

一种用于自监督单目深度估计的轻量级CNN和Transformer架构
描述
摘要
大家好,今天为大家带来的文章: Lite-Mono:A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation 自监督单目深度估计不需要地面实况训练,近年来受到广泛关注。
设计轻量级但有效的模型非常有意义,这样它们就可以部署在边缘设备上。许多现有的体系结构受益于以模型大小为代价使用更重的主干。
在本文中,我们实现了与轻量级ar结构相当的结果。具体来说,我们研究了cnn和transformer的有效结合,并设计了一个混合架构Lite-Mono。提出了连续扩展卷积(CDC)模块和局部全局特征交互(LGFI)模块。
前者用于提取丰富的多尺度局部特征,后者利用自注意机制将长范围的全局信息编码到特征中。实验证明,我们的完整模型在精度上优于Monodepth2,可训练参数减少了80%左右。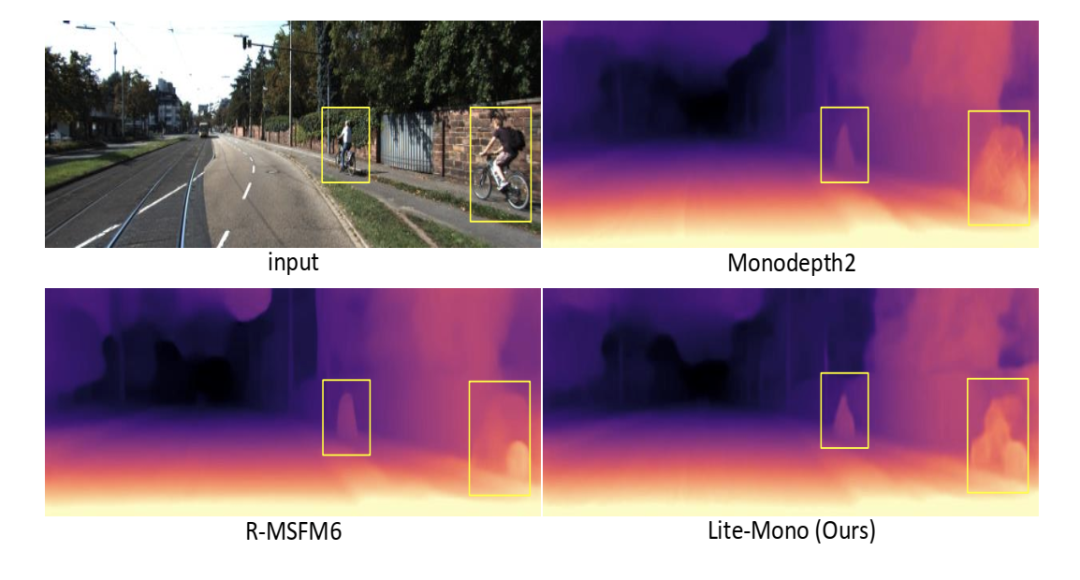
图1 我们的完整模型Lite-Mono的参数比Monodepth2[15]和R-MSFM[44]少,但生成的深度图更准确。
主要工作与贡献
综上所述,我们的贡献如下:
我们提出了一种新的轻量级架构,称为Lite-Mono,用于自监督单目深度估计。我们证明了它的有效性与模型大小和FLOPs
与竞争较大的模型相比,所提出的架构在KITTI[13]数据集上显示出更高的精度。它用最少的可训练参数达到了最先进的水平。在Make3D[31]数据集上进一步验证了模型的泛化能力。为了验证不同设计方案的有效性,还进行了额外的消融实验
在Nvidia Titan XP和Jetson Xavier平台上测试了该方法的推理时间,验证了该方法在模型复杂度和推理速度之间的良好平衡。
算法流程
1.总体结构
多篇论文证明,一个好的编码器可以提取更多有效的特征,从而改善最终结果[15,17,42]。本文着重设计了一种轻量级编码器,可以对输入图像中的有效特征进行编码。图2显示了建议的体系结构。它由一个编解码器DepthNet(章节3.2)和一个PoseNet(章节3.3)组成。DepthNet估计输入图像的多尺度反深度图,PoseNet估计两个相邻帧之间的相机运动。然后生成重建目标图像,计算损失以优化模型(章节3.4)。
增强局部特特征:使用较浅的网络而不是较深的网络可以有效地减小模型的大小。如前所述,浅层cnn的接受野非常有限,而使用扩张卷积[41]有助于扩大接受野。通过叠加提出的连续扩张卷积(CDC),网络能够在更大的区域“观察”输入,同时不引入额外的训练参数。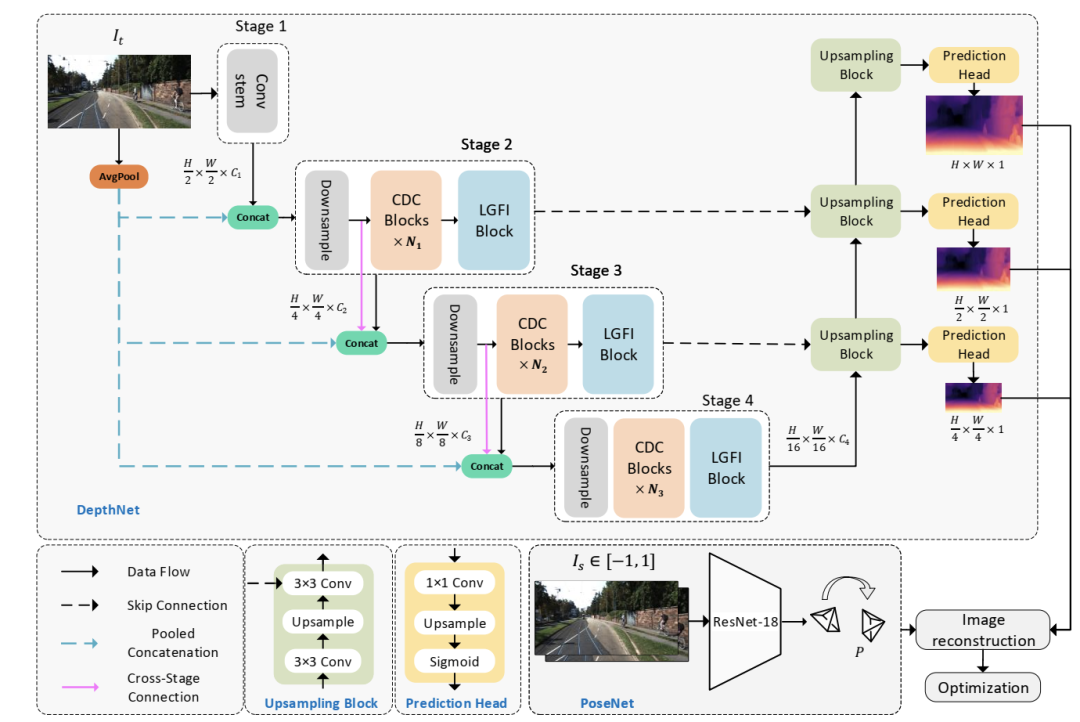
图2 拟议的Lite-Mono概述。我们的Lite-Mono有一个用于深度预测的编码器-解码器DepthNet,以及一个常用的PoseNet[15,44]来估计相邻单目帧之间的姿势。深度网络的编码器由四个阶段组成,我们提出使用连续扩张卷积(CDC)模块和局部全局特征交互(LGFI)模块来提取丰富的层次特征。这些模块的详细信息如图3所示。
低计算量的全局信息:增强的局部特征不足以在没有Transform的帮助下学习输入的全局表示来建模远程信息。原Transformer[8]中的MHSA模块的计算复杂度与输入维数呈线性关系,因此限制了轻量化模型的设计。局部全局特征交互(Local-Global Features Interaction, LGFI)模块采用跨协方差注意力[1]来计算沿特征通道的注意力,而不是跨空间维度计算注意力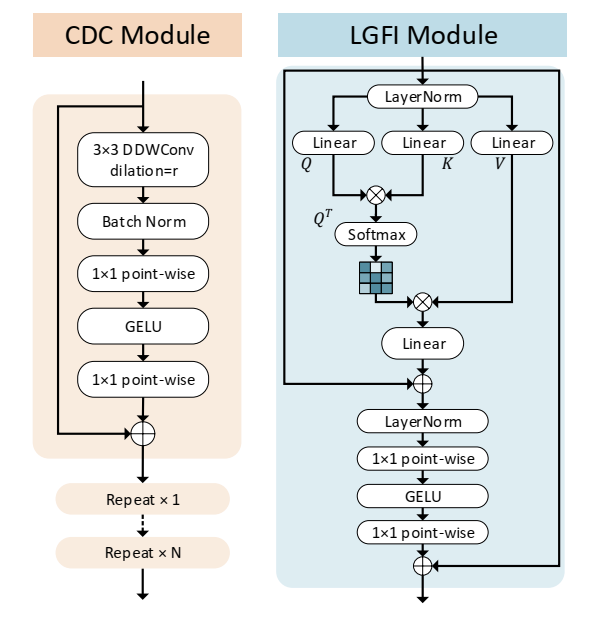
图3 所提出的连续扩展卷积(CDC)模块和局部全局特征交互(LGFI)模块的结构。在每个阶段,不同扩张速率的CDC模块重复N次。
2.DepthNet
2.1 编码器
深度编码器。Lite-Mono在四个阶段聚合了多尺度特征。大小为H ×W ×3的输入图像首先被输入到卷积干中,在那里图像被3 ×3卷积向下采样。接下来进行两个额外的3个×3卷积(stride =1)进行局部特征提取,我们得到大小为H2 ×W2 ×C1的特征映射。
在第二阶段,将特征与池化后的三通道输入图像进行拼接,再使用stride =2的3 ×3卷积对特征图进行下采样,得到大小为H 4 H 4 ×W4 ×C2的特征图。在下采样层中,将特征与平均池化的输入图像进行拼接,可以减少特征尺寸减小所造成的空间信息损失,这是受到ESPNetv2[3]的启发。然后,我们使用提出的连续扩张卷积(CDC)模块和局部-全局特征交互(LGFI)模块来学习丰富的分层特征表示。
2.2 连续扩张卷积(CDC
连续扩张卷积(CDC)。提出的CDC模块利用扩张卷积提取多尺度局部特征。不同于只在网络的最后一层使用并行扩张卷积模块[6],我们在每个阶段插入几个连续的不同扩张速率的扩张卷积,以实现足够的多尺度上下文聚合。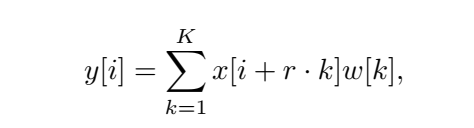
2.3 局部全局特征交互(LGFI)
给定一个维度为H的输入特征映射X ×W ×C,我们可以将其投影到相同维度的查询Q =XWq,键K =XWk,值V =XWv,其中Wq、Wk和Wv是权重矩阵。我们使用交叉协方差注意[1]来增强输入X: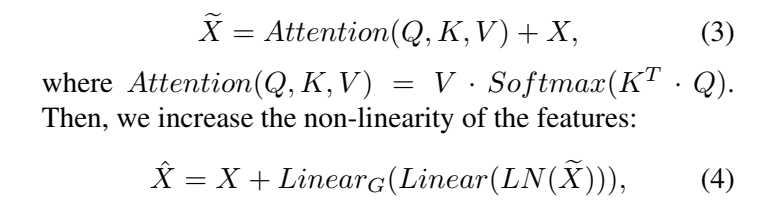
2.4 解码器
不同于使用复杂的上采样方法[44]或引入额外的注意模块[3],我们使用了从[15]改编而来的深度解码器。作为 如图2所示,它使用双线性上采样来增加空间维度,并使用卷积层来连接编码器的三个阶段的特征。每个向上采样块跟随一个预测头,分别以全分辨率、12分辨率和14分辨率输出逆深度图。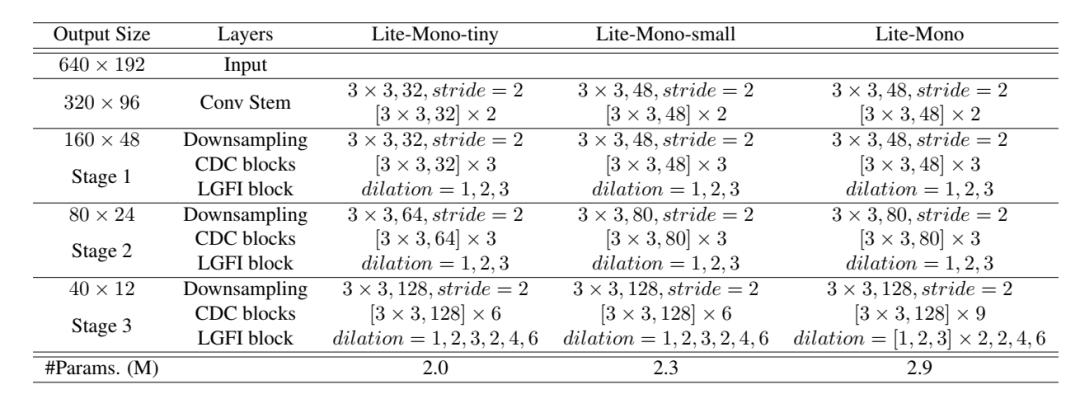
图3 网络结构表
实验结果
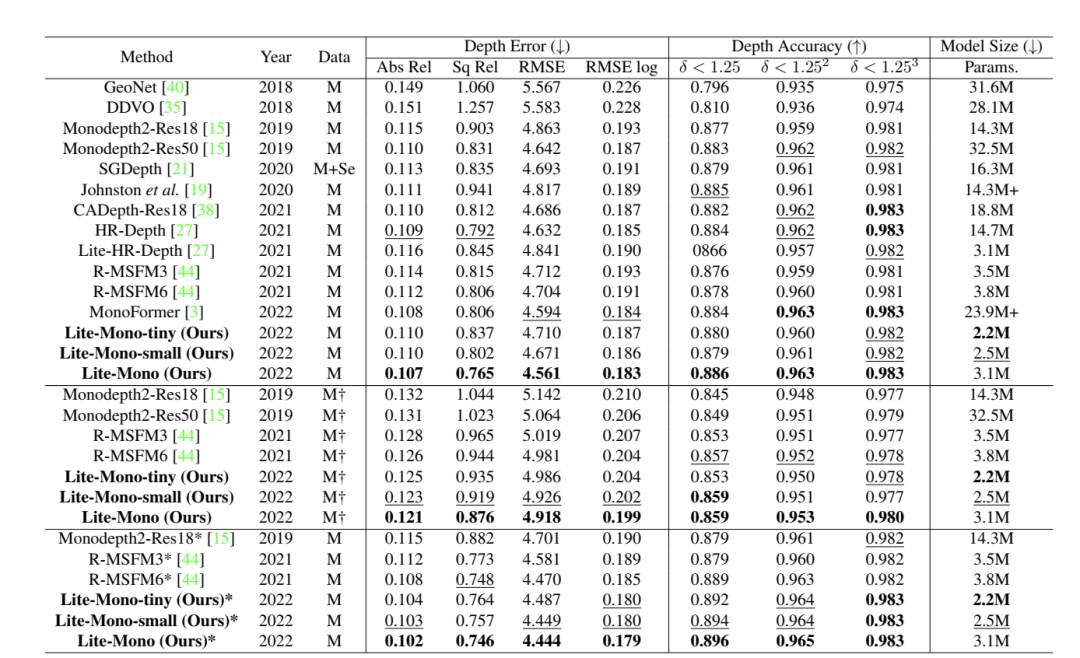
表1我们的模型与KITTI基准上使用特征分割[9]的一些最近的代表性方法的比较。除非另有说明,否则所有输入图像都将调整为640 ×192。最佳和次优结果分别用粗体和下划线突出显示。”M”:KITTI单目视频,“M+Se”:单目视频+语义分割,“*”:输入分辨率1024 ×320,“My”:未经ImageNet预训练[7]。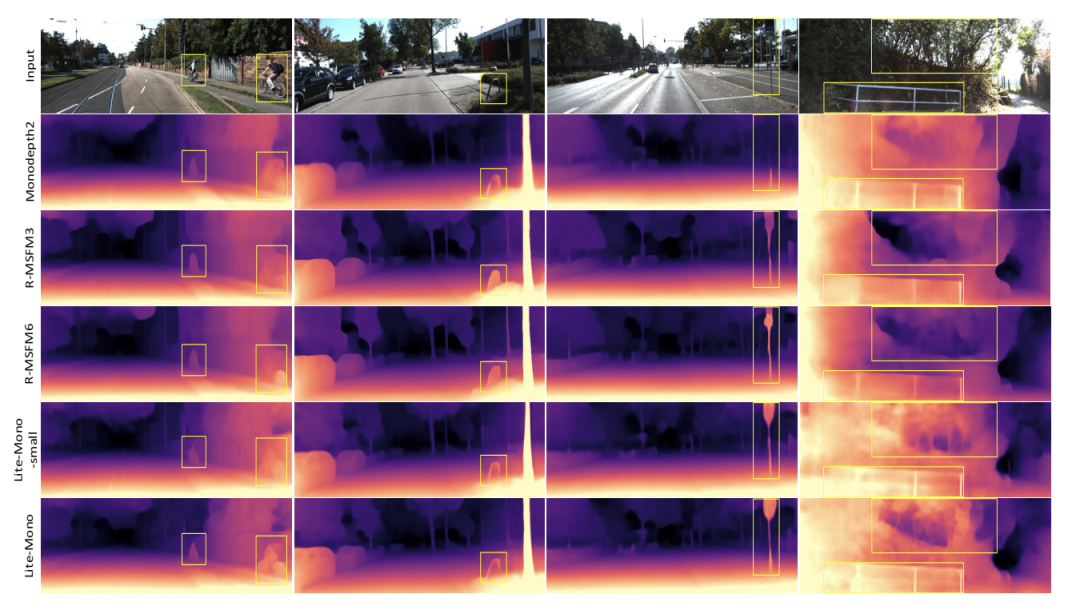
图4 KITTI的定性结果。我们分别展示了Monodepth2 [15],R-MSFM3 [44],R-MSFM6 [44],Lite-Mono-small(我们的)和Lite-Mono(我们的)生成的一些深度图。Monodepth2和R-MSFM的接受域有限,因此它们的深度预测有些不准确。相反,我们的模型可以产生更好的结果
图5 Make3D数据集上的定性结果。我们比较Monodepth2[15]和R-MSFM[44]。我们的模型可以感知不同大小的物体 图3KITTI数据集上的DRAFT预测示例。从(a)输入的RGB图像中,我们显示(b)光流估计,(c)深度估计,和(d)从深度和场景流估计中预测的光流 。
审核编辑:刘清
-
基于transformer和自监督学习的路面异常检测方法分享2023-12-06 3332
-
轻量级深度学习网络是什么2020-04-23 3176
-
一种超轻量级的flashKV数据存储方案分享2021-12-20 1305
-
基于单目深度估计的红外图像彩色化方法_戈曼2017-03-17 713
-
基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度2018-06-04 36540
-
一种轻量级的通信协议 - MAVLink2020-03-12 6459
-
一种轻量级时间卷积网络设计方案2021-03-22 1192
-
采用自监督CNN进行单图像深度估计的方法2021-04-27 1328
-
一种新的轻量级视觉Transformer2022-12-19 2190
-
介绍第一个结合相对和绝对深度的多模态单目深度估计网络2023-03-21 9053
-
一种端到端的立体深度感知系统的设计2023-05-26 1728
-
一种利用几何信息的自监督单目深度估计框架2023-11-06 1198
-
动态场景下的自监督单目深度估计方案2023-11-28 1684
-
单目深度估计开源方案分享2023-12-17 1959
-
【AIBOX 应用案例】单目深度估计2025-03-19 1437
全部0条评论

快来发表一下你的评论吧 !
