能优化查询效率。
往细节上说,查询优化器主要做了下面几方面的优化:
- 子查询优化
- 等价谓词重写
- 条件化简
- 外连接消除
- 嵌套连接消除
- 连接消除
- 语义优化
本文不会对优化的细节展开讲解,大家先对MySQL的整体架构有所了解就可以了,具体细节之后单独开篇介绍
但是优化器也不是万能的,如果SQL语句写得实在太垃圾,再牛的优化器也救不了你了。因此大家在编写SQL语句的时候还是要有意识地进行优化。
2.3.3 执行计划
优化完之后,得到一个什么东西呢?优化器最终会把解析树变成一个查询执行计划。
查询执行计划展示了接下来执行查询的具体方式,比如多张表关联查询,先查询哪张表,在执行查询的时候有多个索引可以使用,实际上该使用哪些索引。
MySQL提供了一个查看执行计划的工具。我们在 SQL语句前面加上 EXPLAIN就可以看到执行计划的信息。
mysql> EXPLAIN SELECT * FROM t_user WHERE user_name = '';
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_user | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
如果要得到更加详细的信息,还可以用FORMAT=JSON,或者开启optimizer trace。
mysql> EXPLAIN FORMAT=JSON SELECT * FROM t_user WHERE user_name = '';
文本不会带大家详细了解执行计划的每一个参数,内容很庞杂,大家先对MySQL的整体架构有所了解就可以了,具体细节之后单独开篇介绍
-
查询SQL在mysql内部是如何执行?2024-01-22 1447
-
MySQL执行过程:如何进行sql 优化2023-12-12 1241
-
oracle执行sql查询语句的步骤是什么2023-12-06 2049
-
sql where条件的执行顺序2023-11-23 3525
-
sql查询语句大全及实例2023-11-17 3302
-
一条SQL如何被MySQL架构中的各个组件操作执行的?2023-05-12 983
-
SQL语句和自定义查询在导入包中可用2023-04-16 1840
-
一条SQL查询语句是怎么去执行的?(上)2023-03-03 930
-
简述SQL更新语句的执行流程12023-02-14 1254
-
一条SQL语句是怎么被执行的2021-09-12 2241
-
select语句和update语句分别是怎么执行的2020-11-03 4657
-
DSP执行一条语句的时间2016-10-15 15841
-
在Delphi中动态地使用SQL查询语句2009-05-10 6718
全部0条评论

快来发表一下你的评论吧 !
