

深入分析深度学习三维重建的网络架构和训练技巧
人工智能
描述
今天分享的是:深度学习领域基于图像的三维物体重建最新方法及未来趋势综述。原文:Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era 三维重建是计算机视觉计算机图形学和机器学习等领域几十年来一个不适定问题。从2015年开始使用CNN解决基于图像的三维重建(image-based 3D reconstruction)有了极大的关注并且展示出强大的性能。在新时代的快速发展下,我们提供了这一领域详细的调研。本文章专注于从RGB图像估计三维物体形状的深度学习方法。除此之外我们还回顾了关于特定物体(如人脸)的近期研究。我们一些重要论文性能的分析和比较,总结这一领域的现有问题并讨论未来研究的方向。
本文是深度学习做三维重建的一篇综述
对自2015年以来本领域的149个方法做详尽的回顾
深入分析深度学习三维重建的各个方面,包括训练集,网络架构选择以及重建结果,训练技巧和应用场景
总结对比了普遍的三维重建算法(88种),本文还包含了三维人脸重建算法(11种),人体形状重建算法(6种方法)
问题陈述和分类
假设 为物体的一张或多张RGB图片。三维重建可以总结为一个学习预测算子的过程,输入图像到该算子可得到一个和物体相似的模型。因此重建的目标函数为,其中为算子的参数,为重建结果和目标的距离函数,也称作深度学习中的损失函数。

如上表所示,本文依据输入数据(Input),输出的表示(Output),神经网络结构(Network architecture)和训练步骤(Training)对算法进行了分类。输入可以是单张图片,多张图片(已知/未知外参),或是视频流,即具有时间相关性的图像序列;输入也可以是描述一个或多个属于已知/未知类别的物体;还可以包括轮廓,语义标注等先验作为输入数据。输出的表示对网络结构的选择来说很重要,它影响着计算效率和重建质量,主要有三种表示方法。体积表示(Volumetric):在早期深度学习的三维重建算法中广泛采用,它可采用体素网格来参数化三维物体;这样二维卷积可以很容易扩展到三维,但是会极大消耗内存,也只有极少数方法达到亚像素精度。基于面的表示(Surface):如网格和点云,它们占用内存小,但不是规则结构,因此很难融入深度学习架构中。中间表示(Intermidiate):不直接从图像预测得到三维几何结构,而是将问题分解为连续步骤,每个步骤预测一个中间表示。实现预测算子的网络结构有很多,它的主干架构在训练和测试阶段也可能是不同的,一般由编码器h和解码器g组成,即。编码器将输入映射到称为特征向量或代码的隐变量x中,使用一系列的卷积和池化操作,然后是全连接层。解码器也称为生成器,通过使用全连接层或反卷积网络(卷积和上采样操作的序列,也称为上卷积)将特征向量解码为所需输出。前者适用于三维点云等非结构化输出,后者则用于重建体积网格或参数化表面。虽然网络的架构和它的组成模块很重要,但是算法性能很大程度上取决于它们的训练方式。本文将从三方面介绍。数据集:目前有多种数据集用于深度学习三维重建,一些是真实数据,一些是计算机图形生成的。损失函数:损失函数很大程度上影响着重建质量,同时反映了监督学习的程度。训练步骤和监督程度:有些方法需要用相应的三维模型标注真实的图像,获得这些图像的成本非常高;有些方法则依赖于真实数据和合成数据的组合;另一些则通过利用容易获得的监督信号的损失函数来避免完全的三维监督。以下为这些方面的详细介绍
编码阶段
基于深度学习的三维重建将输入图像编码为特征向量,其中为隐空间。一个好的映射方程应该满足一下性质。
表示相似物体的两张图像映射在隐空间应彼此相似
的一个小的扰动应与输入形状小的扰动对应
由h引起的潜在表示应和外界因素无关,如相机位姿
三维模型及其对应的二维图像应映射在隐空间的同一点上,这确保表示的特征不模糊,从而有助于重建
前两个条件可以通过使用编码器解决,编码器将输入映射到离散或者连续的隐空间,它可以是平面的或层次的。第三个条件可以通过分离表示解决,最后一个在训练阶段通过使用TL架构(将在training章节中讲)来解决。
离散隐空间Wu在他们的开创性工作[3]中引入了3D ShapeNet,这是一种编码网络,它将表示大小为的离散体积网格的三维模型映射到大小4000×1的向量表示中。其核心网络由3个卷积层(每个卷积层使用3D卷积滤波器)和3个全连接层组成。这种标准的普通架构已经被用于三维形状分类和检索,并用于从以体素网格表示的深度图中进行三维重建。将输入图像映射到隐空间的2D编码网络有着与3D ShapeNet相似的网络架构,但使用2D卷积,代表工作有[4],[5],[6],[7],[8],[9],[10]和[11]。早期的工作在使用的网络层的类型和数量上有所不同,包括池化层和激活函数有所不同。
连续隐空间使用前一小节中介绍的编码器,隐空间可能不是连续的,因此它不允许简单的插值。换句话说,如果并且,则不能保证可以解码为有效的3D形状。此外,的小扰动也不会对应于输入的小扰动。变分自编码器(VAE)及其3D扩展(3D-VAE)具有一个让它们适合生成建模的独特的特性:通过设计,它们的隐空间是连续的,允许采样和插值。其关键思想是,它不是将输入映射到特征向量,而是映射到多变量高斯分布的平均向量和标准差向量。然后,采样层获取这两个向量,并通过从高斯分布随机采样生成特征向量,该特征向量将用作随后解码阶段的输入。这样的思想用于为体积表示([17],[18]),深度表示([19]),表面表示([20]),以及点云表示([21],[22])的三维重建算法学习连续隐空间。3D-VAE可以对在训练阶段没有见过的图片重建出不错结果。
层次隐空间Liu[18]表明,将输入映射到单个潜在表示(向量表示)的编码器不能提取丰富的结构,因此可能导致模糊的重建。为提高重建质量,Liu引入了更复杂的内部变量结构,其具体目标是鼓励对潜在特征检测器的分层排列进行学习。该方法从一个全局隐变量层开始,该层被硬连接到一组局部隐变量层,每个隐变量层的任务是表示一个级别的特征抽象。跳跃连接以自上而下的定向方式将隐编码(向量)连接在一起:接近输入的局部代码将倾向于表示较低级别的特征,而远离输入的局部代码将倾向于表示较高级别的特征。最后,当输入到特定于任务的模型(如三维重建)中时,将局部隐编码连接到扁平结构。
分离表示一张图像中物体的外观受多个因素的影响,例如对象的形状、相机位姿和照明条件。标准编码器用经过学习的编码表示所有这些变量。这在诸如识别和分类之类的应用中是不可取的,这些应用应该对诸如位姿和照明之类的外部因素保持不变。三维重建也可以受益于分离式表示,其中形状、位姿和灯光用不同的编码表示。为了达到这一目的,Grant等[5]提出一个编码器,可以将RGB图像映射为一个形状编码和一个位姿变换编码。它们将会分别解码为三维形状与光线条件位姿。此外,Zhu等人[24]使用相似的思想,将6DOF的位姿参数和三维模型解耦。这样减少网络中的参数,提高了效率。
体积解码
体积表示将三维物体离散化成三维体素栅格。离散化的越精细,模型也表示的更准确。解码的目标就是输入图像,恢复出栅格,使得三维形状近似真实的三维物体。使用体积栅格表示的优点是很多为二维图像分析设计的深度学习框架可以很简单地扩展到三维数据(三维卷积与池化)。下面分别介绍不同体积表示方式,低精度解码器架构以及高精度三维重建。下表为各种体积解码器的分类: 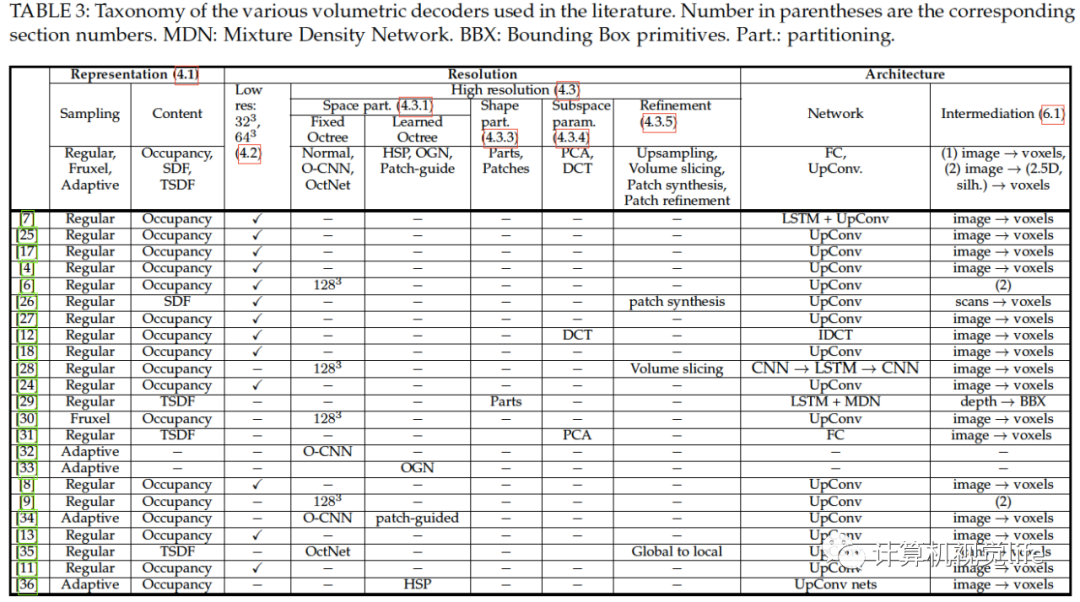 三维形状的体积表示在文献中主要有四种体积表示方法:
三维形状的体积表示在文献中主要有四种体积表示方法:
二元占用栅格(Binary occupancy grid)。在这种表示中,物体的体素被设为1,没有物体占用的体素设为0。
概率占用栅格(Probabilistic occupancy grid)。在概率占用栅格中的每个体素编码了它属于物体的概率。
符号距离函数(SDF-The Signed Distance Function)。每个体素编码了到最近表面的距离。体素在物体内距离为负,在外距离为正。
截断符号距离函数(TSDF-Truncated Signed Distance Function)。首先估计距离传感器的视线方向上的距离,形成一个有符号的投影距离场,然后在较小的负值和正值处截断该场。
概率占用栅格尤其适合输出为似然概率的机器学习算法。符号距离函数可提供表面位姿和法向量方向的无歧义的估计。然而它们很难从部分数据(如深度图)构建。截断距离符号函数牺牲了使用完整的距离域,但是允许基于局部观测来局部更新。他们适合从一组深度图中重建三维体积。
低精度三维体积重建
一旦通过编码器学习到输入的向量表示,下一步就是学习解码算子,也叫做生成器或生成模型,它把向量表示映射成体积体素栅格。方法普遍使用卷积反卷积网络。Wu等人[3]是最先用这种方法从深度图重建三维体积的。Wu等人[6]提出一个叫做MarrNet的两阶段三维重建网络。第一阶段输入图片、得到深度图、法向量图和轮廓图,这三个称作2.5简图。然后再输入另一对编码器解码器回归出三维体积模型。这个工作在后来被Sun等人[9]发展出也回归输入的位姿。这三类图更容易从二维图片中恢复,但很难重建出复杂精细的结构。Wu等人的工作[3]也有很多其他扩展,如[7],[8],[17],[27],[40]。尤其是近期的工作如[8],[11],[13],[18]不用中间表示回归出三维体素栅格。
高精度三维体积重建
有方法为高精度体积重建设计深度学习架构。例如,Wu等人[6]的工作可以重建出大小为的体素栅格。但是栅格精度越高,其存储会随着三次方增长,因此体积栅格表示消耗大量内存。我们把基于算法是否使用空间划分,形状划分,子空间参数化,或是由粗到精的优化策略分为四类。
空间划分 虽然体积栅格利于卷积操作,但是它很稀疏因为物体表面只在很少的体素内。一些论文用这个稀疏性解决分辨率问题,如[32],[33],[41],[42]。它们可以通过使用空间划分的方法(如八叉树)重建出到的三维体素栅格。使用八叉树做基于深度学习的三维重建有两个问题。一个是内存和计算密集,第二点是八叉树的结构是和物体有关的,因此深度神经网络需要学习如何推断八叉树的结构以及它的内容。下面是两个问题的解决方案。一是使用预先定义的八叉树结构,即假设运行时八叉树的结构是已知的。然而这在很多情况下八叉树的结构是未知的且必须要预测。Riegler等[41]提出一种混合的栅格-八叉树结构叫做OctNet,它限制八叉树的最大深度为一个小的数字,并在一个栅格上放几个这样的八叉树。二是学习八叉树的结构:同时估计出八叉树的结构和内容。首先输入编码为一个特征向量。然后反卷积解码得到粗糙的输入的体积重建。将这个构建好的基分割成八份,包含边界体素的部分通过反卷积实现上采样以及后续处理,改善重建的区域。不断递归知直到达到期待的精度。
占用网络 虽然空间划分方法可以减少内存消耗,但是很难实现并且现有的算法建出的体素栅格也比较小(到)。最近一些论文提出用神经网络学习三维模型的隐式表示,如[43]和[44]。
形状划分 除了在空间上划分三维模型,还可以考虑把形状作为几何部分来分配,独立地重建出各个部分,再组合起来构成完整的三维模型。[42]和[29]使用了这样的思想。
子空间参数化 所有可能形状的空间可以使用一组正交基参数化。每一个形状可以由基的线性组合表示,即。这个简化了重建问题。不用学习如何重建体积栅格,取而代之的是设计一个由全连接层构成的解码器去从隐层表示估计参数,恢复出完整的三维模型。可参考文献[12]。
由粗到细优化 另一个提高体积表示三维重建算法分辨率的方法是使用多阶段的方法,如[26],[28],[35],[45],[46]。第一阶段用编码器和解码器恢复出低精度体素栅格()。接下来的阶段作用为上采样网络在局部地方改善重建模型。
深度立方体匹配 尽管体积表示适应于任意拓扑的三维模型,但它需要一个后处理步骤,即立方体匹配(marching cubes)[49],获得实际的三维网格。这样,整个过程不可以端到端地训练,为此Liao等人提出[50]一个可端到端训练的网络深度立方体匹配,可以预测出任意拓扑的显式表面表示。
三维表面解码
基于体积表示的重建算法浪费大量计算资源,因为信息只在三维物体表面附近丰富。基于表面的重建(mesh,点云)主要挑战是他们不是均匀的结构,因此它们很难放在深度学习框架。这一章节把基于表面重建算法分为三类:基于参数的,基于模版变形的,以及基于点的方法。前两类为基于网格的解码器,下表为它的分类。 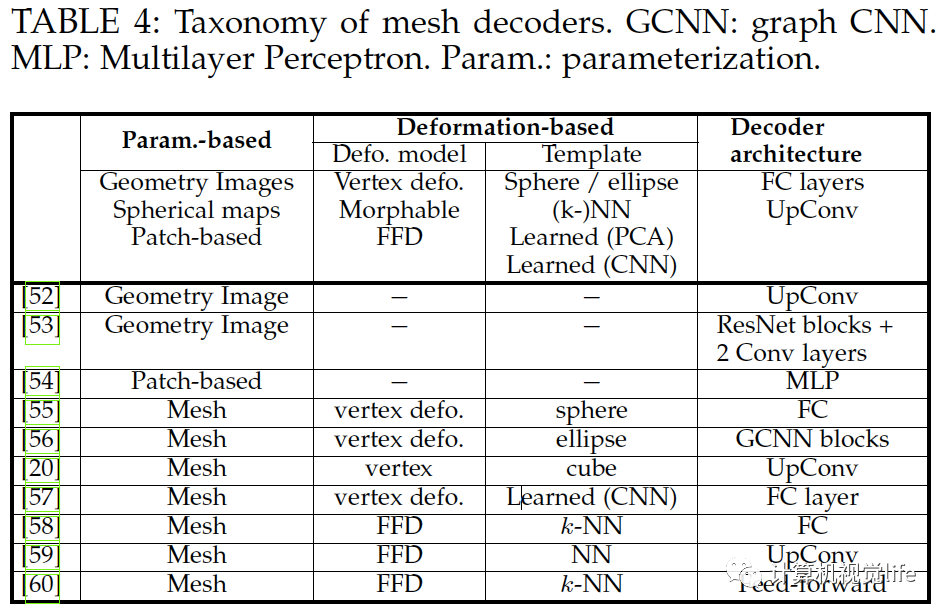
基于参数的三维建模(Parameterization-based 3D reconstruction)
我们可以用一个映射,其中为一个正则参数域。三维建模的目标是从输入中恢复出形状的函数。当为三维域内时,重建算法就是上一节的体积重建。本节取为二维域内参数,它可以是一个二维空间平面的子集。球形参数和几何图像[62],[63]和[64]为最常用的参数化方法,但它们只适合0形(genus-0)和近似圆盘的表面,任意拓扑的表面需要分成像圆盘的几部分,然后展开成一个二维域。这样它适合重建属于同一类外形的物体重建,如人脸和躯干。
基于形变的三维重建(Deformation-based 3D reconstruction)
这类算法输入图像然后估计一个形变域,当运用在一个三维模版模型上时,就得到重建好的三维模型。现有的算法在形变模型的使用,模板定义的方式,以及用于估计形变域的网络架构上有所不同。我们假设三维模型由n个顶点和表面组成。定义为一个模板形状。
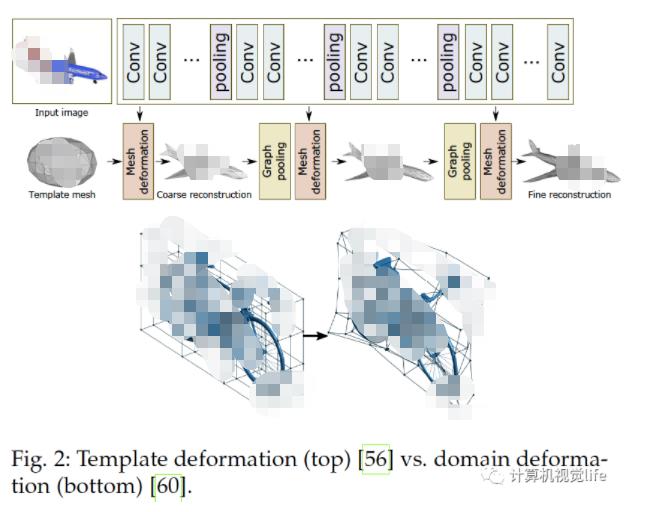
形变模型:大致分三种。一是顶点形变:假设三维模型可以写作模版独立顶点的线形组合,这个形变域定义为,该形变模型如上图的上半部分所示,假设了物体和模版的顶点一一对应且有相似的拓扑结构,[55],[56],[57]用了该模型。二是可渐变模型:假设为平均形状, 为一组正交基,任何形状可以表达为,它的第二项可以视为形变域,算法[68],[69],[70]使用了该模型。三为自由式形变(FFD):除了对模版顶点形变,还可以如上图下半部分所示对附近空间形变,它被用于[58],[59],[60],它的优点是不需要顶点一对一的对应。
定义模版:Kato等人[55]用球形做模板,Wang等人[56]使用椭圆,Henderson等人[20]定义两种模板。为了加速收敛,Kuryenkov等人[59]提出DeformNet,可以输入一张图片,在数据库找到最近临形状再用FFD形变。其他定义模板方法如[70],[57]。
网络架构 基于形变的算法也使用编码器解码器架构。编码器使用连续卷积操作把输入映射到隐空间,解码器通常使用全连接层估计形变域,用球形匹配输入轮廓。[59]如之前所述,在数据库找到相似模板,这个模板首先体素化,用三维CNN编码到隐空间表示,再通过反卷积解码到定义在体素栅格顶点的FFD域,相似的算法还有[60]。
基于点的算法(Point-based techniques)
一个三维模型可以由一组无序的N个点表示。基于点的表示简单但消耗内存小从而较有效。很多论文如[72],[21],[22],[73],[74],[75],[76],[77],[79],[80],[81],[82]等使用点云重建。 点的表示 点云的主要问题是它们没有规则的结构因此很难用于探索空间特征的神经网络。应对这种局限有三种方法解决。一是用点云集表示把点云当作的矩阵,如[21],[22],[72],[75],[77],[81]。二是使用一个或多个大小为的三通道栅格,如[72],[73],[82]。每一个栅格内的像素编码了三维点的坐标。三是用多视角得到的深度图,如[78],[83]。后两种解决方法可称为栅格表示,适合用于卷积网络,同时计算上也有效率因为它们可以只用二维卷积来预测。 网络架构 和体积与基于表面表示的算法一样,基于点表示的算法也使用编码器解码器模型,如下图所示,它们使用解码器的种类和架构不同。 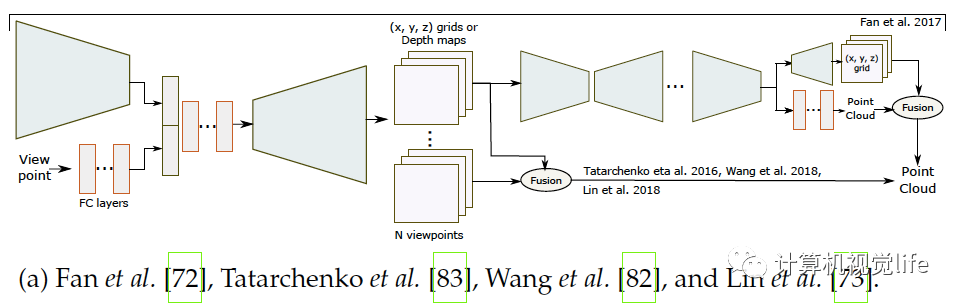
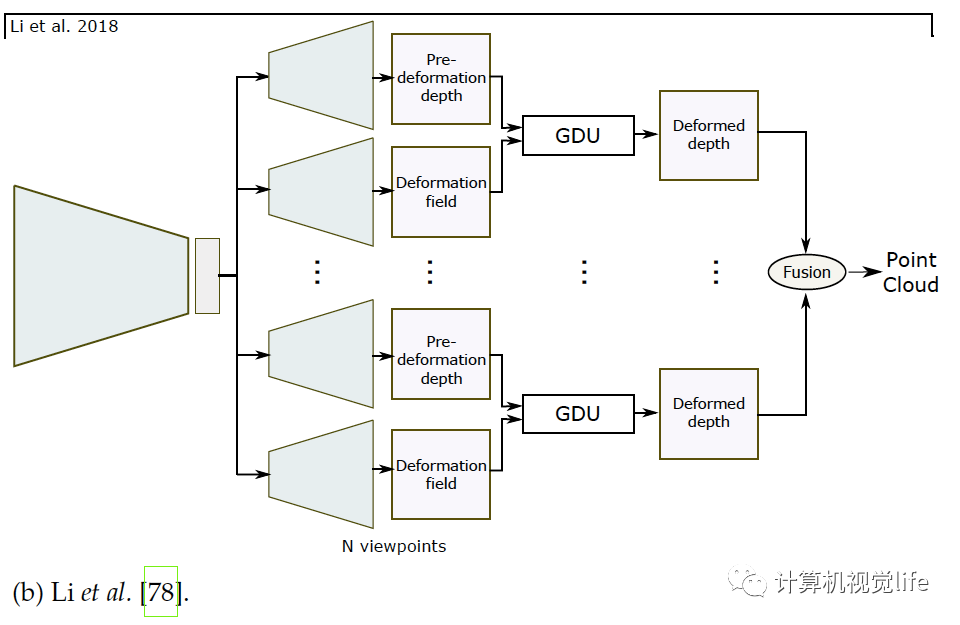
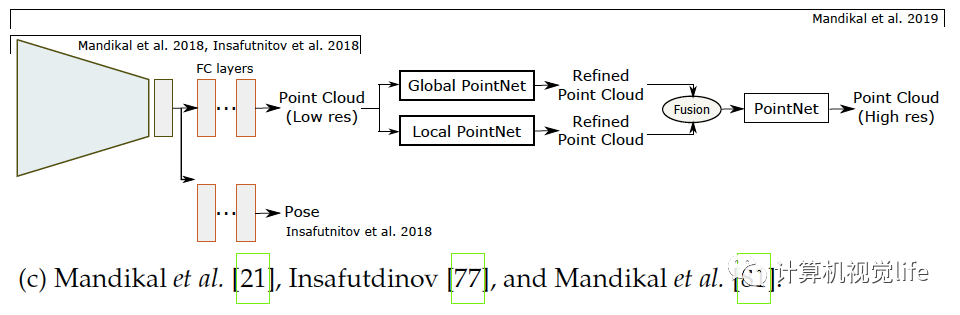
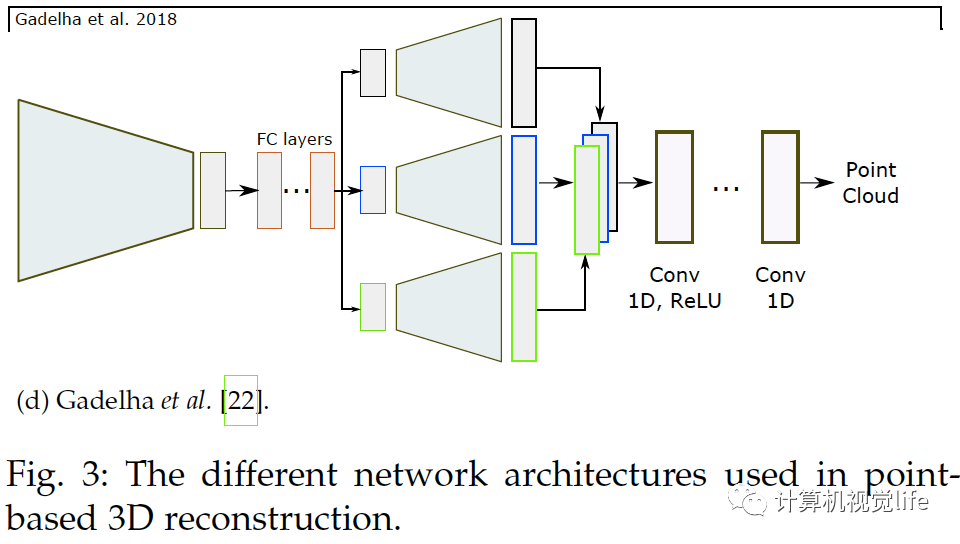
如上图(a)和(b),普遍栅格表示使用反卷积网络解码隐空间变量[72],[73],[78],[82]。基于点集的表示如(c)所示使用全连接层[21],[72],[74],[77],[81],因为点云是无序的。使用全连接层的主要优点是它可以捕捉全局信息。然而和卷积操作相比计算量较大。为了高效的卷积计算,Gadelha等人用空间划分空间排序点云(如KD树)然后用一维卷积处理它们,如上图(d),他们为了一起利用全局和局部信息,把隐空间变量解码为三个不同的分辨率,把它们连接起来再用卷积层处理生成点云。Fan等人提出[72]生成深度网络结合了点集表示和栅格表示,上图(a)。网络结构由几个级联的编码器-解码器组成。[74]和它类似,区别在于训练过程。和基于体积重建的算法类似,基于点的三维重建普遍也只恢复出低精度几何结构。对于高精度重建,Mandikal等人[81]如上图(c)所示,使用级联的多个网络结构:第一个网络预测低精度点云,之后的每个模块输入之前预测的点云,利用类似于PointNet[87]和PointNet++[88]的多层感受结构(MLP)去计算全局特征,在每个点周围MLP计算局部特征。局部和全局特征合在一起送进另一个MLP预测出稠密点云。这个过程可以不断重复直到得到需要的分辨率。Mandikal等人[21]还结合TL架构和变分自动编码器。基于点云表示的算法可以处理任意拓扑的三维物体。但是它们需要一个后处理步骤,例如泊松表面重建[89]或者SSD[90]来提取需要的三维表面网格。整个过程不能端到端训练。因此,这些方法只优化一个定义在中间表示的辅助损失函数。
利用其他信息重建
之前章节讨论了直接从二维观测重建三维物体。本节介绍其他额外信息(如中间表示和时间关系)如何用来帮助三维重建。
中间表示
一些方法把三维重建问题分解为几步,首先估计2.5维的信息,例如深度图,法向图或语义分割的区块,最后再用传统的方法(如空间分割或三维反向投影)再滤波,数据关联,恢复出完整的三维几何结构及输入的位姿。早期算法对不同模块单独训练,而如今的工作提出了端到端的解决方案如[6],[9],[38],[53],[80],[91],[92]。还有的算法从预先定义或任意的视角估计多个深度图,再利用深度图得到重建结果,如[83],[19],[73],[93]。[83],[73]和[9]除了深度图还估计出了轮廓图。使用多阶段方法的优点是深度图,向量图和轮廓图更容易从二维图像恢复出。从这三个恢复出三维模型要比单独直接从二维图像中恢复三维模型要更简单。 时空关系 有时候可以获取到从不同角度对同一物体拍摄的照片。基于单张图片的重建算法可以用来处理单帧得到三维建模,再通过配准合成完整模型。比较理想的是,我们可以利用图片间的时空关系来解决歧义,尤其是在遮挡以及特别杂乱的场景。也就是说,cnn在t时刻应该知道t-1时刻重建了什么,使用它以及新时刻的输入来重建t时刻的物体或场景。处理这样连续时刻数据已经使用RNN和LSTM解决,它们可以使网络记住一段时间内的输入。Choy等人提出[7]叫做3D循环重建网络(3D-R2N2),它可以从不同视角的信息学习物体的三维表示。这个算法让神经网络记住看过的图片并在输入新图片时更新存储,这可以解决物体自我遮挡问题。LSTM和CNN比较耗时并且RNN在输入图片输入顺序变化时不能再估计物体形状,为了解决这样问题,Xie等人提出[86]叫做Pix2Vox,由并行的多个编码器解码器组成。
训练
除了网络结构,深度学习网络也依赖它们训练的方法。本节讨论文献中使用的不同监督模式和训练步骤。
监督的程度 早期算法依赖于三维监督。然而不管是手动还是用传统三维重建算法来获取三维数据的真值都比较困难。因此最近一些算法尝试通过其他监督信号例如一致性通过列表最小化三维监督程度。
三维监督的训练:训练时需要有三维真值,损失函数最小化重建的三维形状与真值之间的差异,有体积损失函数,点集损失函数,N个重建的最小损失函数(MoN)。
二维监督的训练:相对三维来说获取2D或2.5D的视角更加容易,损失函数为真实的视角与重建物体的投影之间的差异。这需要定义估计的三维模型投影的计算子以及重投影误差方程。重投影误差方程主要有基于轮廓的损失函数,基于表面向量和深度的损失函数,或者结合二维与三维损失函数。
视频监督训练 另一个降低监督程度的方法是使用运动代替三维监督。为此,Novotni等人提出[100]使用运动估计结构(SFM)从视频生成监督信号:在训练阶段用视频序列生成部分点云和相对的相机参数。误差函数为网络训练的深度图和SFM得到的深度图的差异。在测试时,这个网络就可以直接从RGB图像恢复出三维几何结构。 训练步骤 除了数据集,损失函数和监督程度,还有一些训练神经网络做三维重建的实践经验。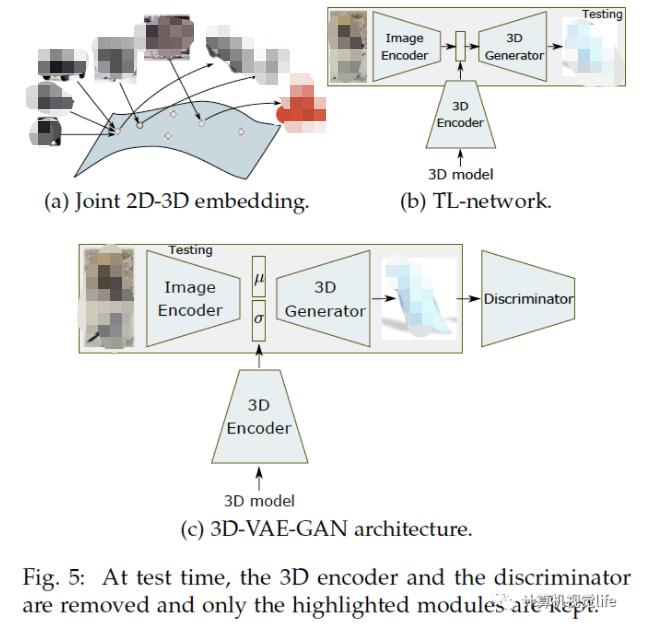
联合二维与三维:如上图(a)和(b),TL-embedding网络一起训练编码:有二维编码器和三维编码器。它们分别把二维图像和它的三维标注映射到隐空间的同一个点。[25],[79],[21]用这样的方法训练网络。
对抗训练:通常步骤训练的可能结果在没见过的数据上重建效果不好。Yang等人[46],[103]开始用生成对抗网络(GAN)训练。GAN的潜力很大,因为它们可以模仿任何分布的数据。在单视图重建方面它们已用于体积重建[13],[17],[30],[40],[46],[103]以及基于点云的重建[74],[75]。三维监督的有[17],[30],[40],[46],[103],二维监督的有[13],[27],[97]。GAN很难训练,对于高精度的模型很不稳定,因此要平衡生成器和分辨器的学习,否则梯度会消失。
和其他任务联合训练:联合训练重建与分割会让它们互相促进。如Mandikal等人[107]的方法。
应用和特殊案例
很多应用处理特定类别的物体如人的身体部位(脸和手等),野外的动物和汽车。使用这些物体类别的先验知识可以显著提高重建质量。
三维人体重建 虚拟的(数字的)人在很多应用如游戏,视觉体验影片中很重要,一些算法可以轻量地只从几个RGB图像中恢复出人体形状和位姿。有基于体积表示的,也有基于模板或参数表示的算法。一些算法只重建出人体模型[108],[109],还有算法也重建出了衣服[110],[111]。基于参数的算法主要把问题转化为不同的统计模型,三维人体模型估计就变为模型参数估计。主要模型有SCAPE[108],[109],[115]和SMPL[110],[116],[117],[118],[119]。基于体积的方法直接推断占用栅格,在之前章节描述的基于体积的方法可直接用于人体重建[121],[122]。
三维人脸重建 大多数方法使用参数表示来重建,广泛使用的是Blanz和Vetter提出的[68]三维形变模型(3DMM)。该模型从几何和纹理的角度捕捉面部的变化。Gerig等人[124]通过将表情作为单独的空间扩展了这个方法。
三维场景解析 除了单独的物体重建,场景解析问题在于遮挡,聚类,形状和位姿的不确定还需要估计场景布局。该问题结局方案涉及到三维物体检测和识别,位姿估计和三维重建。主要方法有[136],[138]。
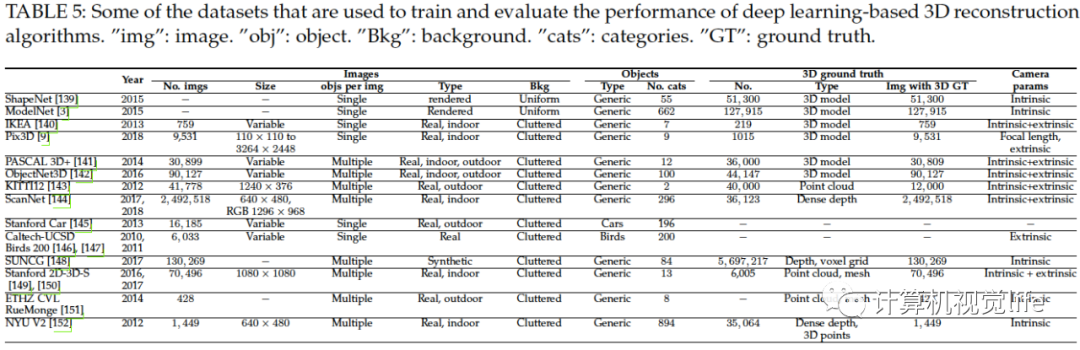
数据集
下面表格列出并总结了普遍使用的数据集的属性。基于深度学习的三维重建需要特别大的训练数据集,监督学习还需要对应的三维标注,弱监督和无监督学习依赖外界监督信号如相机内外参。下表为一些数据集的信息。
性能对比
本节讨论一些关键算法的性能,下面介绍各种性能的标准和度量,并讨论和比较一些算法的性能。
精度指标和性能标准 设为真实三维形状,为重建结果。 精度指标: ·均方误差(MSE):重建结果和真值的对称表面距离 这里和分别是和的采样点数量,是p到沿垂直方向到的距离,如L1和L2,距离越小,重建越好。 ·交并比(IoU):IoU测量重建预测出的形状体积与真实体积的交集与两个体积的并集的比率 其中是指示函数,是第i个体素的预测值,是真值,是阈值。IoU值越高,重建效果越好,这一指标适用于体积重建。因此,在处理基于曲面的表示时,需要对重建的和真实的三维模型进行体素化。 ·交叉熵损失的均值:熵的均值越低,重建效果越好。 ·搬土距离(EMD)和倒角距离(Chamfer Distance) 性能标准: ·三维监督程度:基于深度学习的三维重建算法的一个重要方面是训练时三维监督的程度。事实上,虽然获取RGB图像很容易,但获取其相应的真实3D数据却相当具有挑战性。因此,在训练过程中,与那些需要真实三维信息的算法相比,通常更倾向于需要较少或不需要三维监督的技术。 ·计算时间:虽然训练时间慢,通常希望可以达到实时表现。 ·内存占用:神经网络需要大量参数。一些算法在体积上使用三维卷积,这样就会消耗大量内存,会影响实时性能限制它们的应用范围。
比较和讨论 下图展示了过去四年重建算法精度的改进。
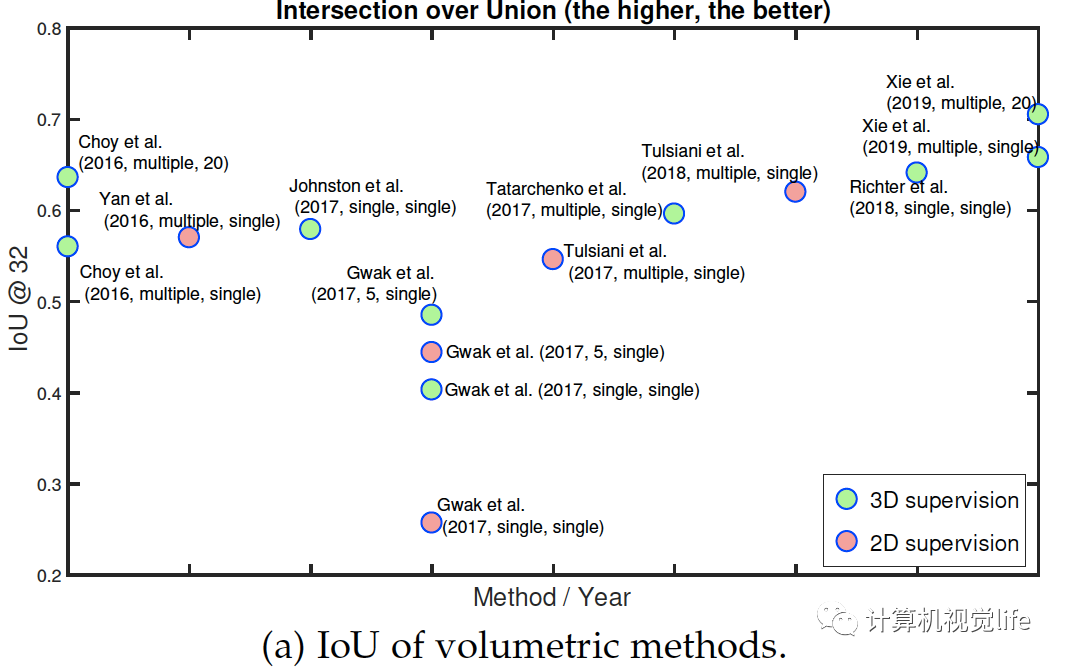
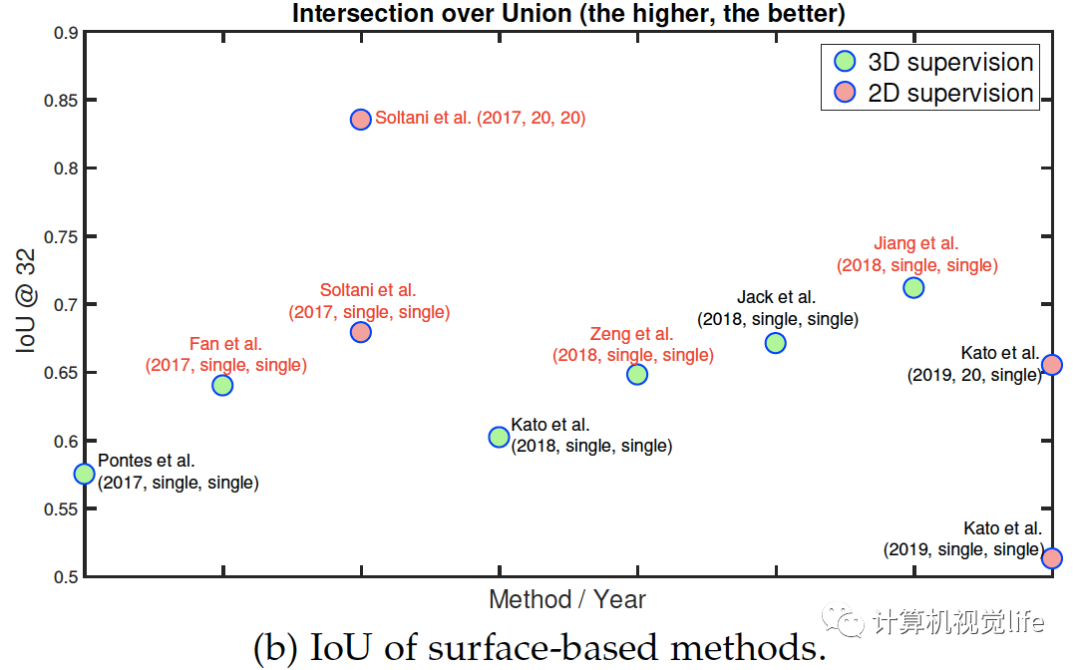
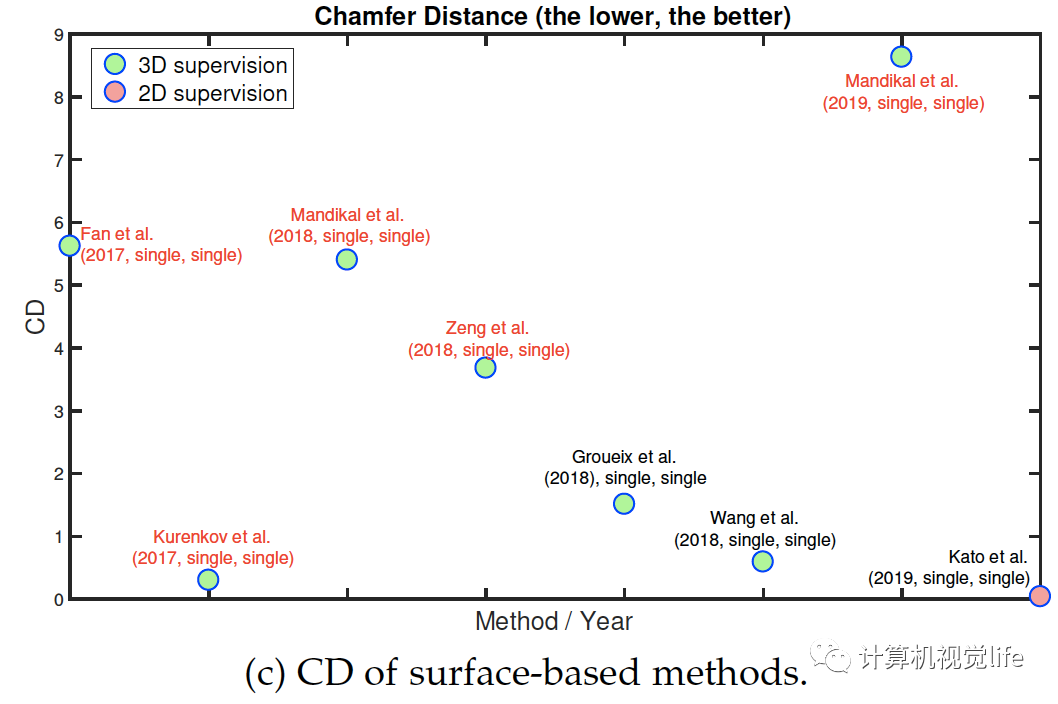
Fig. 6: Performance of some key methods on the ShapeNet dataset. References highlighted in red are point-based. The IoU is computed on grids of size . The label next to each circle is encoded as follow: First author et al. (year, n at training, n at test), where n is the number of input images. 早期的研究大多用体素化表示,这样可以表示任意拓扑复杂物体的表面和内部细节。随着O-CNN,OGN和OctNet等空间分割技术提出,体积表示的算法可以达到相对较高的分辨率,例如。这是由于内存效率的显著提高。然而只有很少论文采用这些方法因为它们的实现比较复杂。为了实现高分辨率的三维体积重建,最近的许多论文都使用了中间表示,通过多个深度图,然后进行体积或基于点的融合。最近有几篇论文开始关注学习连续的有符号距离函数的机制或连续占用网格,这些机制在内存需求方面要求较低。它们的优点是,由于它们学习了一个连续的场,因此可以在所需的分辨率下提取重建的三维物体。图片显示出自2016年以来,使用ShapeNet数据集作为基准的几年来性能的演变。在大小为的体积栅格上计算的IoU度量上,我们可以看到在训练和测试时使用多个视图的方法优于仅基于单个视图的方法。此外,2017年开始出现的基于表面的重建算法略优于体积算法。图片还可看出2017年基于二维监督的算法出现后,性能越来越高。(a)和(b)两图看出基于三维监督的算法性能稍微更好。论文中表6为一些有代表性的算法的性能,见文尾原文的参考链接。
未来研究方向
在过去五年的大量研究中,使用深度学习进行基于图像的三维重建取得了很好的效果。然而这一课题仍在初级阶段,有待进一步发展。这一节介绍一些当前的问题,并强调未来研究的方向。
训练数据问题。深度学习技术的成功在很大程度上取决于训练数据的可用性,不幸的是,与用于分类和识别等任务的训练数据集相比,包含图像及其3D注释的公开数据集的大小很小。二维监督技术被用来解决缺乏三维训练数据的问题。然而,它们中的许多依赖于基于轮廓的监督,因此只能重建视觉外壳。因此,期望在未来看到更多的论文提出新的大规模数据集、利用各种视觉线索的新的弱监督和无监督方法,以及新的领域适应技术,其中使用来自某个领域的数据训练的网络(例如,合成渲染图像)适应新的领域。研究能够缩小真实图像和综合渲染图像之间差距的渲染技术,可能有助于解决训练数据问题。
对看不见的物体的一般化。大多数最新的论文将数据集分成三个子集进行训练、验证和测试,例如ShapeNet或Pix3D,然后测试子集的性能。但是,还不清楚这些方法如何在完全不可见的对象/图像类别上执行。实际上,三维重建方法的最终目标是能够从任意图像中重建任意三维形状。然而,基于学习的技术仅在训练集覆盖的图像和对象上表现良好。
精细的三维重建。目前最先进的技术能够恢复形状的粗糙三维结构,虽然最近的工作通过使用细化模块显著提高了重建的分辨率,但仍然无法恢复植物、头发和毛皮等细小的部分。
重建与识别。图像三维重建是一个不适定问题。因此,有效的解决方案需要结合低层次的图像线索、结构知识和高层次的对象理解。如Tatarchenko[44]最近的论文所述,基于深度学习的重建方法偏向于识别和检索。因此,他们中的许多人没有很好地概括,无法恢复精细的尺度细节。期望在未来看到更多关于如何将自顶向下的方法(即识别、分类和检索)与自下而上的方法(即基于几何和光度线索的像素级重建)相结合的研究,这也有可能提高方法的泛化能力。
专业实例重建。期望在未来看到特定于类的知识建模和基于深度学习的三维重建之间的更多协同作用,以便利用特定于领域的知识。事实上,人们对重建方法越来越感兴趣,这些方法专门用于特定类别的物体,如人体和身体部位、车辆、动物、树木和建筑物。专门的方法利用先前和特定领域的知识来优化网络体系结构及其训练过程。因此,它们通常比一般框架表现得更好。然而,与基于深度学习的三维重建类似,建模先验知识需要三维注释,这对于许多类型的形状(例如野生动物)来说是不容易获得的。
在有遮挡和杂乱背景的情况下处理多个对象。大多数最先进的技术处理包含单个对象的图像。然而,在野生图像中,包含不同类别的多个对象。以前的工作采用检测,然后在感兴趣的区域内重建。然而,这些任务是相互关联的,如果共同解决,可以从中受益。为实现这一目标,应处理两个重要问题。一是缺乏多目标重建的训练数据。其次,设计合适的CNN结构、损失函数和学习方法是非常重要的,特别是对于没有3D监督的训练方法。这些方法通常使用基于轮廓的损失函数,需要精确的对象级分割。
3D视频。本文研究的是一幅或多幅图像的三维重建,但没有时间相关性,而人们对三维视频越来越感兴趣,即对连续帧具有时间相关性的整个视频流进行三维重建。一方面,帧序列的可用性可以改善重建,因为可以利用后续帧中可用的附加信息来消除歧义并细化当前帧处的重建。另一方面,重建的图像在帧间应该平滑一致。
走向全三维场景解析。最后,最终目标是能够从一个或多个图像中语义分析完整的3D场景。这需要联合检测、识别和重建。它还需要捕获和建模对象之间和对象部分之间的空间关系和交互。虽然在过去有一些尝试来解决这个问题,但它们大多局限于室内场景,对组成场景的对象的几何和位置有很强的假设。
总结和评论
这篇论文综述了近五年来利用深度学习技术进行基于图像的三维物体重建的研究进展,将顶级的算法分为基于体积、基于表面和基于点的算法。然后,根据它们的输入、网络体系结构和它们使用的训练机制讨论了每个类别中的方法,还讨论并比较了一些关键方法的性能。该调研重点是将三维重建定义为从一个或多个RGB图像中恢复对象的三维几何体的问题的方法。然而,还有许多其他相关问题也有类似的解决办法。包括RGB图像的深度重建[153]、三维形状补全[26],[28],[45],[103],[156],[160],[161],深度图像的三维重建[103]、新视角合成[164],[165]和三维形状结构恢复[10],[29],[83],[96]等等。在过去五年中,这些主题已被广泛调查,需要单独的总结论文。
编辑:黄飞
-
通过深度学习的图像三维物体重建研究方案2023-02-13 1329
-
怎样去设计一种基于RGB-D相机的三维重建无序抓取系统?2021-07-02 2111
-
如何去开发一款基于RGB-D相机与机械臂的三维重建无序抓取系统2021-09-08 2248
-
无人机三维建模的信息2021-09-16 2225
-
基于FPGA的医学图像三维重建系统设计与实现2011-03-15 1322
-
深度学习时代的来为基于图像的三维重建提供了新的可能2019-08-02 7041
-
透明物体的三维重建研究综述2021-04-21 1235
-
基于分布式传感的实时三维重建系统2021-06-25 1003
-
基于图像的三维物体重建:在深度学习时代的最新技术和趋势综述之训练2022-01-26 1029
-
NVIDIA Omniverse平台助力三维重建服务协同发展2022-10-13 2495
-
深度学习背景下的图像三维重建技术进展综述2023-01-09 4258
-
如何使用纯格雷码进行三维重建?2023-01-13 2329
-
三维重建:从入门到入土2023-03-03 2364
-
如何实现整个三维重建过程2023-09-01 2847
-
基于光学成像的物体三维重建技术研究2023-09-15 2018
全部0条评论

快来发表一下你的评论吧 !
