

你会从哪些维度进行MySQL性能优化?1
电子说
描述
你会从哪些维度进行MySQL性能优化?你会怎么回答?
所谓的性能优化,一般针对的是MySQL查询的优化。既然是优化查询,我们自然要先知道查询操作要经过哪些环节,然后思考可以在哪些环节进行优化。
下面从5个角度介绍一下MySQL优化的一些策略。
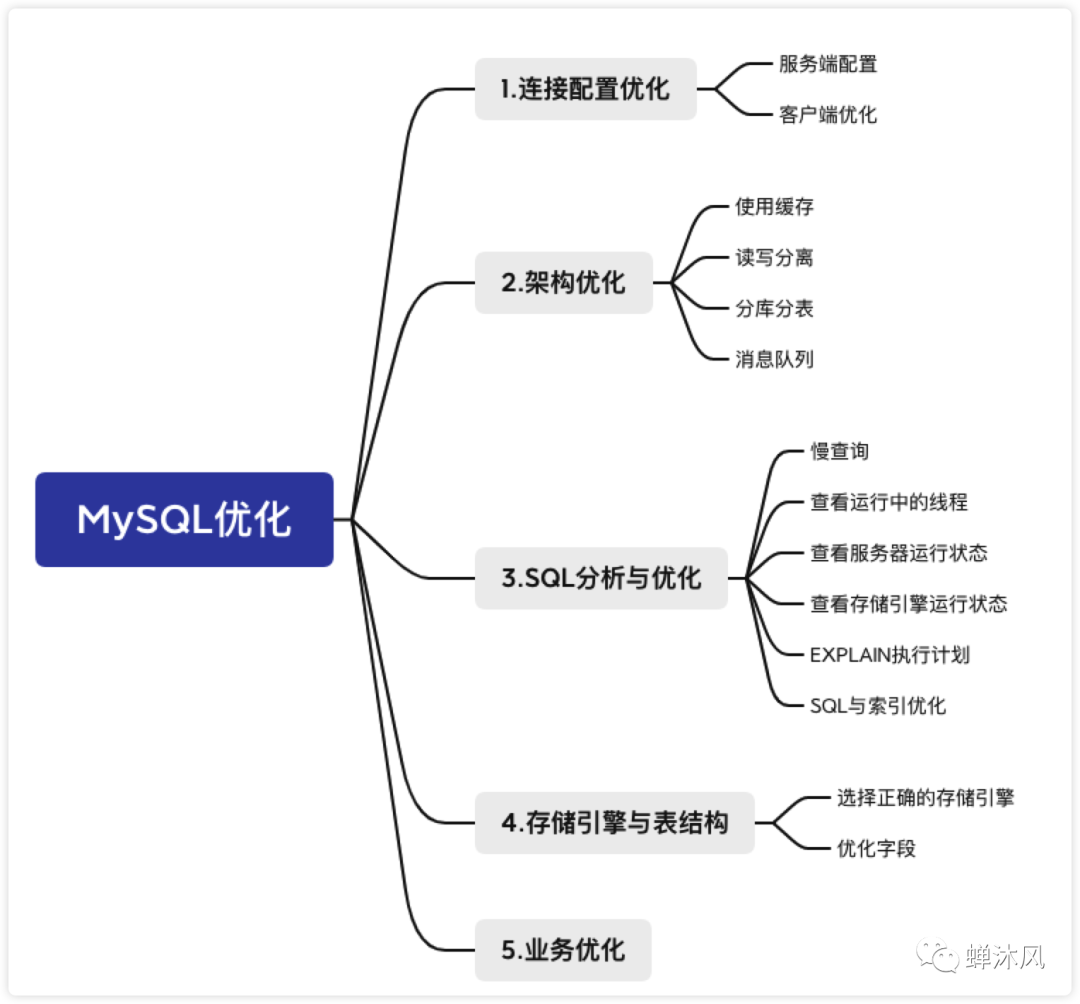
image-20220405204100602
1. 连接配置优化
处理连接是MySQL客户端和MySQL服务端亲热的第一步,第一步都迈不好,也就别谈后来的故事了。
既然连接是双方的事情,我们自然从服务端和客户端两个方面来进行优化喽。
1.1 服务端配置
服务端需要做的就是尽可能地多接受客户端的连接,或许你遇到过error 1040: Too many connections的错误?就是服务端的胸怀不够宽广导致的,格局太小!
我们可以从两个方面解决连接数不够的问题:
- 增加可用连接数,修改环境变量
max_connections,默认情况下服务端的最大连接数为151个
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
1 row in set (0.01 sec)
- 及时释放不活动的连接,系统默认的客户端超时时间是28800秒(8小时),我们可以把这个值调小一点
mysql> show variables like 'wait_timeout';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set (0.01 sec)
MySQL有非常多的配置参数,并且大部分参数都提供了默认值,默认值是MySQL作者经过精心设计的,完全可以满足大部分情况的需求,不建议在不清楚参数含义的情况下贸然修改。
1.2 客户端优化
客户端能做的就是尽量减少和服务端建立连接的次数,已经建立的连接能凑合用就凑合用,别每次执行个SQL语句都创建个新连接,服务端和客户端的资源都吃不消啊。
解决的方案就是使用连接池来复用连接。
常见的数据库连接池有DBCP、C3P0、阿里的Druid、Hikari,前两者用得很少了,后两者目前如日中天。
但是需要注意的是连接池并不是越大越好,比如Druid的默认最大连接池大小是8,Hikari默认最大连接池大小是10,盲目地加大连接池的大小,系统执行效率反而有可能降低。为什么?
对于每一个连接,服务端会创建一个单独的线程去处理,连接数越多,服务端创建的线程自然也就越多。而线程数超过CPU个数的情况下,CPU势必要通过分配时间片的方式进行线程的上下文切换,频繁的上下文切换会造成很大的性能开销。
Hikari官方给出了一个PostgreSQL数据库连接池大小的建议值公式,CPU核心数*2+1。假设服务器的CPU核心数是4,把连接池设置成9就可以了。这种公式在一定程度上对其他数据库也是适用的,大家面试的时候可以吹一吹。
2. 架构优化
2.1 使用缓存
系统中难免会出现一些比较慢的查询,这些查询要么是数据量大,要么是查询复杂(关联的表多或者是计算复杂),使得查询会长时间占用连接。
如果这种数据的实效性不是特别强(不是每时每刻都会变化,例如每日报表),我们可以把此类数据放入缓存系统中,在数据的缓存有效期内,直接从缓存系统中获取数据,这样就可以减轻数据库的压力并提升查询效率。

缓存的使用
2.2 读写分离(集群、主从复制)
项目的初期,数据库通常都是运行在一台服务器上的,用户的所有读写请求会直接作用到这台数据库服务器,单台服务器承担的并发量毕竟是有限的。
针对这个问题,我们可以同时使用多台数据库服务器,将其中一台设置为为小组长,称之为master节点,其余节点作为组员,叫做slave。用户写数据只往master节点写,而读的请求分摊到各个slave节点上。这个方案叫做 读写分离 。给组长加上组员组成的小团体起个名字,叫 集群 。

这就是集群
注:很多开发者不满
master-slave这种具有侵犯性的词汇(因为他们认为会联想到种族歧视、黑人奴隶等),所以发起了一项更名运动。受此影响MySQL也会逐渐停用
master、slave等术语,转而用source和replica替代,大家碰到的时候明白即可。
使用集群必然面临一个问题,就是多个节点之间怎么保持数据的一致性。毕竟写请求只往master节点上发送了,只有master节点的数据是最新数据,怎么把对master节点的写操作也同步到各个slave节点上呢?
主从复制技术来了!我在一条SQL更新语句是如何执行的?中粗浅地介绍了一下binlog日志,我直接搬过来了。
binlog是实现MySQL主从复制功能的核心组件。master节点会将所有的写操作记录到binlog中,slave节点会有专门的I/O线程读取master节点的binlog,将写操作同步到当前所在的slave节点。

主从复制
这种集群的架构对减轻主数据库服务器的压力有非常好的效果,但是随着业务数据越来越多,如果某张表的数据量急剧增加,单表的查询性能就会大幅下降,而这个问题是读写分离也无法解决的,毕竟所有节点存放的是一模一样的数据啊,单表查询性能差,说的自然也是所有节点性能都差。
这时我们可以把单个节点的数据分散到多个节点上进行存储,这就是 分库分表 。
2.3 分库分表
分库分表中的节点的含义比较宽泛,要是把数据库作为节点,那就是分库;如果把单张表作为节点,那就是分表。
大家都知道分库分表分成垂直分库、垂直分表、水平分库和水平分表,但是每次都记不住这些概念,我就给大家详细说一说,帮助大家理解。
2.3.1 垂直分库

垂直分库
在单体数据库的基础上垂直切几刀,按照业务逻辑拆分成不同的数据库,这就是垂直分库啦。

垂直分库
2.3.2 垂直分表

垂直分表
垂直分表就是在单表的基础上垂直切一刀(或几刀),将一个表的多个字短拆成若干个小表,这种操作需要根据具体业务来进行判断,通常会把经常使用的字段(热字段)分成一个表,不经常使用或者不立即使用的字段(冷字段)分成一个表,提升查询速度。

垂直分表
拿上图举例:通常情况下商品的详情信息都比较长,而且查看商品列表时往往不需要立即展示商品详情(一般都是点击详情按钮才会进行显示),而是会将商品更重要的信息(价格等)展示出来,按照这个业务逻辑,我们将原来的商品表做了垂直分表。
2.3.3 水平分表
把单张表的数据按照一定的规则(行话叫分片规则)保存到多个数据表上,横着给数据表来一刀(或几刀),就是水平分表了。

水平分表

水平分表
2.3.4 水平分库
水平分库就是对单个数据库水平切一刀,往往伴随着水平分表。

水平分库

水平分库
2.3.5 总结
水平分,主要是为了解决存储的瓶颈;垂直分,主要是为了减轻并发压力。
2.4 消息队列削峰
通常情况下,用户的请求会直接访问数据库,如果同一时刻在线用户数量非常庞大,极有可能压垮数据库(参考明星出轨或公布恋情时微博的状态)。
这种情况下可以通过使用消息队列降低数据库的压力,不管同时有多少个用户请求,先存入消息队列,然后系统有条不紊地从消息队列中消费请求。

队列削峰
-
系统讲解MySQL数据库慢查询优化思路2026-05-30 162
-
MySQL 8.0性能优化实战指南2025-07-24 1281
-
MySQL执行过程:如何进行sql 优化2023-12-12 1272
-
MySQL性能优化方法2023-11-22 1698
-
你会从哪些维度进行MySQL性能优化?22023-03-03 1156
-
利用MySQL进行一主一从的主从复制2022-07-28 1818
-
MySQL索引的使用问题2021-01-06 2326
-
MySQL数据库:理解MySQL的性能优化、优化查询2020-07-02 3895
-
MySQL索引使用优化和规范2020-06-15 1553
-
MySQL优化之查询性能优化之查询优化器的局限性与提示2020-06-02 2136
-
mysql的查询优化2020-03-12 1201
-
详解MySQL的查询优化 MySQL逻辑架构分析2018-05-28 5319
-
帮助优化MySQL数据库性能的7个技巧2017-11-30 1014
-
MySql5.6性能优化最佳实践2017-09-08 672
全部0条评论

快来发表一下你的评论吧 !
