

数字中国建设整体布局规划,能给ChatGPT带来什么机会呢?
电子说
描述
人工智能 | NLP | GPU架构
深度学习 | AMD | Chat GPT
最近,ChatGPT又引发了不少新闻。比如,香港大学已经正式宣布,禁用ChatGPT,目的是防止论文抄袭。再比如,近日,不少美国企业已经把ChatGPT应用到了日常工作中,甚至代替了部分员工。据美媒报道,本月早些时候,一家提供就业服务的平台对1000家企业进行了调查,结果显示,近50%的企业表示,已经在使用ChatGPT;30%表示,有计划使用ChatGPT。而在已经使用ChatGPT的企业中,48%已经让其代替员工工作。ChatGPT的具体职责包括:客服、代码编写、招聘信息撰写、文案和内容创作、会议记录和文件摘要等。
中国的商业力量也开始对ChatGPT进行布局。除了百度和阿里的布局,前段时间美团的原联合创始人王慧文,也发布了一条AI英雄榜,说出资5000万美元,要打造中国的OpenAI,也就是制造ChatGPT的那家公司。
ChatGPT是由OpenAI开发的大型语言模型,要求较高的算力才能支持其正常的运行。目前OpenAI提供的ChatGPT-3模型需要数千亿次的浮点运算能力,并且需要超过350GB的存储空间来存储模型参数和相关数据。为了支持ChatGPT-3这样的大型语言模型的运行,需要使用大规模的GPU集群或者专门的超级计算机。在实际应用中,为了提高性能和减少延迟,通常会使用分布式计算来支持模型的运行。对于较小规模的语言模型,例如ChatGPT-2,也需要相对较高的算力才能正常运行,通常需要使用高性能计算机或者GPU来支持模型的训练和推理。
Chat GPT的局限
要想知道,ChatGPT的局限到底是什么?它又会带来什么样的问题?必须得先了解,ChatGPT的本质到底是什么?
一、ChatGPT的本质
ChatGPT 的本质是一种基于神经网络的自然语言处理模型,它通过深度学习技术来学习语言的规律和语义信息,并生成人类可读的文本。
具体而言,ChatGPT 采用了一种被称为“Transformer”的神经网络架构,它由多个编码器和解码器组成,可以有效地处理长序列的文本数据,并在学习中自动地学习语言规律和语义信息。ChatGPT 还使用了大量的文本数据进行无监督学习,使得模型具有较强的泛化能力和语言理解能力。
ChatGPT 的核心思想是基于预训练的方式,先在大规模语料库上进行无监督训练,使得模型具有较强的语言理解和生成能力,然后在特定任务上进行微调,以适应具体的应用场景。这种基于预训练的方式已经成为了自然语言处理领域的一个重要研究方向,并在各种文本生成和处理任务中取得了显著的成果。
二、ChatGPT的局限
ChatGPT 作为一种语言模型,能够在各种自然语言处理任务中表现出色。然而,它仍然存在一些局限性,包括:
1、数据偏差
ChatGPT 是基于大规模的语料库进行训练的,如果训练数据存在偏差,例如种族、性别、社会阶层等方面的偏差,模型可能会产生与现实世界不一致的结果。
2、计算资源需求高
ChatGPT 模型的参数非常多,需要大量的计算资源进行训练和推理。因此,只有大型机构或公司才有能力训练和使用这种模型。
3、长期依赖问题
虽然 ChatGPT 能够处理大量的文本信息,但它仍然存在长期依赖问题。在处理长文本时,模型可能会出现信息遗漏或信息重复等问题。
4、对话一致性问题
ChatGPT 在生成对话时,可能会产生与上下文不一致的回答,导致对话的连贯性受到影响。
5、语义理解问题
ChatGPT 能够生成人类可读的文本,但其对语义理解的能力仍然有限。在处理某些复杂的语义问题时,模型可能会出现错误的回答。
虽然 ChatGPT 存在一些局限性,但随着技术的不断发展,相信这些问题也将逐渐得到解决。
ChatGPT 是否是AI的革命
在人工智能技术的发展历程中,ChatGPT代表了自然语言处理技术的一个重要突破,为语言模型的研究和应用提供了新的思路和方法。ChatGPT的成功表明,通过大规模数据的训练和深度学习技术的应用,人工智能可以在自然语言处理领域取得更好的表现。
因此,可以说ChatGPT代表了人工智能技术的进步和创新,但它并不是整个人工智能的革命,因为人工智能技术的进步还需要依赖于许多其他方面的技术和应用,例如计算机视觉、机器学习、自动化等等。
一、人形机器人
ChatGPT 促进了人机交互能力的提升,加速了算法的采用。NLP技术带来的人机交互能力,只有人形机器人才有必要,尤其是C端场景。截至2022年10月,Tesla已经发布了Optimus人形机器人原型机,需要配合算法,形成全面的软硬件协同才能落地。我们认为ChatGPT有望提升人形机器人的人机交互能力,加速人形机器人体验的提升。
在场景2C中,人形机器人需要基于NLP的人机交互能力。人形机器人在与C端用户打交道时,由于其人形形态特征,需要人机交互能力作为接受指令的入口。在人机交互技能中,NLP能力无疑是重中之重。人形机器人必须能够理解人类的指令才能更好地完成各种任务。基于NLP的人机交互能力是类人机器人所需要的。
特斯拉Optimus人形机器人原型机于2022年10月发布,将在上海进博会上首次面向公众展出。2022年10月1日,特斯拉在AIDay发布了人形机器人Optimus原型机,并于2022年11月5日在上海进博会上展示了原件,现场展示的是附壳的二代机。虽然由于交货时间短,运行功能还不成熟,但现场展示版直立不动,但完成率高现场视频显示,样机已经可以完成物体搬运、浇花等动作。这是TeslaBot首次面向公众展示,为后续B端、C端落地埋下伏笔。

上海进博会现场展示的特斯拉人形机器人
二代版本训练时间短未能行走,还有出色的组合动作和手部动作。装壳的最新版本(2代Optimus),这个版本刚出厂还没有完全训练,现场也没有展示其行走功能,但视频显示了四肢和细微的手部动作组合,指关节快速执行1、2、6、拳头等动作,展现高精度、高灵敏度,为未来功能迭代留下巨大想象空间。

现场视频展示了 TeslaBot 手部精细度
以 AI 算法为核心的运动迭代展示了开创性的想法,从艰难移步到双脚离地快速行走用了 5 个月的时间。在特斯拉之前,本田ASIMO与波士顿动力机器人等其他人形机器人已经存在很长时间,能够实现的功能一般为直立行走、挥手、握手、搬运物品、拧瓶盖等。根据特斯拉发布会的官方公告,Tesla Optimus 仅开发了六个月,但已经基本实现了直立行走、挥手、给植物浇水、搬箱子等算法功能。一口气提升 4个月,软件迭代高效。此时,由于二代机才到货一个月,还没有完全调试好;但是,我们希望二代机在落地之后能够在应用中快速学习,实现快速的技术进步和可迭代性。

机器人共享汽车自动驾驶算法
机器人是智能手机的超越版本,单靠硬件无法实现,需要与软件算法协同工作,形成全面协同。 统一的硬件是机器人运行的基础,需要高精度、高灵敏度和高力矩以满足各种活动对机器人活动能力的要求。机器人的实际功能是通过综合算法来实现的,需要智能感知能力、运动控制能力、感控一体技术和AI算法等软硬件能力的综合配合。总之,硬件是机器人的躯体,软件是机器人的灵魂,软件与硬件的结合,灵魂与肉体的结合,才能构成一个完整的、可用的智能机器人。特斯拉的机器人产品迭代过程以及大量的算法和软件发布表明,软件的生态进步是推动当前机器人应用场景实现的关键因素。
特斯拉人形机器人拥有强大的AI软硬件完整备份,增加了后续开发的效率。除了对感知和控制算法的高要求外,人形机器人应用训练需要密集的计算负荷、强大的硬件平台以及合适的软件开发工具和框架;同时,迭代改进的算法模型可以提升AI芯片的性能,帮助解决长尾场景难题。软件、硬件和AI算法的融合,更有利于进一步激活生态,促进机器人未来场景的拓展。
算法框架和AI软硬件加速训练的备份,TESLAOT将进入快速迭代时代。强大的算法框架和AI软硬件储备才是机器人功能实现的真正核心。未来随着FSD的逐渐成熟和DOJO的落地,其算法和数据的闭环将进一步夯实。人形机器人在各种场景下的准确度和灵敏度训练将更加容易,TESLABOT将进入快速迭代时代。
我们认为ChatGPT有望提升人形机器人的人机交互能力,加快算法迭代过程,提升机器人体验升级。ChatGPT的出现进一步推进了NLP技术前沿,使人机对话体验不断优化。如果接入机器人应用,有望带来更好的人形机器人交互体验,加快人形机器人的落地过程。
二、AI 语音语义
NLP 技术正在不断优化被认为是AI皇冠上的明珠。对话式AI和知识图谱正在推动行业发展。到2026年,国内NLP驱动的相关产业规模可破千亿。我们认为,ChatGPT算法的突破,进一步提升了NLP技术的天花板,有望加速NLP技术在千行百业中的应用。
NLP被誉为人工智能皇冠上的明珠,由于语义理解需要海量数据让AI理解常识而壁垒较高。NLP或者说自然语义理解,技术上是指让人工智能理解人类预测背后的含义。NLP衍生的应用涵盖方方面面,包括机器翻译、AI应答机器人等。从技术角度来看,如果要让人工智能理解人类语言,最大的难点在于让机器理解人类对话背后的海量常识设定。因此,NLP训练需要海量数据,比训练其他AI技能难度更大,因此被称为“人工智能皇冠上的明珠”。
对话式人工智能和知识图谱正在推动工业规模的增长。到2026年,国内NLP驱动的相关产业规模可突破千亿。与其他人工智能技术相比,NLP一般不作为独立产品出售,而是作为一项基础技术,结合智能语音和知识图谱等技术,通常以对话式人工智能、机器翻译、知识库等形式出现,产品不断涌现,在独立生产模块的情况下,开发速度较慢。近两年,在对话机器人应用的推动下,智能知识库、分模块对话、对话语义理解、评论正负识别、对话自动输出等NLP产品迎来了发展机遇,并伴随着通用或垂直行业知识的发展在图谱构建中,NLP 与知识图谱的绑定关系将更加紧密。据艾瑞统计研究,到2021年,中国NLP核心产品规模将达到171亿元,带动规模将达到450亿元,到2026年,核心产品规模将达到459亿元,驱动规模将超过1000亿元。
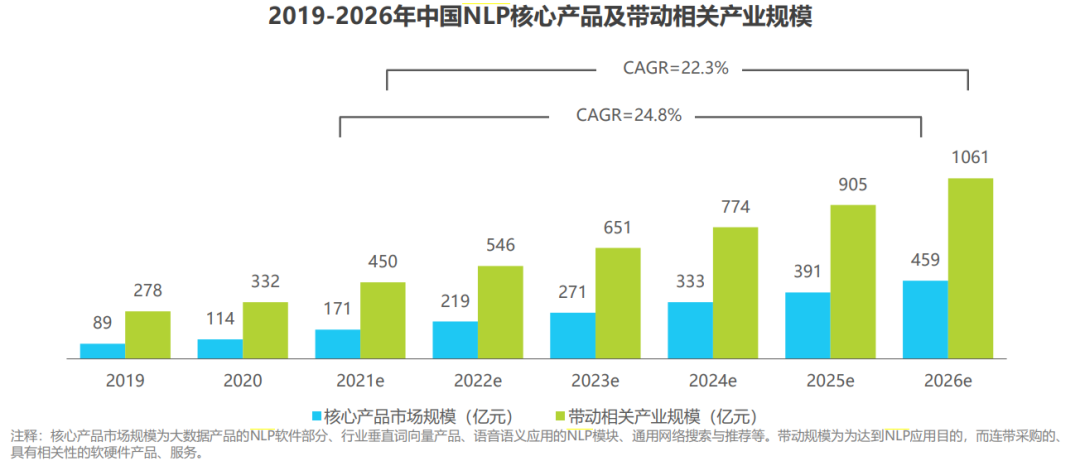
2019-2026 年中国 NLP 核心产品及带动相关产业规模
我们认为,作为NLP模型,ChatGPT算法的突破带来了NLP技术的进一步提升,有望加速NLP技术在智能语音、智能客服、机器人等各个行业和领域的应用。
三、AI 视觉
AIGC方兴未艾,图像识别技术进入落地阶段,有望催化进一步迭代。一方面AIGC技术方兴未艾。这种基于AI的人工智能创作有望在未来彻底改变内容生产方式,而NLP能力是其生产力的重要组成部分。ChatGPT有望加速其技术迭代。另一方面,AI图像识别技术进入广泛应用阶段,以海康威视、大华为首的龙头企业已将该技术应用于G端安防、B端产业/文旅等领域,助力降低成本和提高效率。
1、图像识别技术已经相对成熟,进入广泛落地阶段
人工智能图像识别技术进入广阔应用阶段,以海康、大华为首的人工智能视觉领军企业已将技术应用于安防、工业、文旅等领域。海康、大华等企业以愿景为切入点,落地AI应用,赋能千行百业降本增效。基于人脸识别、温度识别、动态追踪等技术,海康、大华等人工智能龙头企业为制造、旅游、金融等行业提出了智能化解决方案,有效降本增效。
1)在制造业,老板车间与海康威视合作,实现AR数字车间,助力智能生产。海康威视利用AR视频技术结合企业生产信息化,推出AR数字车间业务,为老板电器无人工厂“九天中枢”智能制造平台提供助力。AR数字车间可以在直观的物理世界屏幕上为现场管理人员提供生产线和设备的实时数据,并将大量视频画面、生产数据和设备数据组合成一个视图,帮助企业更快地应对突发事件;还可以将现场人员与管理人员或远程专家联系起来,提供远程实时指导;同时,通过视频图像可以确定分配给高周转量产品的线边空间量,实时监控装卸、计划数据、产出数据,帮助公司优化空间。
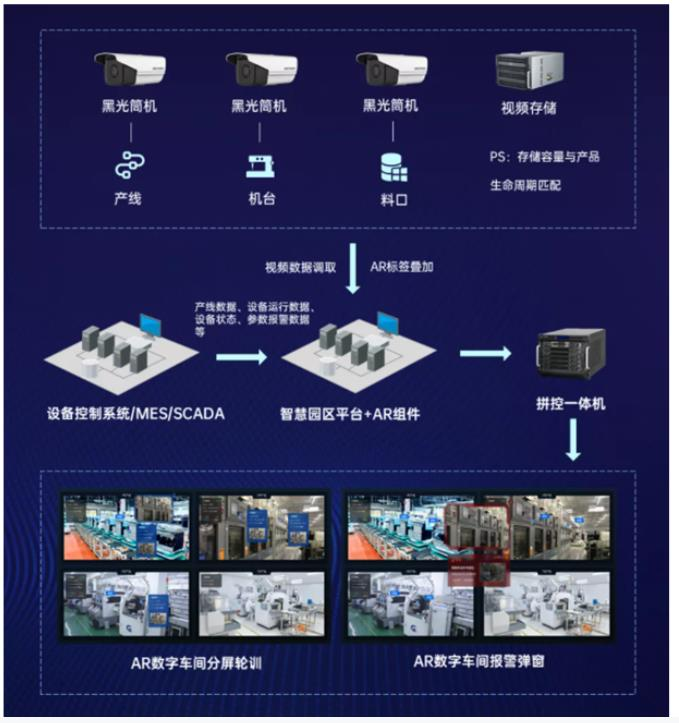
海康威视 AR 数字工厂示意图
2)旅游景区:AI机器视觉助力实现客流管理、智能运维、火灾预警和环境动植物监测。基于智能检测终端、智能网络、物联网技术和移动应用,人工智能机器视觉可实现景区地理、自然资源、基础设施和景区管理的数字化和可视化;完善旅游景区车辆、人员、资产和事件的安全管理。同时,通过智能分析和数据应用,增强景区安全,优化景区管理,丰富游客服务,助力景区环境和经济可持续发展。目前,大华股份的旅游景区解决方案已应用于四川大邑县、福建清源山景区等地的全域旅游项目。
大华股份智慧景区项目展示
2、AIGC技术方兴未艾,基于NLP技术未来有望创新内容创作方式
AIGC是一种利用AI技术自动生成内容的生产方式,包括文本、图片、视频等多种形式的内容。AIGC 是基于人工智能的内容生产,一般来说,使用形式是将需要生成的内容通过句子以一定的格式描述出来,然后让AI系统自动生成文字/图片/视频等。目前,国内外已有多家厂商在AIGC领域布局,比如国内的 AI 小说续写软件彩云小梦、OpenAI 推出的 AI 绘画 模型 Dall-E、知名 AI 绘画网站 midjourney 等。
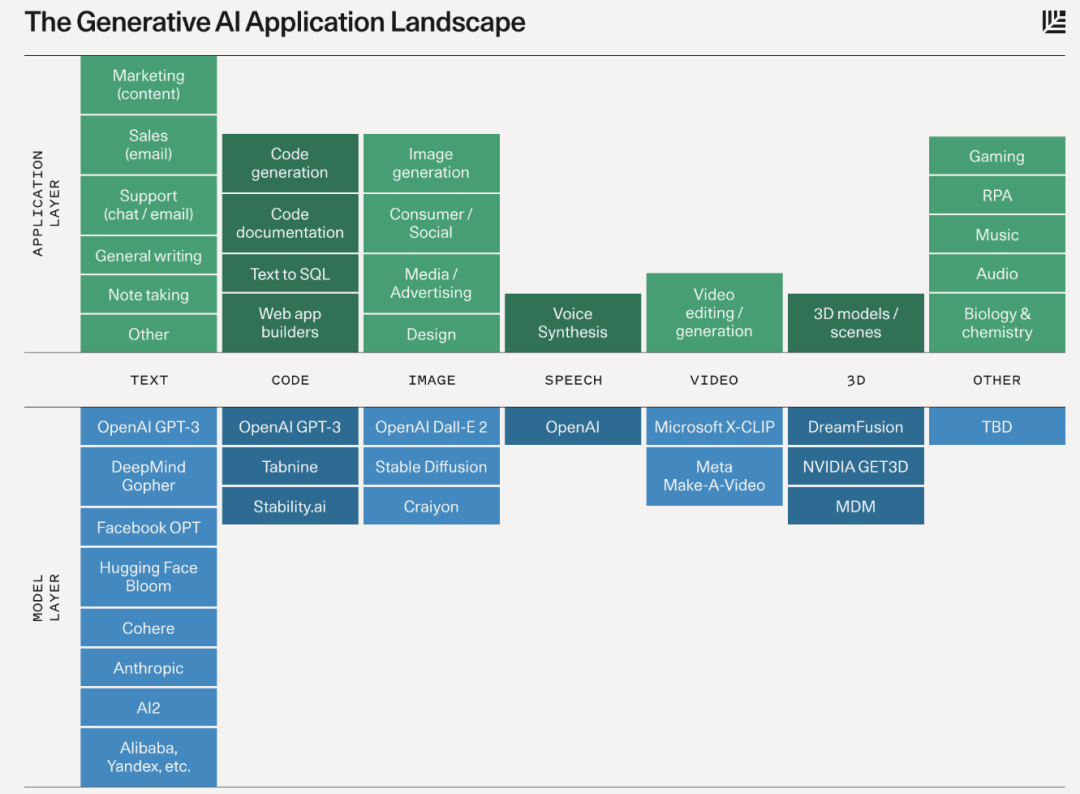
AIGC 应用领域一览
NLP 能力决定了 AIGC 应用对用户意图的理解力,是生产力的重要组成部分,ChatGPT 的到来有望加速其技术迭代。由于目前 AIGC 的生产模式,是通过语言文字的方式输入 用户需求,所以,如何理解用户所描述的内容,就成为决定成品效果的重要因素。而 NLP 技术,正是理解用户意图的关键所在。ChatGPT 作为当前效果最好的对话式 NLP 模型之 一,它的出现有望提升 AI 理解人类意图的水平,从而加速 AIGC 技术的迭代。
Chat GPT 的底层架构
作为一种人工智能模型,ChatGPT 的训练和推理需要大量的计算资源。与 CPU 相比,GPU 具有更高的并行性和处理能力,因此常常被用来加速深度学习任务的运算。因此,ChatGPT 的训练和推理通常会利用 GPU 来加速计算。
在训练过程中,ChatGPT 的架构可以采用分布式训练的方式,使用多个 GPU 并行计算,以加速训练过程。在推理阶段,ChatGPT 可以使用 GPU 进行加速,以实现更快的响应时间和更高的吞吐量。
对于 GPU 的选择,一般来说,需要考虑 GPU 的计算能力、内存大小、功耗、价格等因素。同时,也需要考虑 GPU 的架构是否与 ChatGPT 的计算需求相匹配,以获得最佳的性能和效率。例如,NVIDIA 的 Volta、Turing 和 Ampere 架构都被广泛应用于深度学习领域,包括 ChatGPT 的训练和推理。
GPU的核心竞争力在于架构等因素决定的性能先进性和计算生态壁垒。国内GPU厂商纷纷大力投入研发快速迭代架构,推动产业开放构建自主生态,加速追赶全球头部企业。国产替代需求持续释放叠加国际局势不确定性加剧, AI、数据中心、智能汽车、游戏等GPU需求有望高增,国产GPU迎来发展黄金期,我们看好国产GPU公司的发展与投资机遇。
一、如何理解GPU的架构
为了充分理解GPU的架构,让我们再返回来看下第一张图,一个显卡中绝大多数都是计算核心core组成的海洋。在图像缩放的例子中,core与core之间不需要任何协作,因为他们的任务是完全独立的,然而,GPU解决的问题不一定这么简单,让我们来举个例子。
假设我们需要对一个数组里的数进行求和,这样的运算属于reductuin family类型,因为这样的运算试图将一个序列“reduce”简化为一个数。计算数组的元素总和的操作看起来是顺序的,我们只需要获取第一个元素,求和到第二个元素中,获取结果,再将结果求和到第三个元素,以此类推。
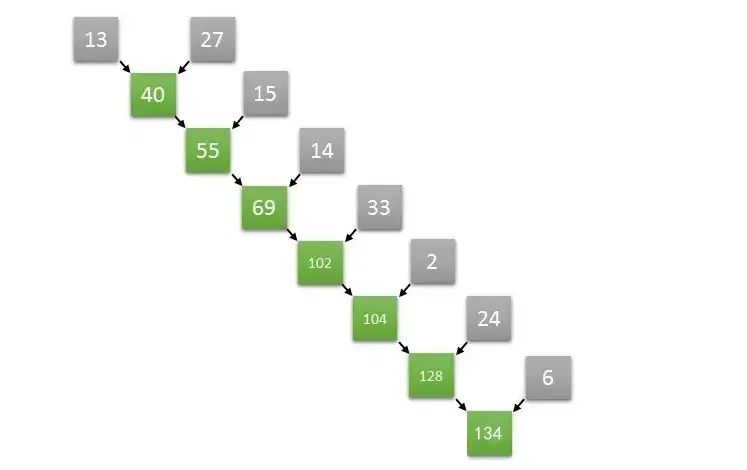
令人惊讶的是,一些看起来本质是顺序的运算,其实可以再并行算法中转化。假设一个长度为8的数组,在第一步中完全可以并行执行两个元素和两个元素的求和,从而同时获得四个元素,两两相加的结果,以此类推,通过并行的方式加速数组求和的运算速度。具体的操作如下图所示,
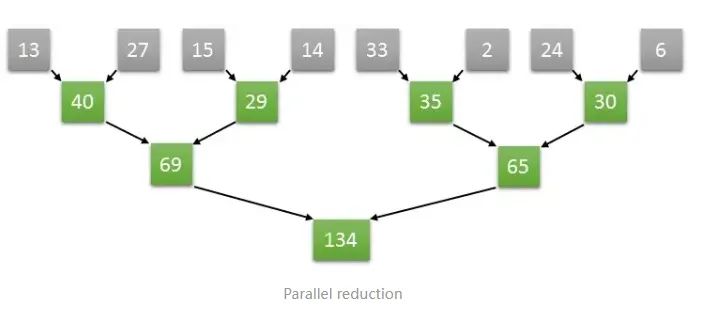
如上图计算方式,如果是长度为8的数组两两并行求和计算,那么只需要三次就可以计算出结果。如果是顺序计算需要8次。如果按照两两并行相加的算法,N个数字相加,那么仅需要log2(N)次就可以完成计算。
从GPU的角度来讲,只需要四个core就可以完成长度为8的数组求和算法,我们将四个core编号为0,1,2,3。
那么第一个时钟下,两两相加的结果通过0号core计算,放入了0号core可以访问到的内存中,另外两两对分别由1号2号3号core来计算,第二个个时钟继续按照之前的算法计算,只需要0号和1号两个core即可完成,以此类推,最终的结果将在第三个时钟由0号core计算完成,并储存在0号core可以访问到的内存中。这样实际三次就能完成长度为8的数组求和计算。
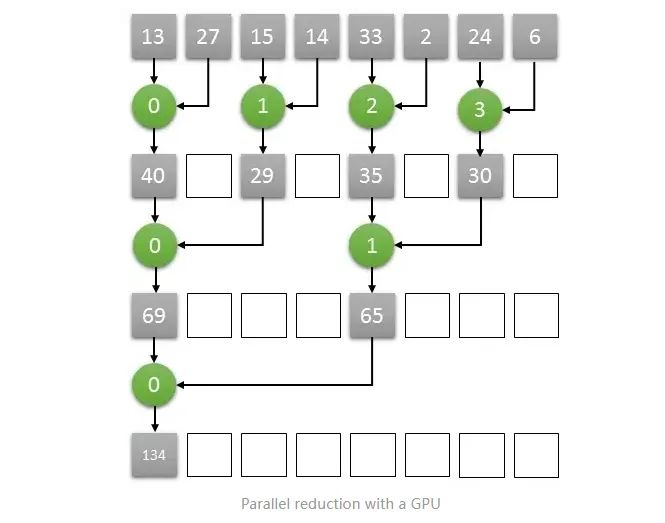
如果GPU想要完成上述的推理计算过程,显然,多个core之间要可以共享一段内存空间以此来完成数据之间的交互,需要多个core可以在共享的内存空间中完成读/写的操作。我们希望每个Cores都有交互数据的能力,但是不幸的是,一个GPU里面可以包含数以千计的core,如果使得这些core都可以访问共享的内存段是非常困难和昂贵的。出于成本的考虑,折中的解决方案是将各类GPU的core分类为多个组,形成多个流处理器(Streaming Multiprocessors )或者简称为SMs。
二、最终的GPU架构
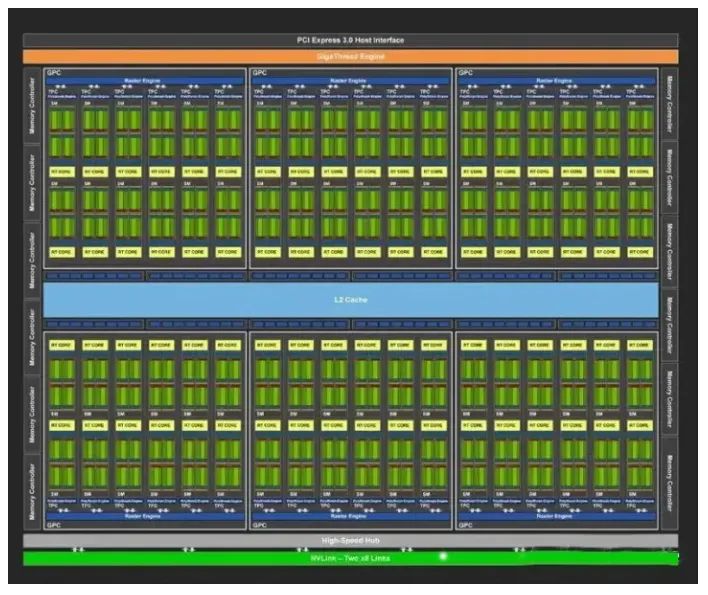
The Turing architecture
上图的绿色部分意味着Core计算单元,绿色的块就是上文谈到的Streaming Multiprocessors,理解为Core的集合。黄色的部分名为RT COREs画的离SMs非常近。单个SM的图灵架构如下图所示
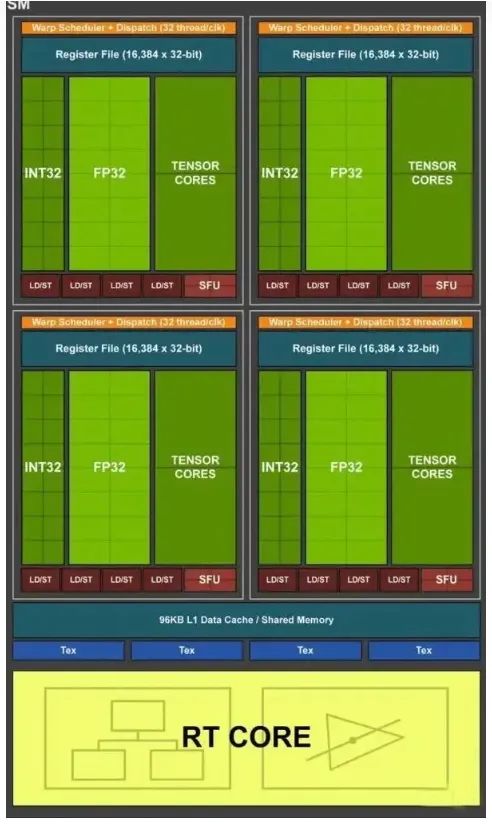
The Turing SM
在SM的图灵结构中,绿色的部分CORE相关的,我们进一步区分了不同类型的CORE。主要分为INT32,FP32,TENSOR CORES。FP32 Cores,执行单进度浮点运算,在TU102卡中,每个SM由64个FP32核,TU120由72个SMs因此,FP32 Core的数量是 72 * 64。
FP64 Cores. 实际上每个SM都包含了2个64位浮点计算核心FP64 Cores,用来计算双精度浮点运算,虽然上图没有画出,但是实际是存在的。Integer Cores,这些core执行一些对整数的操作,例如地址计算,可以和浮点运算同时执行指令。在前几代GPU中,执行这些整型操作指令都会使得浮点运算的管道停止工作。TU102总共有4608个Integer Cores,每个SM有64个SM。
Tensor Cores,张量core是FP16单元的变种,认为是半精度单元,致力于张量积算加速常见的深度学习操作。图灵张量Core还可以执行INT8和INT4精度的操作,用于可以接受量化而且不需要FP16精度的应用场景,在TU102中,我们每个SM有8个张量Cores,一共有8 * 72个Tensor Cores。
在大致描述了GPU的执行部分之后,让我们回到上文提出的问题,各个核心之间如何完成彼此的协作?
在四个SM块的底部有一个96KB的L1 Cache,用浅蓝色标注的。这个cache段是允许各个Core都可以访问的段,在L1 Cache中每个SM都有一块专用的共享内存。作为芯片上的L1 cache的大小是有限的,但它非常快,肯定比访问GMEM快得多。
实际上L1 CACHE拥有两个功能,一个是用于SM上Core之间相互共享内存,另一个则是普通的cache功能。当Core需要协同工作,并且彼此交换结果的时候,编译器编译后的指令会将部分结果储存在共享内存中,以便于不同的core获取到对应数据。当用作普通cache功能的时候,当core需要访问GMEM数据的时候,首先会在L1中查找,如果没找到,则回去L2 cache中寻找,如果L2 cache也没有,则会从GMEM中获取数据,L1访问最快 L2 以及GMEM递减。缓存中的数据将会持续存在,除非出现新的数据做替换。从这个角度来看,如果Core需要从GMEM中多次访问数据,那么编程者应该将这块数据放入功能内存中,以加快他们的获取速度。其实可以将共享内存理解为一段受控制的cache,事实上L1 cache和共享内存是同一块电路中实现的。编程者有权决定L1 的内存多少是用作cache多少是用作共享内存。
最后,也是比较重要的是,可以储存各个core的计算中间结果,用于各个核心之间共享的内存段不仅仅可以是共享内存L1,也可以是寄存器,寄存器是离core最近的内存段,但是也非常小。最底层的思想是每个线程都可以拥有一个寄存器来储存中间结果,每个寄存器只能由相同的一个线程来访问,或者由相同的warp或者组的线程访问。
三、海外复盘:NVIDIA与AMD(ATI)的竞争贯穿GPU发展历程,架构创新升级和新兴AI等领域前瞻探索是领跑的关键
1、NVIDIA长期居于GPU市场领导地位,近年AMD凭借RDNA架构在游戏市场强势崛起。Verified Market Research数据显示,2022年全球独立GPU市场规模约448.3亿美元,NVIDIA和AMD的市场份额占比约为8:2。根据JPR数据,NVIDIA凭借自身性能领先和CUDA生态优势性 始终占有GPU领域超50%的市场份额,数据中心业务更是全面领先,在游戏显卡领域,近年AMD凭借RDNA系列架构强势崛起。
2、NVIDIA先后与AMD等企业在性能方面竞争博弈,架构创新升级和新兴领域前瞻探索是领跑GPU行业的关键。NVIDIA凭借性能领先长期占据超五成市场份额,AMD(ATI)也曾因架构出色、性能惊艳实现反超。同时NVIDIA早在2006年前瞻性布局通用计算、构建CUDA生态,为如今AI&数据中心领域的全面领先构筑牢固的壁垒。NVIDIA积极布局异构芯片、汽车、元宇宙等新市场,寻找新的强有力业务增长点。
四、国内GPU市场:各应用场景市场广阔,国内厂商大有可为
1、GPU市场空间广阔,国内企业规模逐步起量
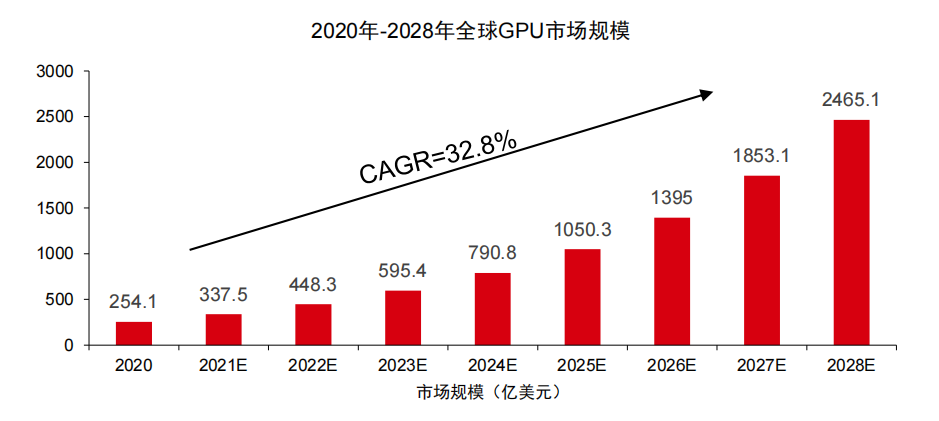
2022年全球GPU市场规模达到448.3亿美元,国内外市场空间正高速增长,年复合增长率达到32.8% ,Verified Market Research 数据显示,2020年,全球GPU市场规模为254.1亿美元,且该机构预计2028年市场规模将达到2465.1亿美元, 对应年复合增长率达32.8%。
国际独立GPU市场由Nvidia、AMD八二分成,国内市场中国企业体量快速增长国际市场上,英伟达、AMD瓜分市场,Jon Peddie Research数据显示2022Q1英伟达占据79%市场份额,AMD占据21%。英伟达在独立GPU领域一枝独秀,AMD在集成GPU领域可与英伟达竞争。根据各公司财报,国内GPU龙头企业景嘉微2022年上半年营业收入5.44亿人民币,2021年营业收入10.93亿人民币;2022年上半年海光信息营业收入为25.3亿元,而英伟达2022Q2营收为67亿美元,2021年NVIDIA中国区的营收约为71亿美元。相比之下,国产厂商相对规模暂时较小,未来成长空间广阔。
2、国内市场:GPU应用市场可划分为—AI和数据中心、智能汽车、游戏
1)需求端1—AI
ChatGPT等AI大模型加速对大算力的需求
2022年11月人工智能实验室 OpenAI 推出了一款AI对话系统—ChatGPT,ChatGPT模型从 GPT-3.5 系列中的一个模型微调而成,并在 Azure AI 超级计算基础设施上进行训练,能够进行有逻辑的对话、撰写代码、撰写剧本、纠正错误、拒绝不正当的请求等,效果超越大众预期。这标志着对话类人工智能可以在大范围、细节问题上给出较合理准确的答案,并根据上下文形成一定像人类一样有逻辑且有创 造力的回答。ChatGPT的优化主要来自模型的增大,以及因此带来的算力增加。GPT、GPT-2和GPT-3(当前开放的版本为GPT-3.5)的参数量从1.17 亿增加到1750亿,预训练数据量从5GB增加到45TB,其中GPT-3训练单次的成本就高达460万美元。
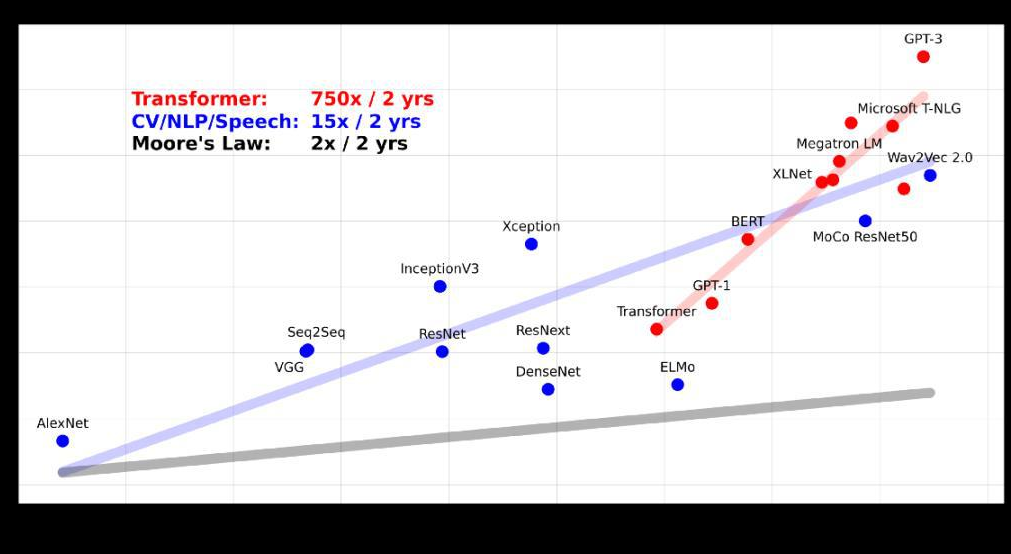
大模型算力
数据中心和终端场景不断落地对计算芯片提出更多更高需求
依据部署位置划分,AI芯片可以细分为终端芯片和云端芯片,云端芯片市场空间约为终端芯片的2-3倍。云端芯片:云端芯片应用于云端服务器,可以进一步细分为推理芯片和训练芯片。根据甲子光年数据,2018年中国云端芯片市场约46.1 亿元,该机构预计2023年增长至384.6亿元。终端芯片:应用于嵌入式、移动终端、智能制造、智能家居等领域的AI芯片,终端芯片需要低功耗和更高的能效比,但是对算力的需求也相对较低,主要应用于AI推理。根据甲子光年数据,2018年中国终端芯片市场约15亿元,该机构预计2023年增长至173亿元。
AI芯片总市场232亿元,其中云端芯片市场空间更大,预计终端芯片将随着AI在多行业落地将进一步放量。甲子光年预测,中国AI芯片市场规模将从2021年232亿元增长至2023年的500亿元左右,对应中国云端芯片市场的复合增长率为52.8%;终端芯片市场规模相对较小,但由于人工智能在汽车、安防、智能家居等行业渗透,届时市场规模增长率达到62.2%。
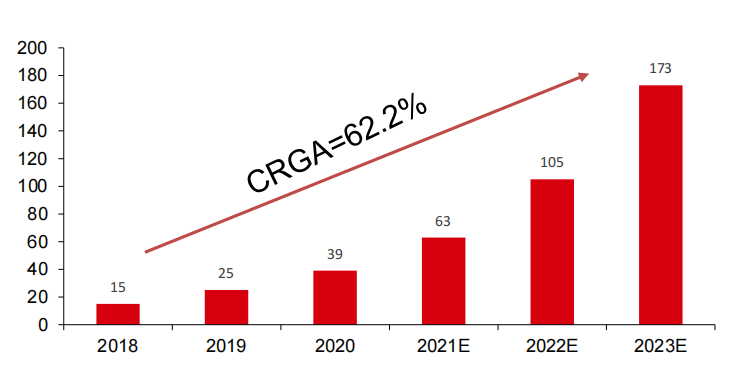
中国终端AI芯片市场规模(亿元)
2)需求端2—汽车:汽车智能化浪潮下控制器GPU市场前景广阔。自动驾驶和智能座舱是智能汽车中具有广阔前景的方向。盖世汽车数据预计,2025年自动驾驶域控制器出货量将达到432万台,每台自动驾驶域控制器配备1-4片高性能计算GPU;智能座舱域控制器出货量达到528万台,绝大多数智能座舱域控制器配备1片GPU。自动驾驶技术进一步智能化拉动汽车GPU市场规模快速扩张。
3)需求端3—游戏:游戏玩家人数持续增长,游戏GPU市场稳中有升。Newzoo Expert数据显示全球游戏玩家人数在2021年已达到30.57亿人,且预计2020-2025年全球游戏玩家人数复合年增率为4.2%;游戏市场内,游戏机和PC两大主体出货量再创新高,游戏机三大巨头2021年出货量高达4008万台;2021年Q4全球PC GPU出货量(包括集成和独立显卡)高达11000万片。
3、国内GPU发展现状
1)GPU市场规模逐年增长:据市场研究公司IDC数据显示,2020年中国GPU市场规模为92.9亿美元,同比增长15.5%。其中游戏、数据中心、人工智能等领域是GPU市场的主要需求方。
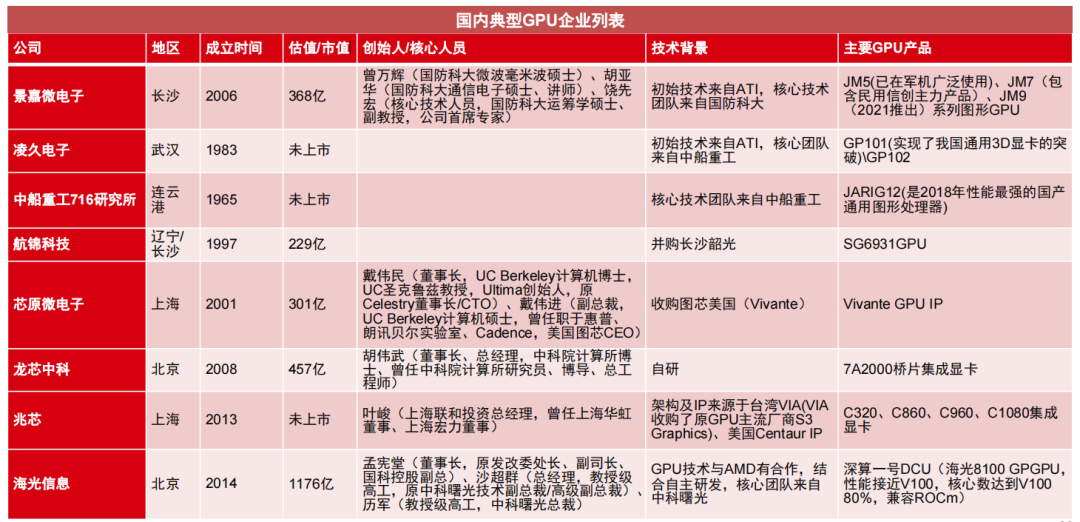
2)国内GPU厂商崛起:中国有多家GPU厂商在市场中崭露头角,例如华为、寒武纪、显现科技、紫光展锐等。这些公司在GPU技术研发、产品创新、市场拓展等方面取得了不少成果,并开始在一些领域崭露头角。
3)国内GPU技术水平提升:中国在GPU技术研发领域也取得了一些成果,例如国产化的GPU服务器、AI加速卡、图像处理器等,这些技术的出现使得国内GPU应用的范围进一步扩大。
4)GPU在科研领域的应用逐步增多:GPU在科研领域的应用逐步增多,例如天河系列超级计算机、中国科学院的高性能计算平台等。GPU的应用不仅加速了科研进程,也为国家科技创新提供了支撑。
总结
数字中国建设是中国国家发展战略的一部分,旨在推动数字化、信息化和网络化的全面发展,提高数字经济的贡献率,构建数字社会和数字政府,加强国家信息安全和网络安全等。数字中国建设的整体布局规划应该包括以下几个方面:
1、建设数字基础设施:包括建设高速宽带网络、移动通信网络、物联网等数字基础设施,提高网络带宽和速度,实现全国覆盖。
2、推进数字产业发展:包括培育数字经济新业态,加强数字产业集聚区建设,促进数字化转型,提高数字产业的国际竞争力。
3、构建数字社会:加强数字技术与社会发展的融合,建立数字健康、数字教育、数字文化等数字社会基础设施,提高人民群众的数字素养和数字生活质量。
4、推进数字政府建设:通过建设数字政府平台、数字化行政审批、电子政务等手段,提高政府工作效率和公共服务水平,推进政府治理现代化。
5、加强信息安全和网络安全:建设信息安全和网络安全的法律制度体系,强化网络空间安全管理,提高信息安全和网络安全能力。
通过数字中国建设的整体布局规划,可以实现数字化、信息化和网络化的全面发展,加速数字经济的发展,提高社会生产力和国家综合实力。此外,ChatGPT可以通过学习数字中国建设的整体布局规划,深入了解数字技术在国家战略和社会发展中的应用,从而提高对数字经济、数字社会、数字政府等领域的理解和认知,为未来发展提供更加全面和深入的思路和支持。
审核编辑 黄宇
-
洲明科技闪耀第九届数字中国建设峰会2026-05-07 270
-
中科曙光亮相第八届数字中国建设峰会2025-05-06 1055
-
诚迈科技助力数字中国建设2024-11-06 1193
-
中兴通讯亮相第七届数字中国建设峰会2024-10-15 1593
-
元宇宙与AI加速推进数字中国建设,需关注降本增效2023-11-15 1561
-
西「景」洞察丨《关于落实数字中国建设总体部署,加快推动智慧民航建设发展的指导意见》2023-07-21 2086
-
4月26日飞腾亮相第六届数字中国建设峰会2023-04-25 1549
-
王春晖解读《数字中国建设整体布局规划》2023-03-08 1433
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2377
-
数字中国升级为国策!IoT产业细分赛道迎来黄金期-IOTE物联网展2023-03-01 1196
-
数字中国建设整体布局规划印发 做强做优做大数字经济2023-02-28 1910
-
中兴通讯正持续推动数字中国建设2022-07-25 3955
-
软件定义存储助力数字中国建设2021-05-27 668
-
紫光集团从“芯”到“云”战略布局,助推数字中国建设2018-04-24 6028
全部0条评论

快来发表一下你的评论吧 !
