

李开复称AI 2.0已至,将筹建新AI公司,中文版ChatGPT热背后的冷思考
描述
电子发烧友网报道(文/吴子鹏)日前,创新工场董事长兼首席执行官、创新工场人工智能工程院院长李开复在朋友圈表示,正在筹组一个全球化公司Project AI 2.0,致力于打造AI 2.0全新平台和AI-first生产力应用。
李开复在国内被称为“创业教父”,这条朋友圈信息表明,他和美团元老王慧文、前京东技术掌门人周伯文等人一样,也加入到了中文版ChatGPT的混战。
李开复和他的AI 2.0
目前,在创新工场官网已经上线“Project AI 2.0”的入口,目前主要在做两方面的工作:其一是寻找AI大模型、NLP、Multi-modality等领域能力的优秀技术人和研究员,和团队相关;其二是寻找具有 AI 2.0 相关技术、场景、算力、投资兴趣的合作方,和合伙人相关。
那么,李开复所谓的AI 2.0到底是什么呢?是不是就单单指中文版ChatGPT。在3月14日的一场分享会上,李开复专门回答过这个问题。
李开复表示,AI 2.0 将会带来平台式的变革,改写用户的入口和界面,诞生全新平台催生新一代 AI 2.0应用的研发和商业化。从他的描述中能够看到,AI 2.0最大的改变应该是多模态,这使得AI 2.0突破了传统AI 1.0的单领域、低纵效等瓶颈。
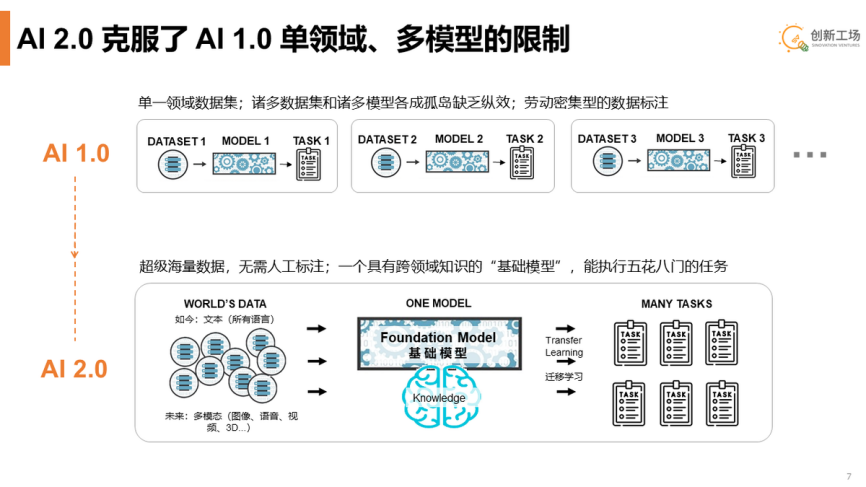
通过上面的示意图可以看到,在AI 1.0阶段,应用主要是基于单一领域的数据集,因此在诸多数据集和诸多模型之间存在很明显的孤岛效应。并且,在这个阶段,需要大量的人工对数据完成标注,以提升训练的效率。
在AI 2.0阶段,大模型会容纳进来更多的数据,李开复将其定义为超级海量数据。当然,为了提升训练的效率,这些数据将不再依靠人工去标注。最终训练得到的模型是一个跨领域知识的“基础模型”,能够执行各种各样的任务。
从李开复的描述来看,当前以ChatGPT为代表的AIGC只是AI 2.0的初期,这一时期的特点是AI从辅助性工具真正开始替代人工,将在写代码、创意和编辑等领域最先开始。然后随着大模型的发展,AI 2.0不会只停留在生成式AI的阶段,将逐渐演化出预测、决策、探索等更高级别的认知智能。因此,AI 2.0囊括的远景要远远超过以ChatGPT为代表的AIGC,绝不是单纯打造一个ChatGPT中文版那么简单。
所以说,AIGC只是AI 2.0的开端。
从李开复的言论可以看出,他对AI 2.0工作的开展非常重视,将亲自带队。创新工场方面表示,已有多位具有全球大厂带领大型团队的技术管理人才,确认了加入意向。李开复讲到,创新工场主要关注三大方向:AI 2.0智能应用、AI 2.0平台、AI基础设施。其中,AI 2.0应用将会迎来遍地开花的阶段,包括各行各业的垂类AI助理、元宇宙应用等之前做不出的应用都会出现。
李开复认为,AI 2.0将分为三个阶段来逐步释放生产力。第一阶段是顺承AI 1.0的模式——人机协同,不过和过往逐字输入而得到大量泛泛的答案不同,AI 2.0将使得文档能够通过用户的描述而精准的输出。不过,这一阶段依然需要人工的协助,以校对AI输出的内容是否准确。在第一阶段,搜索引擎的改变是最直接的,所有用户界面都将被重塑。
第二阶段是局部自动的阶段,这一时期AI将在容错率高的领域独自完成工作,而无需人工的介入,进而显著提升工作效率,比较显著的代表领域是广告、游戏和电子商务等。
第三阶段则是全自动化阶段,完全不再需要人工的介入。这一阶段最典型的特征是,AI将被应用于不容出错的领域中,比如医疗、金融等。
除了自己研究之外,李开复还在朋友圈提到,“我们也积极寻找AI 2.0技术和应用相关的投资机会,加速打造AI 2.0的全新创业生态,对于AI 2.0的未来,我们具有更多更大的想象。 ”
AI 2.0的几道门槛
综上所述,很显然李开复看到的AI 2.0是以ChatGPT中文版为起点,最终实现的是AI对各行各业的渗透。
不过,李开复所提到的AI 2.0在实现的过程中,有几个明显的门槛,并且都极具挑战。
首先是大模型在提示和标注方面的工作,目前这方面的工作很多还是依靠人工。就以提示工作来说,这个岗位除了要求熟悉LLM架构会编程,还要求有探索思维,需要脑洞大开,用合适的描述让AI发挥出最大的潜力,这就说明现阶段的AI还不够聪明;再看一下数据标注,我们都知道光耀的GPT大模型背后隐藏着数据标注的“血汗工厂”,为了训练ChatGPT,OpenAI雇佣了时薪不到2美元的外包肯尼亚劳工,他们所负责的工作就是数据标注,包括数据标注、打标签、分类、调整和处理等。这些需要人工参与的环节随着模型规模的增加将逐渐成为明显的限制,否则那些参数万亿级别的大模型肯定要比GPT强,现实是训练数据更精准的GPT明显更厉害。
其次是法律法规的缺失,GPT-3.5模型已经显示出,如果监管不到位,ChatGPT可能存在对人类的偏见,并表现出攻击性。目前,在GPT-4发布时,微软依然在依赖人工对抗训练来优化这方面,并没有现成的法规来说明需要达到什么程度。如果继续这样野蛮生长,特斯拉CEO埃隆·马斯克、ChatGPT之父Sam Altman等人的担忧也许会成为现实,把人类尤其是分辨力不强的孩童带入到危险的境地,甚至可能产生自主思维消灭人类。因此Sam Altman呼吁,监管机构和社会需要参与这项技术,以防止对人类可能产生的负面影响。
正如中国科学院大学人工智能学院副院长肖俊所言,ChatGPT是人工智能发展过程中的一个正常产物。而我们也都清楚,现阶段以及未来的AI都需要持续依仗大数据。然而,面向公众层面的大数据基本来源于互联网。互联网也被称为数据大染缸,目前还有非常多监管不到位的问题。那么,为了让基于大模型的应用是安全准确的,目前来看李开复所提到的超级海量数据自动筛选和标注在可预见的未来是难以做到的。否则,训练出来的产物将非常不可控。
第三个门槛是国内需要独自面临的问题——国产高端计算芯片的缺失。在李开复的描述中,基础设施建设是AI 2.0环节的重要一环。不过在现阶段,我们见到GPT或者其他相关的大模型实际上都是基于英伟达的GPU在做训练,也就说英伟达产品是当前AIGC发展的动力之源。在这方面,国内硬件差距可能是五年,软硬件的综合差距可能是十年。在全球主要国家和地区都关注AIGC发展时,英伟达GPU随时都可能成为紧俏资源,或者是限制资源,那么我们在基础设施方面的工作到时候只能被迫延后。
此前,有行业人士在接受电子发烧友网采访时表示,目前支撑大模型训练的算力架构从冯诺依曼开始就没有发生过改变,计算、传输和存储是三大核心环节。在这个基本框架下,国内在诸多环节处于落后并受到掣肘。因此,有从业者认为,在AIGC以及大模型狂飙的同时,国内也应该尝试更多算力层面的创新,比如用ASIC+垂直大模型解决具体行业的问题,不再依靠英伟达的通用算力GPU;另外存内计算等创新型计算芯片也值得去关注。
后记
很明显,李开复通过ChatGPT看到了AI 2.0时代更光明的未来,因此独自带队,投身到“Project AI 2.0”项目上,也算是加入到了中文版ChatGPT的混战。不过,AI 2.0图谋的越大越远,里面出现的问题就会越多,我们产业的薄弱环节也会被放大。如果这些短板不能随着模型和算法一起得到增强,我们的AI 2.0时代很可能就是一个地基不稳的大厦,看着宏伟但经不起风吹雨打。
-
大家都在用什么AI软件?有没有好用的免费的AI软件推荐一下?2025-07-09 6665
-
了解AI人工智能背后的科学?2017-09-25 3801
-
『深思考』打造人工智能机器大脑,让AI更懂你!2018-09-13 5171
-
【AI学习】第 1 篇--活用创新模板学 AI2020-11-02 3192
-
《AI概论:来来来,成为AI的良师益友》高焕堂老师带你学AI2020-11-05 6170
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
AI 人工智能的未来在哪?2023-06-27 4408
-
LED热的冷思考2009-12-20 852
-
李开复:AI创业的十个真相2017-01-12 1335
-
李开复:打破巨头垄断局面的“破局者”也会是这些由小变大的AI公司2018-01-25 3255
-
李开复:AI对人类6大挑战2018-01-28 1650
-
中文版ChatGPT:开启AI技术新时代2023-02-08 3028
-
ChatGPT背后的大模型技术2023-05-29 2835
-
ChatGPT背后的AI背景、技术门道和商业应用2024-10-18 24749
-
AI先锋对话:DeepSeek爆火背后,战略破局的新思考2025-02-27 1242
全部0条评论

快来发表一下你的评论吧 !
