

介绍一种对标Tesla Occupancy的开源3D语义场景补全⽅法
描述
一、背景
在 2022 年的 Tesla AI Day 上, Tesla 将 Bev(鸟瞰图) 感知进⼀步升级,提出了基于 Occupancy Network 的感知⽅法。这种基于 Occupancy Grid Mapping 的表示⽅法,⼜叫体素(Voxel)占据,在 3D 重建任务中已经是一个“老熟人”了。
它将世界划分成为⼀系列 3D ⽹格单元,然后定义哪个单元被占⽤,哪个单元是空闲的,并且每个占据单元同时也包含分类信息,⽐如路⾯、⻋辆、建筑物、树⽊等。在⾃动驾驶感知中,相⽐普通的 3D 检测⽅法,这种基于体素的表示可以帮助预测更精细的异形物体。如下图 Tesla Demo 中所展示的那样,对于空间感知更精细。
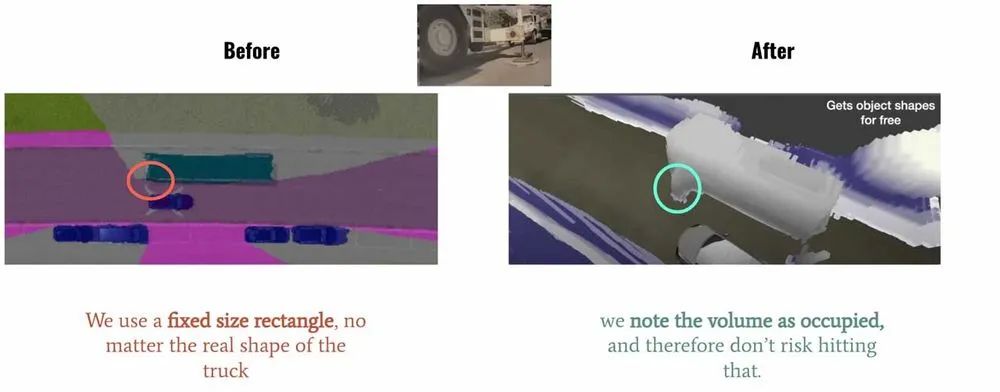
左图:使用固定的矩形框标记车辆;右图:使用体素占据来精细表示车辆
在这种在线重建的⽅法中,⼀般使⽤ SSC ( Semantic Scene Completion)任务评判预测的准确性,即利⽤图像、点云或者其他 3D 数据作为输⼊,预测空间中的体素占据和类别信息,并与 GT 标注相⽐较。在权威的⾃动驾驶 Semantic-Kitti SSC 任务中,可以根据输⼊分成纯图像和基于 3D (点云、 TSDF、体素等)的两类不同的⽅法。
使⽤纯图像⽅案恢复 3D 结构是⼀个⽐较困难的问题,旷视研究院提出了 OccDepth 的⽅法,将纯图像输⼊⽅法的精度⼤幅提升,获得了视觉⽅法的 SOTA,其中 SC IOU 从 34.2 增⻓为 45.1, mIOU 从 11.1 增⻓为15.9。同时可视化结果表明 OccDepth 可以更好地重建出近处和远处的⼏何结构。下⾯将带⼤家介绍 OccDepth 具体的⽅法。

二、任务困难和解决动机
仅从视觉图像估计场景中完整的⼏何结构和语义信息,这是⼀项具有挑战性的任务,其中准确的深度信息对于恢复 3D⼏何结构是⾄关重要的。之前的很多⼯作,都是利⽤点云、 RGBD 、TSDF[1]等其他 2.5D 、3D 形式[2-8]作为输⼊,来预测体素占据,这也需要较昂贵的设备来采集 3D 信息。基于纯图像的⽅案更便宜,同时也可以提供更为丰富且稠密场景表示, MonoScene[9]提出了纯视觉的 Baseline。但相较于上述的 3D ⽅法,在⼏何结构恢复⽅⾯,表现有⼀定的差距。
本项工作借鉴了“人类使用双眼能比单眼更好地感知3D世界中的深度信息”的思想,提出了名为 OccDepth 的语义场景补全⽅法。它分别显式和隐式地利⽤图像中含有的深度信息,以帮助恢复良好的 3D ⼏何结构。在 SemanticKITTI 和 NYUv2 等数据集上的⼤量实验表明,与当前基于纯视觉的 SSC ⽅法相⽐,我们提出的 OccDepth ⽅法均达到了 SOTA,在 SemanticKITTI 上整体实现了+4.82% mIoU 的提升,其中+2.49% mIoU 的提升来⾃隐式的深度优化,+2.33% mIoU 提升来⾃于显式的深度蒸馏。 在NYUv2 数据集上,与当前基于纯视觉的 SSC ⽅法相⽐, OccDepth 实现了+4.40% mIoU 的提升。 甚⾄相⽐于所有 2.5D 、3D 的⽅法, OccDepth 仍然实现了 +1.70% mIoU 的提升。
三、具体方法
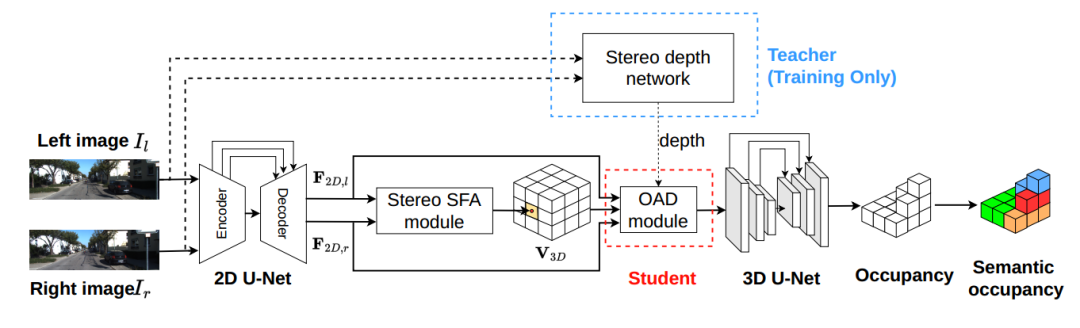
上图是 OccDepth 的主要流程。3D 场景语义补全可以根据输⼊的双⽬图像所推理出来,其中连接了⼀个双⽬特征软融合(Stereo-SFA )模块⽤于隐式地将特征提升到 3D 空间,⼀个占⽤深度感知(OAD) 模块⽤于显式地增强深度预测,后续接上 3D U-Net ⽤于提取⼏何和语义信息。其中双⽬深度⽹络仅在训练的时候使⽤,⽤蒸馏的⽅法帮助 OAD 模块提升深度预测能⼒。
双目特征软融合模块
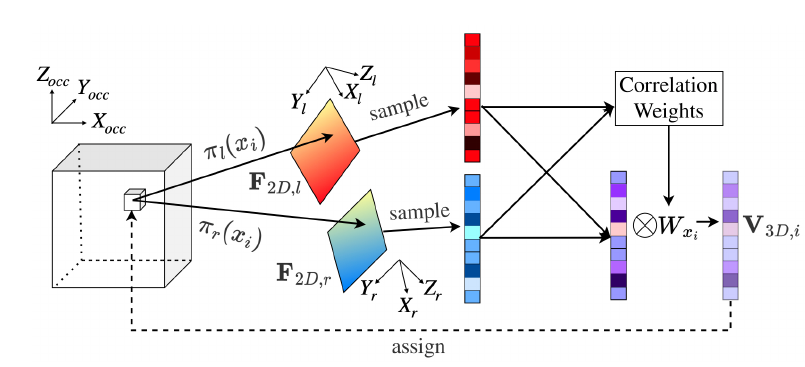

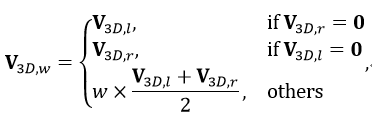

占用感知的深度蒸馏模块
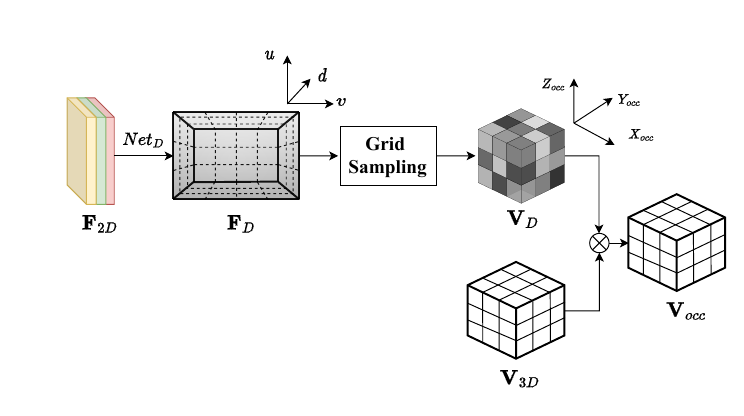

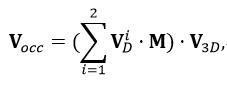

四、实验
指标对比
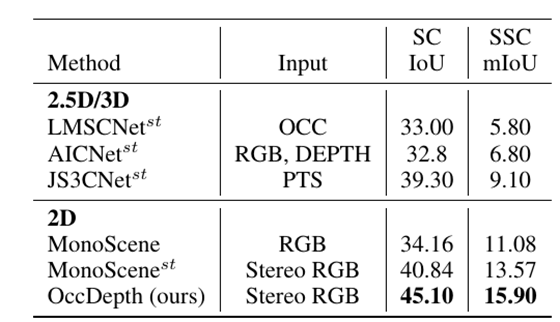

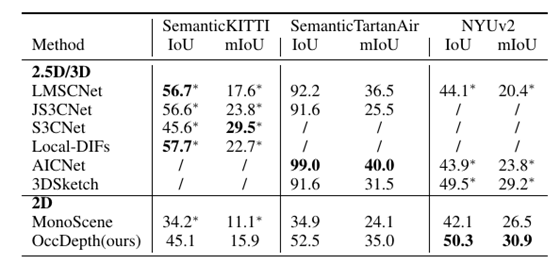
在不同数据集上和 2.5D/3D 数据作为输入的方法的对比表。OccDepth 的结果在一些室内场景上和 2.5D/3D 的方法接近甚至有所超越,在室外场景上和某些 2.5D/3D 方法相媲美。"*" 表示结果引用自 MonoScene。“/”表示缺失结果。
我们还将 OccDepth 与原始 2.5D/3D 作为输入的基础方法进行了比较,结果列在上表中。在 SemanticKITTI 数据集的隐藏测试集中,虽然 OccDepth 只使用水平视野比激光雷达( 82°vs. 180°)小得多的双目图像,但 OccDepth 取得了和使用 2.5D/3D 基础方法可比的结果 。
这个结果表明 OccDepth 具有相对较好的补全能力。在 NYUv2 的测试集中,因为没有双目图像,我们的 OccDepth 将 RGB 图像和深度图生成虚拟双目图像作为输入。结果显示, OccDepth 取得了比所有 2.5D/3D 方法更好的 mIoU 和 IoU([+0.8 IoU,+1.7 mIoU])。
在提出的仿真数据集 SemanticTartanAir 的测试集中,我们在这里使用深度真值作为这些 2.5D/3D 方法的输入,所以 2.5D/3D 方法的准确率非常高。另一方面,与 2.5D/3D 输入方法相比, OccDepth 具有较为接近的 mIoU 结果,并且 OccDepth 没有使用深度真值。与 纯视觉推理的方法相比,OccDepth 具有更高的 IoU 和 mIoU ([+17.6 IoU, +10.9 mIoU])。
定性对比
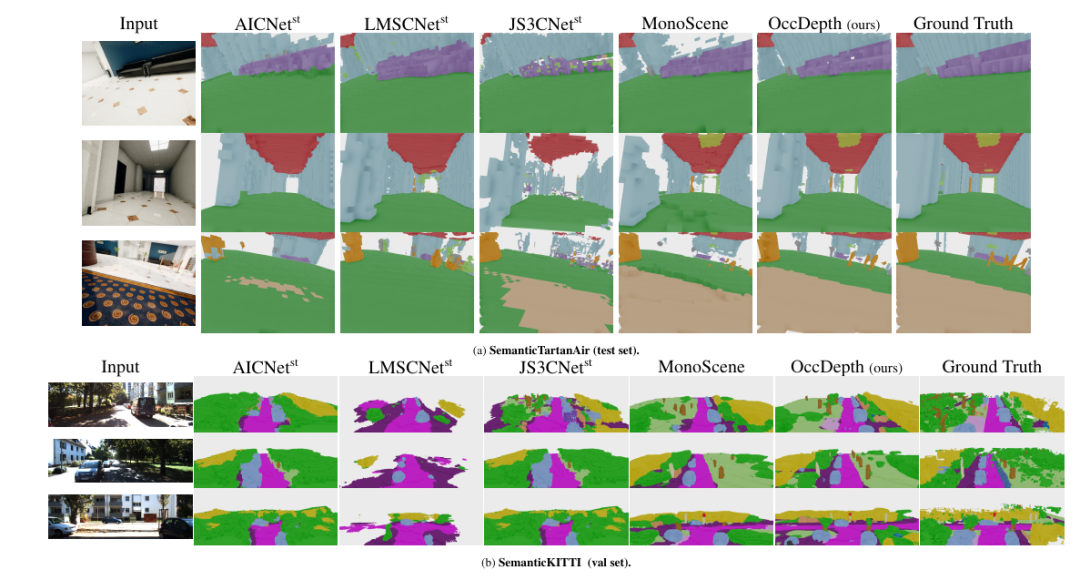
在 SemanticTartanAir 和SemanticKITTI 上的可视化结果。最左侧是输入的图像,最右侧是语义体素真值,中间为各种方法的可视化结果。这里显示了 OccDepth 在两个数据集中有较好结果场景。
在室内场景 SemanticTartanAir 数据集上,虽然所有方法都正确获得了正确的场景表示,但 OccDepth 对物体边缘具有更好的还原效果,例如沙发(图(a)的第 1 行)和天花板灯(图(a)的第 2 行) 和地毯(图(a)的第 3 行)。而在室外场景的 SemanticKITTI 数据集上,与基础方法相比,OccDepth 的空间和语义预测结果明显更好。例如,通过 OccDepth 可以实现路标(图(b)的第 1 行)、树干(图(b)的第 2 行)、车辆(图(b)的第 2 行)和道路(图(b)的第 3 行)的准确识别。
消融实验

对提出的模块进行消融实验。(a) Stereo-SFA 模块的消融实验。(b) OAD 模块中深度蒸馏数据源的消融实验。(c)OAD 模块中深度蒸馏数据源的消融实验。“w/o Depth”表示不使用深度蒸馏,Lidar depth 是指激光雷达点云生成的深度图,Stereo Depth 是指 LEAStereo 模型生成的深度图。以上实验都在 SemanticKITTI 的 08 号轨迹上进行测试。(a),(b),(c)的消融实验结果证明了提出的每个模块的有效性。
五、总结
在这项工作中,我们提出了一种有效利用深度信息的 3D 语义场景补全方法,我们将其命名为 OccDepth 。我们在 SemanticKITTI(室外场景)和 NYUv2(室内场景)数据集等公共数据集上训练了 OccDepth, 实验结果表明,本工作提出的 OccDepth 在室内场景和室外场景上都可与某些以 2.5D/3D 数据作为输入的方法相媲美。特别地是,OccDepth 在所有场景体素类别分类上都优于当前基于纯视觉推理的方法。
审核编辑:刘清
-
什么叫3D微波技术2019-07-02 1517
-
两种建立元件3D图形的方法介2019-07-12 1801
-
求一种非接触式3D指纹识别系统的设计方案2021-04-19 2050
-
如何去实现一种基于codesys平台的3d打印机设计?2021-07-05 2161
-
怎样去设计一种基于3D打印机的Delta机械臂2021-10-11 2049
-
分享一些开源3D打印创新2021-12-21 1571
-
如何使用一种形式化方法的3D虚拟祭祀场景建模语言与环境2019-01-02 1335
-
带你了解3D微波技术及其应用场景2020-07-24 1153
-
什么是3D场景式消费,新兴技术如何助力发展2020-07-08 3482
-
ThingJS平台推出3D场景本地缓存技术2021-03-13 2311
-
HarmonyOS 3D渲染引擎介绍2021-12-23 6351
-
介绍一种高效的线云重建算法ELSR2023-03-29 2422
-
3D打印底盘开源分享2023-07-06 895
-
介绍一种使用2D材料进行3D集成的新方法2024-01-13 2587
-
常见3D打印材料介绍及应用场景分析2025-12-29 1285
全部0条评论

快来发表一下你的评论吧 !
