

MapReduce和Spark概要介绍
电子说
描述
一、MapReduce
(1)MapReduce概要介绍
MapReduce是一种编程模型,可用于大规模数据集(数据量大于1TB的数据集)的并行运算(根据百度百科:并行运算是一种一次可执行多个指令的算法,可提高计算速度)。MapReduce可使程序的并行运算更加简单。
Map(映射)是于各个节点对本地数据的预处理操作。 Reduce(归约)是将Map预处理操作后的数据汇总。Reduce可使编程人员不必关心如何实现分布式并行程序,基于Reduce,编程人员可只关注业务数据处理。
(2)处理模型
MapReduce框架负责处理并行计算中的复杂问题,包括:分布式存储、作业调度、负载均衡、容错处理、网络通信等。
MapReduce的处理流程如图一所示。
首先,数据在数据节点被划分为数据块(个人理解:数据块即图一中的split),MapReduce确定待处理的数据块数量并确定每个记录(个人理解:此处记录可被理解关系数据库的一行数据)在数据块中的位置;
然后,划分后的数据块作为Map的输入;
再然后,Map的输出数据需要经过sort(个人理解:分类)、copy(个人理解:复制)、merge(个人理解:合并)操作成为Reduce的输入,Reduce的输入数据间没有交集,系统中处于Reduce运行的节点的数量等于merge操作后的数据数量;
最后,输出Reduce运行后的数据。 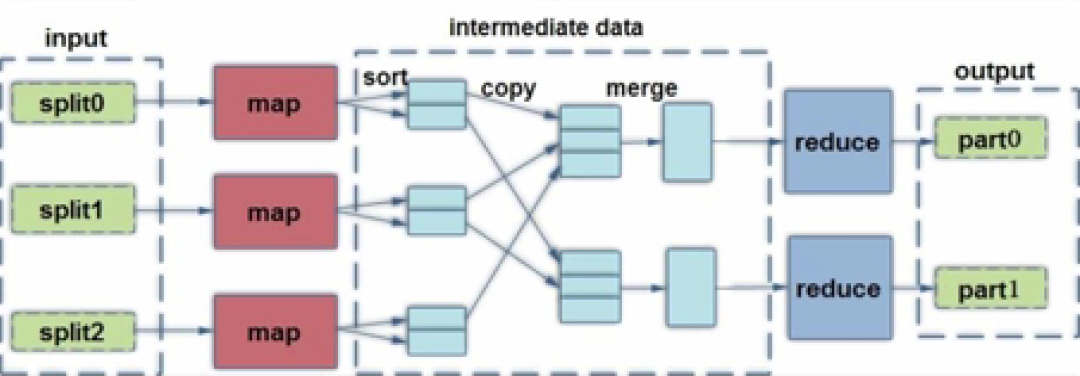
图一,图片来源:学堂在线《大数据导论》
二、Spark
(1)Spark概要介绍
Spark是针对大规模数据处理的快速通用引擎,其功能是类似MapReduce的计算引擎。
(2)Spark的特点
1)计算速度快。Spark计算速度是Hadoop计算速度的一百倍。
2)可用性高。Spark可使用Java、Python、R、SQL等编程语言。
3)通用性。Spark由一系列解决处理复杂问题的组件构成,可处理多种类型有关数据库的复杂问题。
4)可运行于多种环境中,运行环境包括Hadoop等。
图片来源:学堂在线《大数据导论》
(3)Spark的体系架构
1)Cluster Manager:Cluster Manager是主节点,控制整个集群,监控 Worker Node。
2)Worker Node:Worker Node是从节点,负责控制计算节点,启动Executor 或者Driver
3)Driver:运行Application(个人理解:此处Application指某一应用)的main()函数
4)Executor:为Application运行Worker Node上的一个进程。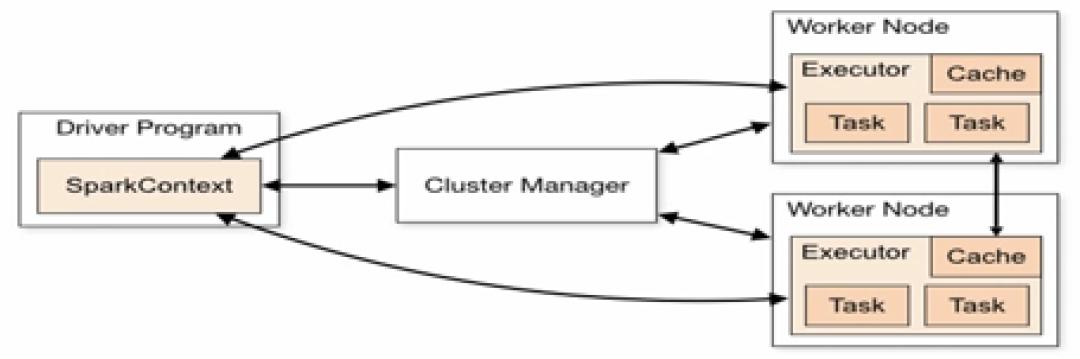
图片来源:学堂在线《大数据导论》
(4)RDD
RDD(Resilient Distributed Dataset)被称为弹性分布式数据集,利用SparkContext实例(根据网络资料理解:每个SparkContext实例是Spark的一个应用)创建的对象均为RDD。RDD是不可变、可分区、其内部元素可并行计算的集合,数据可在RDD中运行RDD的自有函数。
RDD的函数被称为RDD算子,RDD算子分为Transformation和Action两种类型。Transformation具有类似于MapReduce的功能,Action的功能包括:触发RDD计算、统计RDD元素个数等。
RDD的特点包括:自动容错、位置感知性调度、可伸缩性(个人理解:数据量的多少对RDD的运行影响较小)、可在已有RDD的基础上创建新的RDD、延迟执行(延迟执行即Transformation只有在Action被触发后才执行)。
另外,RDD允许用户在执行多个查询时可将工作集缓存在内存中,后续的查询可重用工作集,可提升查询速度。
审核编辑:刘清
-
spark为什么比mapreduce快?2024-09-06 1063
-
Spark的两种核心Shuffle详解2022-08-11 3168
-
剖析Spark的两种核心Shuffle2021-10-11 2757
-
Spark SQL的概念及查询方式2021-09-02 5053
-
MapReduce实例开发指南2019-10-08 1272
-
Spark Streaming的DStream介绍2019-04-25 1158
-
hadoop和spark的区别2018-11-30 2977
-
大数据开发之spark应用场景2018-04-10 2696
-
MaxCompute MapReduce2018-01-31 3804
-
MapReduce的数据放置策略2018-01-26 1134
-
mapreduce编程实例2018-01-02 17477
-
基于Spark的ItemBased推荐算法性能优化2017-11-30 618
-
CT107D_单片机综合训练平台概要介绍2015-11-11 2031
-
MapReduce综述2010-09-18 2532
全部0条评论

快来发表一下你的评论吧 !
