

FPGA运算单元对高算力浮点应用
描述
随着机器学习(Machine Learning)领域越来越多地使用现场可编程门阵列(FPGA)来进行推理(inference)加速,而传统FPGA只支持定点运算的瓶颈越发凸显。Achronix为了解决这一大困境,创新地设计了机器学习处理器(MLP)单元,不仅支持浮点的乘加运算,还可以支持对多种定浮点数格式进行拆分。
MLP全称Machine Learning Processing单元,是由一组至多32个乘法器的阵列,以及一个加法树、累加器、还有四舍五入rounding/饱和saturation/归一化normalize功能块。同时还包括2个缓存,分别是一个BRAM72k和LRAM2k,用于独立或结合乘法器使用。MLP支持定点模式和浮点模式。

考虑到运算能耗和准确度的折衷,目前机器学习引擎中最常使用的运算格式是FP16和INT8,而Tensor Flow支持的BF16则是通过降低精度,来获得更大数值空间。
而且这似乎也成为未来的一种趋势。目前已经有不少研究表明,更小位宽的浮点或整型可以在保证正确率的同时,还可以减少大量的计算量。因此,为了顺应这一潮流,MLP还支持将大位宽乘法单元拆分成多个小位宽乘法,包括整数和浮点数。
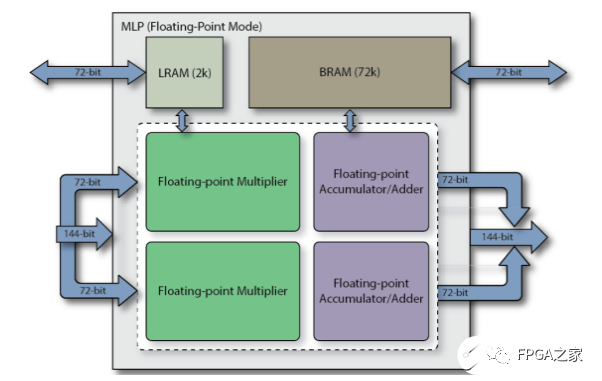
值得注意的是,这里的bfloat16即Brain Float格式,而block float为块浮点算法,即当应用Block Float16及更低位宽块浮点格式时,指数位宽不变,小数位缩减到了16bit以内,因此浮点加法位宽变小,并且不需要使用浮点乘法单元,而是整数乘法和加法树即可,MLP的架构可以使这些格式下的算力倍增。


欢迎加入至芯科技FPGA微信学习交流群,这里有一群优秀的FPGA工程师、学生、老师、这里FPGA技术交流学习氛围浓厚、相互分享、相互帮助、叫上小伙伴一起加入吧!
点个在看你最好看
原文标题:FPGA运算单元对高算力浮点应用
文章出处:【微信公众号:FPGA设计论坛】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- FPGA
-
浮点运算单元的设计和优化2025-10-22 248
-
risc-v中浮点运算单元的使用及其设计考虑2025-10-21 318
-
请问AURIX TC3xx tricore架构下浮点运算和将浮点数小数点去掉变成整数来计算哪种方式更加节省算力?2024-08-26 2256
-
FPGA运算单元对高算力浮点应用2023-02-27 698
-
请问蓝牙芯片有浮点运算单元吗?2022-10-09 908
-
浮点运算单元FPU能给电机控制带来什么?2021-12-04 1123
-
关于STM32浮点运算单元FPU的应用示例2021-01-02 10293
-
FPGA运算单元技术创新可支持高算力浮点2020-05-12 967
-
FPGA运算单元如今已能够支持高算力浮点2020-04-30 1536
-
震惊!FPGA运算单元可支持高算力浮点2020-03-03 2187
-
浮点运算单元的FPGA实现2018-04-10 1611
-
ARM处理器的浮点运算单元2017-09-16 899
-
基于FPGA高精度浮点运算器的FFT设计与仿真2011-12-23 1075
全部0条评论

快来发表一下你的评论吧 !
