

一文彻底搞懂MySQL锁究竟锁的啥1
电子说
描述
MySQL锁系列文章已经鸽了挺久了,最近赶紧挤了挤时间,和大家聊一聊MySQL的锁。
只要学计算机,「锁」永远是一个绕不过的话题。MySQL锁也是一样。
一句话解释MySQL锁:
MySQL锁是解决资源竞争的一种方案。
短短一句话却包含了3点值得我们注意的事情:
- 对什么资源进行竞争?
- 竞争的方式(或者说情形)有哪些?
- 锁是如何解决竞争的?
这篇文章开始带你循序渐进地理解这几个问题。
1. 资源的竞争方式
MySQL对资源的操作无非就是 读 、写两种方式,但是由于事务并发执行的存在,因此对同一资源的并发访问存在3种形式:
- 读—读:并发事务同时读取相同资源。由于读操作不会改变资源本身,因此 这种情况下并不存在并发安全性问题 。
- 读—写/写—读:一个事务对资源进行读操作,另一个事务对资源进行写操作。
- 写—写:并发事务同时对同一个资源进行写操作。
2. 读—写/写—读下的问题
假设一种情形,一个事务先对某个资源进行读操作,然后另一个事务再对该资源进行写操作,如果两个事务到此为止,必然不会导致并发问题。
可是事务这种东西,一般情况下就是包含有很多个子操作啊。
2.1. 幻读
想象一下啊,假设事务T1和T2并发执行,T1先查找了所有name为「王刚蛋」的用户信息,此时发现拥有这个硬汉名字的用户只有一个。然后T2插入了一个同样叫做「王刚蛋」的用户的信息,并且提交了。
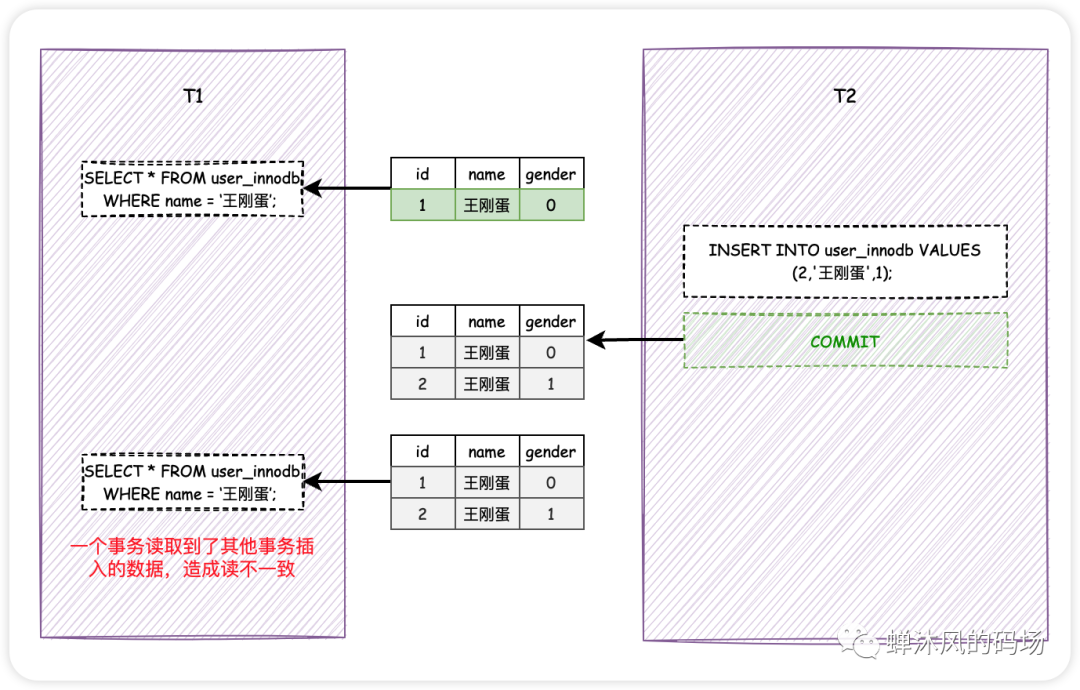
幻读

2.2. 不可重复读
再来,同样是T1和T2两个事务,T1通过id = 1查询到了一条数据,然后T2紧接着UPDATE(DELETE也可以)了该条记录,不同的是,T2紧接着通过COMMIT提交了事务。

此时,T1再次执行相同的查询操作,会发现数据发生了变化,name字段由「王刚蛋」变成了「蝉沐风」。
如果一个事务读到了另一个已提交事务修改过的(或者是删除的)数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做 不可重复读 。
2.3. 脏读
事情还没结束,假设T1和T2都要访问user_innodb表中id为1的数据,不同的是T1先读取数据,紧接着T2修改了数据的name字段,需要注意的是,T2并没有提交!

此时,T1再次执行相同的查询操作,会发现数据发生了变化,name字段由「王刚蛋」变成了「蝉沐风」。
如果一个事务读到了另一个未提交事务修改过的数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做 脏读 。
2.4. 锁与MVCC的关系
总结一下:我们在读—写,写—读的情况下会遇到3种读不一致性的问题,脏读、不可重复读以及幻读。
那写—写呢?很显然,在不做任何措施的情况下,并发会出现更大的问题。那该怎么办呢?
一切的并发问题都可以通过串行化解决,但是串行化效率太低了!
再优化一下,一切并发问题都可以通过加锁来解决,这种方案我们称为 基于锁的并发控制 ( Lock Bases Concurrency Control , LBCC )!但是在读多写少的环境下,客户端连读取几条记录都需要排队,效率还是太低了!
因此,MySQL的设计者为事务之间的隔离性提供了不同的级别,使得开发者可以根据自己的业务场景设置不同的隔离级别,来解决(或者部分解决)读—写/写—读下的读一致性问题,而不是一上来就加锁。
这种机制叫做MVCC,如果你对这个概念不是很了解,我建议你暂停一下,读一下我的事务的隔离性与MVCC这篇文章,写得贼好!!(自卖自夸一下)
那有了MVCC是不是在读—写/写—读的情况下就不需要锁了呢?那也不是。
MVCC解决的是读—写/写—读中“ 比较纯粹的读 ”遇到的一致性问题,原谅我,这是我自己编的词儿。那什么是不纯粹的?拿存款业务举个例子。
假设陀螺要存一笔钱,系统需要先把陀螺的余额读出来,然后在余额的基础上加上本次存款的金额,最后再写入到数据库中。在将余额读出来之后,如果不想让其他事务继续访问该余额,直到整个存款事务完成之后,其他事务才可以对该余额继续进行操作,这种情况下就必须为余额的读取操作添加锁。
再总结一下: MVCC是MySQL默认的解决读—写/写—读下一致性问题的方式,不需要加锁。而锁是实现一致性的最终兜底方案,在某些特殊场景下,锁的使用不可避免 。
说得更准确一点,MVCC是MySQL在
READ COMMITTED、REPEATABLE READ这两种隔离级别之下执行普通SELECT操作时默认解决一致性问题的方式。具体为什么只是这两种隔离级别,建议你看看事务的隔离性与MVCC。
2.5. 锁与事务的关系
事务是多个操作的集合,比如我们可以把「把大象装冰箱」这件事情作为一个事务。

事务有A(原子性)、C(一致性)、I(隔离性)、D(持久性)4大特性,而锁就是实现隔离性的其中一种方案(比如还有MVCC等方案)。
事务的隔离性针对不同场景需求又实现了不同的隔离级别,不同的隔离级别下,事务使用锁的方式又会有所不同。举个例子。
在READ COMMITTED、REPEATABLE READ这两种隔离级别之下,SELECT操作是不需要加锁的,直接使用MVCC机制即可满足当前隔离级别的需求。但是在SERIALIZABLE隔离级别,并且在禁用自动提交时(autocommit=0),MySQL会将普通的SELECT语句转化为SELECT ... LOCK IN SHARE MODE这样的加锁语句,如果你看不懂这句话也没关系,你只需要知道MySQL自动加锁了就行,更详细的下文再说。
另外,一个事务可能会加很多个锁,但是某个锁一定只属于一个事务。这就好比一个管理员可以管理多个保险柜,一个保险柜一定只被一个管理员管理。
3. 写—写情况
写—写的情况下肯定要加锁的了,所以接下来终于要聊一聊锁了。
我们首先研究一下锁住的东西的大小,也就是锁的粒度。
4. 锁的粒度
举一个非常应景的例子。疫情防控的时候,是封锁整个小区还是封锁某栋楼的某个单元,这完全是两种概念。
对应到MySQL锁的粒度,那就是表锁和行锁。
很容易想到,封锁小区的行为远比封锁某栋楼某单元的行为粗旷,因此,
从锁定粒度上来看,表锁 > 行锁
直接堵住小区的门口要比进入小区找到具体某栋楼的某个单元要快不少,因此,
从加锁效率上来看,表锁 > 行锁
直接锁住小区大概率会影响其他楼居民的正常生活和各种社会活动的开展,而锁住某栋楼某单元顶多影响这一个单元的居民的生活,因此,
从冲突概率来看,表锁 > 行锁
从并发性能来看,表锁 < 行锁
MySQL支持很多存储引擎,而不同的存储引擎对锁的支持也不尽相同。对于MyISAM、MERGE、MEMORY这些存储引擎而言,只支持表锁;而InnoDB存储引擎既支持表锁也支持行锁,下文讨论的所有内容均针对InnoDB存储引擎。
说完锁的粒度,还有一件事情需要我们仔细考虑一下。上文说过,READ COMMITTED、REPEATABLE READ这两种隔离级别之下,SELECT操作默认采用MVCC机制就可以了,压根儿不需要加锁,那么问题来了,万一我就是想加锁呢?
你可能会说,“简单啊,那就加锁!把数据锁死!除了我谁也别动!”
很好,但是对于大部分读—读而言,由于不会出现读一致性问题,所以不让其他事务进行读操作并不合理。
你可能又说,“那行吧,那就让读操作加锁的时候允许其他事务对锁住的数据进行读操作,但是不允许写操作。”
嗯,想得确实更细致了一些。但是再想想我上文中举过的陀螺存钱的例子,有时候SELECT操作需要独占数据,其他事务既不能读,更不能写。
我们把这种共享和排他的性质称为锁的基本模式。
5. 锁的基本模式
5.1. 共享锁
共享锁(Shared Lock),简称S锁,可以同时被多个事务共享,也就是说,如果一个事务给某个数据资源添加了S锁,其他事务也被允许获取该数据资源的S锁。
由于S锁通常被用于读取数据,因此也被称为 读锁 。
那怎么给数据添加S锁呢?
我们可以用 SELECT ... LOCK IN SHARE MODE;的方式,在读取数据之前就为数据添加一把S锁。如果当前事务执行了该语句,那么会为读取到的记录添加S锁,同时其他事务也可以使用SELECT ... LOCK IN SHARE MODE;方式继续获取这些数据的S锁。
我们通过以下的例子验证一下S锁是否可以重复获取。

5.2. 排他锁
排他锁(Exclusive Lock),简称X锁。只要一个事务获取了某数据资源的X锁,其他的事务就不能再获取该数据的X锁和S锁。
由于X锁通常被用于修改数据,因此也被称为 写锁 。
X锁的添加方式有两种,
- 自动添加
X锁
我们对记录进行增删改时,通常情况下会自动对其添加X锁。 - 手动加锁
我们可以用SELECT ... FOR UPDATE;的方式,在读取数据之前就为数据添加一把X锁。如果当前事务执行了该语句,那么会为读取到的记录添加X锁,这样既不允许其他事务获取这些记录的S锁,也不允许获取这些记录的X锁。
我们用下面的例子验证一下X锁的排他性。

通常情况下,事务提交或结束事务时,锁会被释放。
-
基于MySQL的锁机制2023-09-30 1698
-
请问DSPflash锁死后,RAM还可以用吗,还是这块芯片就彻底废了?2018-06-13 3469
-
一文读懂eMMC究竟是啥?2021-06-18 4097
-
详细介绍MySQL InnoDB存储引擎各种不同类型的锁2019-02-20 8375
-
彻底搞懂PID到底是啥2020-11-13 27151
-
说说MySQL有哪些锁2022-10-24 1455
-
MySQL是怎么加行级锁的?有什么规则?2022-11-17 1613
-
一文彻底搞懂MySQL锁究竟锁的啥22023-03-03 1162
全部0条评论

快来发表一下你的评论吧 !
