

一种基于直接法的动态稠密SLAM方案
描述
0. 引言
基于特征点法的视觉SLAM系统很难应用于稠密建图,且容易丢失动态对象。而基于直接法的SLAM系统会跟踪图像帧之间的所有像素,因此在动态稠密建图方面可以取得更完整、鲁棒和准确的结果。本文将带大家精读2022 CVPR的论文:"基于学习视觉里程计的动态稠密RGB-D SLAM"。该论文提出了一种基于直接法的动态稠密SLAM方案,重要的是,算法已经开源。
1. 论文信息
摘要
我们提出了一种基于学习的视觉里程计(TartanVO)的稠密动态RGB-D SLAM系统。TartanVO与其他直接法而非特征点法一样,通过稠密光流来估计相机姿态。而稠密光流仅适用于静态场景,且不考虑动态对象。同时由于颜色不变性假设,光流不能区分动态和静态像素。
因此,为了通过直接法重建静态地图,我们提出的系统通过利用光流输出来解决动态/静态分割,并且仅将静态点融合到地图中。此外,我们重新渲染输入帧,以便移除动态像素,并迭代地将它们传递回视觉里程计,以改进姿态估计。
3. 算法分析
图1所示是作者提出的具有基于学习的视觉里程计的动态稠密RGB-D SLAM的顶层架构,其输出的地图是没有动态对象的稠密全局地图。 算法的主要思想是从两个连续的RGB图像中估计光流,并将其传递到视觉里程计中,以通过匹配点作为直接法来预测相机运动。然后通过利用光流来执行动态分割,经过多次迭代后,移除动态像素,这样仅具有静态像素的RGB-D图像就被融合到全局地图中。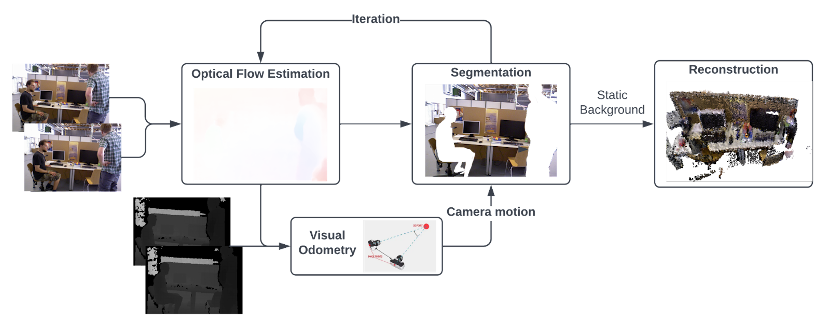
图1 基于学习的视觉里程计的动态稠密RGB-D SLAM顶层架构
3.1 分割算法
为了利用来自TartanVO的光流输出来分类动态/静态像素,作者提出了两种分割方法:一种是使用2D场景流作为光流和相机运动之间的差值。另一种是提取一帧中的像素到它们匹配的核线的几何距离。图2和图3所示分别为两种方法的算法原理。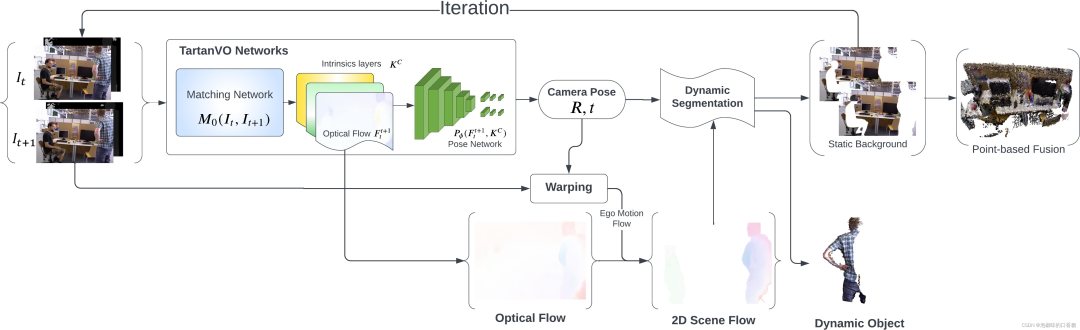
图2 使用基于2D场景流的分割的稠密RGB-D SLAM架构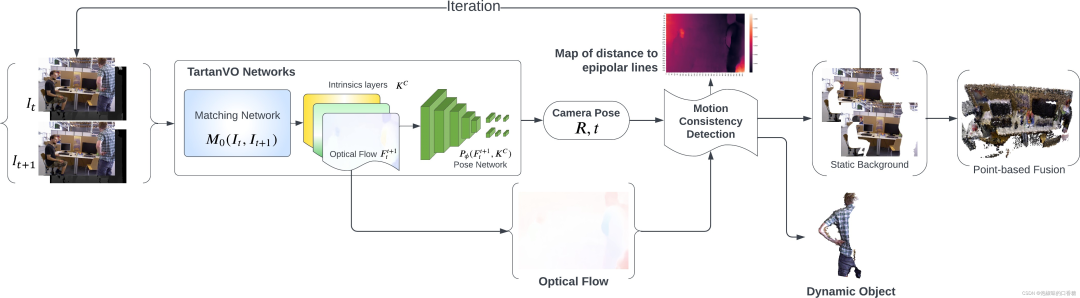
图3 基于运动一致性检测的稠密RGB-D SLAM架构
在图2中,作者首先使用来自TartanVO的匹配网络从两个连续的RGB图像中估计光流,随后使用姿态网络来预测相机运动。然后通过从光流中减去相机自身运动来获得2D场景流,并通过对2D场景流进行阈值处理来执行动态分割。 同时,静态背景被前馈到网络,以实现相机运动的迭代更新。
经过几次迭代后,动态像素被移除,仅具有静态像素的RGB-D图像被传递到基于点的融合中进行重建。图4所示为使用2D场景流进行动态像素分割的原理。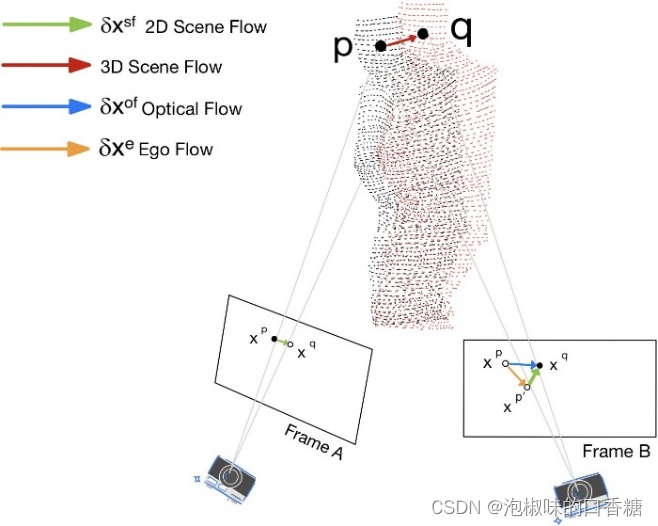
图4 图像平面中投影的2D场景流
在图3中,作者首先使用来自TartanVO的匹配网络从两个连续的RGB图像中估计光流,随后使用姿态网络来预测相机运动。 然后计算从第二帧中的像素到它们的对应核线的距离,其中核线使用光流从匹配像素中导出。
最后通过距离阈值化来执行动态分割。经过几次迭代后,动态像素被移除,仅具有静态像素的RGB-D图像被传递到基于点的融合中进行重建。
图3所示的动态稠密框架基于的思想是:如果场景中没有动态物体,那么第二帧图像中的每个像素应该在其第一帧图像匹配像素的核线上。 在这种情况下,可以使用给定的相机位姿、光流和内在特性进行分割,而不是将第一帧图像直接投影到第二帧。这种方法也被作者称为"运动一致性"检测。
图5所示是运动一致性的细节检测原理。该算法首先获得匹配的像素对,即每对图像中的像素直接施加光流矢量到第一帧上,并计算具有匹配像素对的基础矩阵。 然后,再计算每个像素的对应核线基本矩阵和像素的位置。当第二帧中匹配像素与它的核线大于阈值时,它被分类作为动态像素。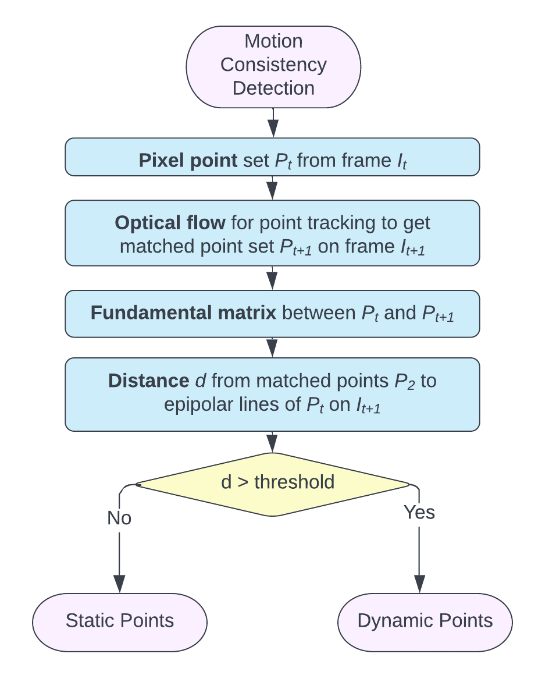
图5 运动一致性检测的算法原理
3.2 迭代和融合
在RGB-D图像中仅剩下静态像素后,作者迭代地将其传递回TartanVO进行改进光流估计,从而获得更精确的相机姿态。理想情况下,通过足够的迭代,分割掩模将移除与动态对象相关联的所有像素,并且仅在图像中留下静态背景。 同时作者发现,即使使用粗糙的掩模,仍然可以提高TartanVO的ATE。另外,如果粗掩模允许一些动态像素进入最终重建,那么它们将很快从地图中移除。
经过固定次数的迭代后,将去除了大多数动态像素的细化图像对与其对应的深度对一起进行融合。数据融合首先将输入深度图中的每个点与全局图中的点集投影关联,使用的方法是将深度图渲染为索引图。 如果找到相应的点,则使用加权平均将最可靠的点与新点估计合并。
如果没有找到可靠的对应点,则估计的新点作为不稳定点被添加到全局图中。
随着时间的推移,清理全局地图,以去除由于可见性和时间约束导致的异常值,这也确保了来自分割的假阳性点将随着时间的推移而被丢弃。因为作者利用稠密的光流并在每个像素上分割图像而不进行下采样,所以算法可以重建稠密的RGB-D全局图。
4. 实验
作者使用TUM数据集中的freiburg3行走xyz序列,图6和图7所示为使用2D场景流的分割结果。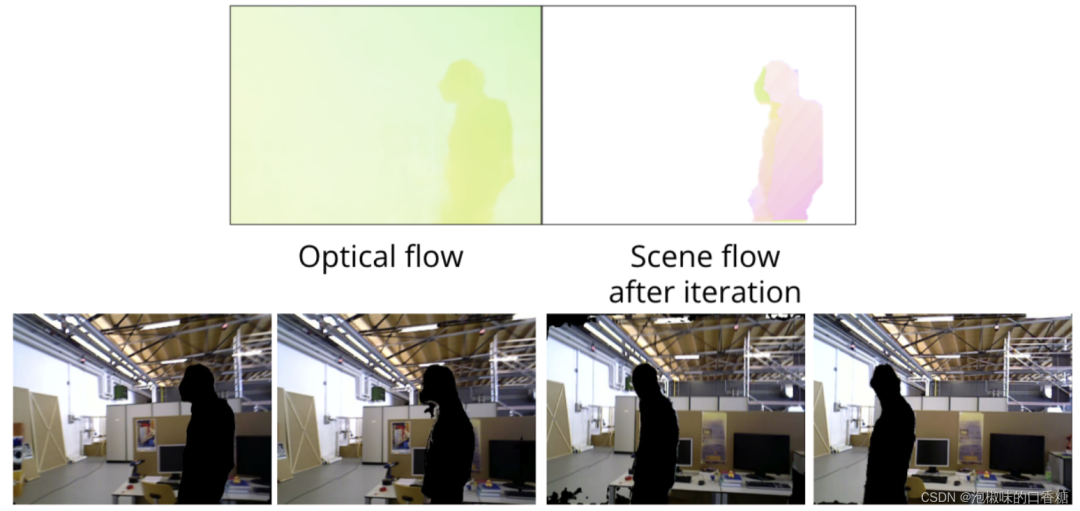
图6 基于2D场景流动态分割向左移动的对象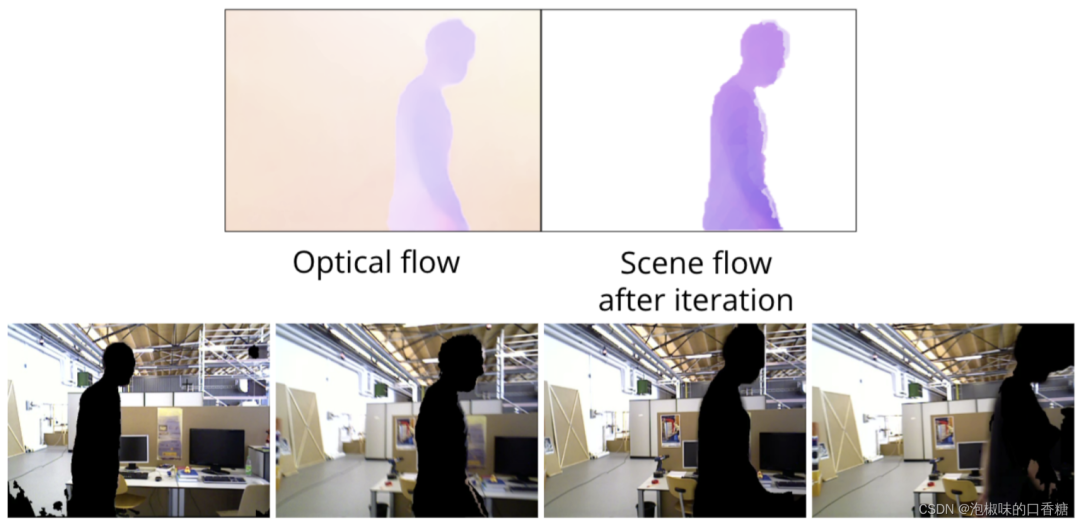
图7 基于2D场景流动态分割向右移动的对象
随后,作者迭代地将重新渲染的图像对传递回TartanVO。作者认为这一操作将改进光流估计,并且获得更精确的相机姿态,如图8所示是实验结果。其中左图是使用原始TartanVO的绝对轨迹误差,右图是使用改进TartanVO的绝对轨迹误差。实验结果显示,如果有足够的迭代,分割过程将移除动态物体中的大多数像素,并且仅保留静态背景。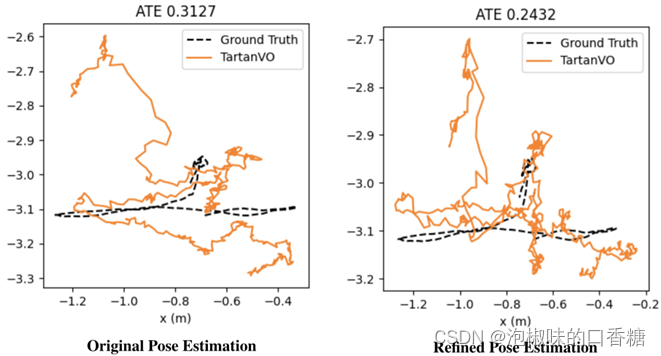
图8 原始TartanVO和回环优化的轨迹误差对比结果
图9所示是在TUM整个freiburg3行走xyz序列上的重建结果,结果显示动态对象(两个移动的人)已经从场景中移除,只有静态背景存储在全局地图中。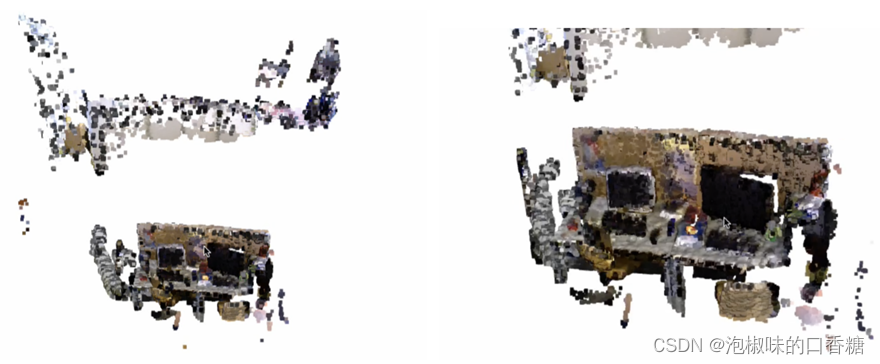
图9 基于点融合的三维重建结果
此外,为了进行不同方法的对比,作者首先尝试掩蔽原始图像以滤除对应于3D中的动态点的像素,然后,在此之上尝试用在先前图像中找到的匹配静态像素来修补空缺,但降低了精度。与产生0.1248的ATE的TartanVO方法相比,原始掩蔽方法产生了更理想的光流,而修补方法产生因为产生过多的伪像而阻碍了光流的计算。如图10所示是对比结果。
图10 tartan VO的三种输入类型对比
5.结论
在2022 CVPR论文"Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry"中,作者提出了一种全新的动态稠密RGB-D SLAM框架,它是一种基于学习视觉里程计的方法,用于重建动态运动物体干扰下的静态地图。重要的是,算法已经开源,读者可在开源代码的基础上进行二次开发。
此外,作者也提到了基于该论文的几个重要的研究方向:
(1) 引入自适应阈值机制,通过利用流、姿态和地图等来为分割提供更一致的阈值。
(2) 在预训练的基于学习的视觉里程计中,使用对相机姿态和光流的BA来补偿大范围运动感知。
(3) 使用动态感知迭代最近点(ICP)算法来代替TartanVO中的姿态网络。
(4) 在更多样化的数据集上进行测试和迭代,以提供更好的鲁棒性。
审核编辑:刘清
-
从基本原理到应用的SLAM技术深度解析2024-02-26 18424
-
一种中频直接采样方案2012-11-25 2479
-
SLAM技术的应用及发展现状2018-12-06 15603
-
视觉SLAM特征点法与直接法对比分析2020-06-02 2608
-
分享一种FPGA的动态配置方案2021-05-27 1844
-
一种适用于动态场景的SLAM方法2021-03-18 1481
-
一种基于RBPF的、优化的激光SLAM算法2021-04-01 1124
-
基于增强动态稠密轨迹特征的视频布料材质识别2021-05-11 1266
-
基于增强动态稠密轨迹特征的布料材质识别技术2021-06-25 851
-
一种快速的激光视觉惯导融合的slam系统2022-11-09 2892
-
3D重建的SLAM方案算法解析2023-09-11 2583
-
一种适用于动态环境的实时视觉SLAM系统2024-09-30 2518
-
一种基于MASt3R的实时稠密SLAM系统2024-12-27 3619
-
一种适用于动态环境的实时RGB-D SLAM系统2025-07-04 1698
-
一种适用于动态环境的自适应先验场景-对象SLAM框架2025-08-19 1209
全部0条评论

快来发表一下你的评论吧 !
