

算法模型发展的燃料,AI基础数据服务市场规模快速增长!
描述
电子发烧友网报道(文/李弯弯)在AI产业链中,算法、算力和数据共同构成技术发展的三大核心要素。在当前人工智能行业发展进程中,有监督的深度学习算法,是推动人工智能技术取得突破性发展的关键技术理论,而大量训练数据的支撑则是有监督的深度学习算法实现的基础,训练数据早已成为算法模型发展和演进的燃料。
AI基础数据服务市场快速增长
当前,全球基础数据服务行业正处于快速成长期,市场规模具有较大的增长空间。从AI产业链的发展情况和未来发展趋势来看,中国基础数据服务行业的市场规模也将不断扩大。
一方面,随着算法模型、技术理论和应用场景的优化和创新,AI产业对训练数据的拓展性需求和前瞻性需求均快速增长;另一方面,随着行业内对训练数据需求类型的增加以及对服务标准要求的提高,产业链的专业化分工将愈加清晰,专业化的训练数据服务提供商将扮演更加重要的角色。
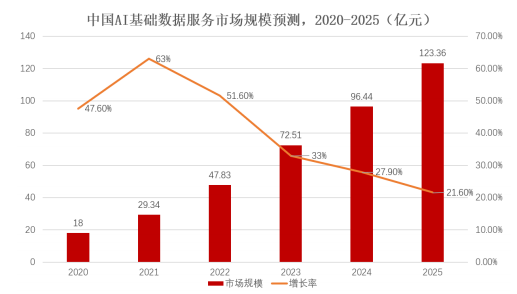
根据IDC预测,2025年中国人工智能市场规模有望达到184.3亿美元(约1200亿人民币)。其中,关于基础数据部分,预计中国AI基础数据服务市场规模近5年来的复合年增长率达到47%,预期2025年将突破120亿元,达到中国人工智能市场支出总额的约10%。
在当前技术发展进程中,深度学习算法是推动人工智能技术取得突破性发展的关键技术理论,而大量训练数据的训练支撑则是深度学习算法实现的基础。训练数据越多、越完整、质量越高,模型推断的结论越可靠。因此,要使算法模型实现从技术理论到应用实践的落地过程,就需要提供大量的训练数据,对算法模型加以训练。
2021年,全球人工智能和机器学习领域最权威的学者之一吴恩达教授提出二八定律:AI研究80%的工作应该放在数据准备上,确保数据质量是最重要的工作。
然而,从自然数据源简单收集取得的原料数据并不能直接用于有监督的深度学习算法训练, 必须经过专业化的采集、加工,形成相应的工程化训练数据集后才能供深度学习算法等训练使用。目前,应用有监督学习的算法对于训练数据的需求远大于现有的标注效率和投入预算,基础数据服务将持续释放其对于算法模型的基础支撑价值。
海天瑞声为全球科技企业提供数据服务
海天瑞声主要从事AI训练数据的研发设计、生产及销售业务。公司通过设计数据集结构、组织数据采集、对取得的原料数据进行加工,最终形成可供AI算法模型训练使用的专业数据集,通过软件形式向客户交付。
自2005年成立以来,该公司始终致力于为AI产业链上的各类机构提供算法模型开发训练所需的专业数据集。经过多年发展,公司已成为人工智能基础数据服务领域具有较强国际竞争力的国内头部企业,并实现了标准化产品、定制化服务、相关应用服务全覆盖。
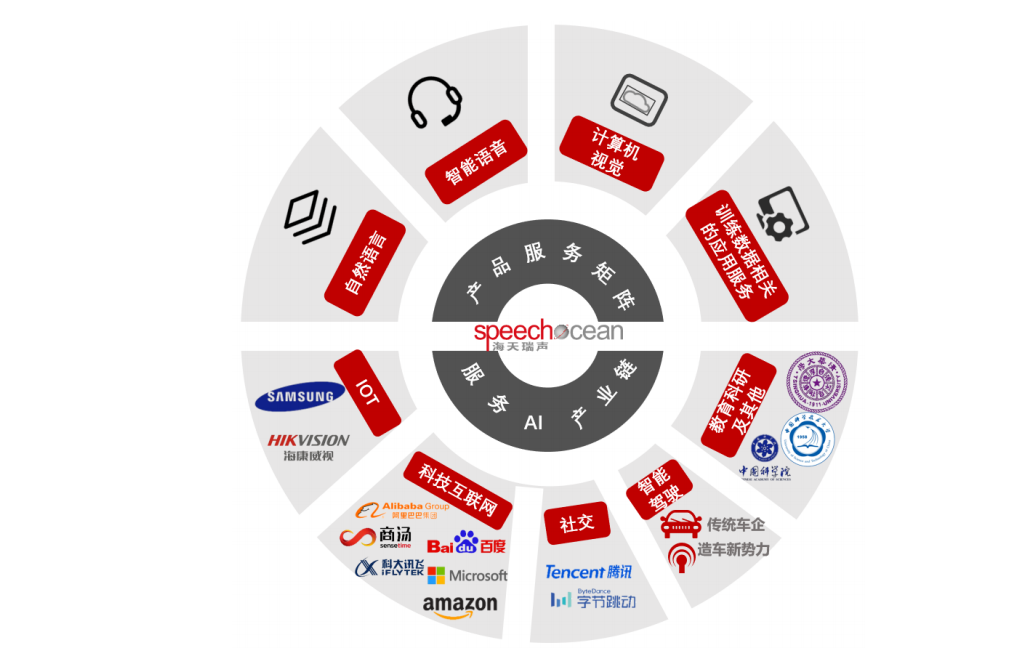
海天瑞声所提供的训练数据涵盖智能语音(语音识别、语音合成等)、计算机视觉、自然语言等多个核心领域,全面服务于人机交互、智能家居、智能驾驶、智慧金融、智能安防等多种创新应用场景。
其产品和服务已获得字节跳动、阿里巴巴、腾讯、百度、科大讯飞、海康威视、微软、 亚马逊、三星、中国科学院、清华大学等国内外客户的认可,应用于其研发的个人助手、智能音箱、语音导航、搜索服务、短视频、虚拟人、智能驾驶、机器翻译等多种产品相关的算法模型训练过程中。
目前公司客户累计数量 740 家,覆盖了科技互联网、社交、IoT、智能驾驶、智慧金融等领域的主流企业,教育科研机构以及部分政企机构。
最近由OpenAI推出的ChatGPT大火,微软也宣布将ChatGPT功能集成到公司的产品中,包括必应。海天瑞声日前表示,微软是公司的重要客户之一,公司向微软提供智能语音-训练数据定制服务及训练数据产品、自然语言-训练数据定制服务及训练数据产品、计算机视觉-训练数据定制服务及训练数据产品、训练数据相关的应用服务。
可以看到海天瑞声的业务已经遍布国内外,除了国内字节跳动、阿里巴巴、腾讯、百度等之外,海天瑞声也与多家海外知名科技企业合作,包括Microsoft、Meta、Samsung、Google等。
海天瑞声表示,相比于境内,海外市场空间更加广阔。根据IDC数据,全球AI投入约为中国AI投入的10倍以上,广阔的市场空间意味着更多的市场参与者与更加激烈的竞争环境,过往多年公司凭借在语音方面的深厚积累,尤其是多语种方面的积累和能力,获得众多境外客户认可,公司的多语种、以及OCR数据集帮助众多海外公司进行其全球化扩张。
截至目前,公司已覆盖超过190种语种/方言,不仅包括含英、法、德、意、西、日、韩等常见语种,还包括东南亚、一带一路等国家地区的罕见多语种,尤其在亚洲多语种的服务上具备独特的竞争优势。
小结
随着ChatGPT大火,预计大模型的训练和部署将会加速,而数据作为AI产业链中的一环,重要作用不可忽视。在这个领域,国内已经有一批早早入局的企业,在技术上已经具备深厚积累,这对于国内在发展大模型技术方面来说,无疑是很好的基础。
打开APP阅读更多精彩内容
AI基础数据服务市场快速增长
当前,全球基础数据服务行业正处于快速成长期,市场规模具有较大的增长空间。从AI产业链的发展情况和未来发展趋势来看,中国基础数据服务行业的市场规模也将不断扩大。
一方面,随着算法模型、技术理论和应用场景的优化和创新,AI产业对训练数据的拓展性需求和前瞻性需求均快速增长;另一方面,随着行业内对训练数据需求类型的增加以及对服务标准要求的提高,产业链的专业化分工将愈加清晰,专业化的训练数据服务提供商将扮演更加重要的角色。
根据IDC预测,2025年中国人工智能市场规模有望达到184.3亿美元(约1200亿人民币)。其中,关于基础数据部分,预计中国AI基础数据服务市场规模近5年来的复合年增长率达到47%,预期2025年将突破120亿元,达到中国人工智能市场支出总额的约10%。
在当前技术发展进程中,深度学习算法是推动人工智能技术取得突破性发展的关键技术理论,而大量训练数据的训练支撑则是深度学习算法实现的基础。训练数据越多、越完整、质量越高,模型推断的结论越可靠。因此,要使算法模型实现从技术理论到应用实践的落地过程,就需要提供大量的训练数据,对算法模型加以训练。
2021年,全球人工智能和机器学习领域最权威的学者之一吴恩达教授提出二八定律:AI研究80%的工作应该放在数据准备上,确保数据质量是最重要的工作。
然而,从自然数据源简单收集取得的原料数据并不能直接用于有监督的深度学习算法训练, 必须经过专业化的采集、加工,形成相应的工程化训练数据集后才能供深度学习算法等训练使用。目前,应用有监督学习的算法对于训练数据的需求远大于现有的标注效率和投入预算,基础数据服务将持续释放其对于算法模型的基础支撑价值。
海天瑞声为全球科技企业提供数据服务
海天瑞声主要从事AI训练数据的研发设计、生产及销售业务。公司通过设计数据集结构、组织数据采集、对取得的原料数据进行加工,最终形成可供AI算法模型训练使用的专业数据集,通过软件形式向客户交付。
自2005年成立以来,该公司始终致力于为AI产业链上的各类机构提供算法模型开发训练所需的专业数据集。经过多年发展,公司已成为人工智能基础数据服务领域具有较强国际竞争力的国内头部企业,并实现了标准化产品、定制化服务、相关应用服务全覆盖。
海天瑞声所提供的训练数据涵盖智能语音(语音识别、语音合成等)、计算机视觉、自然语言等多个核心领域,全面服务于人机交互、智能家居、智能驾驶、智慧金融、智能安防等多种创新应用场景。
其产品和服务已获得字节跳动、阿里巴巴、腾讯、百度、科大讯飞、海康威视、微软、 亚马逊、三星、中国科学院、清华大学等国内外客户的认可,应用于其研发的个人助手、智能音箱、语音导航、搜索服务、短视频、虚拟人、智能驾驶、机器翻译等多种产品相关的算法模型训练过程中。
目前公司客户累计数量 740 家,覆盖了科技互联网、社交、IoT、智能驾驶、智慧金融等领域的主流企业,教育科研机构以及部分政企机构。
最近由OpenAI推出的ChatGPT大火,微软也宣布将ChatGPT功能集成到公司的产品中,包括必应。海天瑞声日前表示,微软是公司的重要客户之一,公司向微软提供智能语音-训练数据定制服务及训练数据产品、自然语言-训练数据定制服务及训练数据产品、计算机视觉-训练数据定制服务及训练数据产品、训练数据相关的应用服务。
可以看到海天瑞声的业务已经遍布国内外,除了国内字节跳动、阿里巴巴、腾讯、百度等之外,海天瑞声也与多家海外知名科技企业合作,包括Microsoft、Meta、Samsung、Google等。
海天瑞声表示,相比于境内,海外市场空间更加广阔。根据IDC数据,全球AI投入约为中国AI投入的10倍以上,广阔的市场空间意味着更多的市场参与者与更加激烈的竞争环境,过往多年公司凭借在语音方面的深厚积累,尤其是多语种方面的积累和能力,获得众多境外客户认可,公司的多语种、以及OCR数据集帮助众多海外公司进行其全球化扩张。
截至目前,公司已覆盖超过190种语种/方言,不仅包括含英、法、德、意、西、日、韩等常见语种,还包括东南亚、一带一路等国家地区的罕见多语种,尤其在亚洲多语种的服务上具备独特的竞争优势。
小结
随着ChatGPT大火,预计大模型的训练和部署将会加速,而数据作为AI产业链中的一环,重要作用不可忽视。在这个领域,国内已经有一批早早入局的企业,在技术上已经具备深厚积累,这对于国内在发展大模型技术方面来说,无疑是很好的基础。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
-
算法模型发展的燃料,AI基础数据服务市场规模快速增长!2023-03-10 2311
-
国内AI芯片市场规模有望持续增长,预计2023年将突破千亿元2021-03-06 5660
-
物联网市场规模扩大对无线模组有哪些影响2021-02-02 5239
-
中国游戏行业市场规模快速增长,移动游戏市场表现强劲2020-12-31 2730
-
物联网将刺激大数据服务增长2020-12-25 3874
-
分析总结2020年中国电源管理芯片市场规模及发展趋势2020-07-18 7211
-
5G建设光模块市场规模预测2020-03-24 2570
-
AI芯片公司该如何在激烈的竞争中生存?2019-09-16 2719
-
中国信通院:未来五年全球AI芯片市场规模将有十倍增长2019-06-29 1211
-
我国智能控制器市场规模将快速增长2019-04-18 9520
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5906
-
智能语音产业快速发展,带动相关领域市场规模增长2018-01-30 4467
-
【亚派·趋势】2017年全球智能电网市场规模或超208亿美元2018-01-24 5225
-
2015年中国RFID行业市场规模将达373亿元2014-04-16 3716
全部0条评论

快来发表一下你的评论吧 !
