

深入探索Linux中的C语言
描述
本章将深入探索 Linux 中的 C 语言。在本章中,我们将学到更多关于编译器、从源码到二进制程序的 4 个步骤、如何使用 Make 工具以及系统调用和 C 标准库函数的差别的知识。我们也将学习一些 Linux 中的基础头文件、C 语言标准以及可移植操作系统(POSIX)标准,C 语言是和 Linux 紧密结合的,掌握 C 语言可以帮你更好地学习 Linux。
本章中,我们将会学习如何开发 Linux C 语言程序和库,学习如何编写通用的Makefile 以及为一些重要的项目编写高级的 Makefile。在学习的过程中,我们也会学到各种 C 语言标准、它们的区别以及对程序有哪些影响。
本章涵盖以下主题:
使用 GNU 编译器套件(GCC)链接库
切换 C 标准
使用系统调用
何时不使用它们
获取 Linux 和类 UNIX 头文件信息
定义功能测试宏
编译过程的 4 个步骤
使用 Make 编译
使用 GCC 选项编写一个通用的 Makefile
编写一个简单的 Makefile
编写一个更高级的 Makefile
3.1 技术要求
在开始学习之前,你需要 GCC 编译器、Make 工具。
本章中的所有代码示例都可以从 GitHub 下载:
https://github.com/PacktPublishing/Linux-System-Programming-Techniques/tree/master/ch3
3.2 使用 GNU 编译器套件链接库
本节中,你将会学到如何把程序链接到一个外部库—一个安装在系统层面,另一个安装在主目录中。在链接库之前,我们需要创建它,这也是本节中我们要学习的内容。学习如何链接库可以让你复用库提供的大量现成函数,无须编写所有内容,就可以使用库文件已提供的功能。通常来说,没有必要重新发明轮子,这可以节约大量的时间。
3.2.1 准备工作
在本范例中,你只需要用到 3.1 节中列出的工具。
3.2.2 实践步骤
我们开始学习如何链接系统中的共享库以及主目录中的库。我们从已有的标准库开始:math 库。
3.2.2.1 链接到 math 库我们会编写一个计算银行账户复利的小程序,会用到 math 库中的 pow() 函数:1. 把下面的代码写入文件,并将其命名为 interest.c。注意,文件顶部包含 math.h,pow() 函数的第一个参数是基数,第二个参数是指数:
#include#include int main(void) { int years = 15; /* The number of years you will * keep the money in the bank * account */ int savings = 99000; /* The inital amount */ float interest = 1.5; /* The interest in % */ printf("The total savings after %d years " "is %.2f ", years, savings * pow(1+(interest/100), years)); return 0; }
2. 编译并链接程序。链接库的选项是 -l,库的名称是 m (更多信息请参阅 man 3 pow 手册页:
$> gcc interest.c -o interest -lm
3.运行程序:
$> ./interest
The total savingsafter 15 years is 123772.95
3.2.2.2 创建自己的库
我们开始学习创建自己的共享库。下一节,我们会链接一个进程到这个库。这个库的 作用是确定一个数是否为素数。
1. 我们从创建一个简单的头文件开始,这个文件只包含一行:函数原型。把以下内容 写入文件并将其命名为 prime.h:
int isprime(long int number);
2. 现在开始编写库文件中的实际函数,把以下代码写入文件并将其命名为 prime.c:
int isprime(long int number)
{
long int j;
int prime = 1;
/* Test if the number is divisible, starting
* from 2 */
for(j=2; j
我们需要通过一些手段把其转换成库。第一步是把它编译成一个叫目标文件的对象。我们还需要向编译器传递一些额外的参数使其作为库运行。更具体一些,我们需要 使其成为位置无关的代码 ( PIC)。运行以下编译命令会生成一个叫prime.o 的文 件,使用 ls -l 命令来查看文件,我们将在本章后面学到更多关于目标文件的知识:
$> gcc -Wall -Wextra -pedantic -fPIC -c prime.c
$> ls -lprime.o
-rw-r--r-- 1 jakejake 1296 nov 28 19:18prime.o
4. 现在,我们将目标文件打包成一个库,在下面的命令中, -shared 参数创建一个共 享库。-Wl、-soname、libprime .so 参数用于链接器。它告诉链接器这个共享 库的名字( soname)叫 libprime .so。-o 参数指定输出文件名,即 libprime . so。这是动态链接库的标准命名约定,结尾的so 代表共享对象。当库要在系统范 围内使用时,通常会添加一个数字来指示版本。在命令的最后,我们加上需要被包 含在共享库中的目标文件 prime .o:
$> gcc -shared -Wl,-soname,libprime.so -o
> libprime.soprime.o
3.2.2.3 链接到主目录中的库
有时,你想要链接到主目录(或其他目录)中的共享库。它可能是你从网上下载的库或 者你自己构建的库。我们将会在本书的后续章节学习更多创建共享库的知识。这里,我们 使用刚刚创建的 libprime.so 共享库。
1. 把以下代码写入文件并将其命名为is-it-a-prime .c。这个程序将会使用到刚才 创建的共享库。程序代码中必须包含刚刚创建的头文件 prime .h。请注意包含本地 头文件的不同语法(不是系统级别的头文件):
#include
#include
#include
#include "prime.h"
int main(int argc, char*argv[])
{
long int num;
/* Only one argument is accepted
*/
if (argc != 2)
{
fprintf(stderr,
"Usage: %s number
",
argv[0]);
return 1;
}
/* Only numbers0-9 are accepted */
if (strspn(argv[1], "0123456789") !=
strlen(argv[1]) )
{
fprintf(stderr, "Only numeric values are"
"accepted
");
return 1;
}
num =atol(argv[1]); /* String to long */
if (isprime(num))
/* Check if num is a prime */
{
printf("%ld
is a prime
", num);
}
else
{
printf("%ld
is not a prime
", num);
}
return 0;
}
2. 编译并把它链接到 libprime .so。由于共享库在主目录中,因此需要指定共享库 的路径:
$> gcc -L${PWD} is-it-a-prime.c
> -o is-it-a-prime -lprime
3.在运行程序之前,我们需要设置环境变量 $LD_LIBRARY_PATH 为当前目录(也就
是共享库所在的目录)。原因是这个库是动态链接的,它并不在系统库所在的路径:
$> export LD_LIBRARY_PATH=${PWD}:${LD_LIBRARY_PATH}
4.运行程序。用一些不同的数字测试一下,看看它们是否为素数:
$> ./is-it-a-prime 11
11 is aprime
$> ./is-it-a-prime 13
13 is aprime
$> ./is-it-a-prime 15
15 is not a prime
$> ./is-it-a-prime 1000024073
1000024073 is a prime
$> ./is-it-a-prime 1000024075
1000024075 is not a prime
我们可以通过 ldd 命令查看程序依赖哪些共享库,如果我们检查is-it-a-prime 程序,会看到它依赖 libprime .so 库。当然它也还有其他依赖项,例如 libc.so.6,这是标准的 C 库:
$> ldd is-it-a-prime
linux-vdso.so.1(0x00007ffc3c9f2000)
libprime.so => /home/jake/libprime.so
(0x00007fd8b1e48000)
libc.so.6=> /lib/x86_64-linux-gnu/libc.so.6
(0x00007fd8b1c4c000)
/lib64/ld-linux-x86-64.so.2 (0x00007fd8b1e54000)
3.2.3 它是如何工作的
在“链接到 math 库”一节中使用的 pow() 函数需要链接标准库中的 math 库 libm . so。你可以在系统库路径中找到这个库文件,它通常位于 /usr/lib 或 /usr/lib64。对于 Debian 和 Ubuntu 发行版来说,它通常位于 /usr/lib/x86_64-linux-gnu (对于 64 位系统来说)。由于这个文件位于系统默认的库文件路径,因此我们可以仅使用 -l 参数 来包含它。math 库文件的全称是 libm .so,但是当我们指定库文件时,只写了 m (即我们删除了 lib 和 .so 的扩展名), -l 和 m 之间不应该有空格,所以链接时,使用-lm。
我们需要链接到 math库才能使用 pow() 函数的原因是 math库和标准 C库 libc .so 是分开的。我们之前使用的函数都是标准库 libc .so 提供的,这个库默认就被链接,所 以不需要指定,如果想在编译时显示指定libc .so 的链接,可以执行 gcc -lc some- program.c -o some-program。
pow() 函数接受 2 个参数:x 和 y,例如 pow(x,y)。函数返回 x 的 y 次幂值。比如 pow(2,8)返回 256。返回值类型和参数 x、y 的类型都是 double 浮点数。
计算复利的公式如下所示:
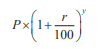
这里,P是你存入账户的起始资本, r 是利率(以百分比表示),y 是资金存在银行的年数。
链接到主目录中的库
在 C 程序 is-it-a-prime .c 中,我们需要包含 prime.h 头文件。头文件只有一行 isprime() 的函数原型。实际的 isprime()函数在 prime.o 创建的 libprime.so 库 文件中。 .so 文件叫作共享库或共享对象文件。共享库包含已编译的函数目标文件。我们 将在本章后面介绍什么是目标文件。
当我们链接到自己下载或者创建的共享库时,会比链接系统库麻烦一点,因为它们没 有安装在系统库的默认路径。
首先,我们需要指定共享库的名字和路径,路径通过-L 参数指定。本章的例子中, 我们指定路径为当前目录,也就是我们创建库文件的地方。我们通过${PWD} 来指定当 前目录, ${PWD} 是一个 shell 环境变量,它表示当前目录的绝对路径。你可以尝试执行 echo ${PWD} 看看输出。
现在还不能运行程序, 我们还需要设置另外一个环境变量 $LD_LIBRARY_PATH,把 $LD_LIBRARY_PATH 设置为当前目录(同时必须包含变量中已有的路径)。原因是这是 一个动态链接库,库文件并不包含在程序中,意味着程序运行时需要找到共享库。环境变 量 $LD_LIBRARY_PATH 的作用,就是告诉程序到哪里找这个库文件。同时我们也不想覆 盖 $LD_LIBRARY_PATH 已有的内容,因此设置时需要包含原有内容。如果没有设置这 个环境变量,在执行程序时会收到一条错误消息,即“ error while loading shared libraries:libprime.so ”。当我们使用 ldd 查看程序依赖时,可以看到 libprime .so 位于主目录中, 而不是系统的路径。
3.2.4更多
如果你对标准 C 库有兴趣,可以阅读 libc 的 man 手册。想了解 pow() 函数,可以 阅读 man 3 pow。
我也鼓励你通过 man ldd 阅读 ldd 的手册,并使用 ldd 查看进程的依赖,比如在本 节中编写的interest 进程。你会看到 libm .so 库及其系统路径。你也可以尝试用 ldd查看系统二进制,比如 /bin/ls。
3.3 切换 C标准
在本范例中,我们会学习不同的 C 标准,它们是什么、为什么重要,以及它们如何影 响程序。我们还会学习如何在编译时选择 C 标准。
现在几种最通用的 C 标准是 C89 、C99 和 C11 ( C89 是 1989 年发布的,C11 是 2011 年发布的,以此类推)。很多编译器仍然默认使用 C89 标准,因为它是兼容性最好,使用 最广泛,实现最完整的。不过,C99 是一种更加灵活和更加现代化的实现。通常在较新的 Linux 版本里,默认使用 C18 标准以及一些 POSIX 标准。
在本范例中,我们会编写 2个进程,并分别用 C89 和 C99 编译, 看看它们的区别。
3.3.1 准备工作
在本范例中你只需要一台安装有 Linux 系统的计算机,并且安装 GCC,最好通过我们 在第 1 章中介绍的软件包来安装。
3.3.2 实践步骤
我们继续探索不同 C 标准的差异。
1. 把下面的代码写入文件,并将其命名为no-return.c。注意,代码中缺少 return 语句:
#include
int main(void)
{
printf("Hello, world
");
}
2.用 C89 标准编译程序:
$> gcc -std=c89 no-return.c -o no-return
3.运行程序并检查退出码:
$> ./no-return
Hello, world
$> echo $?
13
4. 仍然使用 C89 标准编译程序,但是开启所有类型警告、扩展语法警告,以及pedantic 检查( -W 表示警告参数, all 表示警告类型,所以用 -Wall),注意 GCC 输出的错
误消息:
$> gcc -Wall -Wextra -pedantic -std=c89
> no-return.c -o no-return
no-return.c:
In function 'main':
no-return .c:6:1: warning: control reaches end of non-void
function [-Wreturn-type]
}
5. 改用 C99 标准重新编译程序,并开启所有类型警告和pedantic 检查。现在就不会显 示错误:
$> gcc -Wall -Wextra -pedantic -std=c99
> no-return.c -o no-return
6.重新运行程序,并检查退出码。看看和之前的区别。
$> ./no-return
Hello, world
$> echo $?
0
7. 把下面的代码写入文件,并将其命名为 for-test .c。这个程序在 for 循环内新定 义了一个 i 整型变量,只有 C99 允许这个写法:
#include
int main(void)
{
for (int i = 10;
i>0; i--)
{
printf("%d
",
i);
}
return 0;
}
8. 用 C99 标准编译:
$> gcc -std=c99 for-test.c -o for-test
9.运行这个程序,可以看到它正常工作:
$> ./for-test
10
9
8
7
6
5
4
3
2
1
10. 现在尝试用 C89 标准编译。注意 GCC 的报错明确说明了这个用法只在 C99 或更高 版本被允许。GCC 的报错都很有用,所以一定要认真看,它可以帮你节约大量时间。
$> gcc -std=c89 for-test.c -o for-test
for-test.c: In function 'main':
for-test .c:5:5: error: 'for' loop initialdeclarations
are only allowed in C99 or C11 mode
for (int i = 10;
i>0; i--)
11. 现在编写下面的小程序并将其命名为 comments .c。这个程序使用了 C99 注释(也 称为 C++ 注释):
#include
int main(void)
{
// A C99 comment
printf("hello, world
");
return 0;
}
12.用 C99 编译程序:
$> gcc -std=c99 comments.c -o comments
13.现在尝试用 C89 标准编译程序。注意这里 GCC 的报错也很有用:
$> gcc -std=c89 comments.c -o comments
comments.c: In function 'main':
comments .c:5:5: error:C++ style comments are not allowed
in ISO C90
// A C99 comment
^
comments .c:5:5: error:
(this will be reported only once
per input file)
3.3.3 它是如何工作的
这只是 C89 和 C99 的一些常见区别,在 Linux 上使用 GCC 还有其他不明显的差异。我们在 3.3.4节会讨论其中的一些不可见差异。
我们通过 GCC 的 -std 参数选择不同的 C 标准。在本节中,我们测试了2个标准,C89 和 C99。
在第 1~ 6步中,我们看到函数忘记返回值这种情况在编译时的区别。在C99 中, 由 于未指定其他值,因此假定返回值为 0。但是在 C89 中,忘记返回值是不行的。程序可以 编译通过,但是程序运行时会返回 13(错误码),这是错误的,因为程序中没有发生错误。你测试时返回的实际值可能不同,但错误码始终大于0。当编译时启用所有警告、额外警告 和 pedantic 检查( -Wall -Wextra -pedantic)时,可以看到警告输出这意味着忘记返 回值是不合法的。所以,在C89 中总是返回一个带有 return 的值。
在第 7 ~ 10步中,我们看到 C99 可以在 for 循环中声明一个新变量,这在 C89 中是 不可以的。
在第 11~ 13步中,我们看到一种新的注释方式:2个斜杠 //。这在 C89 中也是不合法的。
3.3.4更多
除了 C89 和 C99,还有很多的 C 语言标准和方言。例如 C11 、GNU99 ( GNU 的 C99 方言)、 GNU11 ( GNU 的 C11 方言)等,但今天最常用的 C 语言标准是 C89 、C99 和 C11。C18 开始作为某些编译器和发行版的默认设置。
实际上,C89 和 C99 的差异比我们在这里介绍的更多, 其中一些差异无法使用 Linux 计算机上的 GCC 演示,因为 GCC 已经做了兼容,其他编译器也是如此。但是也有其他的 一些差异,比如 C89 不支持 long long int 类型,但是C99 是支持的。尽管如此,一些 编译器(包括 GCC)支持了 C89 使用 long long int 类型,但是在C89 下使用要非常小 心,并非所有编译器都支持。如果要使用 long long int 类型,最好使用C99 、C11 或 C18。
我们建议你始终使用 -Wall、-Wextra和 -pedantic 选项编译程序。
3.4 使用系统调用
在任何关于 UNIX 和 Linux 的讨论中,系统调用都是一个令人兴奋的话题。它是Linux系统编程最底层的部分之一。我们按图3.1 从上往下看,运行的 shell 和二进制在最上层, 在它的下面是标准C 库函数,比如 printf()、fgets()、putc() 等。在 C 库的下面(即 最底层)有系统调用,比如 creat()、write() 等。
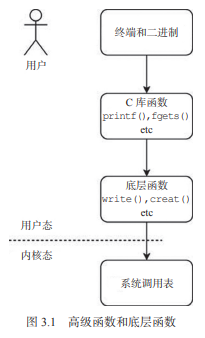
图 3.1 高级函数和底层函数
我在本书中讨论的系统调用是指内核提供的C 函数系统调用,而不是实际的系统调用表。我们在这里使用的系统调用是用户态调用的,但是函数本身是在内核态执行的。
很多标准 C 库的函数在实现中调用了一个或多个系统调用。putc() 函数是一个很好 的例子,它使用 write() 在屏幕上打印一个字符(这是一个系统调用)。还有一些标准 C 库函数根本不需要使用系统调用,比如 atoi(),它只需在用户态执行,不需要内核帮它 执行字符串转换数字的操作。
一般来说,如果有可用的标准 C 库函数,我们应该优先使用C 库函数而不是系统调用。相比较而言,系统调用更难使用并且更加原始。一般来说,把系统调用视为底层接口,把C 库函数视为高层接口。
但是,在某些情况下,我们必须使用系统调用,或者说在这些场景下使用系统调用更 方便。学习何时以及为什么使用系统调用会让你成为更好的程序员。比如我们可以通过系 统调用在 Linux 上执行很多文件操作,但是在其他地方是不行的。另一个使用系统调用的 例子是创建进程的时候,详见后文。总之,当我们需要对系统进行操作时就需要用到系统 调用。
3.4.1 准备工作
在本节中,我们将使用 Linux 系统调用,所以你需要一台 Linux 计算机。请注意, sysinfo() 系统调用在 FreeBSD 和 maxOS 下不可用。
3.4.2 实践步骤
使用 C 库的函数和使用系统调用实际上没有太大区别,Linux 中的系统调用在头文件 unistd .h 中声明,所以我们在使用系统调用时需要包含这个文件。
1. 在文件中写入以下代码并将它命名为 sys-write .c。它用到了 write() 系统调 用。注意,代码中没有包含 stdio .h 头文件,因为不需要 printf() 函数或者任 何标准输入、标准输出、标准错误文件流。我们直接输出到1 号文件描述符(标准输 出)。三个标准文件描述符总是被打开:
#include
int main(void)
{
write(1,
"hello, world
", 13);
return 0;
}
2. 编译代码。为了写出更好的代码,从现在开始,我们会始终打开-Wall、-Wextra 和 -pedantic 参数:
$> gcc -Wall -Wextra -pedantic -std=c99
> sys-write.c-o sys-write
3.运行程序:
$> ./sys-write
hello, world
4. 编写相同的代码,只是用fputs()函数替代了 write() 函数。注意,我们在这里 包含了 stdio.h,而不是 unistd.h,将程序命名为 write-chars.c:
#include
int main(void)
{
fputs("hello, world
", stdout);
return 0;
}
5.编译程序:
$> gcc -Wall -Wextra-pedantic -std=c99
> write-chars .c -o write-chars
6.运行程序:
$> ./write-chars
hello, world
7. 现在,我们编写一个读取用户和系统信息的程序。把程序另存为 my-sys .c。代码 示例中所有的系统调用都加粗显示了。这个程序会获取你的用户ID、当前工作目 录、机器总内存和可用随机存储内存 (RAM),以及当前的进程 ID (PID ):
#include
#include
#include
#include
int main(void)
{
char cwd[100] = { 0 }; /* for current dir */
struct sysinfo si;
/* for system information */
aetc丛g(c丛g、 T00):/* get current working dir*/
e入eT对Eo(CeT):/* get system information
* (linux only)
*/
printf("Youruser ID is %d
",aet门Tg());
printf("Your
effective user ID is %d
",
aete门Tg());
printf("Your
current working directory is %s
",
cwd);
printf("Yourmachine has %ld megabytes of "
"total RAM
", si.totalram / 1024 / 1024);
printf("Yourmachine has %ld megabytes of "
"free RAM
", si.freeram / 1024 / 1024);
printf("Currently, there are %d processes "
"running
",si.procs);
printf("Thisprocess ID is %d
",aetbTg());
printf("The
parent process ID is %d
"aetbbTg());
return 0;
}
8.编译程序:
t> acc -Mg丁丁 -Mext泥g -begg对tTc -etg=coo m入-e入e .c -o /
> m入-e入e
9.运行程序,你会看到用户信息和机器信息:
t> .m入-e入e
Your user ID is 1000
Your effective user ID is 1000
Your current workingdirectory is /mnt/localnas_disk2/
linux-sys/ch3/code
Your machine has 31033
megabytes of total RAM
Your machine has 6117
megabytes of free RAM
Currently,there are 2496 processes running
This process ID is 30421
The parent processID is 11101
3.4.3 它是如何工作的
在实践步骤的第 1~ 6步中,我们了解了 write() 和 fputs() 函数之间的区别。区 别可能不那么明显,但是 write() 系统调用使用了文件描述符而不是文件流。这几乎适用 于所有的系统调用。文件描述符比文件流更加原始。同样,自顶而下的方法也适用于文件描述符和文件流。文件流在文件描述符上层,并提供了高级别的接口。但是,有时候我们 也需要直接使用文件描述符,因为它们提供了更多的控制。另外,文件流可以提供更强大和更丰富的输入和输出(带有格式化的输出,比如, printf())。
在第 7 ~ 9 步中,我们编写了一个程序来获取系统信息和用户信息。在这里包含了三 个特定于系统调用的头文件:unistd .h、sys/types.h 和 sys/sysinfo.h。
unistd.h 是 UNIX 和 Linux 系统中常见的头文件。sys/types .h 是系统调用中另 一个常见的头文件,经常用于从系统取值。这个头文件包含了特殊的变量类型,比如用于 用户 ID ( UID)的 uid_t、用于组 ID ( GID)的 gid_t。它们一般是int整型。还有用于 inode 编号的 ino_t、用于 PID的 pid_t 等。
sys/sysinfo .h 头文件专门用于 sysinfo() 函数,而且这个函数只适用于 Linux 系统调用,所以在其他UNIX 系统(例如 macOS 、Solaris 或 FreeBSD/OpenBSD/NetBSD) 下不起作用。这个头文件声明了 sysinfo 结构,我们通过调用 sysinfo() 函数获取系统 信息。
我们在程序中使用的第一个系统调用是 getcwd(),用于获取当前工作目录。函数有 两个参数:一个表示缓冲区,用来保存路径;另外一个是缓冲区的长度。
下一个使用的系统调用是只能在Linux 系统下工作的 sysinfo() 函数。这个函数包 含很多信息。当函数执行时,所有的数据都会保存到 sysinfo 数据结构中。包括系统正常运行时间、平均负载、内存总量、可用和已使用内存、总的和可用交换空间、以及正在运 行的进程总数。在 man 2 sysinfo 中,可以找到有关 sysinfo 数据结构中的各种变量 及其数据类型的信息。在示例代码的下半部分,我们还使用printf() 打印了其中的一些 变量,例如 si .totalram,它表示系统内存的大小。
其余的系统调用都直接从printf() 函数中调用并打印出返回值。
3.4.4更多
在手册中有很多系统调用的详细信息。一个好的学习方式是查看 man 2 intro 和 man 2 syscalls。
提示
一般系统调用出错时都返回 -1,检查返回值是一个好办法。
3.5 获取 Linux 和类 UNIX 头文件信息
Linux 和其他 UNIX 系统中有很多特定的函数和头文件,一般来说,它们都是 POSIX 函数,但是只能运行 Linux 上的函数,比如 sysinfo()。我们已经在前面用到了 2 个 POSIX 文件:unistd.h 和 sys/types.h。因为它们是 POSIX标准的,所以适用于所有 类 UNIX 系统,例如 Linux 、FreeBSD 、OpenBSD 、macOS和 Solaris。
在本节中,我们会更多地学习POSIX 头文件的知识、它们的作用以及如何使用。我们 还会学习如何在手册中查找这些头文件的信息。
3.5.1 准备工作
在本范例中,我们要学习在手册中查找头文件。如果你使用的是基于Fedora 的系统, 例如 CentOS 、Fedora 或 Red Hat,默认这些手册页已经安装在系统上。如果由于某些原 因它们丢失了,你可以用 root 权限或者 sudo 执行 dnf install man-pages 重新安装。
如果你使用的是基于 Debian 的系统,例如 Ubuntu 或 Debian,默认是不安装这些手册 的,需要按照下面的命令来安装它们。
Debian
Debian 对于非自由软件更加严格,所以我们需要做一些额外步骤。
1. 以 root 权限打开 /etc/apt/sources .list。
2. 在每行末尾的 main 后面加上 non-free (在 main 和 non-free 之间有一个空格)。
3.保存文件。
4. 以 root 权限执行 apt update。
5. 以 root 权限执行 apt installmanpages-posix-dev 安装手册。
Ubuntu
Ubuntu 和其他基于 Ubuntu 的发行版对非自由软件没有那么严格,所以我们可以直接 安装对应的软件包。执行 sudo apt install manpages-posix-dev。
3.5.2 实践步骤
头文件非常多,所以重要的是学习哪些头文件是我们需要的以及如何查找它们的信息。通过阅读手册,可以知道如何列出所有的头文件。接下来我们会介绍这些。
在前面的范例中,我们使用了 sysinfo() 和 getpid() 函数。这里将学习如何找到 系统调用的相关信息以及所需的头文件。
1.首先,我们阅读 sysinfo() 的手册:
$> man 2sysinfo
在 SYNOPSIS 头文件下面,我们看到下面 2 行:
#include
int sysinfo(structsysinfo *info);
2. 这指我们要包含 sys/sysinfo.h 才能使用 sysinfo() 函数。函数需要一个 sysinfo 的数据结构作为参数。在 DESCRIPTION 中,可以看到 sysinfo 数据结构的组成。
3.查阅 getpid()。这是一个 POSIX 函数,因此有更多的信息:
$> man 2getpid
在 SYNOPSIS 下,需要包含两个头文件:sys/types .h 和 unistd .h。另外,该 函数返回一个 pid_t 类型的值。
4.我们继续学习,打开 sys/types .h 的手册:
$> mansys_types.h
在 NAME 下,我们看到头文件包含的数据类型。在 DESCRIPTION 下,可以看到 pid_t 数据类型用于进程 ID 和进程组 ID,但是没有指明实际的数据类型。所以,让 我们继续向下滚动,直到找到一个写着 Additionally 的副标题。这里写着 blksize_t、 pid_t 和 ssize_t 应该是有符号整数类型。任务完成,现在我们知道它是一个有 符号整数类型,可以使用 %d 格式化运算符来打印它。
5.我们进一步学习。阅读 unistd .h 手册:
$> man unistd.h
6.在手册中搜索 pid_t,可以找到更多关于它的信息:
输入一个字符 /,再输入 pid_t,按回车键搜索。按 n 搜索下一个出现单词的位置。你会发现其他函数也返回 pid_t 类型,如 fork()、getpgrp() 和 getsid() 等。
7. 当你阅读unistd .h 手册时,可以看到头文件中声明的所有函数;如果找不到,可 以搜索 Declarations。按 /,输入 Declarations,然后按回车键。
3.5.3 它是如何工作的
手册中 7posix 或 0p 特殊章节取决于你的 Linux 发行版,这部分内容来自 POSIX Programmer’s Manual。比如,当你打开 man unistd .h,可以看到 POSIX Programmer’s Manual,而不像打开 man 2 write 时,你会看到 Linux Programmer’s Manual 。POSIX Programmer’s Manual 来自电气和电子工程师协会( IEEE)和开放组织,而不是来自 GNU 项目或 Linux 社区。
因为 POSIX Programmer’s Manual 不是自由的(就像在开源中一样),Debian 选择不把 它放在主软件源中。这就是我们要添加 non-free库到 Debian 中的原因。
POSIX 是 IEEE 制定的一组标准。该标准的目的是在所有 POSIX 操作系统(大多数 UNIX 和类 UNIX 系统)中实现一个通用的编程接口。如果你只在程序中使用 POSIX 函数 和 POSIX 头文件,它将与所有其他UNIX 和类 UNIX 系统兼容。其实际实现可能因系统而 异,但整体功能应该是相同的。
有时,我们需要一些特定信息(比如pid_t 是哪种类型)时,需要阅读多个手册。
这里的主要内容是通过函数的手册找到相应的头文件,然后根据头文件的手册找到更 多信息。
3.5.4更多
POSIX 头文件手册是手册的一个特殊部分,没有在man man 中列出。在 Fedora 和 CentOS 下,这部分称为 0p;在 Debian 和 Ubuntu 下,它被称为 7posix。
提示
你可以通过 apropos . 命令列出指定部分的所有手册(点表示匹配所有)。
比如,要列出第 2 节中的所有手册,输入 apropos -s 2. (包括点,它是命令的一 部分)。要列出 Ubuntu 下 7posix 特殊部分中的所有手册,输入 apropos -s 7posix.。
3.6 定义功能测试宏
在本节中,我们将学习一些常见的 POSIX 标准、如何使用它们、为什么要使用它们, 以及如何在功能测试宏中指定它们。
我们已经学习了几个包含 POSIX 标准以及一些特定 C 标准的示例了。例如,使用 getopt() 时,在源代码最顶部定义了 _XOPEN_SOURCE 500 (第 2 章中的mph-to- kph_v2.c 示例,它可以使程序更易于编写脚本)。
功能测试宏控制那些出现在头文件中的定义。我们可以通过两种方式来使用,通过功 能测试宏阻止我们使用非标准的定义来构建可移植的应用程序,或者反过来,允许我们使 用非标准的定义。
3.6.1 准备工作
我们将在本范例中编写 2 个程序:str-posix.c 和 which-c.c。你可以从 https://github.com/PacktPublishing/Linux-System-Programming-Techniques/ tree/master/ch3 下载它们,也可以跟随下文编写它们。你还需要我们在第 1章中安装 的 GCC 编译器。
3.6.2 实践步骤
这里,我们将学习功能测试宏、 POSIX 标准、 C 标准,以及其他相关知识的内部原理。
1. 把下面的代码写入文件,并将其命名为 str-posix.c。这个程序只简单地使用 strdup() 复制一个字符串,并打印它。注意,我们在此处需要包含头文件string.h :
#include
#include
int main(void)
{
char a[] = "Hello";
char *b;
b = strdup(a);
printf("b
= %s
", b);
return 0;
}
2.让我们看看用 C99 标准编译程序会发生什么。你会看到不止一条错误信息:
$> gcc -Wall -Wextra -pedantic -std=c99
> str-posix.c-o str-posix
str-posix.c: In function 'main':
str-posix .c9: warning: implicit declaration of
function 'strdup'; did you mean 'strcmp'? [-Wimplicit-
function-declaration]
b = strdup(a);
^~~~~~
strcmp
str-posix.c7 assignment to 'char
*' from
'int' makes pointer from integer withouta cast [-Wint-
conversion]
b = strdup(a);
3. 这里产生了一个非常严重的警告,不过编译成功了。如果我们尝试运行程序,它会 在某些发行版上失败,但在某些发行版上不会。这就是所谓的未定义行为:
$> ./str-posix
Segmentation fault
但是在另一些 Linux 发行版上,我们看到下面的输出:
$> ./str-posix
b = Hello
4. 现在到了最有趣,但同时也令人困惑的部分。这个程序崩溃的原因只有一个,但有
几个可能的解决方案。我们都会在这里介绍。程序崩溃的原因是strdup()不是 C99 的一部分(我们将在 3.6.3节介绍为什么它有时会生效)。最直接的解决方案是 查看手册,其中明确指出我们需要将 _XOPEN_SOURCE 功能测试宏设置为 500 或 更高。为了实验,我们将它设置为 700 (我稍后会解释原因)。在 str-posix .c 的 最顶部添加以下行,它需要在任何include 语句之前的第一行。否则,它将不起 作用:
#define _XOPEN_SOURCE700
5.现在你已经添加了上述行,我们重新编译程序:
$> gcc -Wall -Wextra -pedantic -std=c99
> str-posix.c-o str-posix
6. 现在没有警告了,我们运行程序:
$> ./str-posix
b = Hello
7. 这是其中一种最显而易见的解决方案。接下来删除文件中的第一行(#define这行)。
8. 删掉 #define 这行,我们重新编译程序,但是这次,我们在编译时设置功能测试 宏。通过 GCC中的 -D 参数设置:
$> gcc -Wall -Wextra -pedantic -std=c99
> -D_XOPEN_SOURCE=700 str-posix.c -o str-posix
9. 再次运行程序:
$> ./str-posix
b = Hello
10.这是第二个解决方案。但是当我们用 man feature_test_macros 阅读功能 测试宏的手册时,可以看到 _XOPEN_SOURCE 设置成 700或更大的值的效果和 _POSIX_C_SOURCE 设置成 200809L 或更大的值的效果是一样的。我们现在尝试 用 _POSIX_C_SOURCE 重新编译程序:
$> gcc -Wall -Wextra -pedantic -std=c99
> -D_POSIX_C_SOURCE=200809L str-posix.c -o str-posix
11. 这样也可以工作。现在,我们用最后一种也是最危险的解决方案。我们不设置任何 C 标准或任何功能测试宏,重新编译程序:
$> gcc -Wall -Wextra -pedantic str-posix.c
> -o str-posix
12.没有警告, 我们运行一下:
$> ./str-posix
b = Hello
13. 当我们只定义所有这些宏和标准时,这到底如何工作?好吧,事实证明,当我们不 设置任何 C 标准或功能测试宏时,编译器有一些默认设置。为了证明这一点,并了
解编译器的工作原理,我们编写以下程序。将它命名为 which-c .c。该程序将打 印正在使用的 C 标准和定义的功能测试宏:
#include
int main(void)
{
#ifdef __STDC_VERSION__
printf("Standard
C version: %ld
",
__STDC_VERSION__);
#endif
#ifdef _XOPEN_SOURCE
printf("XOPEN_SOURCE:
%d
",
_XOPEN_SOURCE);
#endif
#ifdef _POSIX_C_SOURCE
printf("POSIX_C_SOURCE:
%ld
",
_POSIX_C_SOURCE);
#endif
#ifdef _GNU_SOURCE
printf("GNU_SOURCE:
%d
",
_GNU_SOURCE);
#endif
#ifdef _BSD_SOURCE
printf("BSD_SOURCE:
%d
", _BSD_SOURCE);
#endif
#ifdef _DEFAULT_SOURCE
printf("DEFAULT_SOURCE:
%d
",
_DEFAULT_SOURCE);
#endif
return 0;
}
14.我们在不设置任何 C 标准和功能测试宏的情况下编译并运行程序:
$> gcc -Wall -Wextra -pedantic which-c.c -o which-c
$> ./which-c
Standard C version:
201710
POSIX_C_SOURCE: 200809
DEFAULT_SOURCE: 1
15. 我们指定编译时使用 C99 标准,然后重新编译 which .c。这里编译器会强制执行 严格的 C 标准并禁止原来默认会设置的一些功能测试宏:
$> gcc -Wall -Wextra -pedantic -std=c99
> which-c.c -owhich-c
$> ./which-c
Standard C version:
199901
16.让我们看看如果设置 _XOPEN_SOURCE 等于 600 会发生什么:
$> gcc -Wall -Wextra -pedantic -std=c99
> -D_XOPEN_SOURCE=600 which-c.c -o which-c
$> ./which-c
Standard C version:
199901
XOPEN_SOURCE:
600
POSIX_C_SOURCE:
200112
3.6.3 它是如何工作的
在实践步骤的第 1 ~ 10步中, 我们看到了使用不同的标准和功能测试宏时程序会发生 什么。我们还注意到在没有指定任何C 标准或功能测试宏的情况下,编译器也可以出人意 料地正常运行。这是因为 GCC (以及其他编译器)默认设置了一些功能测试宏和 C 标准。但我们不能依赖这个默认设置。自己指定总是更安全。这样,我们知道它一定会起作用。
在第 13步中,我们编写了一个程序来打印编译时默认设置的功能测试宏。为了防止编 译器在未设置功能测试宏时产生错误,我们将所有printf() 行包装在 #ifdef 和 #endif 语句中。这些语句是编译器的if 语句,不是 C程序的 if 语句。例如以下行:
#ifdef _XOPEN_SOURCE
printf("XOPEN_SOURCE:
%d
", _XOPEN_SOURCE);
#endif
如果 _XOPEN_SOURCE 未定义,则编译的预处理阶段后不包含此printf() 行。反之 _XOPEN_SOURCE 被定义,它将被包括在内。我们将在下一范例中介绍什么是预处理。
在第 14步中,我们看到在系统上,编译器将 _POSIX_C_SOURCE 设置为 200809 时 有效。但是手册说我们应该将 _XOPEN_SOURCE 设置为 500 或更大。怎么会这样呢?
如果我们阅读功能测试宏的手册( man feature_test_macros),会看到 _XOPEN_ SOURCE 设置成 700 或更大与 _POSIX_C_STANARD 设置为 200809 或更大的效果相同。由 于 GCC 已经默认设置 _POSIX_C_ STANDARD为 200809,所以这和 _XOPEN_SOURCE等于 700 具有相同的效果。
在第 15 步中,我们了解了当指定一个标准,比如 -std=c99 时,编译器会强制执行 严格的 C 标准。这就是 str-posix .c 无法运行(在编译期间收到警告)的原因。它不是 一个标准的 C 函数,而是 POSIX 函数。这就是为什么我们需要包含 POSIX 标准来使用它。当编译器使用严格的 C 标准时,不会启用其他功能。当系统中的 C 编译器支持 C99 时, 这 会使我们编写的代码可以移植到所有系统。
在第 16 步中,我们在编译程序时指定 _XOPEN_SOURCE 等于 600,这样同时也会将 _POSIX_C_STANDARD 设置为 200112。我们可以在手册( manfeature_test_macros) 中阅读相关内容:“ [ 当 ]_XOPEN_SOURCE 定义为大于或等于 500 的值时 [...]以下宏 _POSIX_C_SOURCE 也会被隐式定义 [...]”。
功能宏有什么用呢,它们如何影响代码 ?
系统头文件里充满了#ifdef 语句,功能测试宏是否设置决定了是否启用和禁用各种 功能和特性。例如,当我们使用 strdup() 函数时,string .h 头文件有包含在 #ifdef 语句中的strdup() 函数。这些语句检查是否定义了 _XOPEN_SOURCE 或其他一些 POSIX标准。如果未指定此类标准,则 strdup() 不可见。这就是功能测试宏的工作原理。
但是在第 3 步中,为什么程序在某些发行版上执行会报段错误,有些则不会 ? 就像前 文提到的,如果没有功能测试宏,代码是没有 strdup() 的声明的,发生的事情是不确定 的。由于某些特定的实现细节,它可能会起作用,也可能不起作用。当我们编程时,应该始终避免未定义的行为。某些程序可以在特定的 Linux 发行版上运行,这并不能保证它可 以在其他发行版的计算机上运行。因此,我们应该始终努力按照标准编写正确的代码。这样才能避免未定义的行为。
3.6.4更多
我们定义的所有这些功能测试宏都应该对应于 POSIX 或其他标准。这些标准背后的思 想是在不同的 UNIX 版本和类 UNIX 系统之间创建一个统一的编程接口。
如果你想要深入研究标准和功能测试宏,有一些优秀的手册可以阅读。例如:
man 7 feature_test_macros[这里可以阅读到所有功能测试宏对应的特定标 准,例如 POSIX 、Single Unix Specification 、XPG (X/Open Portability Guide)等 ]
man 7 standards (有关标准的更多信息)
man unistd .h
man 7 libc
man 7 posixoptions
审核编辑:汤梓红
-
Linux内核中C语言宏的使用技巧2023-07-21 1198
-
[推荐]linux下的c语言编程简介2009-04-29 3955
-
Labview 深入探索2012-04-27 3385
-
LabVIEW_深入探索2012-08-31 2944
-
LabVIEW 深入探索2015-07-01 2724
-
Linux中的汇编语言2011-04-07 784
-
linux内核C语言的编程风格2017-09-26 933
-
嵌入式Linux与物联网软件开发C语言内核深度解析书籍的介绍2019-05-15 1688
-
linux中编译c语言的方法2020-06-09 1967
-
Linux下C语言编程入门教程详细说明2020-08-25 2280
-
基于Linux的C语言编程入门教程2021-06-15 1269
-
C语言_Linux基本命令与C语言基础2022-08-14 2421
-
【Linux + C语言】C语言获取文件大小的方法都在这2022-08-31 5004
-
Linux内核中常用的C语言技巧有哪些2023-05-12 1506
-
浅析Linux内核中常用的C语言技巧2023-06-25 1087
全部0条评论

快来发表一下你的评论吧 !
