

Open AI团队发推正式宣布:GPT-4来了!
电子说
描述
今天凌晨,Open AI 团队发推正式宣布:GPT-4 来了!

我花了点时间,看完了 Open AI 团队对于 GPT-4 的整篇介绍。
GPT-4 介绍:https://openai.com/research/gpt-4
下面挑些重点,跟大家进行详细介绍。
GPT-4 基础能力
本次发布的 GPT-4 跟此前透露的消息一样,是一个多模态大模型,支持接受图像和文本输入,输出文本。
虽然没一步到位,把音视频也覆盖上,但如果能把图像与文本这两块做好,相信其应用潜力无限。
对于 GPT-4 的实际能力,团队也给大家提前打了一针强心剂,即便 GPT-4 在许多现实世界场景中能力不如人类,但在各种专业和学术基准上的表现,还是超过了人类的平均水平。
这里有一个数据是,在律师模拟考中,GPT-4 的成绩排在应试生的前 10% 中,而此前发布的 GPT-3.5,则在倒数 10% 的行列。
看到这里,不知道你发现没有,现在衡量 GPT 模型的能力,已经不是能否通过人类社会中的应试,而是看其参加的多种不同领域的专业应试,能够排到多靠前的位置。
在团队进行的多个 GPT-4 与 GPT-3.5 的考试测试中,发现这两个模型间存在很微妙的差异。
当任务的复杂性足够高时,GPT-4 比 GPT-3.5 更可靠、更有创意,并且能够处理更细微的指令。
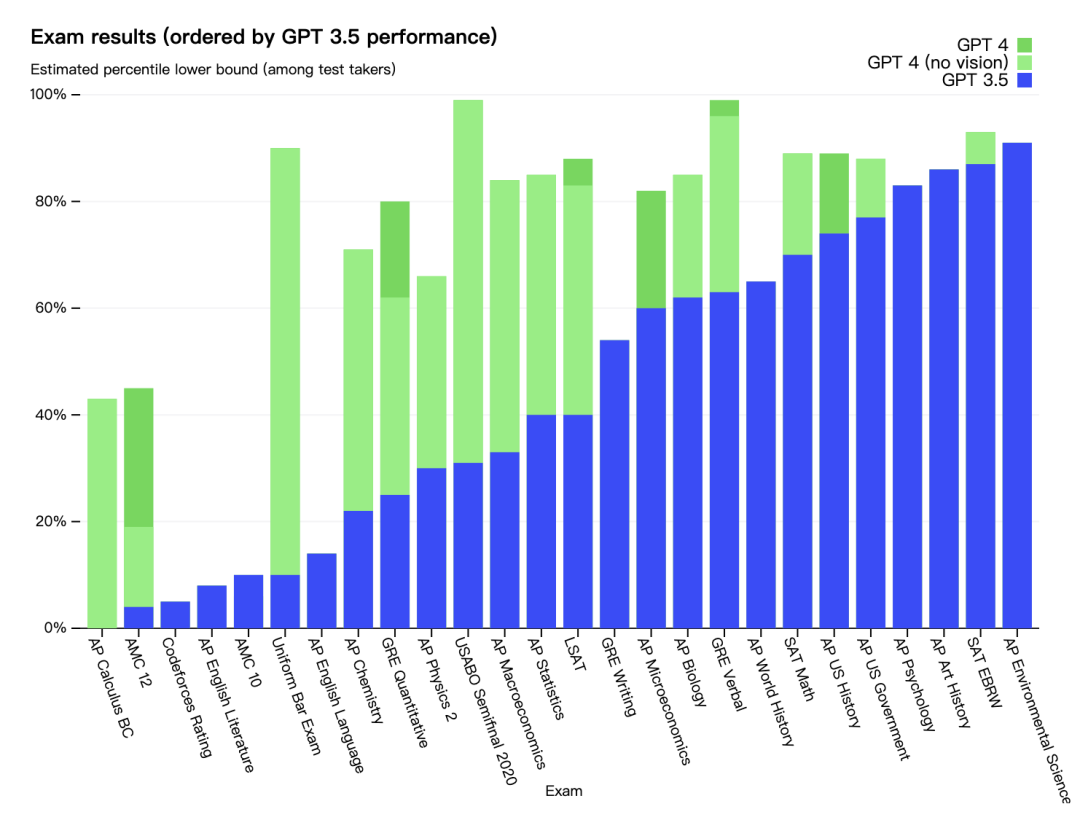
在 GPT-4 发布之前,Open AI 团队花了 6 个月的时间 ,使用对抗性测试程序,以及从 ChatGPT 得到的经验教训,对 GPT-4 进行了迭代调整 ,进而在其真实性、可操控性等方面取得了有史以来最好的结果。
在与当前机器学习模型进行基准评估对比后,GPT-4 大大优于现有的大型语言模型,以及大多数最先进的 (SOTA) 模型。
GPT-4 图像处理
当然了,GPT-4 本次最为令人看重的,还是它接受与处理图像的具体能力。
在官方报告中,团队提供了多个实际交互示例,这里我挑 2 个比较有代表性的给大家看下。
示例 1:理解图片
当你给 GPT-4 发送下面这张图片,并询问它,该图片有哪些不寻常的地方?

GPT-4 回答:这张照片的不同寻常之处在于,一名男子正在行驶中的出租车车顶上的熨衣板上熨烫衣服。
示例 2:识别与解析图片内容
将论文截图直接发送给 GPT-4,并要求它进行解析与总结。

除此之外,它还能解析报表图片并进行汇总,直接回答图片中包含的提问内容等操作。
不过,GPT-4 跟 GPT-3.5 类似,对训练数据中断后(2021 年 9 月)所发生的事情不太了解,也会犯一些在我们看来很简单的推理性错误,给用户提供不合理的建议,以及在生成的代码中引入安全漏洞。
对于这些潜在性的危险因素,团队也聘请了来自多个不同行业的专家对模型进行了优化调整,但是其具体效果,还需要等后面场景应用较为广泛后,才能得出结论。
开源项目:OpenAI Evals
为了让开发者能更好的评测 GPT-4 的优缺点,OpenAI 的技术团队还开源了 OpenAI Evals 项目,可用于自动评估 AI 模型性能的框架,以便用户能更专业的指导团队,进一步优化与改进模型。
该项目具有以下功能特性:
使用数据集生成提示;
衡量 OpenAI 模型提供的补全质量;
比较不同数据集和模型的性能。
GitHub:https://github.com/openai/evals
申请 GPT-4 API
目前,OpenAI 已面向开发者开放 GPT-4 API 的申请通道,大家想提前使用的话,可以先提交申请,进入 waitlist 中等待通过。
我吸取了上次 New Bing 开放申请后,苦等无果的惨痛教训。现如今对于这类工具,都是第一时间申请,后面就看 Open AI 什么时候能给我通过了。

申请通道:https://openai.com/waitlist/gpt-4-api
对了,如果你有 ChatGPT Plus 订阅会员,则可以直接获得 GPT-4 的试用权限,无需等待。不过有一定限制,在 4 小时内,最多只能发布 100 条信息。
获得访问权限后,用户当前还是只能向 GPT-4 模型发出纯文本请求,图像请求可能得等稍晚一些时间才对外开放。
以上,就是关于 GPT-4 的大致介绍。
审核编辑 :李倩
-
OpenAI推出新模型CriticGPT,用GPT-4自我纠错2024-06-29 1327
-
OpenAI计划宣布ChatGPT和GPT-4更新2024-05-13 1331
-
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型2024-03-13 1594
-
全球最强大模型易主,GPT-4被超越2024-03-05 1397
-
ChatGPT plus有什么功能?OpenAI 发布 GPT-4 Turbo 目前我们所知道的功能2023-12-13 2270
-
GPT-4没有推理能力吗?2023-08-11 1906
-
OpenAI宣布GPT-4 API全面开放使用!2023-07-12 2100
-
GPT-4已经会自己设计芯片了吗?2023-06-20 2174
-
微软GPT-4搜索引擎重大升级 新Bing开放AI能力2023-05-05 4029
-
GPT-4是这样搞电机的2023-04-17 1898
-
GPT-4 Copilot X震撼来袭!AI写代码效率10倍提升,码农遭降维打击2023-04-04 2163
-
关于GPT-4的产品化狂想2023-03-26 4005
-
GPT-4发布!多领域超越“人类水平”,专家:国内落后2-3年2023-03-16 6001
-
ChatGPT升级 OpenAI史上最强大模型GPT-4发布2023-03-15 3694
全部0条评论

快来发表一下你的评论吧 !
