

一文了解多个段的相关程序
描述
这是 x86 汇编连载系列第七篇文章,前六篇文章见文末。
上回我们简单认识了一下什么是段,段前缀和一段安全的段空间是哪里,但是程序中不会仅有一个段,复杂程序必然是包含多个段的,这篇文章我们就来了解下多个段的相关程序。
内存地址空间是由操作系统直接管理和分配的,一般操作系统分配空间有两种方式:
程序由磁盘载入内存中时,会由操作系统直接为程序分配其运行所需要的内存空间。
程序在运行时可以动态向操作系统申请分配内存空间。
如果想要在程序被载入时获得内存空间分配,我们就需要在源程序中对其进行声明,通过定义多个段的方式来申请内存空间。这样的好处是能够保证段内的数据连续,而且对于我们来说也能够清晰明白的看懂程序逻辑,所以我们一般采用定义多个段的方式编写程序。
在代码段 cs 中使用数据
现在考虑这样一个问题,如何累加下面这几个数据的和,并把它放在一个 ax 寄存器中呢?
0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
我们当然可以通过一个数据接一个数据这样进行累加,并把每次累加的结果都用 ax 进行存储,简单一点的方式是通过循环的方式累加,一共需要累加 8 次数据,用 ax 存储。但是现在就有一个问题,这 8 个数据应该放在哪呢?我们之前学的累加做法都是把他们放在一组连续的内存单元,这样我们就可以累加内存中的数据来把它们进行累加了,但是如何把这些数据放在一个连续的内容单元中呢?这段内存单元又是从哪找呢?
我们可以不用自己找内存单元,直接让操作系统分配,我们只需要定义这些数据并把它们放在一个连续的内存单元即可,具体该怎么做呢?请看下面代码
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h mov ax,0 mov bx,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end
上面汇编代码中出现了之前我们没有学过的 dw,dw 的含义是定义字型数据,dw 的全称就是 define word,上面代码使用 dw 定义了 8 个字型数据,它们所占用的空间为 16 个字节。
定义了数据之后,我们就需要对这 8 个数据进行累加,我们该如何找到这 8 个数据呢?
仔细观察上面代码,我们可以知道这 8 个数据在代码段 cs 中,所以我们可以通过 cs 来找到这几个数据,所以 cs 是段地址,而偏移地址是用 ip 表示的,也就是说这 8 个数据的偏移地址分别是 cs:0 cs:2 cs:4 cs:6 cs:8 cs:a cs:c cs:e 。
我们将上面这段代码编写、编译和链接后,对其 exe 文件进行 debug :

??????等下,这个 and ax,[bx+di] 是什么东西?再看下 cs:ip 的地址,是初始地址没错啊,为啥没看到程序中的指令呢?我们再用 debug -u 看看
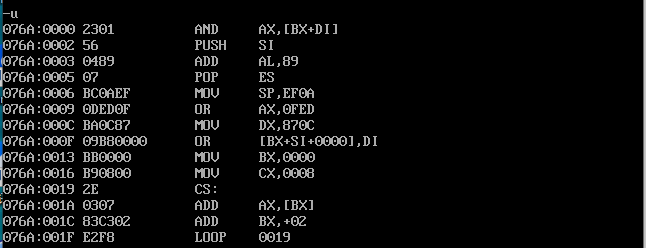
这前几条指令都是什么东西?怎么 mov bx,0000 在偏移地址 0013 处?
从上图中我们可以看到,程序被加载入内存之后,所占内存空间的前 16 个单元存放在源程序中用 dw 定义的数据,后面的单元存放源程序中汇编指令所对应的机器指令。
那么如何执行汇编指令所定义的机器指令呢?你可以直接 -t 慢慢的执行到 mov bx,0 处,也可以改变 ip 寄存器的值,也就是 ip = 10h,从而使 cs:ip 指向程序的第一条指令。
这两种方式看起来哪个都有一定的局限性,那么还有没有更简洁一点的方式呢?
看下面这段代码
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h start: mov ax,0 mov bx,0 mov cx,8 s: add ax,cs:[bx] add bx,2 loop s mov ax,4c00h int 21h code ends end start
仔细看这段代码,和上面那段代码有什么区别?
只有两个区别,一是在 mov ax,0 前面加了一个 start: 标志,并且在 end 后加了一个 start 标志,这两个标志分别指向程序的开始处和结束处。
那么问题来了,为什么你加一个 start: 标志就说这是程序的开始处,我随便加个比如 begin: ,能不能成为程序的开始处呢?
assume cs:code code segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h begin: ...... code ends end begin
经过我的实验验证是可以的,为什么呢?
关键点并不在于你定义的是什么标志,而在于最后的 end,end 除了能够告诉编译器程序结束的位置外,还能够告知编译器程序是从哪里开始的,在上面代码中我们用 start: 和 end start 告诉程序从 start 处开始,并执行到 end start 处结束,而 mov ax,0 是程序的第一条指令。
程序开始标志 start: 和 IP
我们知道,CS 和 IP 这两个寄存器能够指明程序的开始处和程序执行的偏移地址,而且 start: 标号指明了程序开始的地方,那么 start: 标号所指向的偏移地址是不是我们之前讨论的 10h 处呢?

我们编译链接执行程序看一下。
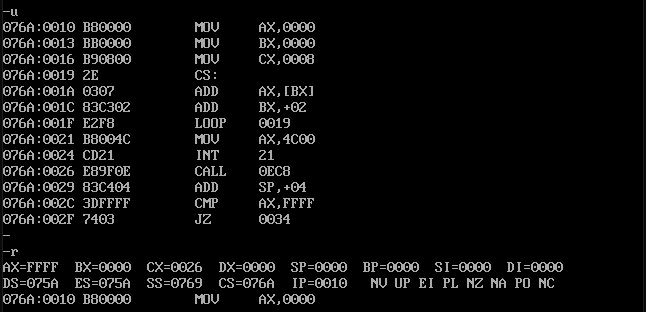
我们通过 -u 和 -r 分别执行了一下,可以看到,程序的起始地址都是 076A:0010 ,这也就是说,除了我们 dw 定义的几条数据外,IP 指向的偏移地址 0010 就是程序的开始处。
所以有了这种方法,我们就可以这样安排程序框架:
assume cs:code code segment ...数据 start: ... 代码 code ends end start
在代码段 cs 中使用栈
除了在 cs 代码段中定义数据,还可以在 cs 代码段中定义栈,比如下面这个需求:
利用栈将程序定义的数据逆序存放,源代码如下
assume cs:codesg codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ...... codesg ends end
如何实现将数据逆序存放呢?可以这么思考:
先定义一段和数据相同大小的栈空间,然后把数据入栈,然后再依次出栈就能够实现逆序存放了,因为栈是后入先出的数据结构,最开始 push 进去的最后 pop 。
代码如下:
assume cs:codesg codesg segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 start:mov ax,cs mov ss,ax mov sp,30h mov bx,0 mov cx,8 s0:push cs:[bx] add bx,2 loop s mov bx,0 mov cx,8 s1:pop cs:[bx] add bx,2 loop s1 mov ax,4c00h int 21h codesg ends end start
解释下上面这段代码:
首先先定义了 16 个值为 0 的字型数据,程序被载入内存后,操作系统会为程序分配 16 个字型数据空间,用于存放 16 个数据,把这段空间当做栈来使用。
start 标号处开始程序,首先先要设置一段空间为栈段,由于我们只有一个 cs 段,所以程序是从 cs 段开始的,刚开始 dw 的 8 个数据所需的地址空间为 cs:0 ~ cs:f,后面 dw 定义的 16 个字所需的地址空间是 cs:10 ~ cs:2f ,由于 ss:sp 这两个寄存器始终指向栈顶,目前还没有数据入栈,所以栈顶必须为 2f + 1 ,也就是 30h 才可。
编译链接执行后的栈段如下图所示
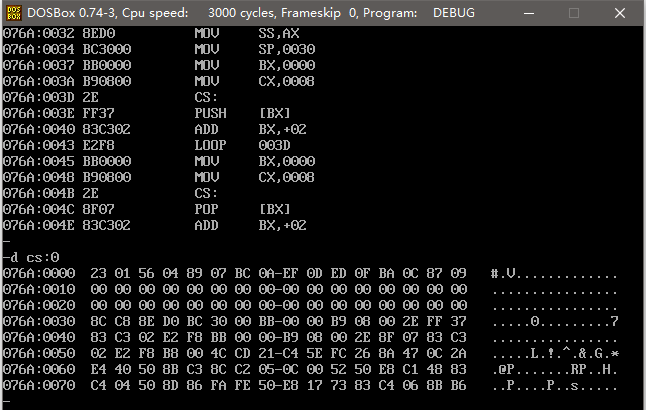
这是程序被载入后的内存分配情况,可以看到,cs:0 ~ cs:f 存储的是 8 个字型数据,cs:10 ~ cs:2f 存储的是 16 个字型 0 数据。
程序执行完成后的内存分配图如下,可以看到已经实现了数据的逆序存放。
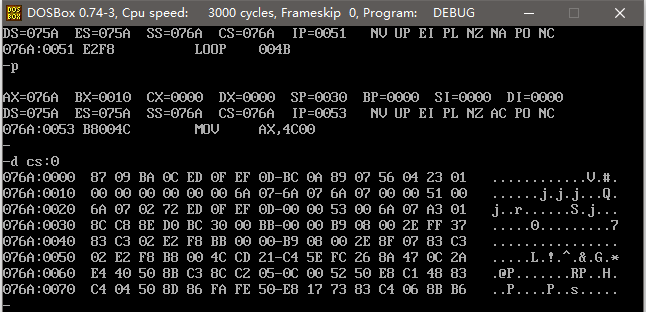
可见,我们定义这些数据的最终目的,是通过它们取得一定容量的内存空间,所以我们在描述 dw 的作用时,可以说用它来定义数据,也可以说用它来开辟一段内存空间。比如上面的 dw 0123h ... 0987h ,可以说定义了 8 个字型数据,也可以说开辟了 8 个内存空间,它们的效果是一样的。
多个段的使用
上面讨论的内容都是将数据和栈放入一个段中,这样做虽然比较省事,但是程序逻辑不够清晰,像个大杂烩一样,而且都放入一个段中,这个段的内存有可能不够用(8086 CPU 中一个段最大不能超过 64 KB)。
为了能够清晰说明程序逻辑,并且能够容纳数据和栈,我们一般使用多个段的方式分别将数据、代码和栈分别放入各自的段中。
比如我们通过多个段的方式将上面实现逆序存放的程序进行改写,代码如下
assume cs:codesg,ds:data,ss:stack data segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h data ends stack segment dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 stack ends code segment start: mov ax,stack mov ss,ax mov sp,20h mov ax,data mov ds,ax mov bx,0 mov cx,8 s0: push [bx] add bx,2 loop s0 mov bx,0 mov cx,8 s1: pop [bx] add bx,2 loop s1 mov ax,4c00h int 21h code ends end start
如上代码所示,在 assume 后面定义了三个段,这些都是伪指令,只是为了方便说明段的类型。然后分别在 data segment 和 stack segment 定义了相关数据,最后再 code segment 编写的程序代码。
基本上代码和在一个段中的定义是一样的,值得说明是,同一个段中的 ss:sp 指向的是 ss:30 ,而在这段代码中的 ss:sp 指向的是 ss:20 ,这个大家知道是怎么回事吧?由于数据会直接定义在 data segment 中,所以栈段的 16 个字型数据占用的空间就是 ss:0 ~ ss:1f,所以 ss:sp 指向 20h 处。
其实,代码段、数据段、栈段完全是我们自己定义的,但是并不是我们分别定义了 cs:code,ds:data,ss,stack 之后,程序就会把它们分别当做程序段、数据段和栈段的。要知道这些和 assume 一样都是伪指令,它们是由编译器执行的,CPU 并不知道这些指令的存在,所以我们必须要在程序中告诉 CPU 哪个是栈段、哪个是数据段。
该如何告诉 CPU 呢?
我们看下栈段的设置指令
mov ax,stack mov ss,ax mov sp,20h
这样就会将 ss 指向 stack ,ss:sp 用来指向 stack 栈段的栈顶地址,只有在这个指令执行后,CPU 才会把 stack 段当做栈段来使用。
相同的,CPU 如果想访问 data 段中的数据,则可用 ds 指向 data 段,用其他寄存器比如 bx 来存放 data 段中的偏移地址即可。
所以,我们完全可以按照下面这种方式来定义程序
assume cs:a,ds:b,ss:c b segment dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h b ends c segment dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 c ends a segment d: mov ax,c mov ss,ax mov sp,20h mov ax,b mov ds,ax mov bx,0 mov cx,8 s0: push [bx] add bx,2 loop s0 mov bx,0 mov cx,8 s1: pop [bx] add bx,2 loop s1 mov ax,4c00h int 21h code a end d
最终程序的功能和上面的一模一样。
-
一文全面了解linux相关知识2023-01-29 1045
-
一文了解STM32启动过程2023-05-08 3991
-
一文详解PLC子程序与子程序指令2023-12-14 16484
-
一文带你了解步进电机的相关知识2021-07-08 2344
-
一文了解BLDC与PMSM的区别2021-08-30 2420
-
一文了解LVGL的学习路线2021-12-07 3076
-
一文了解SiP封装资料下载2021-04-25 1971
-
一文了解气象观测站是什么?2023-09-12 2555
-
一文了解pcb电路板加急打样流程2023-11-08 7905
-
一文了解 PCB 的有效导热系数2023-11-24 4133
-
一文了解刚柔结合制造过程2023-12-04 2135
-
一文了解单向晶闸管的结构及导电特性2023-12-05 3303
-
一文了解相控阵天线中的真时延2023-12-06 4144
-
一文带你了解 DAC2023-12-07 14088
-
pcb应变测试有多重要?一文了解!2024-02-24 2118
全部0条评论

快来发表一下你的评论吧 !
