

SimANS:简单有效的困惑负样本采样方法
描述
本文介绍了本小组发表于EMNLP2022 Industry Track的论文SimANS,其设计了一简单有效的通用困惑负样本采样方法,在5个数据集上提升了SOTA的稠密检索模型的效果。
论文下载地址:https://arxiv.org/pdf/2210.11773.pdf
论文开源代码:https://github.com/microsoft/SimXNS
前言
在各类检索任务中,为训练好一个高质量的检索模型,往往需要从大量的候选样本集合中采样高质量的负例,配合正例一起进行训练。已有的负采样方法往往采用随机采样策略(Random Sampling)或直接基于该检索模型自身选择Top-K负例(Top-K Hard Negative Sampling),前者易得到过于简单的样例,无法为模型训练提供足够信息;后者很可能采样得到假负例(False Negative),反而干扰模型训练。本文针对稠密检索场景,通过一系列基于负例梯度的实验对随机采样和Top-K采样两种方式导致的问题进行分析,发现前一种负例产生的梯度均值较小、后一种负例产生的梯度方差较大,这两者都不利于检索模型训练。此外,以上实验还发现,在所有负例候选中,与Query的语义相似度接近于正例的负例可以同时具有较大的梯度均值和较小的梯度方差,是更加高质量的困惑负样本。因此我们设计了一个简单的困惑负样本采样方法SimANS,在4个篇章和文档检索数据集,以及Bing真实数据集上均成功提升了SOTA模型的效果,且该方法已经应用于Bing搜索系统。
一、研究背景与动机
1、稠密检索
给出用户的查询Query,检索任务关注于从大量的候选文档集中检索最相关的Top-K文档。随着近年来文本表示方法的发展,稠密检索任务开始成为该任务的主流方法,其通常采用一双塔模型架构,分别将查询Query和候选Document转换成低维的稠密表示,然后基于Query和Document稠密表示的点积来预测两者的语义相关性,并依此进行候选文档的排序。这一计算方式支持ANN等方法加速,故可以推广到千万级别文档的查询。
近年来,由于预训练语言模型的出现,已有的稠密检索方法往往采用预训练语言模型作为Query和Document的Encoder,然后将其编码后生成的[CLS]表示作为其稠密表示。
2、负采样方法
为训练该稠密检索模型,已有方法通常基于一对比学习训练目标,即拉近语义一致的Query和Document的表示(Positive),并推远语义无关的Document(Negative)。由于在大量的候选文档集中,大量的文档都是语义无关的,故需要采用一合适的负采样方法,从中选择高质量的负例来进行训练,依此减少需要的负样本数量。
2.1.随机负采样
该类方法直接基于一均匀分布从所有的候选Document中随机抽取Document作为负例,这一过程中由于无法保证采样得到的负例的质量,故经常会采样得到过于简单的负例,其不仅无法给模型带来有用信息,还可能导致模型过拟合,进而无法区分某些较难的负例样本。
2.2.Top-K负采样
该类方法往往基于一稠密检索模型对所有候选Document与Query计算匹配分数,然后直接选择其中Top-K的候选Document作为负例。该方法虽然可以保证采样得到的负例是模型未能较好区分的较难负例,但是其很可能将潜在的正例也误判为负例,即假负例(False Negative)。如果训练模型去将该部分假负例与正例区分开来,反而会导致模型无法准确衡量Query-Document的语义相似度。
二、先导实验
1、理论分析不同负例训练时对梯度的影响
以稠密检索常用的BCE loss为例,正例与采样的负例在计算完语义相似度分数后,均会被softmax归一化,之后计算得到的梯度如下所示:
上式中是经过softmax归一化后的语义相似度分数。对于随机采样方法,由于其采样得到的负例往往过于简单,其会导致该分数接近于零,,进而导致其生成的梯度均值也接近于零,,这样过于小的梯度均值会导致模型不易于收敛。对于Top-K采样方法,由于其很容易采样得到语义与正例一致的假负例,其会导致正负样本的右项值相似,但是左项符号相反,这样会导致计算得到的梯度方差很大,同样导致模型训练不稳定。
2、实验验证不同负例的梯度与语义相似度关系
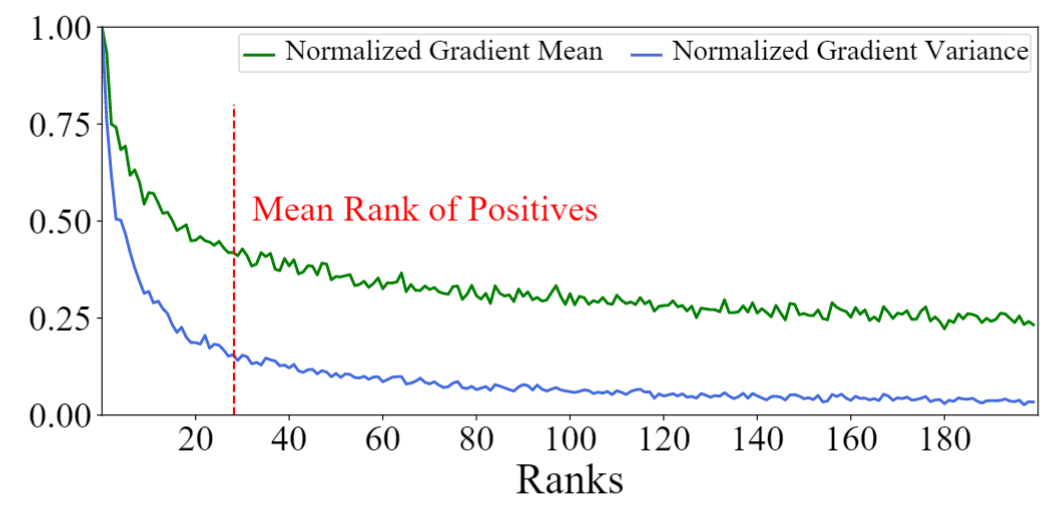
我们基于SOTA的稠密检索模型AR2,在MS-MARCO数据集上,首先计算候选Document与Query的语义相似度分数,然后将这些Document进行排序,并计算其梯度的均值与方差。如下图所示,我们可以看到实验结论与以上分析一致,排名靠前的Top-K负例产生的梯度均值和方差均很大;而排名靠后的负例产生的均值和方差均很小,两者不能很好的平衡大均值和小方差这两个很重要的负例性质。作为对比的是,与正例语义相似度接近的负例往往能够同时取得较大的梯度均值和较小的梯度方差,有利于模型训练。我们将其命名为困惑样本(既不过于难又不过于容易区分),并关注于对其进行采样。
三、SimANS:简单的困惑样本采样方法
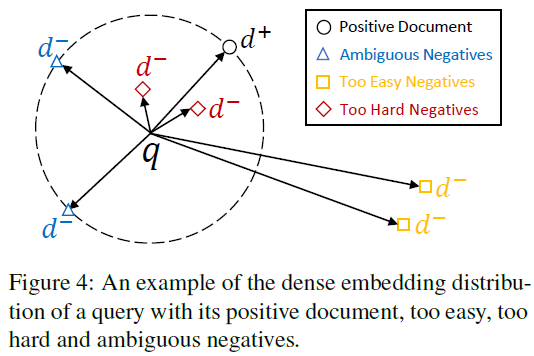
基于上述实验,我们考虑对与正例语义相似度接近的困惑负例样本进行采样。故设计的采样方法应该具有以下特点:(1)与Query无关的Document应被赋予较低的相关分数,因其可提供的信息量不足;(2)与Query很可能相关的Document应被赋予较低的相关分数,因其可能是假负例;(3)与正例语义相似度接近的Document应该被赋予较高的相关分数,因其既需要被学习,同时是假负例的概率相对较低。
困惑样本采样分布
通过以上分析可得,在该采样分布中,随着Query与候选Document相关分数和与正例的相关分数的差值的缩小,该候选Document被采样作为负例的概率应该逐渐增大,故可将该差值作为输入,配合任意一单调递减函数即可实现(如)。故可设计采样分布如下所示:
其中为控制该分布密度的超参数,为控制该分布极值点的超参数,是一随机采样的正例样本,是Top-K的负例。通过调节K的大小,我们可以控制该采样分布的计算开销。以下为该采样方法具体实现的伪代码:

四、实验结果
1、主实验
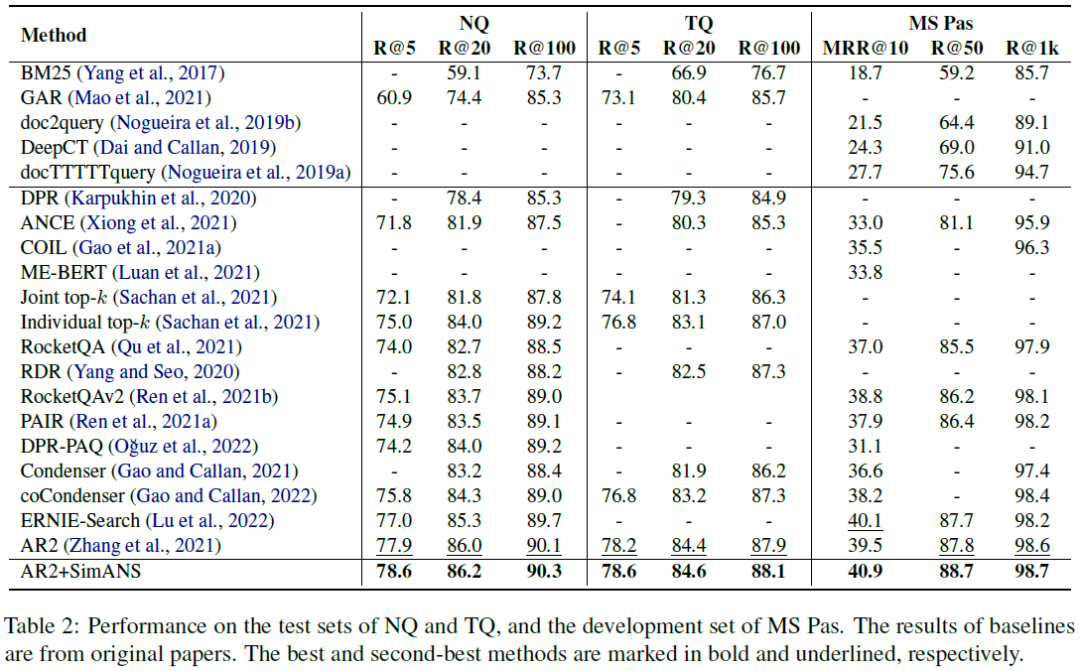
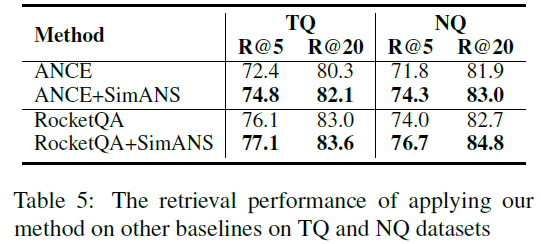
我们在4个公开的文档检索数据集上进行实验,分别是Natural Question(NQ)、Trivia QA(TQ)、MS-MARCO Passage Ranking(MS-Pas)和MS-MARCO Document Ranking(MS-Doc)数据集;同时还在Bing真实工业数据集上进行实验,实验结果如下表所示。通过对比可以清晰地看出我们的方法可以提升SOTA的AR2模型的效果,进一步领先其他模型。
2、该负采样方法的通用性
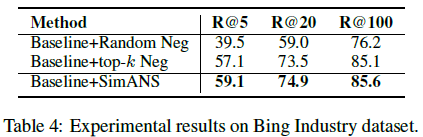
我们还在RocketQA和ANCE这两个经典的稠密检索模型上实现了我们提出的SimANS方法,来提升这些模型的性能。可以看出,在采用该方法之后,以上两个模型的的表现都超过了原始模型,证明了我们提出的方法的通用性。
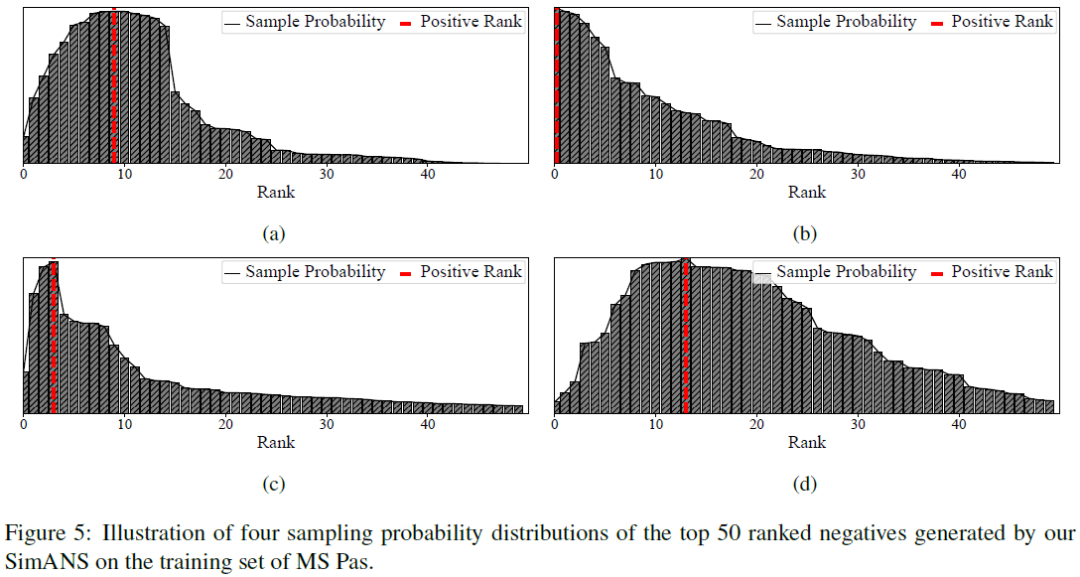
3、负采样分布的可视化
在实验的最后,我们将SimANS得到的采样分布制作成图,可以看到我们的采样分布函数确实能够惩罚过于难和过于简单的负例,并保证与正例的语义相似度接近的负例的采样概率较大。实现了我们的设计初衷。
审核编辑 :李倩
-
机器学习的5种采样方法介绍2020-05-17 6238
-
PCB接地设计宝典4:采样时钟考量和混合信号接地的困惑根源2014-11-20 15119
-
怎么使用UART向PC发送数字样本2019-04-28 1534
-
一种先分割后分类的两阶段同步端到端缺陷检测方法2020-07-24 3421
-
有什么简单可行的方法可以实现负压输出呢2021-11-03 2581
-
测量功率二极管的反向恢复时间简单有效方法2009-11-11 1317
-
什么是采样频率?什么叫采样频率2009-05-04 22410
-
入侵检测样本数据优化方法2018-02-26 1108
-
经典的采样方法有哪些?2018-07-09 14523
-
基于构造性覆盖算法的过采样技术CMOTE2021-04-12 1554
-
一种从患者血液样本中有效分离异质性CTCs的简单、广谱的方法2021-06-11 3429
-
基于有效样本的类别不平衡损失2021-08-16 2637
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3282
-
双塔模型扩量负样本的方法比较2022-07-08 2184
-
基于有效样本数的类平衡损失2022-08-25 2128
全部0条评论

快来发表一下你的评论吧 !
