

基于MLP网络的VR一体机全身Avatar动捕方案
vr|ar|虚拟现实
描述
根据给定的稀疏上身追踪信号(头和双手)来实现全身追踪,亦即头显追踪的头部运动,以及控制器追踪的双手运动
目前大多数基于VR一体机的Avatar系统都没有下半身,一个重要的原因是,尽管设备能够通过内向外追踪实现头部和双手的动捕,而这又使得估计手臂和胸部的位置相对容易,但系统难以判断你的腿、脚或臀部位置,所以今天的Avatar一直都是缺失下半截。
所以,行业一直在探索各种解决方案。例如,Meta早前的一份研究就提出了基于AI的纯头显全身Avatar动捕方案,无需任何光学标记。
在另一篇论文中,Meta的研究人员又提出了另一种为Avatar长出双腿的方法AGRoL。据介绍,这是一种全新的条件扩散模型,专门用于根据给定的稀疏上身追踪信号(头和双手)来实现全身追踪,亦即头显追踪的头部运动,以及控制器追踪的双手运动。所述模型使用了一个简单的MLP架构和一种新的运动数据调节方案,从而能够准确流畅预测全身运动,尤其是具有挑战性的下半身运动。
人类是AR/VR应用的主要参与者。所以,能够追踪全身运动是所述应用的一大需求。常见的方法只能准确地追踪上身,而全身追踪可以解锁引人入胜的体验,增加用户的临场感。但在典型的AR/VR设置中,缺乏对完整人体的强烈追踪信号,只有头和手通过嵌入头显和控制器中的惯性测量单元传感器进行追踪。对于理想情况,我们希望使用大多数头显提供的标准三输入(头和双手)来实现高保真全身追踪。
考虑到头和手的位置和方向信息,预测全身姿势,尤其是下半身,其本质是一个欠约束的问题。为了解决这一挑战,一系列的方法依赖于生成性模型。在这个领域,扩散模型在图像和视频生成中显示出令人印象深刻的结果,特别是对于条件生成。这促使Meta使用扩散模型来生成基于稀疏追踪信号的全身姿态。
当然,在这项任务中使用扩散模型并非易事。具有扩散模型的条件生成方法广泛用于跨模态条件生成。遗憾的是,考虑到数据表示的差异,例如人体关节特征与图像,所述方法不能直接应用于运动合成任务。
在名为《Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model》的论文中,Meta提出了一种全新的扩散架构Avatars Grow Legs(AGRoL),并专门针对条件运动合成任务而设计。
这项研究使用了基于MLP的架构,团队发现精心设计的MLP网络已经可以实现与最先进方法相当的性能。然而,MLP网络的预测运动可能包含抖动伪影。
为了解决这个问题,并从稀疏的追踪信号中生成平滑的真实全身运动,研究人员设计了一个由MLP架构赋能的轻量级扩散模型。
扩散模型需要在训练和推理期间将时间步长嵌入注入网络,而他们发现这个MLP架构对输入中的位置嵌入不敏感。所以,团队进一步提出了一种新的策略,以在扩散过程中有效地注入时间步长嵌入。利用所提出的策略,模型可以显著减轻抖动问题,并进一步提高性能及其对追踪信号丢失的鲁棒性。正如在大型运动捕捉数据集AMASS的实验证明,AGRoL在全身运动预测能力方面优于现有技术的全身运动。
Meta的目标是预测给定稀疏追踪信号的全身运动,即头显和双手控制器的方向和平移。给定N个观察到的关节特征序列:
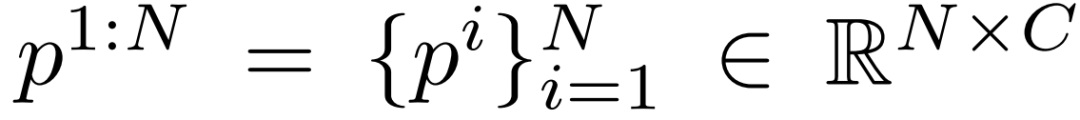
团队希望预测N个帧的全身姿态:
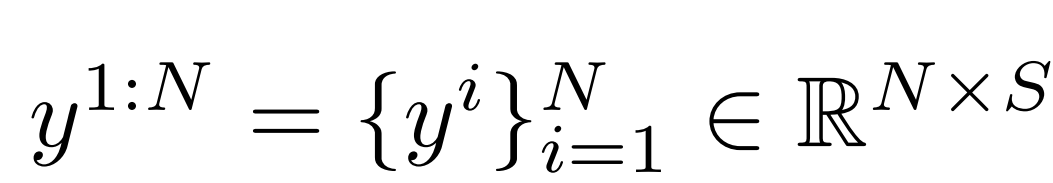
其中C和S表示输入/输出关节特征的维度。
研究人员采用SMPL模型来表示人体姿势,并且仅使用SMPL模型的前22个关节,而忽略手上的关节。因此,y 1:N表示骨盆的全局方向和每个关节的相对旋转。
基于MLP的网络
网络仅由4种在深度学习时代广泛使用的组件组成:全连接层(LN)、SiLU激活层、1D卷积层(内核大小为1)和层归一化。注意,1D卷积层同时可以视为在不同维度操作的全连接层。所述网络架构的细节如下图所示。
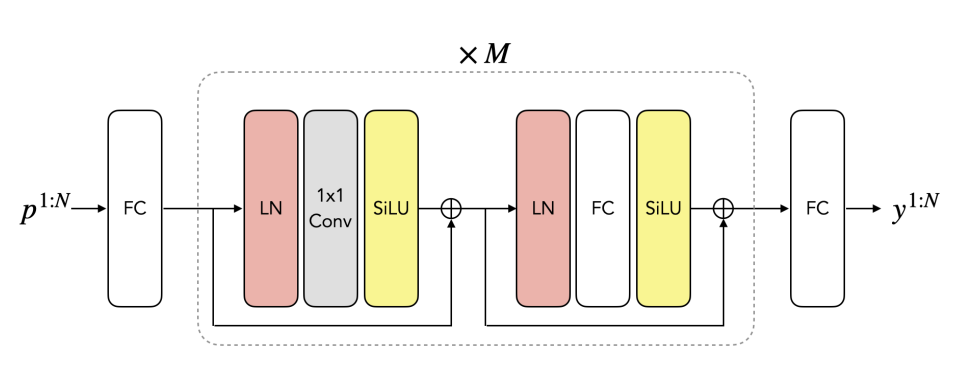
MLP网络的每个block包含一个卷积层和一个全连接层,分别负责时间和空间信息合并。研究人员使用skip-connection作为层的预规范化。首先,使用线性层将输入数据p 1:N投影到更高维度的latent space。网络的最后一层从latent space投射到全身的输出空间,其比例为y 1:N。
扩散模型
扩散模型是一种生成性模型,它学习反转由马尔可夫链添加的随机高斯噪点,以便从噪点中恢复期望的数据样本。
在扩散模型中,时间步长t的嵌入通常作为额外的输入馈送到网络。添加时间步长嵌入的常见方法是将其与输入连接,类似于transformer-based method中使用的位置嵌入。然而,由于Meta的网络使用MLP,研究人员发现模型对时间步长嵌入的值不太敏感,这阻碍了去噪过程的学习,并导致具有严重抖动问题的运动预测。
为了解决这个问题,研究人员提出了一种新的策略,在MLP网络的每个block之前重复注入时间步长嵌入。管道的细节下图所示。
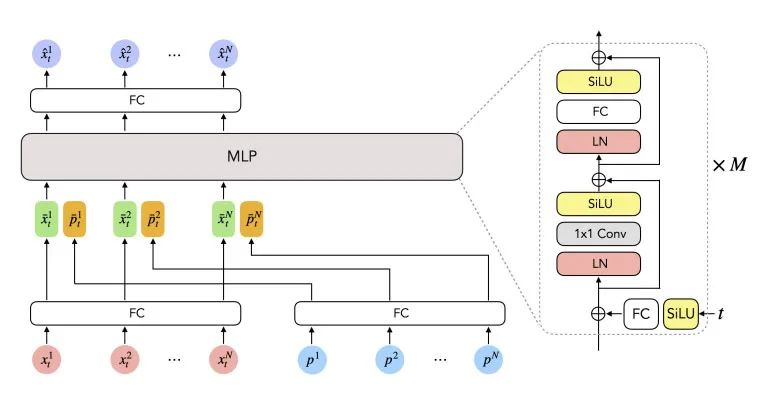
时间步嵌入投影为通过全连接层和SiLU激活层匹配输入特征维度,然后,预测每个block的时间步嵌入的比例和移位因子,直接将获得的特征添加到输入中间激活。团队指出,所提出的策略可以在很大程度上减轻抖动问题,并实现平滑运动的合成。
研究人员在AMASS数据集训练和评估模型,采用SMPL人体模型作为人体姿态表示,并训练模型来预测根关节的全局方向和其他关节的相对旋转。

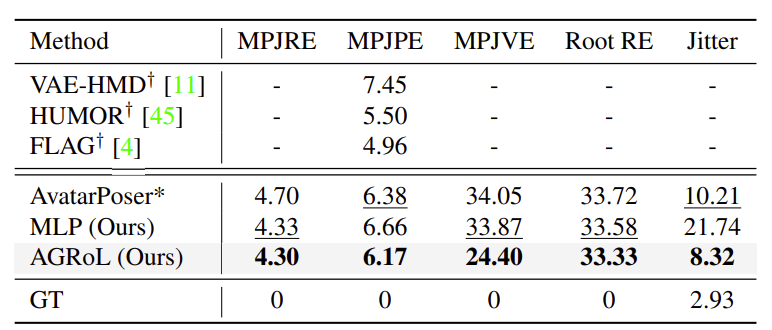
如表1和表2所示,Meta的MLP网络完全可以超越大多数以前的方法,并与最先进的方法取得可比的结果,这表明了所述网络的有效性。在扩散过程的帮助下,AGRoL模型进一步提高了MLP网络的性能,并超越了所有以前的方法。
另外,所提出的AGRoL模型显著减少了抖动误差,这意味着与其他模型相比,生成性运动更加平滑。

上图是AGRoL(下方)和AvatarPoser(上方)对AMASS数据集测试序列的定性比较。图中可视化了预测的骨骼和人体网格。绿色的骨架表示使用Meta方法预测的运动。红色的骨架则表示使用AvatarPoser预测的运动。蓝色的骨骼表示ground truth运动。如图所示,与AvatarPoser的预测运动相比,Meta的预测运动更准确。
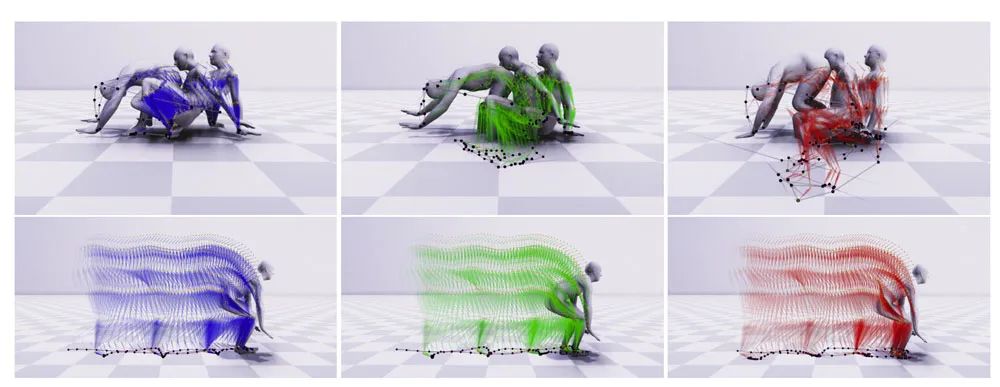
上图可视化了预测运动的轨迹。左边的图像显示了带有蓝色骨架的ground truth运动。中间图像显示了带有绿色骨架的AGRoL预测运动。右边图像显示了AvatarPoser预测运动(红色骨骼)。
图中的浅紫色矢量表示每个关节的速度矢量。通过可视化运动轨迹,可以从图中更好地查看抖动问题和双脚滑动问题。平滑运动倾向于具有规则的姿势轨迹,每个关节的速度向量稳定地变化。姿势轨迹的密度将随着行走速度而变化,当人减速时,轨迹将变得更密集。
相关论文:
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model
总的来说,AGRoL是一种专门为基于稀疏IMU追踪信号的全身运动合成而设计的条件扩散模型。AGRoL是一种简单而高效的MLP扩散模型。为了实现渐进去噪并产生平滑的运动序列,研究人员提出了一种分block注入方案,在神经网络的每个中间block之前添加扩散时间步长嵌入。通过这种时间步嵌入策略,AGRoL在全身运动合成任务中实现了最先进的性能,而不会出现其他运动预测方法中常用的任何额外损失。
研究表明,基于轻量级扩散的模型AGRoL可以生成真实的平滑运动,同时实现实时推理速度,使其适合在线应用。与现有方法相比,它对追踪信号丢失更为鲁棒。
编辑:黄飞
-
芯片厂商重拳出击,争夺VR一体机市场2017-03-01 1091
-
三类国产VR一体机或将跻身世界前列2017-02-20 4003
-
新一代高清智能高精度测速一体机系统2015-11-05 3892
-
VR一体机技术的关键技术2018-09-21 5145
-
微鲸VR一体机的外形及性能介绍2017-09-14 1111
-
质量好的VR一体机推荐:Pico NeoVR一体机、大朋VR一体机2017-09-15 2868
-
Facebook:2018聚焦VR一体机 推动VR设备走向主流2018-01-15 1404
-
VR一体机、VR头盔和VR眼镜的概念以及区别分析2018-02-02 18016
-
大朋VR一体机拆机测评2018-02-10 4845
-
VR一体机市场人气火爆2018-05-16 2242
-
为什么说VR/AR一体机移动是趋势2018-07-19 1825
-
小米VR一体机评测 国内VR行业的标杆2018-12-20 5275
-
VR一体机的存活因素是什么2020-05-31 1021
-
VR一体机的五大选购技巧2020-06-13 3796
-
三款主流的VR一体机推荐2021-01-26 13623
全部0条评论

快来发表一下你的评论吧 !
