

20个机器学习自动化库介绍
人工智能
描述
AutoML是指自动机器学习。它说明了如何在组织和教育水平上自动化机器学习的端到端过程。机器学习模型基本上包括以下步骤:
数据读取和合并,使其可供使用。
数据预处理是指数据清理和数据整理。
优化功能和模型选择过程的位置。
将其应用于应用程序以预测准确的值。
最初,所有这些步骤都是手动完成的。但是现在随着AutoML的出现,这些步骤可以实现自动化。AutoML当前分为三类:
用于自动参数调整的AutoML(相对基本的类型)
用于非深度学习的AutoML,例如AutoSKlearn。此类型主要应用于数据预处理,自动特征分析,自动特征检测,自动特征选择和自动模型选择。
用于深度学习/神经网络的AutoML,包括NAS和ENAS以及用于框架的Auto-Keras。
为什么需要AutoML?
机器学习的需求日益增长。组织已经在应用程序级别采用了机器学习。仍在进行许多改进,并且仍然有许多公司正在努力为机器学习模型的部署提供更好的解决方案。
为了进行部署,企业需要有一个经验丰富的数据科学家团队,他们期望高薪。即使企业确实拥有优秀的团队,通常也需要更多的经验而不是AI知识来决定哪种模型最适合企业。机器学习在各种应用中的成功导致对机器学习系统的需求越来越高。即使对于非专家也应该易于使用。AutoML倾向于在ML管道中自动执行尽可能多的步骤,并以最少的人力保持良好的模型性能。
AutoML三大优点:
它通过自动化最重复的任务来提高效率。这使数据科学家可以将更多的时间投入到问题上,而不是模型上。
自动化的ML管道还有助于避免由手工作业引起的潜在错误。
AutoML是朝着机器学习民主化迈出的一大步,它使每个人都可以使用ML功能。
让我们看看以不同的编程语言提供的一些最常见的AutoML库:
以下是用Python实现
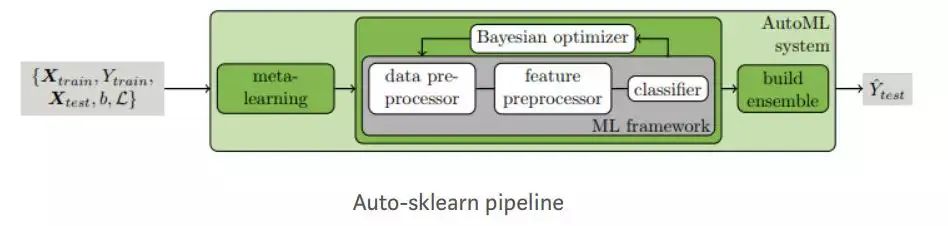
auto-sklearn
图片
auto-sklearn是一种自动机器学习工具包,是scikit-learn估计器的直接替代品。Auto-SKLearn将机器学习用户从算法选择和超参数调整中解放出来。它包括功能设计方法,例如一站式,数字功能标准化和PCA。该模型使用SKLearn估计器来处理分类和回归问题。Auto-SKLearn创建管道并使用贝叶斯搜索来优化该渠道。在ML框架中,通过贝叶斯推理为超参数调整添加了两个组件:元学习用于使用贝叶斯初始化优化器,并在优化过程中评估配置的自动集合构造。
Auto-SKLearn在中小型数据集上表现良好,但无法生成在大型数据集中具有最先进性能的现代深度学习系统。
例子
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
import autosklearn.regression
def main():
X, y = sklearn.datasets.load_boston(return_X_y=True)
feature_types = (['numerical'] * 3) + ['categorical'] + (['numerical'] * 9)
X_train, X_test, y_train, y_test =
sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.regression.AutoSklearnRegressor(
time_left_for_this_task=120,
per_run_time_limit=30,
tmp_folder='/tmp/autosklearn_regression_example_tmp',
output_folder='/tmp/autosklearn_regression_example_out',
)
automl.fit(X_train, y_train, dataset_name='boston',
feat_type=feature_types)
print(automl.show_models())
predictions = automl.predict(X_test)
print("R2 score:", sklearn.metrics.r2_score(y_test, predictions))
if __name__ == '__main__':
main()
FeatureTools
它是用于自动功能工程的python库。
安装
用pip安装
python -m pip install featuretools
或通过conda上的Conda-forge频道:
conda install -c conda-forge featuretools
附加组件
我们可以运行以下命令单独安装或全部安装附件
python -m pip install featuretools[complete]
更新检查器—接收有关FeatureTools新版本的自动通知
python -m pip install featuretools[update_checker]
TSFresh基本体-在Featuretools中使用tsfresh中的60多个基本体
python -m pip install featuretools[tsfresh]
例
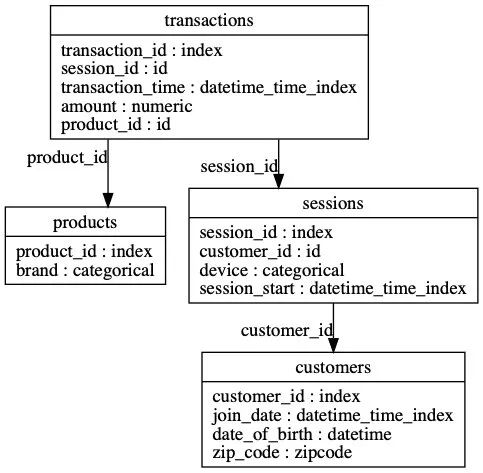
import featuretools as ft
es = ft.demo.load_mock_customer(return_entityset=True)
es.plot()
图片
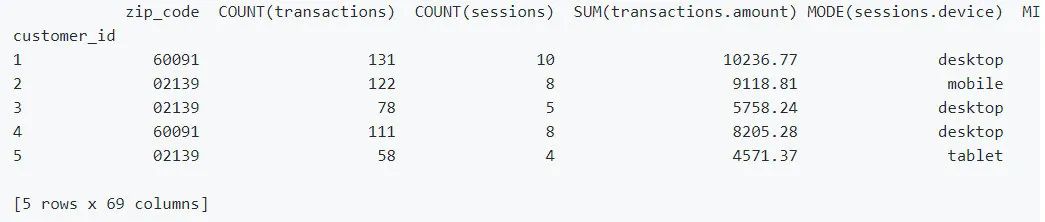
Featuretools可以为任何"目标实体"自动创建一个特征表
feature_matrix, features_defs = ft.dfs(entityset=es,
target_entity="customers")
feature_matrix.head(5)
图片
MLBox
MLBox是功能强大的自动化机器学习python库。
根据官方文档,它具有以下功能:
快速读取和分布式数据预处理/清理/格式化
高度强大的功能选择和泄漏检测以及精确的超参数优化
最新的分类和回归预测模型(深度学习,堆叠,LightGBM等)
使用模型解释进行预测,MLBox已在Kaggle上进行了测试,并显示出良好的性能。
管道
MLBox体系结构
MLBox主软件包包含3个子软件包:
预处理:读取和预处理数据
优化:测试或优化各种学习者
预测:预测测试数据集上的目标
TPOT
TPOT代表基于树的管道优化工具,它使用遗传算法优化机器学习管道.TPOT建立在scikit-learn的基础上,并使用自己的回归器和分类器方法。TPOT探索了数千种可能的管道,并找到最适合数据的管道。
TPOT通过智能地探索成千上万的可能管道来找到最适合我们数据的管道,从而使机器学习中最繁琐的部分自动化。
TPOT建立在scikit-learn的基础上,因此它生成的所有代码都应该看起来很熟悉……无论如何,如果我们熟悉scikit-learn。详细原理与案例请见(点击查看)一文彻底搞懂自动机器学习AutoML:TPOT
TPOT仍在积极开发中。
下面是分类和回归问题的两个例子:
分类
这是具有手写数字数据集光学识别功能的示例。
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data,
digits.target,
train_size=0.75,
test_size=0.25,
random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50,
verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
此代码将发现达到98%的测试精度的管道。应将相应的Python代码导出到tpot_digits_pipeline.py文件,其外观类似于以下内容:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline, make_union
from sklearn.preprocessing import PolynomialFeatures
from tpot.builtins import StackingEstimator
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9799428471757372
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
StackingEstimator(estimator=LogisticRegression(C=0.1, dual=False, penalty="l1")),
RandomForestClassifier(bootstrap=True, criterion='entropy',
max_features=0.35000000000000003,
min_samples_leaf=20, min_samples_split=19,
n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
回归
TPOT可以优化管道以解决回归问题。以下是使用波士顿房屋价格数据集的最小工作示例。
from tpot import TPOTRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
housing = load_boston()
X_train, X_test, y_train, y_test = train_test_split(
housing.data,
housing.target,
train_size=0.75,
test_size=0.25,
random_state=42)
tpot = TPOTRegressor(generations=5, population_size=50,
verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_boston_pipeline.py')
这将导致流水线达到约12.77均方误差(MSE),tpot_boston_pipeline.py中的Python代码应类似于:
import numpy as np
import pandas as pd
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE',
sep='COLUMN_SEPARATOR',
dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target =
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: -10.812040755234403
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False),
ExtraTreesRegressor(bootstrap=False, max_features=0.5,
min_samples_leaf=2, min_samples_split=3,
n_estimators=100)
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
Lightwood
一个基于Pytorch的框架,它将机器学习问题分解为较小的块,可以与一个目标无缝地粘合在一起:让它变得如此简单,以至于您只需要一行代码就可以构建预测模型。
安装
我们可以从pip安装Lightwood:
pip3 install lightwood
注意:根据我们的环境,在上面的命令中我们可能必须使用pip而不是pip3。
鉴于简单的sensor_data.csv,我们可以预测sensor3的值。
从Lightwood导入预测变量
from lightwood import Predictor
训练模型。
import panda
ssensor3_predictor = Predictor(output=['sensor3']
).learn(from_data=pandas.read_csv('sensor_data.csv'))
现在我们可以预测sensor3的值。
prediction = sensor3_predictor.predict(when={'sensor1':1, 'sensor2':-1})
MindsDB
MindsDB是现有数据库的开源AI层,可让您轻松使用SQL查询来开发,训练和部署最新的机器学习模型。
mljar-supervised
mljar-supervised是一个自动化的机器学习Python软件包,可用于表格数据。它旨在为数据科学家节省时间time。它抽象了预处理数据,构建机器学习模型以及执行超参数调整以找到最佳模型common的通用方法。这不是黑盒子,因为您可以确切地看到ML管道的构造方式(每个ML模型都有详细的Markdown报告)。
在mljar-supervised中,将帮助您:
解释和理解您的数据,
尝试许多不同的机器学习模型,
通过分析创建有关所有模型的详细信息的Markdown报告,
保存,重新运行和加载分析和ML模型。
它具有三种内置的工作模式:
解释模式,非常适合于解释和理解数据,其中包含许多数据解释,例如决策树可视化,线性模型系数显示,排列重要性和数据的SHAP解释,
执行构建用于生产的ML管道,
竞争模式,用于训练具有集成和堆叠功能的高级ML模型,目的是用于ML竞赛中。
Auto-Keras
Auto-Keras是由DATA Lab开发的用于自动机器学习(AutoML)的开源软件库。Auto-Keras建立在深度学习框架Keras之上,提供自动搜索深度学习模型的体系结构和超参数的功能。
Auto-Keras遵循经典的Scikit-Learn API设计,因此易于使用。当前版本提供了在深度学习期间自动搜索超参数的功能。
在Auto-Keras中,趋势是通过使用自动神经体系结构搜索(NAS)算法来简化ML。NAS基本上使用一组算法来自动调整模型,以取代深度学习工程师/从业人员。
神经网络智能 NNI
用于神经体系结构搜索和超参数调整的开源AutoML工具包。NNI提供了CommandLine Tool以及用户友好的WebUI来管理训练实验。使用可扩展的API,您可以自定义自己的AutoML算法和培训服务。为了使新用户容易使用,NNI还提供了一组内置的最新AutoML算法,并为流行的培训平台提供了开箱即用的支持。
Ludwig
路德维希(Ludwig)是一个工具箱,可让用户无需编写代码即可训练和测试深度学习模型。它建立在TensorFlow之上,Ludwig基于可扩展性原则构建,并基于数据类型抽象,可以轻松添加对新数据类型和新模型架构的支持,可供从业人员快速培训和测试深度学习模型以及由研究人员获得的强基准进行比较,并具有实验设置,可通过执行相同的数据处理和评估来确保可比性。
路德维希提供了一组模型体系结构,可以将它们组合在一起以为给定用例创建端到端模型。举例来说,如果深度学习图书馆提供了建造建筑物的基础,路德维希提供了建造城市的建筑物,您可以在可用建筑物中进行选择,也可以将自己的建筑物添加到可用建筑物中。
无需编码:不需要任何编码技能即可训练模型并将其用于获取预测。
通用性:新的基于数据类型的深度学习模型设计方法使该工具可在许多不同的用例中使用。
灵活性:经验丰富的用户对模型的建立和培训具有广泛的控制权,而新用户则会发现它易于使用。
可扩展性:易于添加新的模型架构和新的特征数据类型。
可理解性:深度学习模型的内部通常被认为是黑匣子,但是路德维希(Ludwig)提供了标准的可视化效果来了解其性能并比较其预测。
开源:Apache License 2.0
AdaNet
AdaNet是基于TensorFlow的轻量级框架,可在最少的专家干预下自动学习高质量的模型。AdaNet建立在AutoML最近的努力基础上,以提供快速的,灵活的学习保证。重要的是,AdaNet提供了一个通用框架,不仅用于学习神经网络体系结构,而且还用于学习集成以获得更好的模型。
AdaNet具有以下目标:
易于使用:提供熟悉的API(例如Keras,Estimator)用于训练,评估和提供模型。
速度:可用计算进行扩展,并快速生成高质量的模型。
灵活性:允许研究人员和从业人员将AdaNet扩展到新颖的子网体系结构,搜索空间和任务。
学习保证:优化提供理论学习保证的目标。
Darts
该算法基于架构空间中的连续松弛和梯度下降。它能够有效地设计用于图像分类的高性能卷积体系结构(在CIFAR-10和ImageNet上),以及用于语言建模的循环体系结构(在Penn Treebank和WikiText-2上)。只需要一个GPU。
automl-gs
提供一个输入的CSV文件和一个您希望预测为automl-gs的目标字段,并获得训练有素的高性能机器学习或深度学习模型以及本机Python代码管道,使您可以将该模型集成到任何预测工作流中。没有黑匣子:您可以确切地看到如何处理数据,如何构建模型以及可以根据需要进行调整。
图片
automl-gs是一种AutoML工具,与Microsoft的NNI,Uber的Ludwig和TPOT不同,它提供了零代码/模型定义界面,可在多个流行的ML / DL框架中以最少的Python依赖关系获得优化的模型和数据转换管道。
以下是用R实现
AutoKeras的R接口
AutoKeras是用于自动机器学习(AutoML)的开源软件库。它是由德克萨斯农工大学的DATA Lab和社区贡献者开发的。AutoML的最终目标是为数据科学或机器学习背景有限的领域专家提供易于访问的深度学习工具。AutoKeras提供了自动搜索深度学习模型的体系结构和超参数的功能。
在RStudio TensorFlow for R博客上查看AutoKeras博客文章。
以下是用Scala实现
TransmogrifAI
TransmogrifAI(发音为trăns-mŏgˈrə-fī)是用Scala编写的AutoML库,它在Apache Spark之上运行。它的开发重点是通过机器学习自动化来提高机器学习开发人员的生产率,以及一个用于强制执行编译时类型安全,模块化和重用的API。通过自动化,它实现了接近手动调整模型的精度,时间减少了近100倍。
如果您需要机器学习库来执行以下操作,请使用TransmogrifAI:
数小时而不是数月内即可构建生产就绪的机器学习应用程序
在没有博士学位的情况下建立机器学习模型在机器学习中
构建模块化,可重用,强类型的机器学习工作流程
以下是用Java实现
Glaucus
Glaucus是基于数据流的机器学习套件,它结合了自动机器学习管道,简化了机器学习算法的复杂过程,并应用了出色的分布式数据处理引擎。对于跨领域的非数据科学专业人士,帮助他们以简单的方式获得强大的机器学习工具的好处。
用户只需要上传数据,简单配置,算法选择,并通过自动或手动参数调整来训练算法。该平台还为培训模型提供了丰富的评估指标,因此非专业人员可以最大限度地发挥机器学习在其领域中的作用。整个平台结构如下图所示,主要功能是:
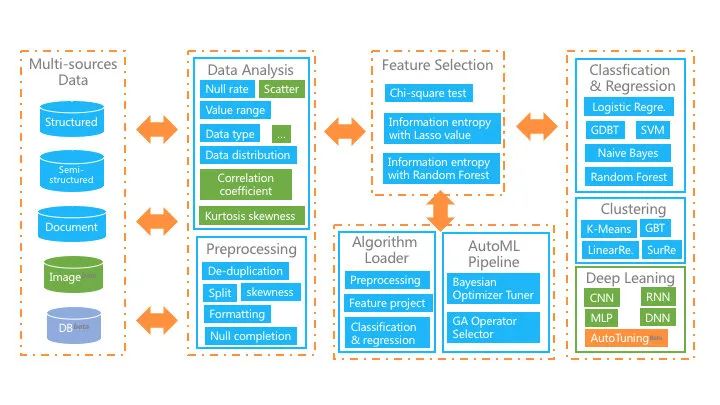
图片
接收多源数据集,包括结构化,文档和图像数据;
提供丰富的数学统计功能,图形界面使用户轻松掌握数据情况;
在自动模式下,我们实现了从预处理,特征工程到机器学习算法的全管道自动化;
在手动模式下,它极大地简化了机器学习流程,并提供了自动数据清理,半自动特征选择和深度学习套件。
介绍几款其他工具
H20 AutoML
H2O AutoML界面设计为具有尽可能少的参数,因此用户所需要做的只是指向他们的数据集,标识响应列,并可选地指定时间限制或训练的总模型数量的限制。
在R和Python API中,AutoML与其他H2O算法使用相同的数据相关参数x,y,training_frame,validation_frame。大多数时候,您需要做的就是指定数据参数。然后,您可以为max_runtime_secs和/或max_models配置值,以在运行时设置明确的时间或模型数量限制。
PocketFlow
PocketFlow是一个开源框架,用于以最少的人力来压缩和加速深度学习模型。深度学习广泛用于计算机视觉,语音识别和自然语言翻译等各个领域。但是,深度学习模型通常在计算上很昂贵,这限制了在计算资源有限的移动设备上的进一步应用。
PocketFlow旨在为开发人员提供一个易于使用的工具包,以提高推理效率而几乎不降低性能或不降低性能。开发人员只需指定所需的压缩和/或加速比,然后PocketFlow将自动选择适当的超参数以生成用于部署的高效压缩模型。
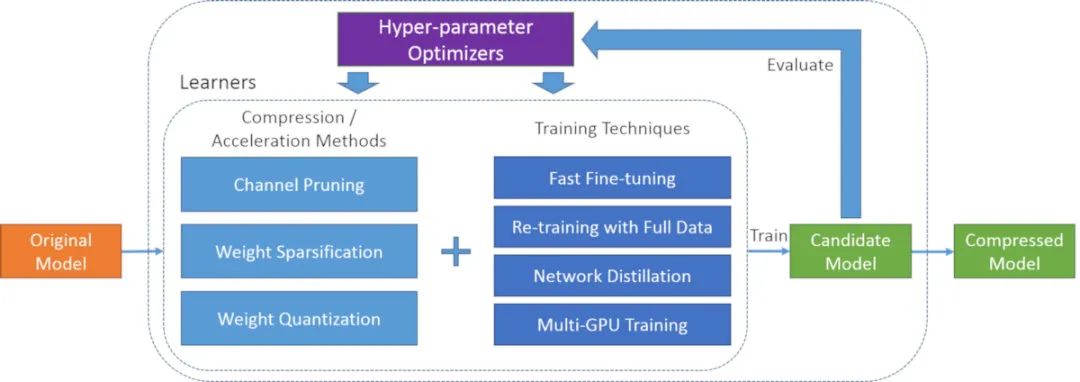
图片
Ray
Ray提供了用于构建分布式应用程序的简单通用API。
Ray与以下库打包在一起,以加快机器学习的工作量:
Tune:可伸缩超参数调整
RLlib:可扩展的强化学习
RaySGD:分布式培训包装器
Ray Serve:可扩展和可编程服务
SMAC3
SMAC是用于算法配置的工具,可以跨一组实例优化任意算法的参数。这还包括ML算法的超参数优化。主要核心包括贝叶斯优化和积极的竞速机制,可有效地确定两种配置中哪一种的性能更好。
有关其主要思想的详细说明,请参阅Hutter, F. and Hoos, H. H. and Leyton-Brown, K.Sequential Model-Based Optimization for General Algorithm ConfigurationIn: Proceedings of the conference on Learning and Intelligent OptimizatioN (LION 5)
SMAC v3是用Python3编写的,并经过了Python3.6和python3.6的持续测试。它的随机森林用C++编写。
结论
autoML库非常重要,因为它们可以自动执行重复任务,例如管道创建和超参数调整。它为数据科学家节省了时间,因此他们可以将更多的时间投入到业务问题上。AutoML还允许每个人代替一小部分人使用机器学习技术。数据科学家可以通过使用AutoML实施真正有效的机器学习来加速ML开发。
让我们看看AutoML的成功将取决于组织的使用情况和需求。时间将决定命运。但是目前我可以说AutoML在机器学习领域中很重要。
编辑:黄飞
-
如何轻松掌握机器学习概念和在工业自动化中的应用2021-01-16 4017
-
介绍10个Python自动化脚本2022-10-17 1402
-
2016上海工业自动化及机器人展览会2016-01-29 4396
-
工业自动化应用中的主要机器故障类型2020-12-07 6358
-
机器学习专家们每天都在做什么?如何让机器学习自动化2018-07-19 5845
-
自动化机器学习是什么情况2019-11-04 1827
-
机器流程自动化是什么2020-01-01 10142
-
谈谈如何将机器学习引入自动化2020-10-09 3102
-
自动化立体库结构是如何组成的2021-04-24 2637
-
简述人工智能和机器学习实现完全自动化的5种方法2021-06-15 5278
-
自动化立体库的工作原理2021-07-01 2510
-
自动化立体库的组成结构2021-08-13 2433
-
DB4564_用于STM32微控制器的自动化机器学习(ML)工具2022-11-23 747
-
利用人工智能和机器学习更好地跨行业部署自动化2022-12-06 1296
-
20个必知的自动化机器学习库(Python)2023-05-26 1559
全部0条评论

快来发表一下你的评论吧 !
