

 LabVIEW开放神经网络交互工具包【ONNX】,大幅降低人工智能开发门槛,实现飞速推理
LabVIEW开放神经网络交互工具包【ONNX】,大幅降低人工智能开发门槛,实现飞速推理
电子说
描述
前言
前面给大家介绍了自己开发的LabVIEW ai视觉工具包,后来发现有一些onnx模型无法使用opencv dnn加载,且速度也偏慢,所以就有了今天的onnx工具包,如果你想要加载更多模型,追求更高的速度,那可以使用LabVIEW onnx工具包实现模型的推理与加速。
一、工具包内容
这个开放神经网络交互工具包主要优势如下:
- **简单编程:**图形化编程,无需掌握文本编程基础即可完成机器视觉项目;
- **提供多种框架生成的onnx模型导入模块:**包括pytorch、caffe、tensorflow、paddlepaddle等生成的onnx模型;
- 多种高效加速推理接口 :CUDA、TensorRT对模型进行最大化的加速;
- 支持多种硬件加速 :支持Nvidia GPU、Intel、TPU、NPU多种硬件加速
- 提供近百个应用程序范例 :包括物体分类、物体检测、物体测量、图像分割、 人脸识别、自然场景下OCR等多种实用场景
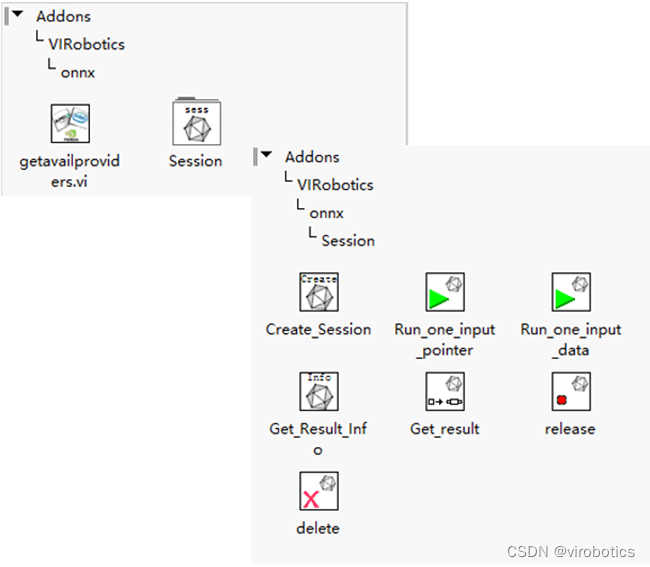
** 工具包中的函数选版如下:**
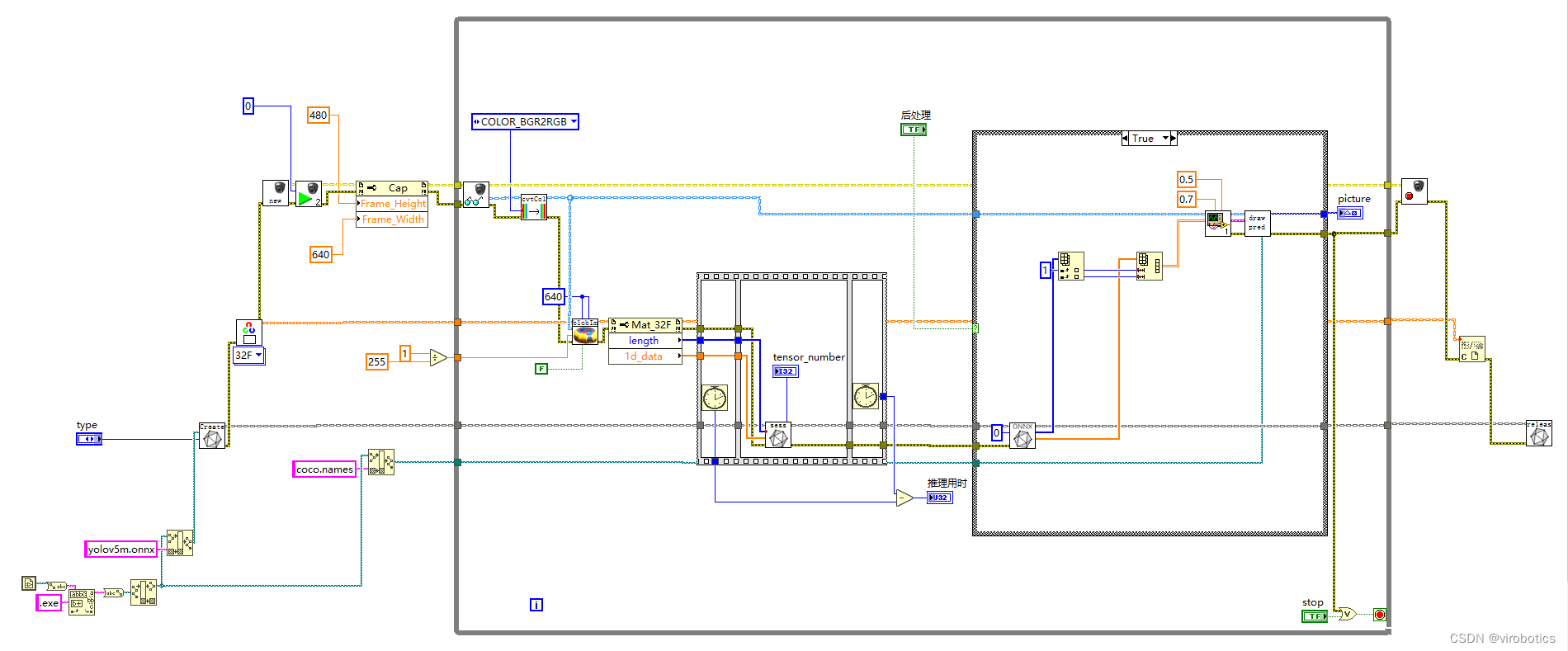
例如,一个摄像头采集并进行yolov5目标检测的范例程序,只需在LabVIEW中编写简单的图形化程序,即可实现。在大量简化编程难度的同时,也保持了c++的高效运行特性。
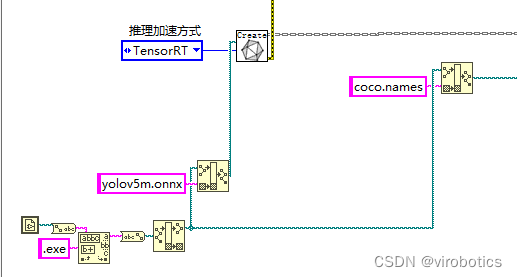
通常我们做项目,在部署过程中想要加速,无非就那么几种办法,如果我们的设备是CPU,那么可以用openvion,如果我们希望能够使用GPU,那么就可以尝试TensorRT了。那么为什么要选择TensorRT呢?因为我们目前主要使用的还是Nvidia的计算设备,TensorRT本身就是Nvidia自家的东西,那么在Nvidia端的话肯定要用Nvidia亲儿子了。
不过因为TensorRT的入门门槛略微有些高,直接劝退了想要入坑的玩家。其中一部分原因是官方文档比较杂乱;另一部分原因就是TensorRT比较底层,需要一点点C++和硬件方面的知识,学习难度会更高一点。我们做的****开放神经网络交互工具包GPU版本 ,直接将TensorRT一起集成到了onnx_session中,可以加载任何onnx模型,可以使用CUDA或者TensorRT加速,实现高效的推理
二、工具包下载链接
https://pan.baidu.com/s/1vwCp1LuKEjYGM4goNYMagw?pwd=yiku
三、工具包安装步骤
详细安装步骤可查看: LabVIEW开放神经网络交互工具包(ONNX)(非NI Vision)下载与安装教程
四、实现物体识别
无论使用何种框架训练物体检测模型,都可以无缝集成到LabVIEW中,并使用工具包提供的CUDA、tensorRT接口实现加速推理,模型包括但不限于:
- yolov5、yolov6、yolov7、pp-yoloe、yolox
- torchvision中的图像分类、目标检测模型等
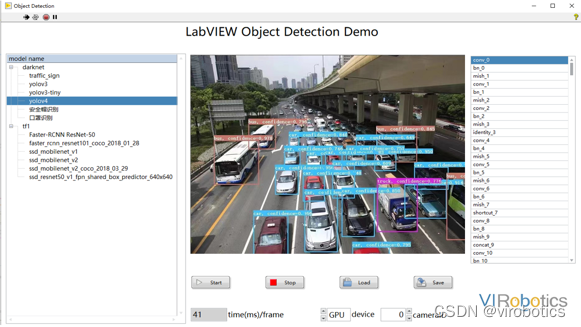
通过算法优化,在LabVIEW中运行模型的速度明显好于python,这对于对性能要求较高的工业现场来说非常友好实用。比如说:工地安全帽检测、物体表面缺陷检测等,如下图进行物体识别,在GPU模式下,无论是运行速度和识别率都可以达到工业级别。
- yolov4实现目标检测:
- 基于onnx,yolov5使用tensorRT实现推理加速:
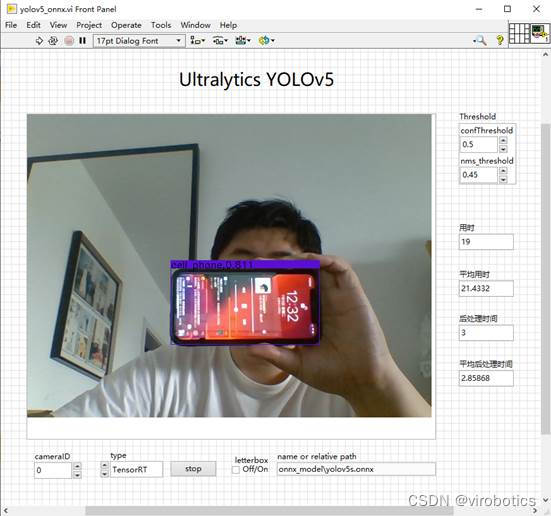
- NI vision采集图像、tensorRT加速实现yolov5目标检测
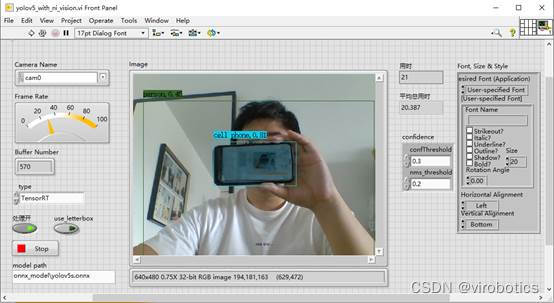
- yolov5实现口罩检测:
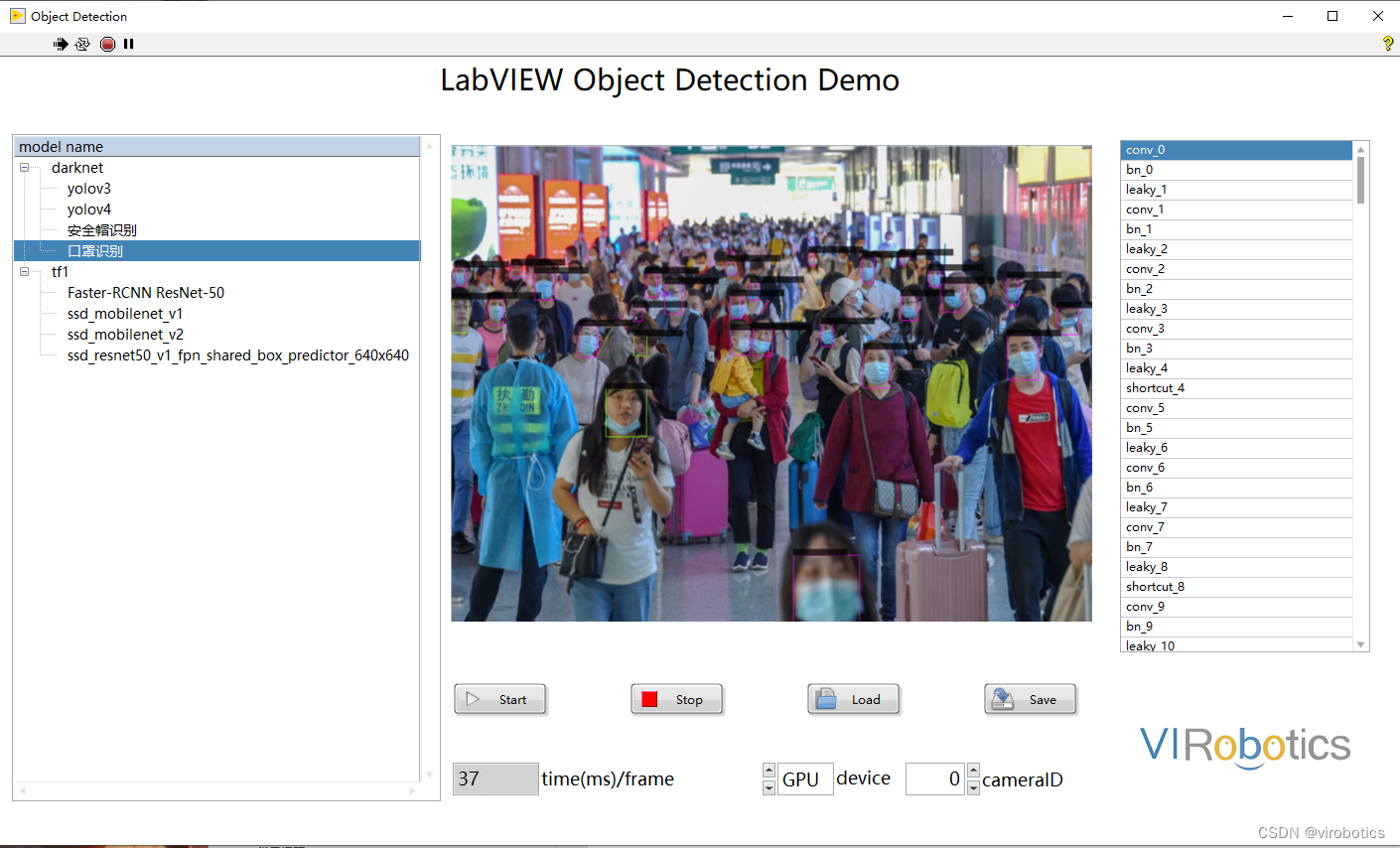
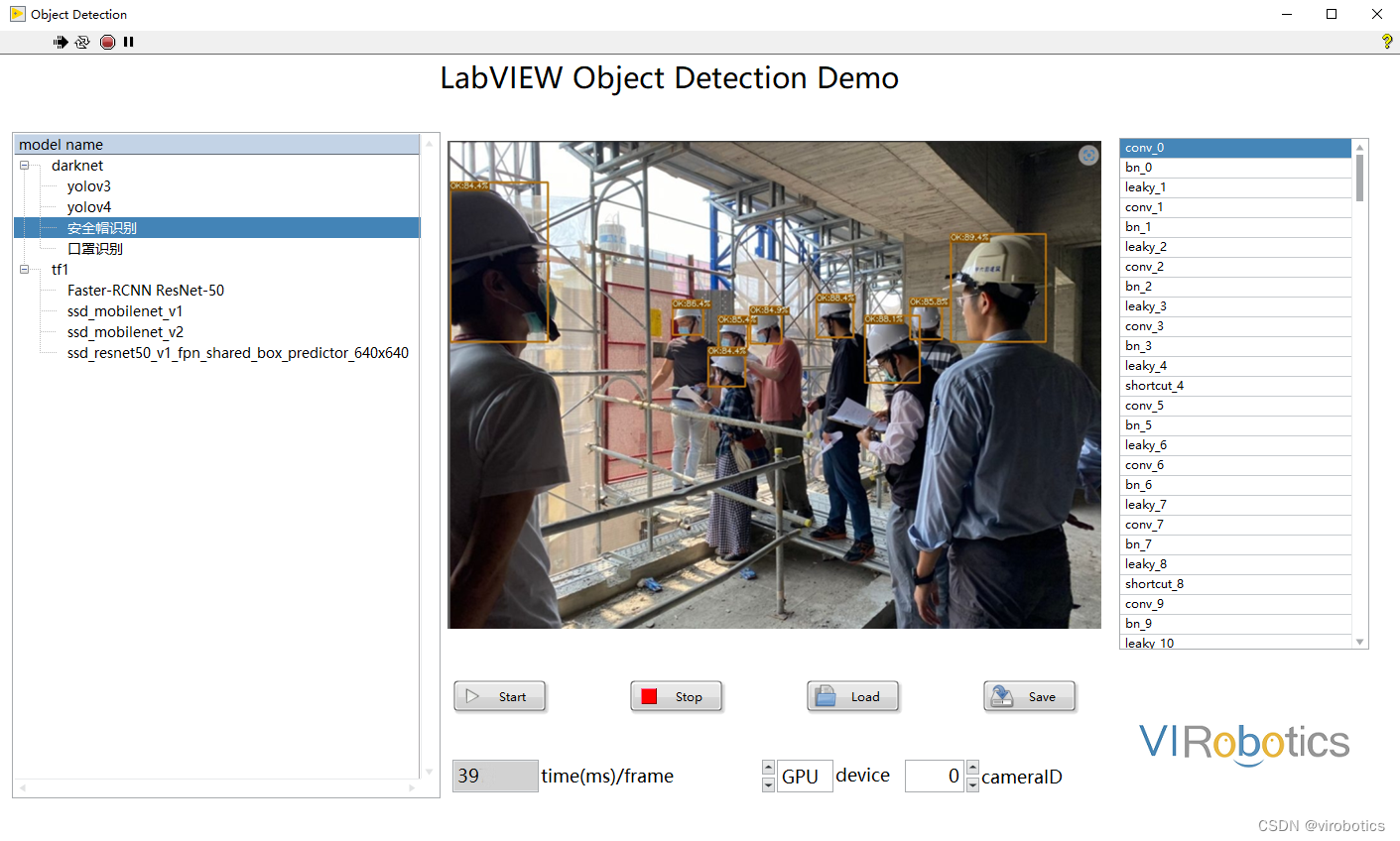
- yolov5实现安全帽检测:
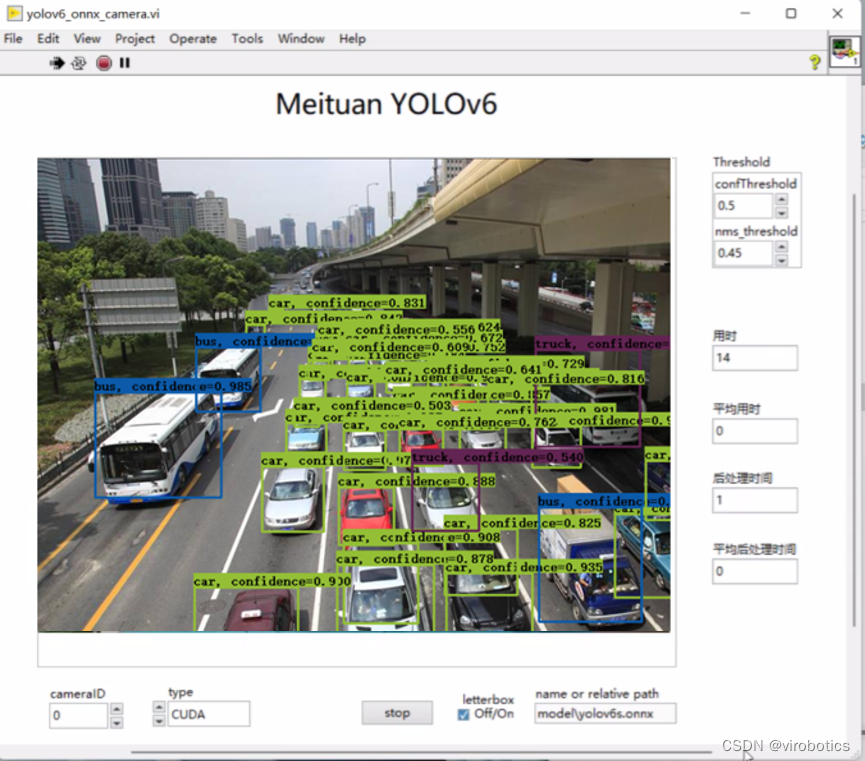
- yolov6实现目标检测:
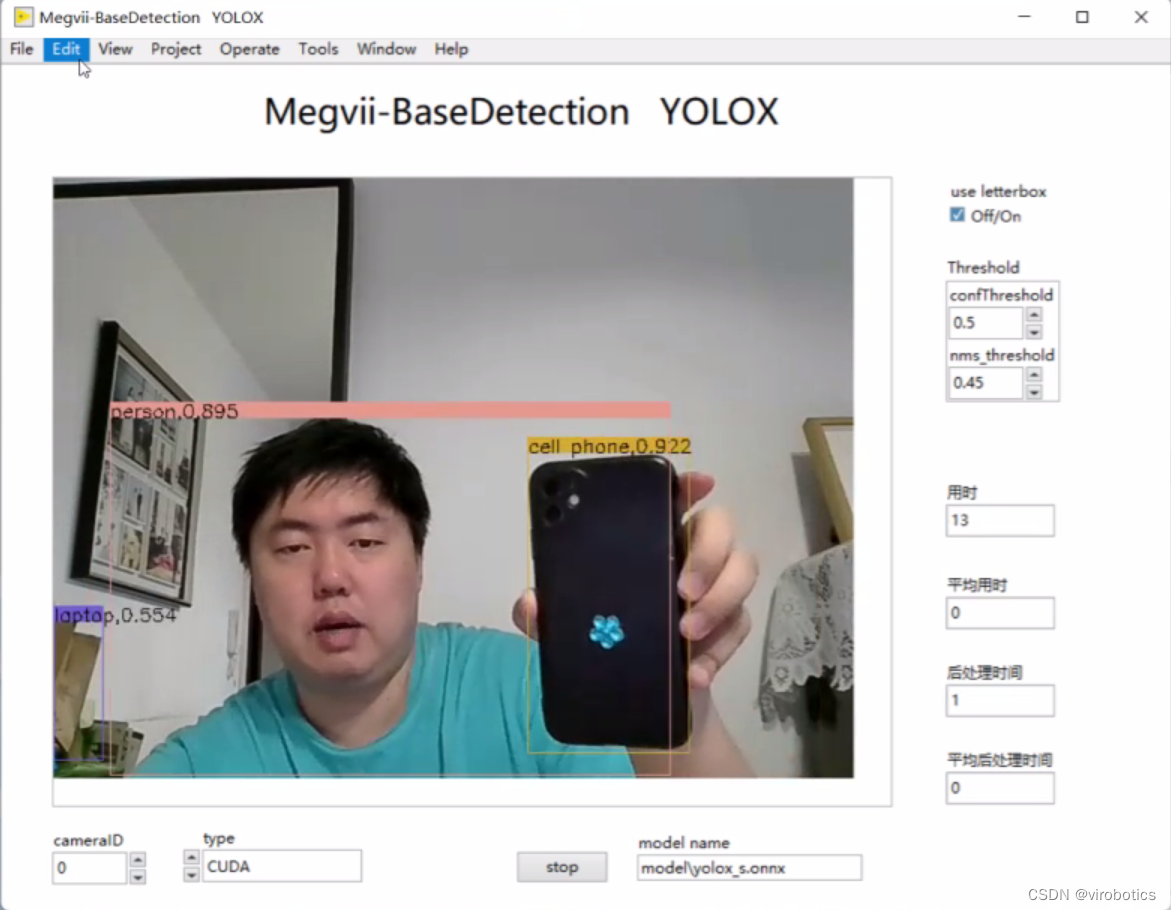
- yolox实现目标检测:
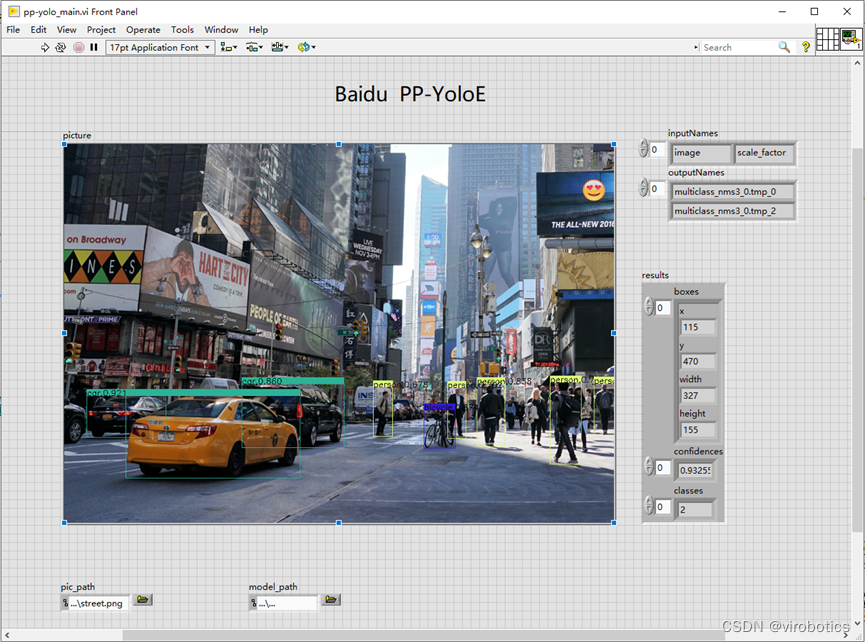
- 百度PP-YOLOE实现目标检测:





五、实现图像分割
图像分割是当今计算机视觉领域的关键问题之一。从宏观上看,图像分割是一项高层次的任务,为实现场景的完整理解铺平了道路。场景理解作为一个核心的计算机视觉问题,其重要性在于越来越多的应用程序通过从图像中推断知识来提供营养。随着深度学习软硬件的加速发展,一些前沿的应用包括自动驾驶汽车、人机交互、医疗影像等,都开始研究并使用图像分割技术。
本次集成的工具包提供了多种图像分割的调用模块,并实现了GPU模式下TensorRT的加速运行。如:
语义分割:Segnet、deeplabv1~deeplabv3、deeplabv3+、u-net等;
实例分割:Mask-RCNN、PANet等
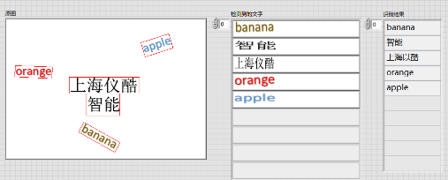
六、自然场景下的文字识别
工具包提供了文本检测定位(DB_TD500_resnet50、EAST)、文本识别的模块(CRNN),用户可以使用该模块实现自然场景下的中英文文字识别
应用:身份证识别、表单识别、包装盒标签检测等

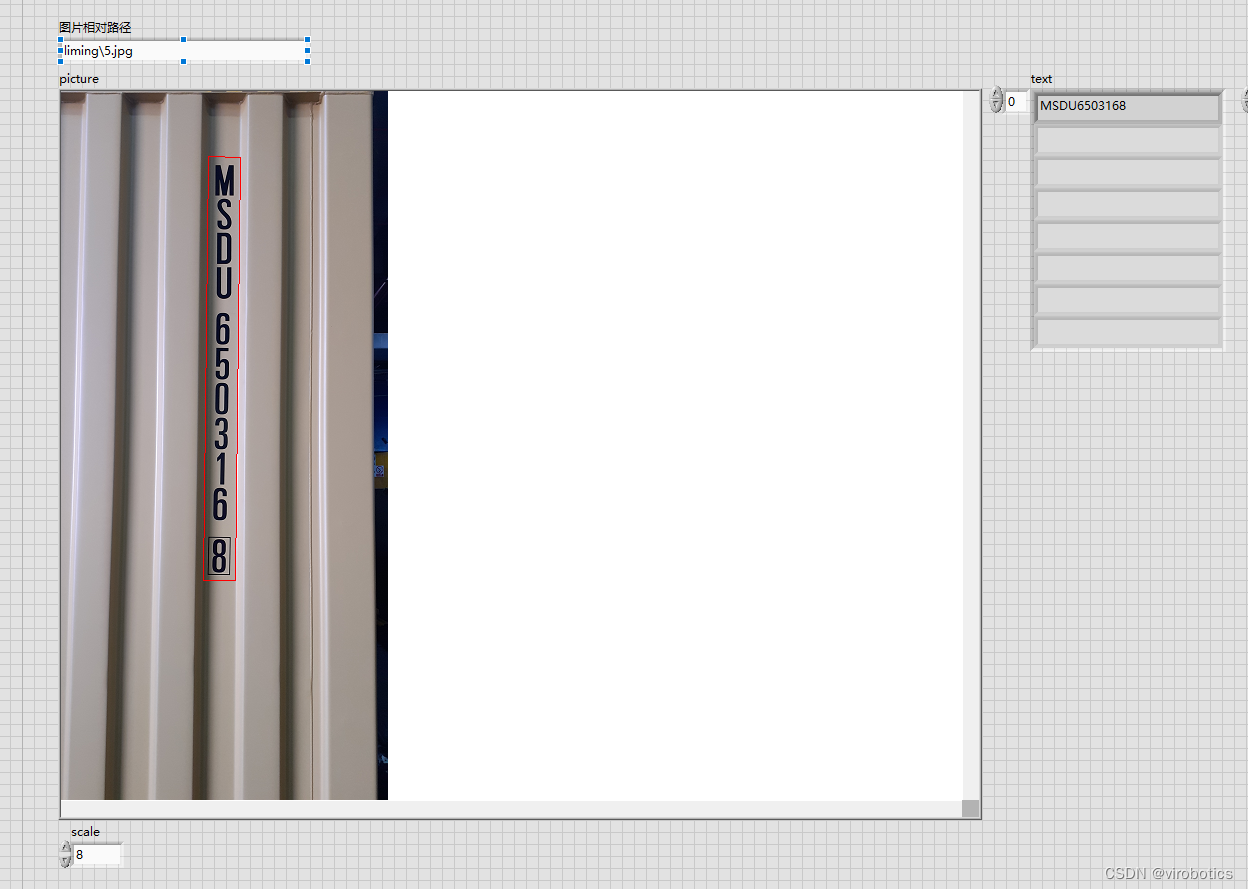
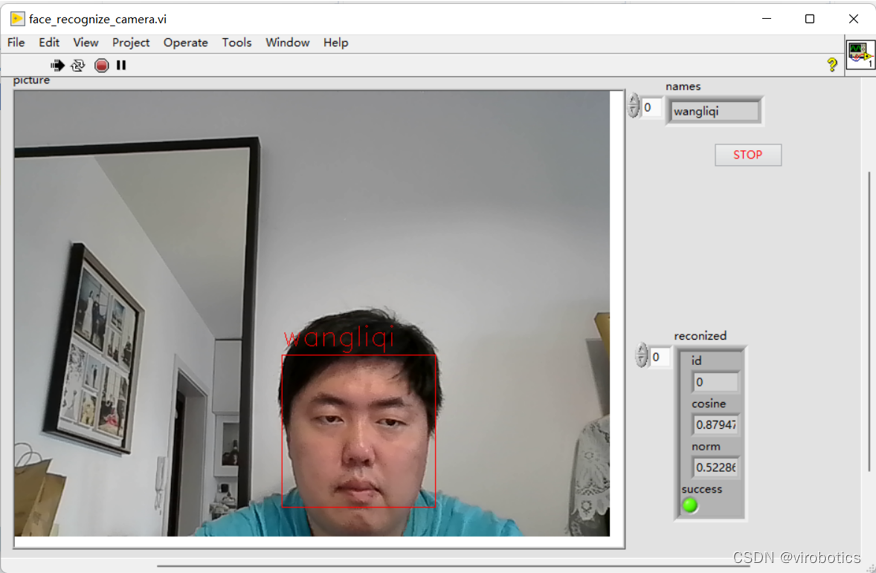
七、人脸检测与识别
八、人体关键点检测
** 人体骨骼关键点对于描述人体姿态,预测人体行为至关重要。因此人体骨骼关键点检测是诸多计算机视觉任务的基础,例如动作分类,异常行为检测,以及自动驾驶等等。近年来,随着深度学习技术的发展,人体骨骼关键点检测效果不断提升,已经开始广泛应用于计算机视觉的相关领域。**
** 本次集成的工具包提供了关键点检测的调用模块,并实现了GPU模式下TensorRT的加速运行。**

总结
工具包的具体使用可以关注博主的后续博客,如果有问题可以在评论区里讨论,提问前请先点赞支持一下博主哦
如果文章对你有帮助,欢迎关注、点赞、收藏 .
审核编辑 黄宇
-
手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别2023-03-20 4410
-
仪酷LabVIEW AI视觉工具包及开放神经网络交互工具包常见问题解答2023-07-24 2872
-
labview BP神经网络的实现2017-02-22 14502
-
2019年5月“人工智能”主题精选资料合集2019-06-21 6180
-
STM32Cube.AI工具包使用初探2022-02-22 1208
-
隐藏技术: 一种基于前沿神经网络理论的新型人工智能处理器2022-03-17 16040
-
AI人工智能计算棒RK1808 Al Compute Stick介绍2022-08-15 2663
-
不可错过!人工神经网络算法、PID算法、Python人工智能学习等资料包分享(附源代码)2023-09-13 4118
-
联发科技已加入“开放神经网络交换”项目 人工智能的新平台2018-07-17 1137
-
揭秘人工智能神经网络为何无法实现人类的推理或产生意识2018-05-14 7856
-
学习关于ST推出的STM32 Cube.AI人工智能神经网络开发工具包2020-03-04 5298
-
Microchip推出软件开发工具包和神经网络IP2020-06-03 3601
-
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛2023-02-20 2815
-
使用LabVIEW人工智能视觉工具包快速实现传统Opencv算子的调用源码2023-09-28 762
-
神经网络和人工智能的关系是什么2024-07-03 3174
全部0条评论

快来发表一下你的评论吧 !
