

昆仑芯科技资深架构师侯珏:昆仑芯×飞桨——AI产业实践与“芯”生态
描述
近日,“算网筑基、开源启智、AI赋能”第四届OpenI/O启智开发者大会于深圳成功举行。大会围绕中国算力网资源基座、开源社区服务支撑环境、国家级开放创新应用平台三大部分,探讨如何高效建设适合我国的人工智能开源生态体系。
会上,百度飞桨联合大会,围绕“引领前沿技术,推动产业升级”的主题,举办“深度学习与大模型产业应用专场”论坛。
作为飞桨的生态合作伙伴,昆仑芯科技受邀参与该论坛并进行主题演讲,与多位人工智能技术专家和资深工程师,从算法、硬件及大模型等不同视角进行深入探讨,介绍各领域深度学习及大模型在产业应用的最新进展与技术突破。

昆仑芯科技资深架构师 侯珏
本篇以下内容整理于昆仑芯科技资深架构师侯珏题为《昆仑芯×飞桨——AI产业实践与“芯”生态》演讲实录。
大家好,我是来自昆仑芯科技的侯珏。很高兴有这个机会跟大家交流和分享。我分享的题目是《昆仑芯×飞桨——AI产业实践与“芯”生态》。本次主题演讲分为四个方面:
1. 关于昆仑芯科技
2. 昆仑芯x飞桨生态
3. 大模型:训练和推理
4. AI产业实践
01
关于昆仑芯科技
昆仑芯科技前身是百度智能芯片及架构部,2011年开始研发基于FPGA的加速器,截止2017年,FPGA系列的加速器部署数量超过12000片。2018年,我们正式启动了昆仑芯AI芯片产品的研发,发布第一代产品,2020年成功进行了大规模部署。紧接着,第二代系列产品于2021年8月成功量产,到了2022年,昆仑芯二代产品就开始启动互联网及相关行业的交付,不断有项目在落地中。

从我们十几年来的AI芯片及其相关行业的经验来看,AI芯片产业化要重点解决三个问题。我们内部一致认为,可以把三个问题称为三道窄门:一定要过的门,而且门还挺窄。
首先芯片要量产,量产是前提。只有把芯片做到量产、规模化,才能平摊前期流片、研发、设计等一系列成本。并且,一个芯片是不是能够成功量产,也是衡量芯片本身是否成熟的一个标志。
其次,有配套的软件生态。这个软件生态指的是芯片自己的软件以及周边的一些软件。显而易见,如果我们只做了一个芯片给客户,客户不知道如何使用芯片,或者说不知道芯片能够给其业务带来怎样的帮助,在市场上就没有什么竞争力。所以,我们在做软件生态时,除了做昆仑芯自己的一套软件栈,包括编译器、SDK、算子库、模型库等,还为开发者社区以及一定量的用户构建了整个的软件生态。
最后,做产品化。虽然我们说一定要成就客户,要完成具体的项目来实现我们的业务落地,但实际上更重要的是投入长期努力,把一款芯片做好,把一组芯片做好,长期地做出产品来,才能够保证我们的商业模式是可持续发展的状态。

然后介绍一下昆仑芯科技的产品。首先向大家展示的是昆仑芯二代产品系列中的R200加速卡,是一个全高全长双槽位的卡,可以进行INT8、INT16、FP16、FP32多种精度的计算。算力、内存、访存带宽等细节可参见上图表格。R200可以搭配昆仑芯软件栈,也可以搭配飞桨上层的软件栈。例如,昆仑芯可支持飞桨的深度学习框架,同时支持飞桨框架的各种相关周边套件,进行推理、训练。

大家会想,只有一张卡也许干不了什么事。因此,针对多卡并行计算的需求,我们又做了一个加速器组。大家可以买一些R200加速卡自己拼,但应该没有我们拼的好,因为我们在做加速器组时,专门做了卡片间的互联,可达200GB/s。当然,8张卡在一起,算力和显存也达到了原来的8倍。单机多卡的形式基本上可以满足最常见的单机的推理或者并行训练的需求。

有的朋友可能仍觉得不方便,为此,我们联合飞桨以及百度的全功能AI开发平台BML,做了一个开箱即用的昆仑芯软硬集成一体机。图上是一个2U的服务器,里面有面板、CPU、内存、开发平台等所有东西。此外,还集成了飞桨的稳定发布版本,以及内置了100多个各行各业的模型,真正做到了开箱即用。也就是说,从我们这买了一台2U或4U的服务器,只需要插个电线和网线,就可以用了。
02
昆仑芯×飞桨生态
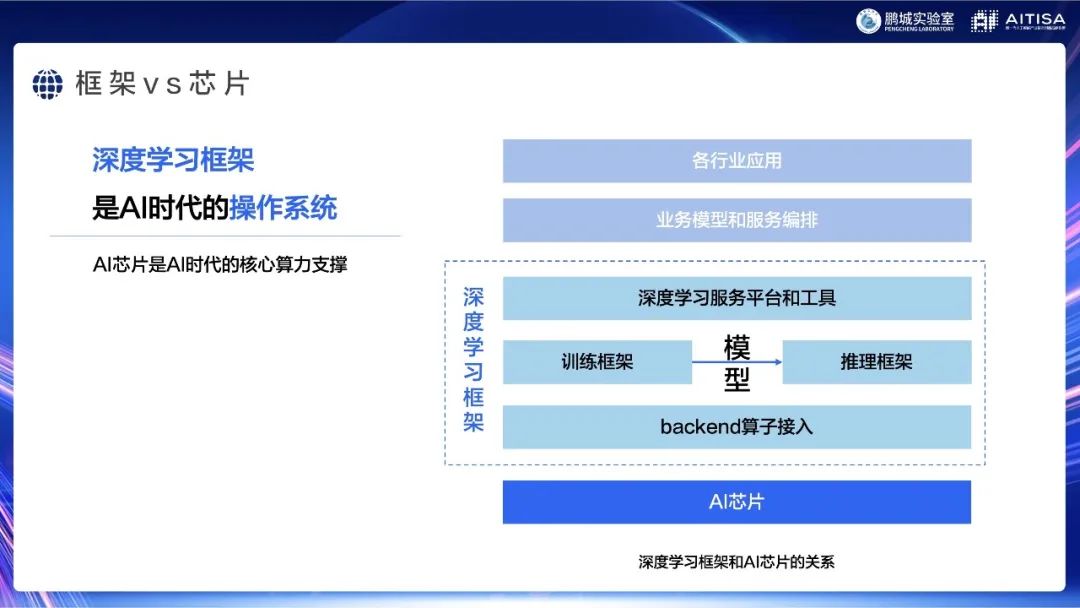
首先,我们说深度学习框架是AI时代的操作系统,AI芯片是AI时代的核心算力支撑。框架和芯片的关系大概就如图所示:框架在中间,上面是应用和服务编排,底下是芯片。大家的业务应用都需要通过业务模型和服务编排,再跑到框架,框架负责把用户的脚本、组网代码、参数、优化器等拿到。更准确的说,框架把各种神经网络层、优化算法、学习率衰减等数据拿到之后,会把实际的计算过程翻译成各个算子,下发到AI芯片上进行真正的计算,算好了之后再把结果拿回框架里,继续调下一个算子。
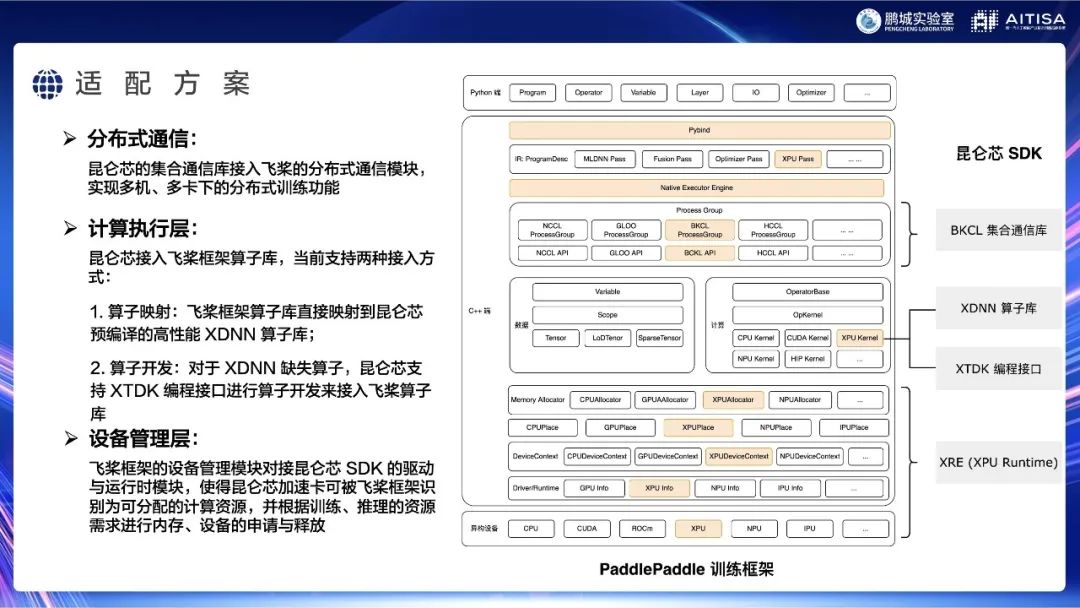
我们按照这个逻辑做了昆仑芯和飞桨的适配,原则是你要什么,我就有什么。接下来为大家介绍下重点。
首先从下往上说,最底下是设备管理层。飞桨的框架有一个设备管理模块,对接着我们提供的驱动和运行时模块,也就是昆仑芯的runtime,这样框架就能识别到我们的设备,并且往我们的设备上下发指令,包括申请内存等。
再往上是计算执行层。这一层是以飞桨的算子库为主,飞桨的算子库有大量的算子,其中很多是昆仑芯提供的,也有很多是昆仑芯与飞桨一起提供的。在昆仑芯软件栈中,有XDNN算子库和XTDK编程接口。从飞桨角度看,可以像调用其它异构计算硬件一样,把要执行的操作,通过算子调用的方式下发到设备上,也就是大家所说的:我们要launch一个kennel,然后去拿结果,在host上发起操作,在device上执行,设备内部算好了再返回给框架。有了这两件事,单机单卡所有的事都能搞定。
但大家会发现单机单卡越来越不够用,所以上面还有一个分布式通信层。昆仑芯有集合通信库(Communication library),把它和飞桨的分布式通信(fleet)模块结合起来,就可以做到通信所需要的send、receive、all_reduce等,也就可以实现单机多卡、多机多卡的训练和推理。
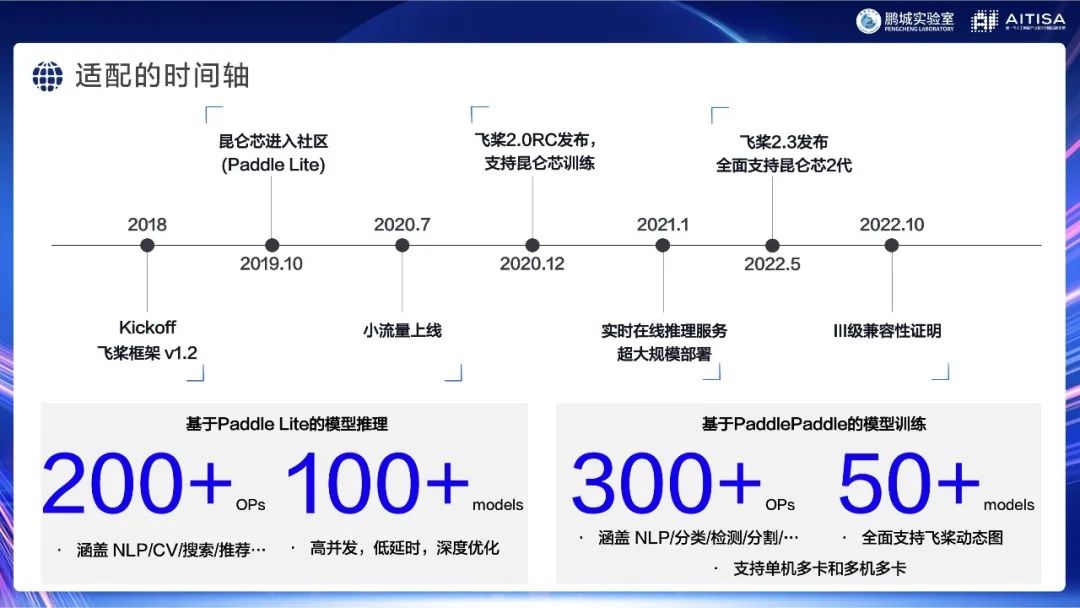
从时间轴上来看,我们跟飞桨的合作从2018开始,合作经历了从简单到困难、从推理到训练、从相对单一的场景扩展到了更复杂的场景的不同阶段。我们一共支持了大概300多个算子,还有大规模验证的50多个模型。(没准儿我正在做主题演讲的同时,昆仑芯和飞桨的QA同学又测试通过了模型,这个数儿还得往上加。)对应的流水线和单元测试我们也都有,这是稳定、正式的发布情况。此外,还有200多个小模型跑通了飞桨TIPC认证的全流程。
需要注意的是,并不是只有50多个模型可以跑,而是因为飞桨框架已经有了这个机制,万一遇到了个别很奇怪的算子,没法放在device上算,就可以自动fallback到CPU上,速度也许会慢点,但也能算。并且我们也在不断更新中,将业界最新的论文、百度各种自研的模型加入到我们的支持列表中来。
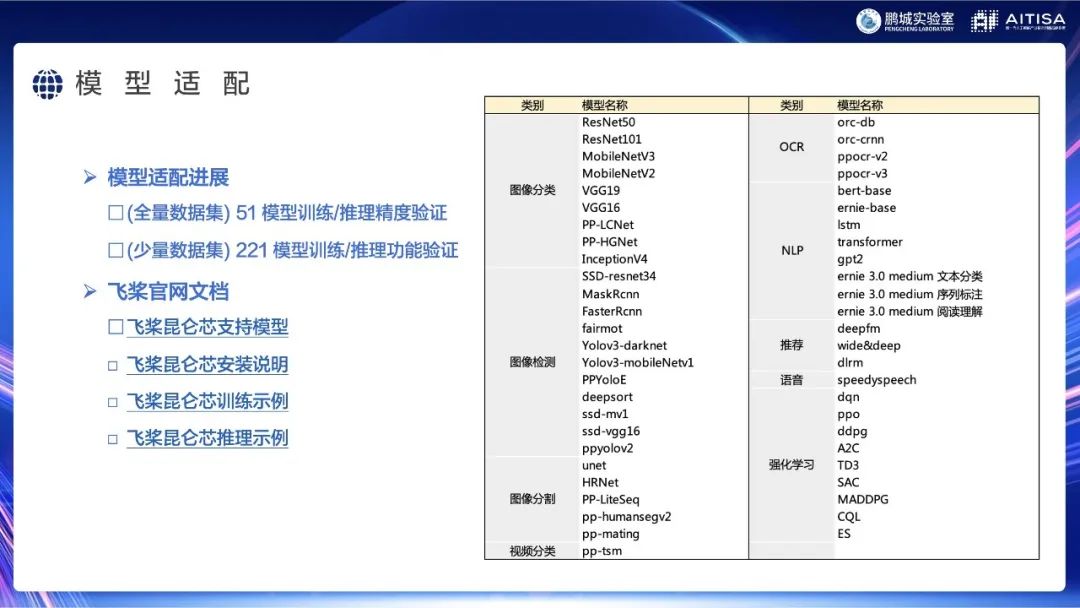
上图列出了一些我们已经适配好的模型,有图像分类、检测、分割、OCR、自然语言处理(NLP)等。其中有一些是飞桨特色的模型,例如PPYOLO、PPOCR等“PP”开头的模型。在飞桨的官方网站上也可以看到,如何使用昆仑芯进行编译、安装,运行飞桨的各种操作,可供大家参考。
03
大模型:训练和推理
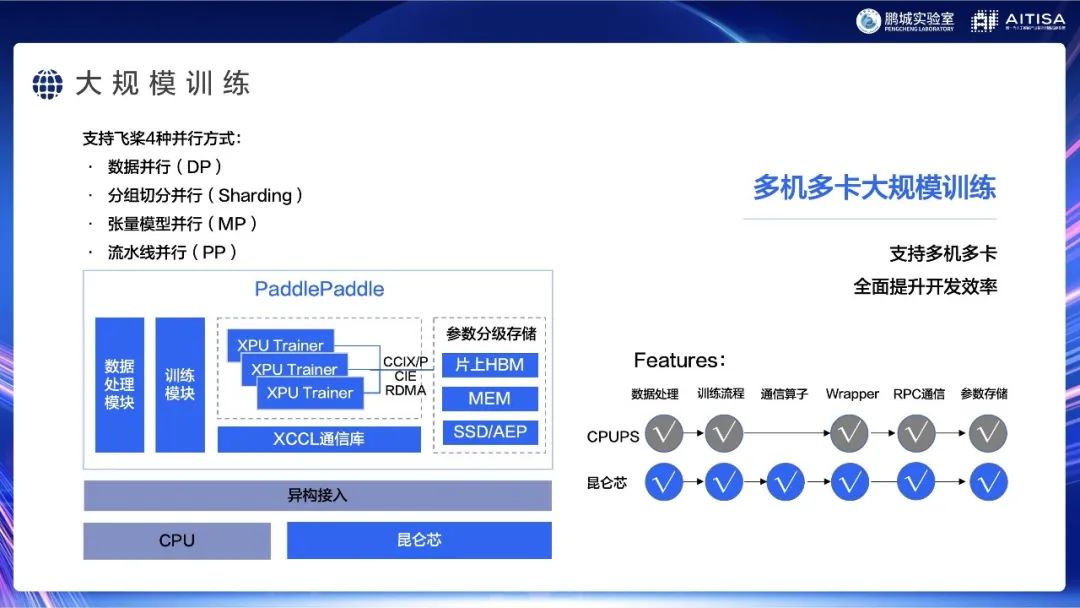
下一部分是介绍我们在大模型上专门进行的一些工作,包括训练和推理两部分。
训练部分,昆仑芯可全部支持飞桨的四种数据并行方式:数据并行(DP)、分组切分并行(Sharding)、张量模型并行(MP)、流水线并行(PP)。如果大家用飞桨运行这四种并行方式时很顺利,在用昆仑芯计算时应该也不会有什么问题,只需要把大家熟悉的set_device操作,在昆仑芯的设备上执行。原理很简单,所有飞桨需要的操作我们都可以支持,有kennel、通信算子,那么这些支持就都不是难事。
此外,我们也支持飞桨的各种套件,例如PaddleClass、PaddleDetection等。大家在用PaddleClass、PaddleDetection时,把模型配置中的yaml文件中的项目use_xpu=true打开一下即可。
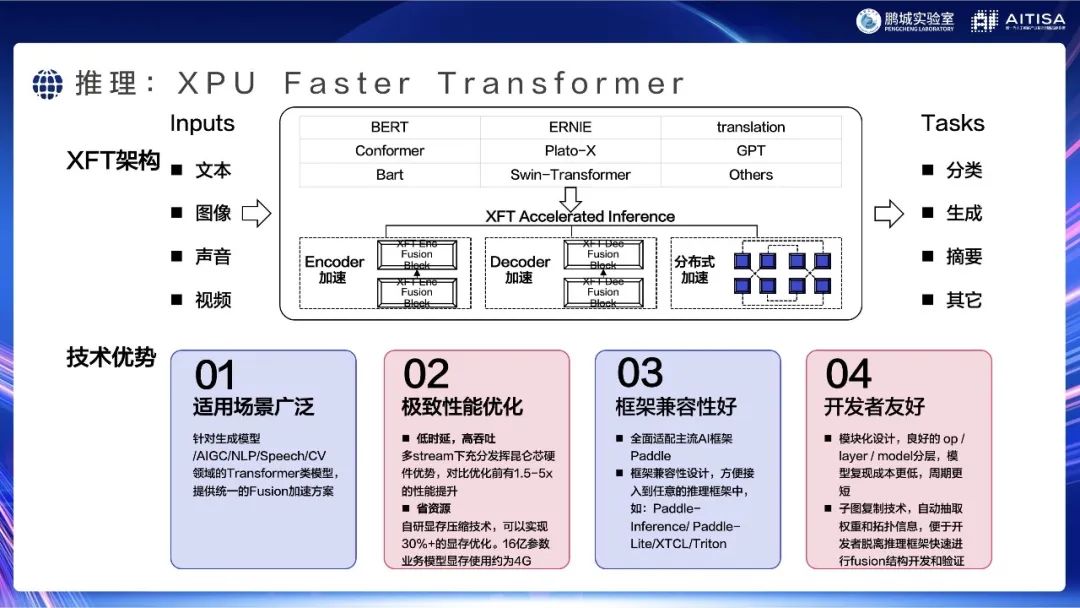
推理部分,针对Transformer,我们专门开发了XPU Faster Transformer工具,可以对算子进行fusion,在针对这些Transformer类型的网络结构时进行加速,并且可以节约很多显存。我们在上面进行了很多针对性的性能优化,使它可以在昆仑芯硬件上充分发挥优势。
04
AI产业实践
首先来看一个典型的工业质监场景。一个工业摄像机拍摄一组零件的健康状况,通过机械臂把不合格的产品踢掉。

这个原理看似是图片上那么简单,但需要做到推理、训练两件事才能实现。例如要有机构硬件、深度学习平台、推理引擎、Serving、模型训练等等,这些事情做完后就可以拿到一个高效率、高速度的工业质检流水线。
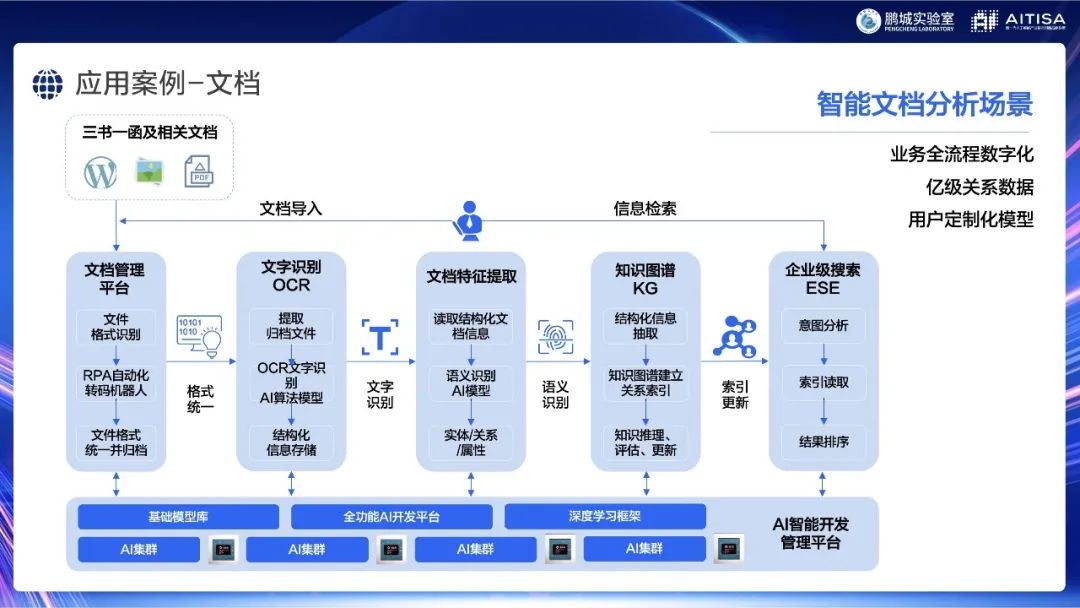
还有一个文档相关的案例。可能有法律界或相关行业的朋友知道“三书一函”。首先需要对文档进行分析、导入,包括文字识别、语义分析、语义理解,做成一个知识图谱并保存,就可以进行完整的检测和语义分析,最后拿到结果排序,实现了业务全流程的数字化,同时支持用户的自定义模型。
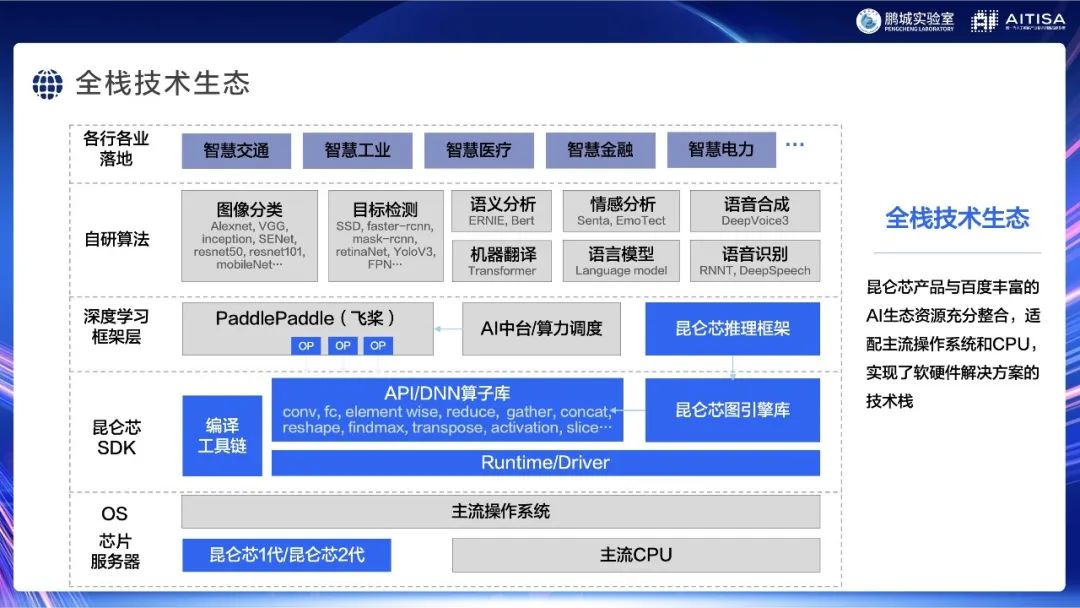
昆仑芯落地案例丰富,前面两个案例是选择的比较通俗易懂的进行讲解。上图是一个全栈的技术生态图景,从底层的芯片、服务器,到中间的昆仑芯SDK,再到飞桨框架,我们就可以帮助大家把业务目标落地。
本次主题分享的题目是“芯”生态,“芯”是“芯片”的“芯”,也是“昆仑芯”的“芯”。我希望昆仑芯和飞桨,以及一系列上层应用,可以在各行各业发挥出力量,从芯片、框架到算法,从软件到硬件,持续做大做强,和各位开发者、客户一起互相促进、互相成就、共同进步。
最后,非常感谢大家的聆听,欢迎大家访问昆仑芯科技的官网。
-
昆仑芯科技与浪潮信息签署元脑战略合作协议2022-07-07 2175
-
昆仑芯2代AI芯片为开发者提供灵活便捷的部署方案2022-10-11 2714
-
昆仑芯AI芯片以AI算力服务实体经济 筑底算力经济新基建2022-10-19 4044
-
昆仑芯科技产业级AI模型部署全攻略2022-12-28 3026
-
昆仑芯新品R100正式发布,强大算力赋能边缘推理场景2022-12-29 4706
-
昆仑芯2代AI芯片荣获「2022年度AI生产力创新奖」2023-02-03 1887
-
昆仑芯完成OpenCloudOS社区首个兼容性认证,软硬协同加速AI技术落地2023-02-16 2196
-
昆仑芯科技 × OpenI/O启智开发者大会看点多多2023-02-24 1096
-
生态合作再度升级!昆仑芯已入驻飞桨AI Studio硬件生态专区2023-08-18 3810
-
昆仑芯科技携手生态伙伴领跑大模型产业落地2023-09-08 2740
-
国芯科技与昆仑芯签订战略合作协议2023-09-13 1930
-
介绍一款基于昆仑芯AI加速卡的高效模型推理部署框架2023-10-17 3585
-
昆仑芯率先完成Deepseek训练推理全版本适配2025-02-06 2659
-
昆仑芯服务器中标招商银行AI芯片资源项目2025-03-28 2919
-
昆仑芯科技亮相2026亚布力中国企业家论坛并发表主题演讲2026-03-24 496
全部0条评论

快来发表一下你的评论吧 !
