

ChatGPT连续宕机五次,是真不把高可用当回事?
电子说
描述
最近一段时间以来,ChatGPT 火遍全球,然而在飞速的用户增长下,ChatGPT 却有点不堪重负,两天内宕机了五次。
这次宕机事件,再一次凸显了高可用架构的重要性,毕竟任何一个飞速发展的应用在两天内宕机五次,所带来的损失都是难以接受的。
如果说 ChatGPT 还是由于请求量激增导致的服务不稳定,那么以下几个案例就是纯粹的基础设施没做好而导致的服务宕机了:
2021年8月31日,美国在线办公软件 Notion 在全球范围内出现宕机。
2021年6月17日,美国在线协作工具 Figma 在全球范围内出现宕机。
2021年3月9日,全球最大的代码托管平台 GitHub 在全球范围内出现宕机。
它们事后都在推特上披露了事故原因,都是因为数据库/数据中心发生不稳定而导致的宕机事件,应用服务的基础设施稳定性、可用性再一次成为大型宕机事故的高发原因。
尤其是在 2023 年的现在,互联网已经成为了无处不在的基础设施,和电力一样成为了现代人生活中不可或缺的一部分,任何一个公司的应用如果发生了宕机事件都有可能失去在互联网发展的契机,因为对于用户来说,几乎每个赛道都有替代品,你的应用在我需要使用的时候出问题了,或许我转头就卸载下载竞品了。
所以现在的公司都在做应用的时候也都会非常关注应用架构,稍微大一点的公司或者是有长远发展的规划的公司,都会上云做一套高可用架构以保证突发情况能够顺利度过。
这就像你开车出门没买交强险,不小心追尾奔驰了,本来提前买保险2000块钱就能解决的事,这下子可能得花两万块钱才能解决,如果你再不幸一点,追尾了法拉利那可能得花二十万才能解决了。
无论哪种情况都远超你当初的提前投入。
那么,云厂商的高可用架构到底有什么优势能如此强大呢?
什么是高可用架构
在回答云上高可用架构之前,我们先来说说高可用架构。
高可用架构是指设计具有高度可靠性、稳定性、可扩展性和容错性的软件系统,以确保系统在面对大量请求和异常情况时能够保持稳定的性能和可用性。
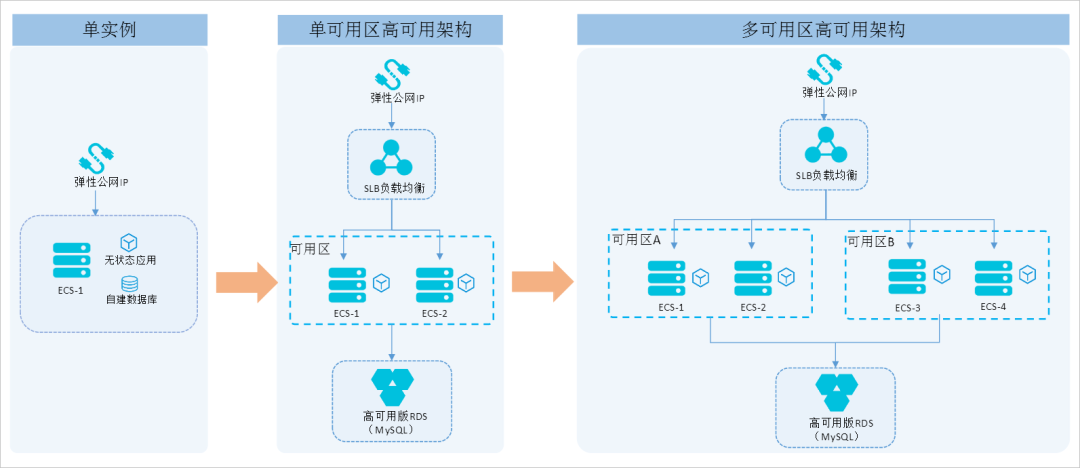
下图是一个简化版的软件架构发展历程图:
img
这张图大致将软件架构分为三个阶段:
单实例阶段:这个阶段用户量较少,数据库与应用都部署在同一台服务器上,数据库或者服务器网络分区出现问题,都会导致应用不可用。
单区高可用阶段:这个阶段服务器和数据库都已经集群化,集群中的机器分布在一个大区的不同机房中,集群中的任何一个机器发生问题,都不会影响整体的应用可用性,但是它们整体还是处在同一个区域的数据中心,所以这种方案也可以被称之为同城双活。
多区高可用阶段:多区高可用是在单区高可用的基础上将机房扩大到多个大区中,比如华东大区和华南大区,每个大区都要一整套完整的服务集群,大区与大区之间通过专线进行数据同步,这种设计可以在某个大区故障时立即切换流量到另一个大区,这个方案也是大家俗称异地多活。
越高级的架构抵御风险的能力越强,就像你家的房子(单实例)只能抗5级地震,但是别人家的房子(多区高可用)是为抗震单独设计过的,真到地震来了别人家的房子可以在八级地震下依然完好无损,这就是高可用的优势。
说到这,好像很多人会把高可用和高可靠傻傻分不清,那我就举一个例子来说明他俩的区别:
如果一个系统在每小时奔溃1ms,那么它的可用性超过99.9999%,但它是高度不可靠的。
如果一个系统从来不崩溃,但是每年要停机两星期保养,那它是高度可靠的,但是可用性只有96%。
在现代应用系统中,造成高可靠下降的因素多是不可抗力,所以都着力保障高可用优先,对于真正的 C 端客户来说,其实高可用和高可靠就是一回事,就是无论什么时候、出现什么情况,服务都能照常使用。
一般来说,传统的高可用的架构主要从以下四个方面来保证服务的高可用:
负载均衡:通过使用负载均衡器(如SLB,一般是 NGINX 集群)对多台服务器进行流量分发,可以提高系统的性能、扩展性和容错性。
冗余备份:通过使用多可用区、多机房、多地域等方式,可以实现数据和服务的冗余备份,以防止单点故障或灾难恢复,这在遇到不可抗因素时(区域网络断网、地震)极其重要。
服务降级:通过使用熔断器、限流器、降级器等技术,可以实现服务的降级处理,以保证核心功能的正常运行,避免雪崩效应。
监控报警:通过使用监控系统(如Prometheus)和报警系统(如Alertmanager)对系统的各个指标进行实时监控和异常报警,可以及时发现和解决问题,提高系统的稳定性。
以上只是传统高可用架构的优势,但是现在的高可用架构基本都会上云,云上高可用架构比之传统高可用就又多了几个优势。
云上高可用架构
动态扩容
动态扩容是云厂商的一个重磅功能,它可以让你在极短的时间内快速部署大量应用以应对用户的快速增长。
假如你是一个小镇青年,花费三年心血推出一款产品,一经上市便被用户自发传播,用户量呈指数级上升,或许再过不久你即将走上人生巅峰,但是因为用户量的激增你的服务器资源与数据库资源天天告警,因为资源的不足,用户使用起来也越来越卡,竞品公司看到你的产品这么火,马上抄了一个,已经投入了市场开始推广。
此时如果你的应用上云了,那么你可以:登录你的云服务账号,挥动鼠标点击几下扩容,将服务器和数据库资源瞬间扩大 N 倍,保证用户的体验,避免用户流失。
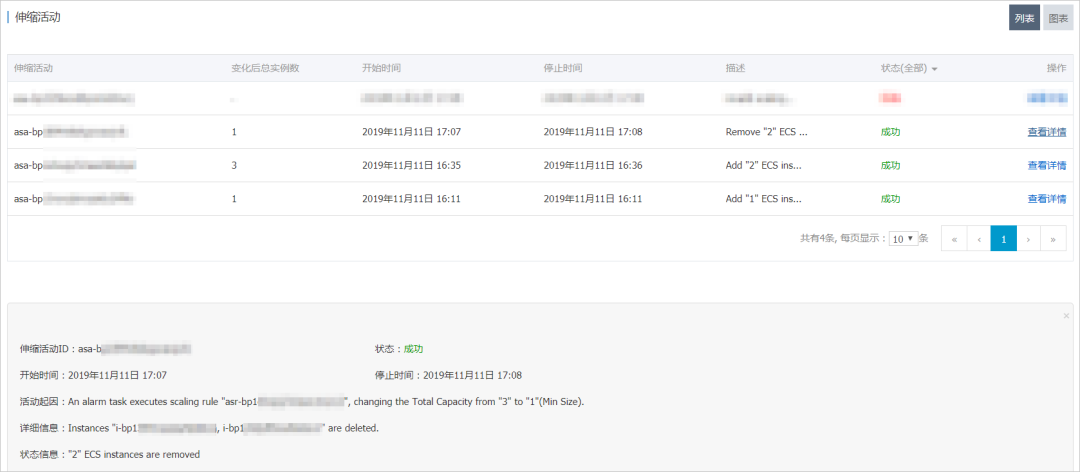
img
甚至你都不需要自己去处理扩容问题,如上图所示,现在的云厂商都支持预设扩容规则,当服务器压力达到你设置的一定条件后可以自行进行扩容,这样你就不必在深夜被服务器报警吵醒。
此时如果你的应用没上云,那么你可以:赶紧买一台高性能服务器并且搭建环境,然后把应用在新的服务器上也部署一份,并且发布到测试环境开始调试,最后提心吊胆发布上线,这么一折腾可能半个月就过去了,用户也被竞品吸引走了,走上人生巅峰的梦想也破灭了。
数据安全
除了动态扩容之外,云服务厂商的数据安全也普遍更靠谱一些,云厂商不光采用最顶级的硬件,还采用一套复杂的软件系统来为数据提供:快照、备份和加密的功能。
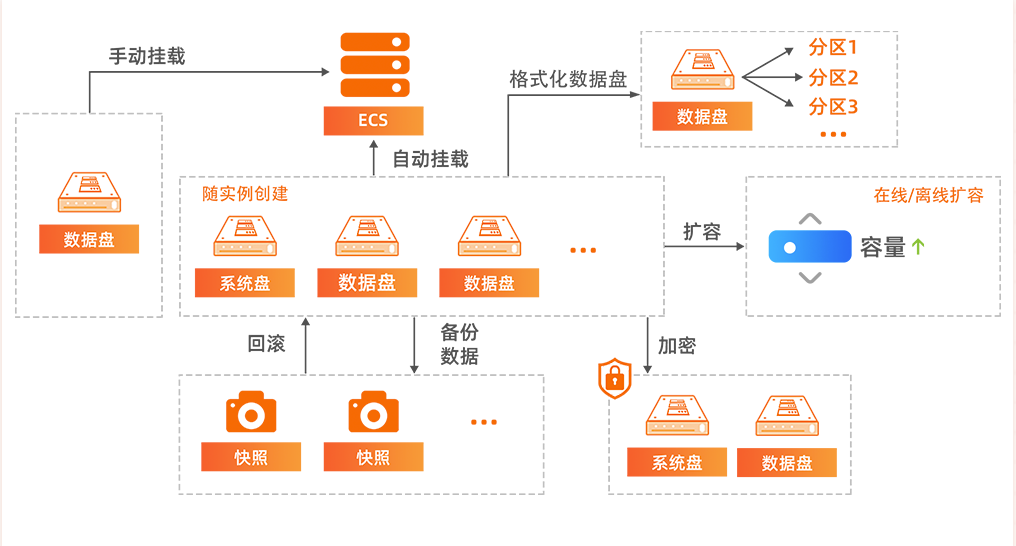
img
有了云服务厂商给的这套数据安全基础之后,本来需要自己操心的数据安全性则完全可以放给云服务厂商来处理了,专注于业务。
便利性
便利性可以指很多方面,其中最大的便利性当属空间方面的便利性,比如当我们要做异地多活的时候,往往需要多地、多机房进行部署应用。
如果你处在特殊行业,国家明确规定相关行业要每年至少进行一次容灾演练,对于这种行业的容灾架构来说,异地多活几乎是或不可缺的。
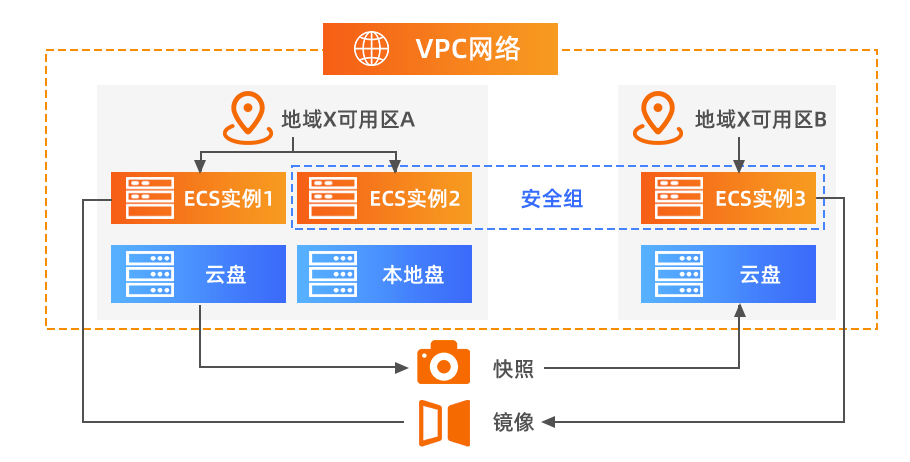
img
如果你没上云,那每次开辟一个新机房都要派一批人去另一个城市租用别人的机房,然后再重新搭建一套与现有的机房相兼容的生产环境,并且还要提心吊胆的进行大量测试才能投入使用。
而且现在出海是很多企业尝试的一个方向,出海应用则不可能将服务器部署在国内,为了速度考量往往都是部署在当地的机房,这时候云厂商的便利性就又体现出来了,在全球的特大城市都有机房存在,无论你想在哪部署你的应用,只要在电脑上就能操作完成。
稳定性
说到底,稳定性才是云厂商的最大优势,云厂商一般提供存储、数据库、计算和网络这些基础设施,由于云厂商具有大量的用户,大量的应用部署在云上, 所以他们对于这些基础设施本身就有一套高可用的架构在支撑,而且这些基础设施在大量用户的考验之下也逐渐坚如磐石。
像做应用常用的两个组件:存储中心和数据库,如果你自己搭建往往需要自己再给他们做一套高可用方案,毕竟这两个部分可谓说是系统的基石存在,如果你直接使用云服务厂商的这些设施,不光实现了稳定性还节省了大量的成本。
云上高可用,就万无一失了吗
虽然云上高可用,已经对我们的应用做了很多的保护措施,但是作为使用者来说,你仍然需要在设计高可用架构的时候遵循一些原则,遵循以下这些原则可以让你的应用更健壮,抗风险能力更加强。
在设计高可用架构时,需要遵循以下原则:
分布式:采用分布式系统架构可以将负载分散到多个服务器上,提高系统的容错性和可用性,比如你有一个订单服务集群,那么你可以把这个集群分布在不同的服务器上,而非同一台服务器。分布式架构不单指将应用分开部署,还有使用的一些基础设施比如数据库、缓存中间件也尽量使用分布式组件,利于日后扩展。
多活:多活架构意味着系统中有多个独立的节点,每个节点都可以处理请求。这种架构可以减少单点故障的影响,提高系统的可用性。比如你有一个订单服务的集群,在部署的时候尽量在多地部署,比如北京、上海、成都各一台,这样可以在某个区域的所有服务器都出现问题的时候利用其他区域的服务器继续提供服务。
自动化运维:采用自动化运维工具可以帮助系统自动检测和恢复故障,降低故障处理时间,提高系统的可用性。比如发版时可以进行灰度发版,发版出现问题时可以通过版本管理快速回滚到上一个版本等。
弱依赖:弱依赖原则是指服务模块之间应该尽可能地减少依赖关系,使得系统中的各个模块能够独立地进行开发、测试、部署和维护。这样可以提高系统的可维护性和可扩展性,降低模块之间的耦合度,减少系统中出现的意外行为和故障。比如我们有购物车和订单两个模块,只要不是强依赖,购物车模块出现问题是不会影响到订单服务的,继而也不会影响用户的下单操作。
自我保护:在软件设计中,系统应该具备自我保护的能力,能够自动检测和修复错误,从而避免系统因错误而导致的崩溃或无响应情况。同时应用在极端情况下应该能自我降级,通过返回大量的降级响应而避免上层应用被拖垮。
以上五条,就是我在多年开发经验中总结出的高可用设计中需要遵循的一些原则,大家可以将其实际应用到工作中去,相信一定会取得不错的效果。
如果你已经做好了云上高可用架构,依然发生了应用崩溃情况,那么你和云服务厂商之间,究竟应该谁来负责呢?
我的应用宕机了,云服务厂商应不应该负责?
对于这个问题,其实业内云厂商有一个通行的安全责任划定表,对用户与云厂商做出了清晰的责任划分:

img
从上图可以看到,云服务厂商主要负责的部分是硬件设施,如果硬件出现了问题导致了客户的应用出现问题,那么云服务厂商是应该承担责任的。
比如在 2022年1月,谷歌云在美国东部地区出现了大规模的网络故障,导致谷歌云上的数千个网站和应用程序无法正常访问。该网络故障是由于谷歌云的网络设备出现了故障所致,导致一些客户的数据流无法正常传输。
为此,谷歌云向受影响的客户提供了一定的赔偿方案,具体赔偿方案包括:为使用受影响的谷歌云服务的客户提供一定比例的服务费用折扣,并在必要时进行赔偿。
所以,即使是云上高可用架构方案,也不可能保证 100% 的可靠性。
不过这种情况在现实生活中也是极少数案例,大部分的事故宕机还是由于网站管理员误操作引起的问题,比如:
2019年11月19日,GitHub 因为一名员工在执行一个数据库清理脚本时不小心删除了一个生产数据库集群的主节点,导致该集群不可用,持续了43分钟。
2019年7月2日,Facebook、Instagram和WhatsApp因为一名员工在配置数据库时误删了一些关键数据,导致这三个平台的服务不可用,持续了约8小时。
2018年7月3日,GitLab 因为一名员工在执行一个数据库迁移任务时误删了一个PostgreSQL数据库中的重要表,导致 GitLab 服务不可用,持续了约30分钟。
这些误操作事故看起来都很好恢复,但是因为没有备份机制,导致事故造成影响的时间比较长,如果它们使用的是云数据库或者具有多活节点,其实都不会发生这么大的影响,最多几分钟服务就恢复了。
毕竟云服务提供商通常拥有完善的数据备份和容灾机制,包括地理上的备份和异地多活架构等,可以有效地应对各种灾害和数据安全风险。
而且云服务提供商通常会提供自动化、智能化的容灾解决方案,能够快速检测和响应各种故障和安全事件,提供快速恢复的服务,保障企业的业务连续性和数据安全。
所以大家在架构设计阶段时,就要时刻考虑我上面所提到的五个原则,一个合格的高级开发人员,应该在开发过程中就预想过各种各样的场景,并对这些场景做出一定的准备工作,这样才能最大程度上保证自己的应用不出问题。
良好的设计原则 + 强大的云上高可用架构与云上运维工具,可以让我们在遇到事故问题时做到游刃有余。
总结
今天主要给大家带来了云上高可用架构的内容,主要带大家详细了解了云上高可用架构的优势以及上云的必要性。
同时上云虽然有诸多般好处,但是也不可能保证 100% 的可靠性,但是虽然上云不能保证 100% 的可靠性,还是有大量大厂、小厂趋之若鹜的进行上云。
他们用实际行动告诉了我们,上云的好处多于坏处,2023 年是中国提振中国经济的一年,如果你心底也在考量要不要上云,我觉得可以先进行一部分业务的搬迁工作,体验一下云计算便利性再说。
毕竟,未来,一定是云计算的时代。
审核编辑 :李倩
-
OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了2024-05-27 47928
-
#chatgpt chatGPT辅助开发第二弹 软件单元代码编写,工作效率大幅提升,代码可用性高#人工智能jf_82140138 2023-03-02
-
【微信精选】很实用!老工程师谈电子物料:别拿一分钱不当回事!2019-09-13 2515
-
连续通断五次的电路2020-06-07 3309
-
Lcd仿真不可用的原因是什么?2022-01-12 1770
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2352
-
存储产业技术创新战略联盟连续五年被评为“高活跃度联盟”2018-07-05 4329
-
解析keepalived+nginx实现高可用方案技术2020-09-30 4740
-
Kafka的概念及Kafka的宕机2021-08-27 3211
-
快讯:脸书一周内第二次宕机 联想集团终止科创板上市2021-10-09 1605
-
探究Kafka宕机引发的高可用问题2021-10-20 2249
-
禾赛科技连续第五次上中国领先汽车科技企业50榜单2022-04-16 3076
-
GaussDB,连续五次No.1!2023-06-05 1368
-
华为云网站高可用解决方案,保障企业业务连续可用,数据更安全2023-07-04 1197
-
OpenAI就ChatGPT宕机事件致歉2024-12-16 1465
全部0条评论

快来发表一下你的评论吧 !
