

基于专家知识+AI算法的性能调优
电子说
描述
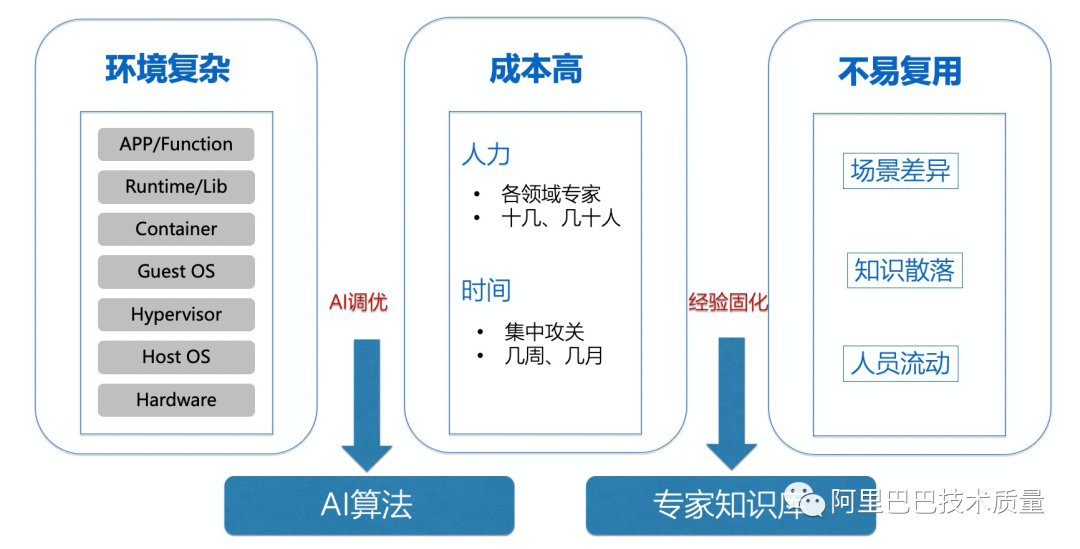
在业务的性能调优中,我们往往会遇到下面三个方面的问题:
1)操作系统的软硬件配置过于繁杂。
无论是应用内核参数、系统服务还是应用配置,都有成百上千的参数,而且参数之间相互,在调优的时候往往存在跷跷板现象,如何管理如此大量的领域知识,是非常困难的事情。
2)人力、时间成本高。
做一次有效的全栈调优,往往需要把多个领域的专家集中起来进行一次1-3个月的集中攻关,在人力和时间成本上是非常大的代价。
3)专家知识难以固化复用。
即使是我们在一个场景上把所有专家集中起来做了一次非常好的攻关,专家知识还是非常难以固化下来并在下个应用扩展使用起来,到了下一次调优场景,还是几乎要重头再来。
针对上述问题我们该如何求解呢?
如果专家知识非常难以固化,那我们为什么不建一个专家知识库平台来把专家知识固化起来呢?
如果我们的配置关系非常复杂,投入时间和人力非常高,那我们为什么不把AI算法引入进来,让人工智能帮我们做一些事情。
在容量评估测试中,我们也会遇到类似的问题:Benchmark的参数众多,哪些参数是需要使用的,哪些其实无关紧要?需要使用的参数,如何设置它的值才能保证给出的压力是足够的,从而不会因为压力不足而无法验证到物理机/系统真实的容量呢?
I 可行的解决途径——KeenTune的缘起
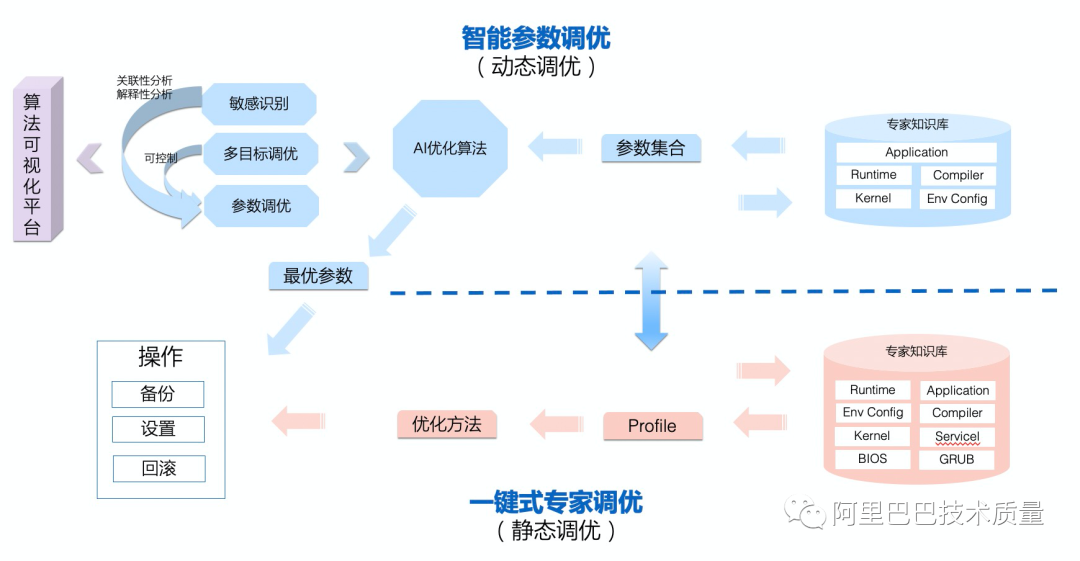
从上个部分中,我们其实可以看出求解的方式,一个是需要专家知识的固化平台,一个是可以考虑引入AI算法来解决人工无法有效探索参数取值空间的问题。这也就是KeenTune的起源,其主要完成两大部分的功能,一方面将人工的经验固化下来,形成能够在业务上一键调优的专家知识库——也就是静态调优;另一方面,在有了需要调优的参数及其取值空间的概要知识的情况下,可以使用AI算法来进行最优取值搜索。
这是KeenTune产品开始研发时最朴素的想法,后面也因为业务的实际需要,引入了参数可解释性方向的算法,来识别出来哪些参数对结果真实有影响,其最优取值范围是什么,从而指导进行人工解释和进一步研究;同时,也引入了高保真方向的算法来规避Benchmark/业务环境的波动对调优效果的准确性带来的影响;另外,也针对“在不增加时延的情况下,提升吞吐量”这样的带控制条件的实际调优需求,引入了多目标调优方向的算法。

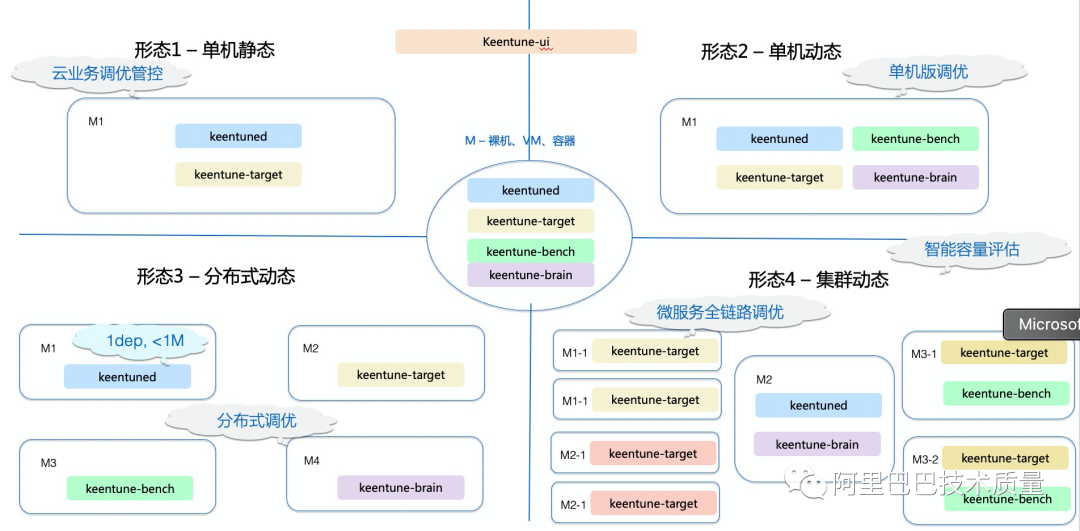
请注意,KeenTune提供的动静态协同调优的能力,可以协助实际业务解决如下问题:
1)POC小集群调优到线上大规模集群调优,比如:POC小集群动态调优完后,调优经验固化成静态调优,直接大规模部署到线上;
2)相似场景的精细化调优,比如:调优过mysql后,使用mysql的固化出的静态专家知识库,转化成动态进行精细化调优。
在算法创新的同时,基于阿里业务自身的特点,KeenTune采用了高度模块化的分布式部署的方式,在业务端只需要部署轻量的agent(keentune-target),管控调度模块keentuned,算法模块keentune-brain,Benchmark管控模块keentune-bench,前端管控与算法可视化模块keentune-ui都是可以部署在网络可连通的其他环境上,因此,对业务的适配度非常高。
一、创新点
KeenTune项目目前已经提交13篇专利,其中9篇已提交专利;另外,还有3篇正在提交流程中。A类论文发表1篇(FSE2022:KeenTune: Inteligent Parameter Interpretability and Tuning Tool for Linux System),1篇在投A类论文。
本章节的各小节中,后续也会简单介绍一下KeenTune的创新点。
I 多领域算法的集成
KeenTune主要使用的算法为Hyper Parameter Tuning方向,目标是在参数空间上寻找最优组合。不过,在实际应用落地中,发现在实际应用中会存在很多问题:
1)在高维空间上,无论是传统的Bayes,还是更新的HORD、EPTE等算法,都无法达到工程需求的快速收敛(比如:100个连续/分散取值的参数,在100轮达成收敛目标),而一般Benchmark的执行时间都会在几分钟甚至几小时,每一轮执行代价都非常大,因此,降低轮次成为首要问题。
2)非单一目标调优,在实际中,往往是“不增加时延的情况下提升吞吐”、“不仅avg_latency降低,还要求99_latency、95_latency都降低” 3)无论是Benchmark还是业务环境,都存在抖动的问题,如何识别出环境抖动并且尽量消除,是个问题。
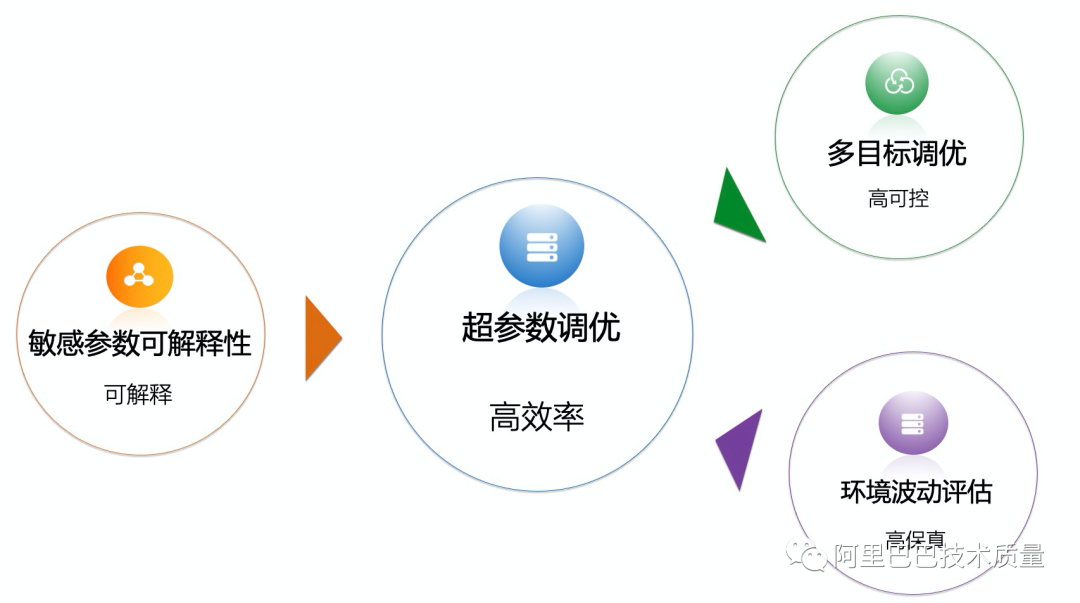
为应对这些问题,KeenTune集成了多个领域的算法来使参数调优在实际工程中能够产生效果:
敏感参数可解释性方向算法:从众多的参数中识别出真正对结果有影响的TOP参数,并且能够给出其最优取值的范围,给出参考。一方面,可以成为参数调优算法的输入,大大降低参数空间,从而实现快速找到优化点的目标。另一方面,也可以为人工提炼专家静态知识库并进行领域分析提供依据。
多目标调优算法:KeenTune自研的带有可控制条件的多目标调优,有效地解决了工程中遇到的各种多个评价指标同时调优,甚至是带有强制限制条件的调优问题。
高保真算法:能够通过评估环境的波动情况,调整每轮运行的次数,从而保证调优效果。另外,结合early stop机制,能够智能化控制实际的运行效率,从而大大提升对于每次调优的收敛效率。
I 自研参数调优算法BGCS
为了实现高效可扩展的参数调优算法,BGCS参考了HORD框架进行了改进,使用CNN/MLP模型取代RBF模型作为代理模型,以提高代理模型预测准确性。
在HORD算法的DYCORS过程中,通过两个变量φ和δ来控制变异的过程,前者控制的是给坐标的某个维度进行变异的概率,后者决定了增加变异的幅度。在调优过程中,φ随着调优的进行递减,而δ根据每一轮是否发现了新的最优参数进行动态调整。
虽然有两个变量干预参数的变异,但HORD算法的参数变异过程整体来说是随机的,在这个过程中会产生大量无意义的参数配置。我们针对这个过程加入性能梯度对参数编译的过程进行指导,避免盲目随机地生成大量参数配置。同时使用梯度对参数维度进行排序,优先针对性能梯度较高的参数进行变异,同时保持性能梯度低参数的取值,降低代理模型预测误差的干扰。
I 自研参数可解释性算法XSen
为了达成算法能够正确的找到真正对结果产生影响的参数,PIA将多种不同的敏感参数领域算法进行融合,根据实际情况使用。下图中列出了PIA的框架,主要是分为analyzer和aggregator。
Analyzer分为mutual information analyzer、linear analyzer、non-linear analyzer三种。Non-linear analyzer分为两种:DNN模型、树形模型,linear analyzer使用线性模型。在工程验证中,高维度non-linear analyzer的准确度更高,但是运行时间较久;linear analyzer运行时间在1s内,不过准确度相对不高。mutual information analyzer捕捉线性和非线性信息,通过信息识别来识别敏感参数。
二、应用实践
I KeenTune在Linux全栈性能调优中的实践
KeenTune不仅在算法层面上实现了对kernel、environment configuration、runtime、compiler、application的多个层级的参数的动态算法调优,还积累了包括多层级的人工经验。目前,在云场景、云原生场景、编译器场景等多个合作项目中达成了调优目标,并且在社区中与统信、中兴、intel等SIG伙伴进行相关共建。
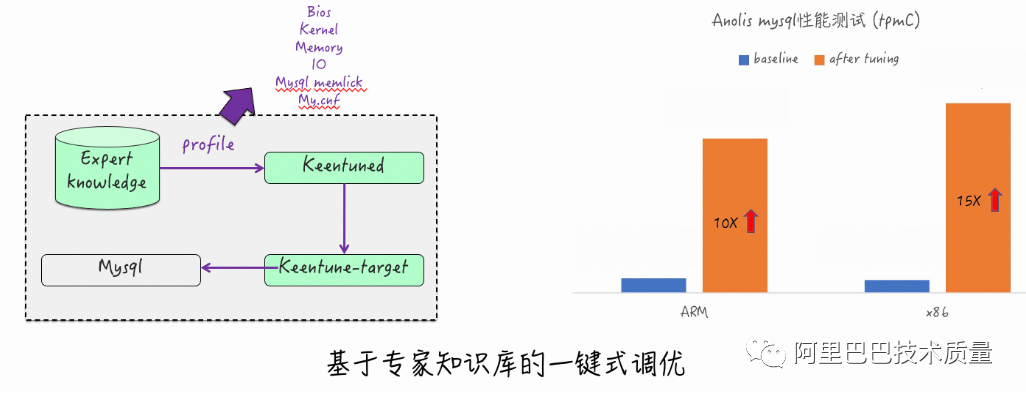
1. 专家一键式调优 –MySQL的竞分打榜
项目背景:
某商业打榜
调优目标:
AnolisOS提供自研性能调优工具能力,主流应用(MySQL)调优能力不低于友商
调优效果:
MySQL的TPCC跑分在一键式专家调优后,相比初始安装性能提升10倍+
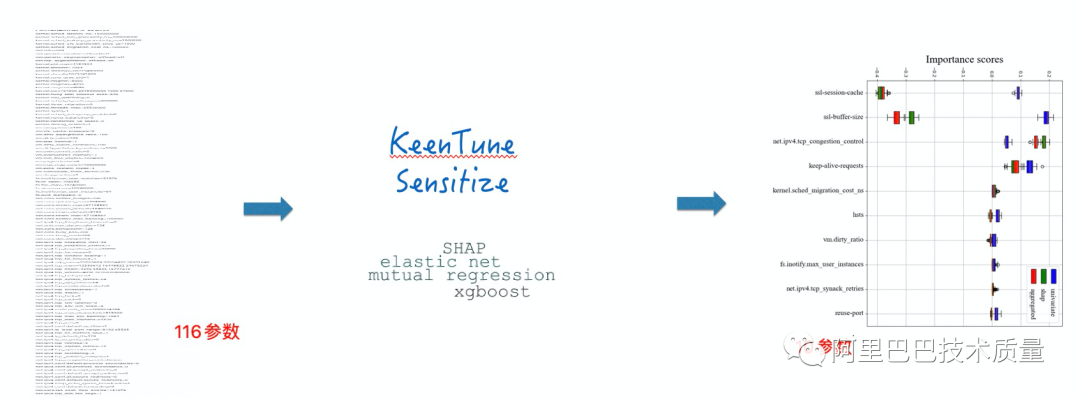
2. 敏感参数识别 –Nginx业务的参数可解释性
项目背景:
调优参数多导致参数空间巨大,进而导致参数调优算法收敛慢(100参数收敛需要2000轮以上)
调优目标:
116个联合参数(内核+ Nginx) 中对结果影响大的参数,目标20个以内
识别效果:
TOP10参数对Nginx吞吐与时延的影响已经超过90%,降维后调优效果和全量保持一致
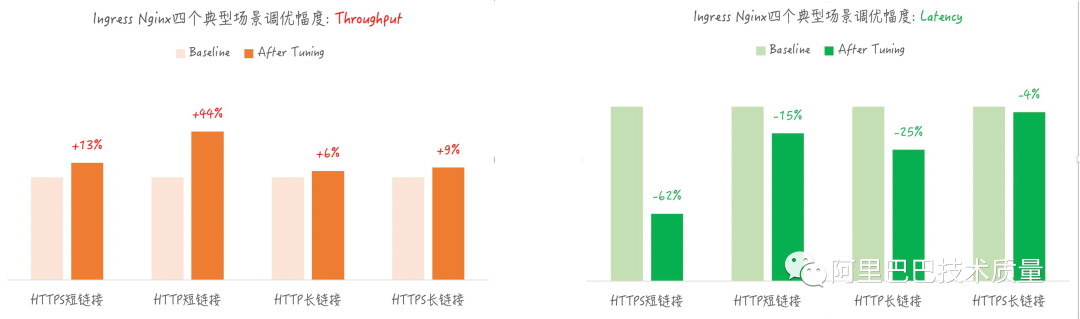
3. 智能参数调优 – 云原生业务Ingress-Nginx的全栈调优
项目背景:
调优参数多导致参数空间巨大,进而导致参数调优算法收敛慢(100参数收敛需要500轮以上)
调优目标:
四个场景完整覆盖:HTTP短链接,HTTP长链接,HTTPs短链接,HTTPs长链接
多领域参数协同调优:Sysctl,Nginx
两个指标统一优化:Throughput提升的同时Latency下降
调优效果:
四个场景均达成了throughput提升的同时latency下降,有些场景最好效果达到40%+
达成内核到应用的全栈调优,取得良好效果
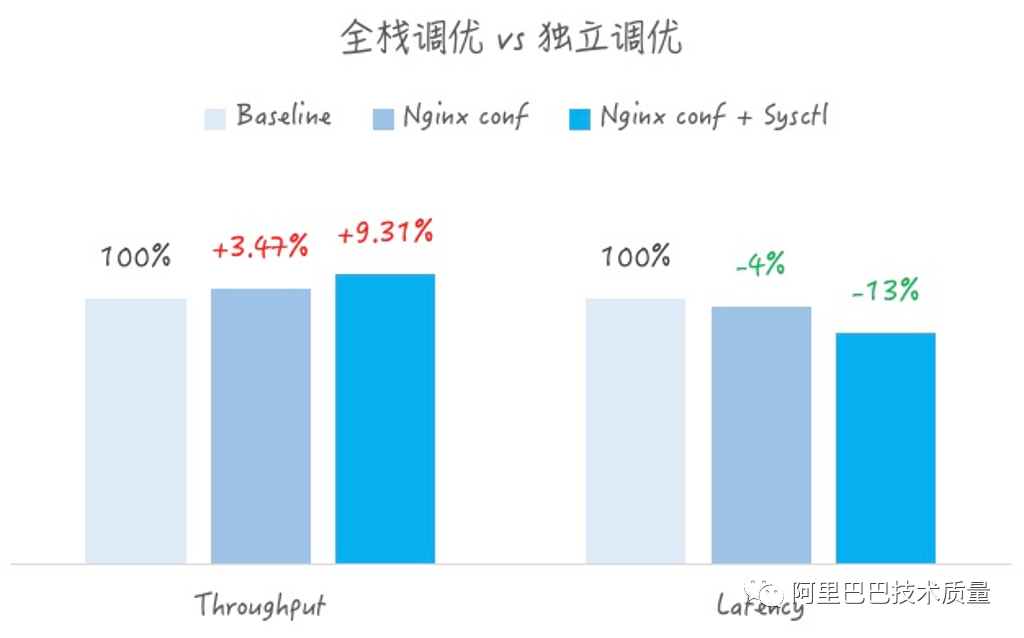
同时,在其中,尤其是长连接的场景,对比了只进行nginx.conf参数调优,与内核+Nginx的全量调优的对比,可以非常明显的看出,多层级的全栈调优效果会比单一层级的调优效果突出。
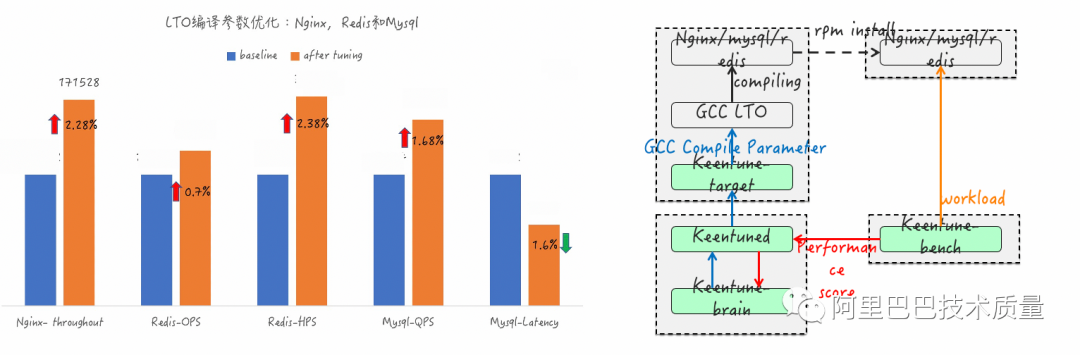
4. 智能参数调优 – 云业务gcc编译参数调优
项目背景:
gcc编译参数对应用性能影响较大,人工定义配置比较困难
调优目标:
对云业务上TOP3的应用进行编译参数优化
调优效果:
TOP3应用的主要指标均达成调优目标(目标1-3%)
I KeenTune在容量评估方向的实践
容量评估一直一直以来的痛点,就是Benchmark工具,大家都知道是什么,怎么用,不过却不一定能够用对。现在集团内的使用方式基本上还是人工定义性能测试用例,用这个结果直接评估是否正确,这就对Benchmark使用人员有着非常高的要求,怎么创建模型,定义Benchmark的各个参数是很有讲究的。
往往存在直接从网上找到使用的命令行方式,修改修改参数,跑出来个结果就开始做分析。可是这样子就会有几个问题:
1)不少Benchmark的参数都非常多,比如:sysbench,那么,哪些参数是我们需要关注并且使用的呢?
2)在不同规格的机器上,都使用相同一套参数的测试用例,是不是不合适?换个说法,是否能够提供足够的压力用来提供容量评估?
3)Benchmark本身的资源消耗怎样?会不会因为参数设置不当,或者环境选用不当,导致Benchmark自己占掉了所有资源而无法给出足够压力?这一点在wrk上非常明显。
为了解决这些问题,KeenTune的参数调优算法登场了,开始在看似不属于自己的领域,进行了一些还挺有效果的实践。
1. 基础Benchmark的压力管控 – iperf3网络带宽测试
项目背景:
在与私有云团队进行容量评估的需求分析时,发现使用人工用例进行容量评估,往往存在因为Benchmark压力不足导致无法测出真实容量
压控目标:
通过动态控压,评测出硬件和云上环境的真实容量
压控效果:
相比人工测试用例,评测出更真实的网络容量,高出10%+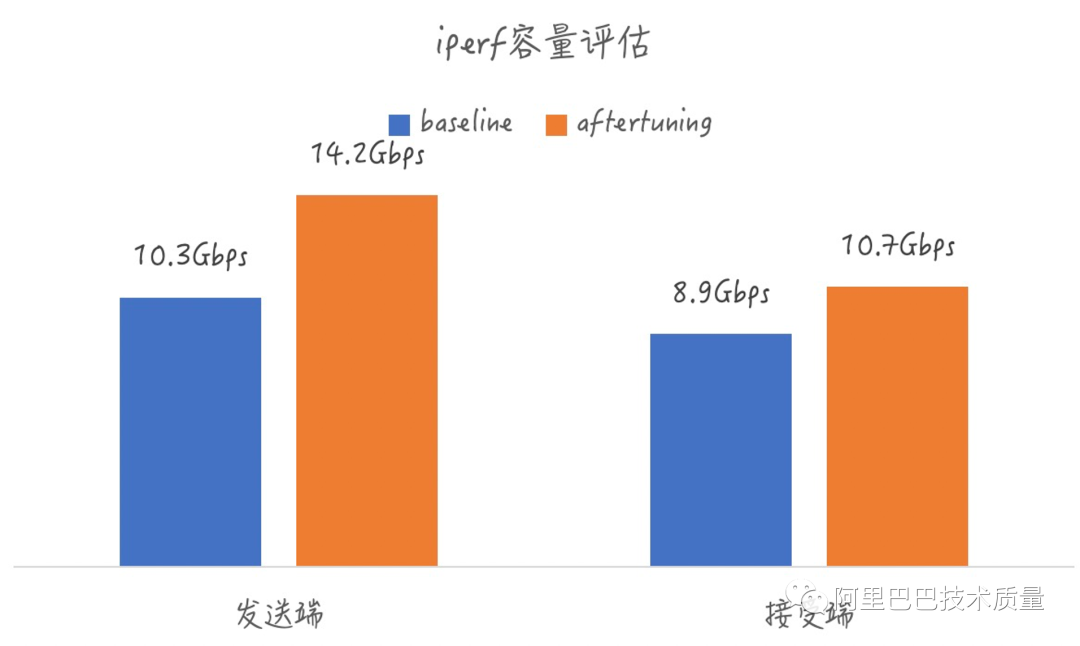
管控更多工具参数,并且能够提供最佳效果取值范围
说明:左边的两个图分别是iperf3进行接收端和发送端容量评估时,iperf3中参数真正对结果有效果的3个参数,右边的两列图,分别给出来了接收端和发送端在当前规格机器中这三个敏感参数的取值推荐。

2. 应用的调优、压力双控 – MySQL的调优与变压
项目背景:
进行应用的调优时,需要解决两部分问题:(1)Benchmark压力不足;(2)应用环境及自身调优
压控目标:
同时管控MySQL与Benchmark的参数,保证压力控制的状况下进行MySQL调优

审核编辑:刘清
-
HarmonyOS AI辅助编程工具(CodeGenie)智慧调优2025-08-14 567
-
MMC SW调优算法2024-09-20 484
-
OSPI控制器PHY调优算法2024-08-30 544
-
鸿蒙开发实战:【性能调优组件】2024-03-13 1632
-
KeenOpt调优算法框架实现对调优对象和配套工具的快速适配2022-11-11 1805
-
KeenTune的算法之心——KeenOpt 调优算法框架 | 龙蜥技术2022-10-28 16813
-
关于JVM的调优知识2022-09-14 1626
-
详细介绍算法效果调优的流程2022-08-24 1948
-
基于全HDD aarch64服务器的Ceph性能调优实践总结2022-07-05 3713
-
史上最全性能调优总结2022-05-13 7469
-
欧拉(openEuler)Summit 2021:基于AI的操作系统性能调优引擎2021-11-10 2956
-
HBase性能调优概述2019-07-03 1581
-
infosphere CDC性能调优的文档2017-09-07 785
全部0条评论

快来发表一下你的评论吧 !
