

别只关心315打老虎,来看看全年无休的AI打假
描述
一年一度的“3·15”消费者权益日如期而至,这一天,全民最期待、各家公关最紧张的环节,应该是“打老虎”的高光时刻。
某些高高在上的巨头或大牌的“套路”被曝光,次日忙不迭道歉整改,让广受其害但维权困难的消费者们拍手称快,这样的故事大家已经耳熟能详了。但在3月15日这一天之外,人们日常还会面临各式各样、层出不穷的造假售假,不能都指望一天时间、一台晚会、打几只老虎来解决。
能够全年无休的AI打假师,也就被科技企业推进了大众的视野。不过,想要真的用好AI打假,还要对它的逻辑、能力和有限性,有一定的了解。
本文希望通过科普AI打假的段位,帮大家在日常维权时用好科技的武器。
初级段位:机器视觉PK假货
提到打假,很多人日常接触到的假东西,应该是各类假冒伪劣、以假乱真的消费品。以消费者服务平台——黑猫投诉为例,对假货、售假、货不对板的投诉量非常之大。
先说AI应用在货品打假上的基本逻辑。
逻辑:人工打假难、打假贵、周期长、套路多——通过机器视觉提升“眼力”。
人工打假难:随着现代制作工艺技术越发精湛,越来越多的“大牌”包包、高仿潮鞋、收藏品伪作,不再是粗制滥造的“一眼假”,可以做到以假乱真的地步,看走眼的专家数不胜数。有些造假技艺出神入化的“古玩”,甚至连专业仪器都不能准确鉴定。
人工打假贵:人工甄别需要多名鉴定师“背靠背”鉴定,因此收费也往往是在线鉴定的数倍。国内某奢侈品鉴定平台,在线鉴定49元,实物鉴定收费则达到199元。
周期长:制假售假贩假大多是流水线式团队作战,批量生产,加上越来越多生活富裕的人加入消费/收藏的队伍,交易数量多,相应的投诉量也增多,维权周期也很长,很多消费者只能选择自认倒霉。
套路多:很多人觉得,专家的意见很可靠,专业机构出具的证书有背书作用,但架不住造假套路太多,市场上充斥着仅在鉴定培训班学习过几天而取得“结业证书”的廉价大师,还有不具备相应条件又未经过合法审批的鉴定中介机构浑水摸鱼,证书只要给钱就能出,所以即使人工鉴定也可能陷入套路。
所以,近年来通过在线平台,用户拍摄照片上传,AI系统比对鉴定,变得流行起来。有企业推出的“AI鉴定师”,一秒钟能识别20个假冒商标,有的艺术品鉴定,可以对文物进行“一物一图”的识别鉴定,规避仿造的问题。这些都是靠什么能力实现的呢?
能力:机器视觉的快、准、惠。
面对假货,没有“眼力”就会处于弱势。机器视觉是AI的一个分支,让机器能够“看”和“理解”视觉信息,类似于人类的“眼力”。
首先,机器视觉系统会对物品的高精度图像进行识别和分析,提取出物品的形状、颜色、纹理等相关特征。
然后,系统结合已知真假货的数据集,根据真假货的规律和特征,比如正品大牌包包的五金件颜色,logo字母的形状等,进行比照。
当然,随着造假技术的提高,很多直观的细节不再是造假的难点,仅仅单一特征的图像比对是不够的。比如有的古籍造假,会使用年代久远的纸张,文字或图案通过软件调色贴近真迹,真中有假,假中藏真,让很多专家也只能凭感觉“觉得哪里不对”,而AI算法可以快速找到多种特征的彼此矛盾之处,找到真假“杂拼”的违和感,再由人工鉴定师进行判断。
通过机器视觉,可以快速、准确地识别出假货特征,与人工鉴定相结合,降低鉴定的整体成本。
有限性:造假升级,数据瓶颈
当然,基于机器视觉的在线鉴定,还不能百分百取代人工鉴定,技术的有限性主要来自于:
一是造假手段的科技化。造假不可怕,就怕造假的人有文化,现在很多产品的造假技术也上了一个新的台阶,比如购入正品后,拆解成几个部分,再拼凑在一起高价卖出;有的大牌包包在各种细节上都与正品一致,不同的可能是五金件的铜含量不一样,这就需要借助专业的金属检测设备,仅靠机器视觉识别是不够的。
二是真假数据的限制。机器视觉算法的准确率,需要庞大的真假货特征数据集来支持,而大牌产品更新换代很快,数据集的速迭代速度如果跟不上,就会让新款假货成为漏网之鱼。此外,很多艺术品/收藏品都是孤件,收藏家没有动力将其数字化后共享数据,这也会影响算法结果的准确度。同时,很多鉴定标准都是行业专家口口相传的口诀,没有形成一定的算法规则,垂直品类如紫砂壶、明青花等,行业知识匮乏、数据稀疏,也会影响算法的有效性。
这里要说的是,以假乱真的造假,更多用于艺术品、奢侈品等价值昂贵的产品上,吸引的群体比较有限。正是市面上大量流通的大众消费品,才导致了规模庞大的受害者,而这些产品的造假一般不会费心地精益求精,AI的到来,无疑提供了一把价廉物美的打假武器。
中级段位:Anti-Deepfake PK Deepfake
造谣一张嘴,辟谣跑断腿。当深度伪造技术Deepfakes换脸轻而易举,图像、音频以假乱真,很多人的脸被拿来做成虚假视频,在网络上疯狂传播,近年来越来越地引发维权。
逻辑:Deepfake带来的伪造危机——更强大的Anti-Deepfake自动甄别技术 “攻子之盾”。
你也许会说,被改头换面是公众人物、明星的烦恼,自己只是个普通人,干嘛要担心AI换脸。试想一下,这样的形象造假越来越多,让网络上的信息真伪难辨,权威专家的嘴型可以p,领导人的脸可以换,那会让没有专业辨识能力的普罗大众,陷入谣言和欺骗的信息海洋,在无形中损伤了整个社会的互信,引发集体信任危机。
此外,如果Deepfakes被用于非法用途,如诈骗、敲诈勒索等,很难保证黑客不会将其产业化、普及化,这样就会对更广大的群体带来形象和经济上的损害。我
我曾采访过一家智能金融机构,对方提到,通过在线视频确认借款人身份时,就可能会遇到深度伪造视频的攻击,提高了风控的难度。
所以,检测和消除深度伪造图像和视频,避免技术被恶意利用,也成为许多科技公司打造负责任的技术的一种选择。
能力:基于GAN(生成式对抗网络)的Anti-Deepfake算法,使用多个深度学习模型对输入数据进行分析,提取出视觉、语音和动态特征,并将它们结合为一个特征向量,与已知的生物特征进行比较。
Deepfakes算法不是完美的,缺少常识,所以伪造的脸存在很多不对劲的特征,但这些面孔本身看起来很逼真,靠人的肉眼“找茬”有点费劲,但AI可以快速找到这些线索。
比如一只耳朵上没有戴耳环(除非她是一个叛逆朋克少女),牙齿数量以及方向不对,衣服或背景的形态很不合常理。
有科学家找到了一种检测伪造的方法,研究团队发现Deepfakes难以准确再现常规的瞳孔。真正的人类瞳孔是一个规则的椭圆形,而Deepfakes生成的瞳孔明显不规则,因为它对人脸结构没有生理常识。
此外,有的伪造线索是动态的,比如声音和口型对不上,需要检测算法提取视频的音、画特征进行分析匹配。
有限性:真伪游戏,永无止境
通过AI自动检测来识别深度伪造的音视频,根本挑战在于伪造技术进化得非常快。
2018年纽约州立大学开发出一款“反换脸”AI刑侦工具,通过预测眼睛是否眨动的状态来识别伪造人脸,准确率达到 99%,但这款工具还没推广就失效了,因为Deepfakes技术进化了。
自动检测算法需要在高质量的数据集上进行训练,这些数据集要包括真实数据和合成数据,如果数据的多样性不足,训练视频和测试视频的相似性很高,那么实际检测的效果也会不理想。
此外,用户发现被深度伪造内容侵权后,问责和维权是非常难的,一般首先问责的是平台,对侵权视频/账号做出下架、删除、处罚等处理,但整个过程不确定性很大,还要和平台企业的客服、运营、公关、法务等多部门交锋,非常繁琐,很多用户只能选择不了了之。用户监督对检测技术的升级,影响有限。
只能希望数据隐私保护的相关法律持续完善和落地,科技企业加强技术伦理和研发,在这场真伪斗法中不断保障用户的权益。
高级段位:AI内容识别器PK AI作弊
ChatGPT的出现,将AIGC带入了新的巅峰。据《纽约时报》报道,大型语言模型(LLM)生成的文本,与人类编写的文本难以区分,资深大学教授也无法准确区分学生是否用ChatGPT写了论文作业。
所以,为了防止学生用AI作弊,纽约公立学校已全面禁止使用ChatGPT,美国一些学区也开始采取这一措施。
还有科学家让AI来检测ChatGPT撰写的医学研究摘要,不仅比论文剽窃检测器的效果好得多,而且比人类审稿人的成绩还高。也就是说,ChatGPT撰写的论文摘要,已经可以让人类专家都难辨真假了。
而就在今天,GPT-4问世,支持多模态的生成任务,对代码有超强的理解能力,这也使得AI内容识别器成为了一项必需品,来避免AIGC快速发展拉大“假内容”的识别难度。
逻辑:大型语言模型强大的生成能力导致AI沦为作弊工具——AI内容识别器,检测内容是人类写的还是AI写的。
能力:不详。
是的,作为一种最新最前沿的造假手段,目前还没有一种技术或软件,能够有效且准确地识别出用ChatGPT作弊内容。
AI内容识别的方法,目前有两种:
一种是黑盒检测,即通过统计特征的分析,找到AI文本和人类文本的区别,已经有多个团队或开发者,推出了相应的解决方案。
比如普林斯顿大学计算机科学专业的华裔学生Edward Tian开发的GPTZero,号称可以通过分析语言模型对文本的“喜爱”程度,以及AI写作一段文本时的“困惑”程度,通过“亲AI”分数来判断文章是否出自AI之手。
斯坦福大学提出的DetectGPT,认为人写文章和模型样本的摄动差异分布有显著差异,通过这个差异来检测一段文本是否由模型生成。
OpenAI也在前不久推出了AI生成内容识别器,但博客数据显示,检出成功率只有26%,对英文以外的语言,检测效果要差很多,并且不支持1000字符以内的短文本(因为人类写的和AI写的答案可能是一样的)。而且,一些AI生成的文本经过编辑之后,也可能规避掉检测。
大模型能力的提升,使得AIGC和人类的差距越来越小,导致AI内容识别器的检测准确性也难以保障。比如最新的GPT-4,表现相比GPT-3.5有了大幅提升,之前针对GPT-3等大型语言模型的检测工具,都面临失效的风险。
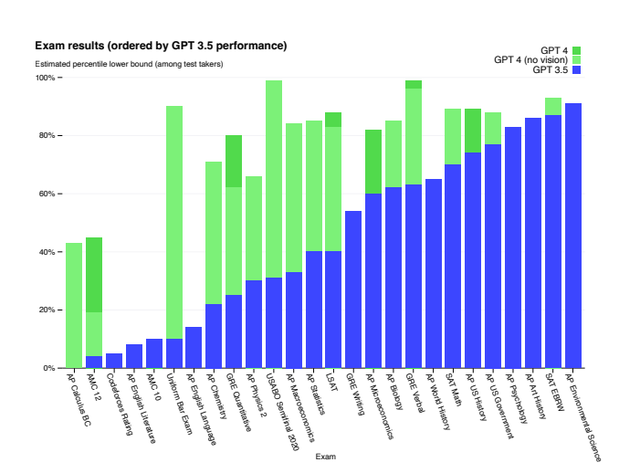
(GPT-4在大多数测试中表现优于GPT-3.5)
另一种是白盒检测,即模型的开发人员对AI内容进行一定的处理,从而满足检测目的。
此前OpenAI就声称,考虑给AI内容加上水印,在词汇选择上加入“不引人注意的秘密信号”,这样就能证明这段文字是 GPT 模型生成的。
这一方法的问题是,只能由模型开发者植入水印,模型开源之后可以通过微调来移除水印,也会失效。
有限性:AI检测技术的进步,慢于AI生成技术的进步。
说了这么多,当然不是为了把AI等新技术生成的东西都“一棒子打死”。
今天,我们能在博物馆里看到临摹仿制的复制品,这种“假”与欺骗无关;能靠Deepfakes将失德艺人的脸换掉,让作品继续上映,保住整个制作团队的心血;能用AI画出自己想象中的场景,当然也不能算是造假……
物品没有对错,技术没有好坏,错的只是人心,只是握刀的那只手。
作为普通人,我们能做的就是“知己知彼”,了解造假技术的逻辑、能力和局限,将捍卫自身权益的武器,掌握在自己手里。
审核编辑 黄宇
-
导热凝胶的特色有哪些,来看看2023-03-07 4559
-
CAD建筑制图入门加老虎窗2021-03-26 9164
-
来看看未来的智能家居合不合你的口味2020-12-03 2268
-
东力久特种电机股份有限公司正式成为315打假工作委员会认可的优质品牌2020-09-25 3584
-
AI用于打假应该支持吗2019-12-12 661
-
如何给人个人化服务?Louis Vuitton推AI聊天机器人2018-01-15 1635
-
好久没来了,来看看2017-03-09 1517
-
快来看看!Flyme 6 的效果如何,您喜欢吗?2016-12-29 1224
-
小编推荐资料包,需要的来看看2016-01-17 3016
-
模拟老虎机程序分享2015-01-13 12940
-
下来看看怎么样 下来看看怎么样 下来看看怎么样2013-05-13 1718
-
每天上来看看2012-12-22 1948
-
天天来看看~~~2012-12-15 0
-
很热闹,常来看看!2012-02-15 3432
全部0条评论

快来发表一下你的评论吧 !
