

 手把手教你使用LabVIEW实现Mask R-CNN图像实例分割(含源码)
手把手教你使用LabVIEW实现Mask R-CNN图像实例分割(含源码)
描述
前言
前面给大家介绍了使用LabVIEW工具包实现图像分类,目标检测,今天我们来看一下如何使用LabVIEW实现Mask R-CNN图像实例分割。
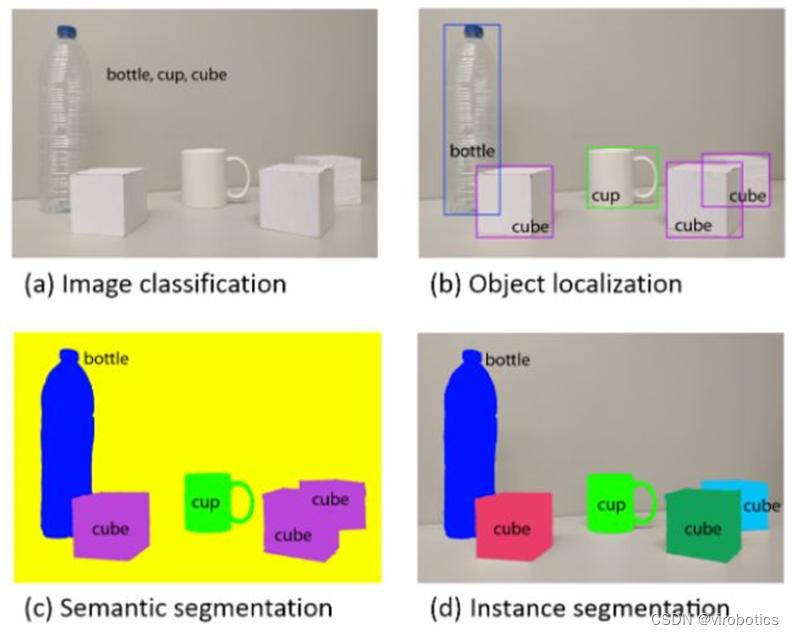
一、什么是图像实例分割?
图像实例分割(Instance Segmentation)是在语义检测(Semantic Segmentation)的基础上进一步细化,分离对象的前景与背景,实现像素级别的对象分离。并且图像的语义分割与图像的实例分割是两个不同的概念,语义分割仅仅会区别分割出不同类别的物体,而实例分割则会进一步的分割出同一个类中的不同实例的物体。
计算机视觉中常见的一些任务(分类,检测,语义分割,实例分割)
二、什么是Mask R-CNN

Mask R-CNN是一个实例分割(Instance segmentation)算法,可以用来做“目标检测”、“目标实例分割”、“目标关键点检测”。 Mask R-CNN算法步骤:
- 首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 对这个feature map中的每一点设定预定的ROI,从而获得多个候选ROI;
- 将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI
- 接着,对这些剩下的ROI进行ROIAlign操作(即先将原图和feature map的pixel对应起来,然后
- feature map和固定的feature对应起来);
- **最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作) **
三、LabVIEW调用Mask R-CNN图像实例分割模型
1、Mask R-CNN模型获取及转换
- 安装pytorch和torchvision
- 获取torchvision中的模型(我们获取预训练好的模型):
model = models.detection.maskrcnn_resnet50_fpn(pretrained=True)
- 转onnx
def get_pytorch_onnx_model(original_model):
model=original_model
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "maskrcnn_resnet50.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
model.eval()
x = torch.rand(1, 3, 640, 640)
# model export into ONNX format
torch.onnx.export(
original_model,
x,
full_model_path,
input_names=["input"],
output_names=["boxes", "labels", "scores", "masks"],
dynamic_axes={"input": [0, 1, 2, 3],"boxes": [0, 1],"labels": [0],"scores": [0],"masks": [0, 1, 2, 3]},
verbose=True,opset_version=11
)
return full_model_path
完整获取及模型转换python代码如下:
import os
import torch
import torch.onnx
from torch.autograd import Variable
from torchvision import models
dirname, filename = os.path.split(os.path.abspath(__file__))
print(dirname)
def get_pytorch_onnx_model(original_model):
model=original_model
# define the directory for further converted model save
onnx_model_path = dirname
# define the name of further converted model
onnx_model_name = "maskrcnn_resnet50.onnx"
# create directory for further converted model
os.makedirs(onnx_model_path, exist_ok=True)
# get full path to the converted model
full_model_path = os.path.join(onnx_model_path, onnx_model_name)
model.eval()
x = torch.rand(1, 3, 640, 640)
# model export into ONNX format
torch.onnx.export(
original_model,
x,
full_model_path,
input_names=["input"],
output_names=["boxes", "labels", "scores", "masks"],
dynamic_axes={"input": [0, 1, 2, 3],"boxes": [0, 1],"labels": [0],"scores": [0],"masks": [0, 1, 2, 3]},
verbose=True,opset_version=11
)
return full_model_path
model = models.detection.maskrcnn_resnet50_fpn(pretrained=True)
print(get_pytorch_onnx_model(model))
2、LabVIEW调用 Mask R-CNN (mask rcnn.vi)
注意:Mask R-CNN模型是没办法使用OpenCV dnn去加载的,因为有些算子不支持,所以我们主要使用LabVIEW开放神经网络交互工具包(ONNX)来加载推理模型。
-
onnxruntime调用onnx模型并选择加速方式

-
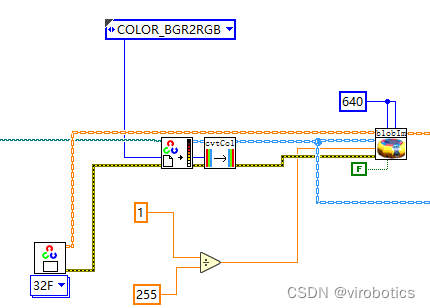
**图像预处理 **
-
**执行推理 **
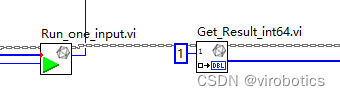
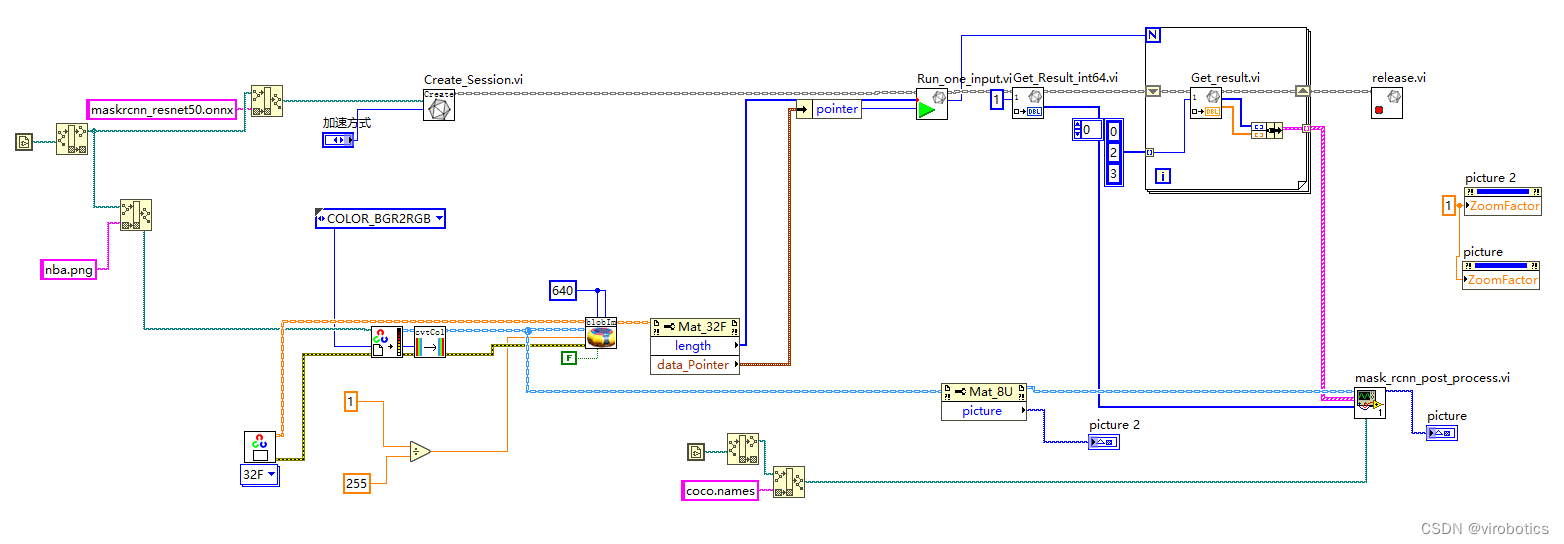
我们使用的模型是:maskrcnn_resnet50_fpn,其输出有四层,分别为boxes,labels,scores,masks,数据类型如下:

** 可以看到,labels的类型为INT64,所以我们的源码中需要“Get_Rresult_int64.vi,index为1,因为labels为第二层,即下标为1;**
另外三个输出我们都可以使用float32来获取了,masks虽然数据类型是uint8,但在实操过程中发现,它其实做过归一化处理了,也可以使用float32.
-
后处理并实现实例分割
因为后处理内容较多,所以直接封装为了一个子VI, mask_rcnn_post_process.vi,源码如下:
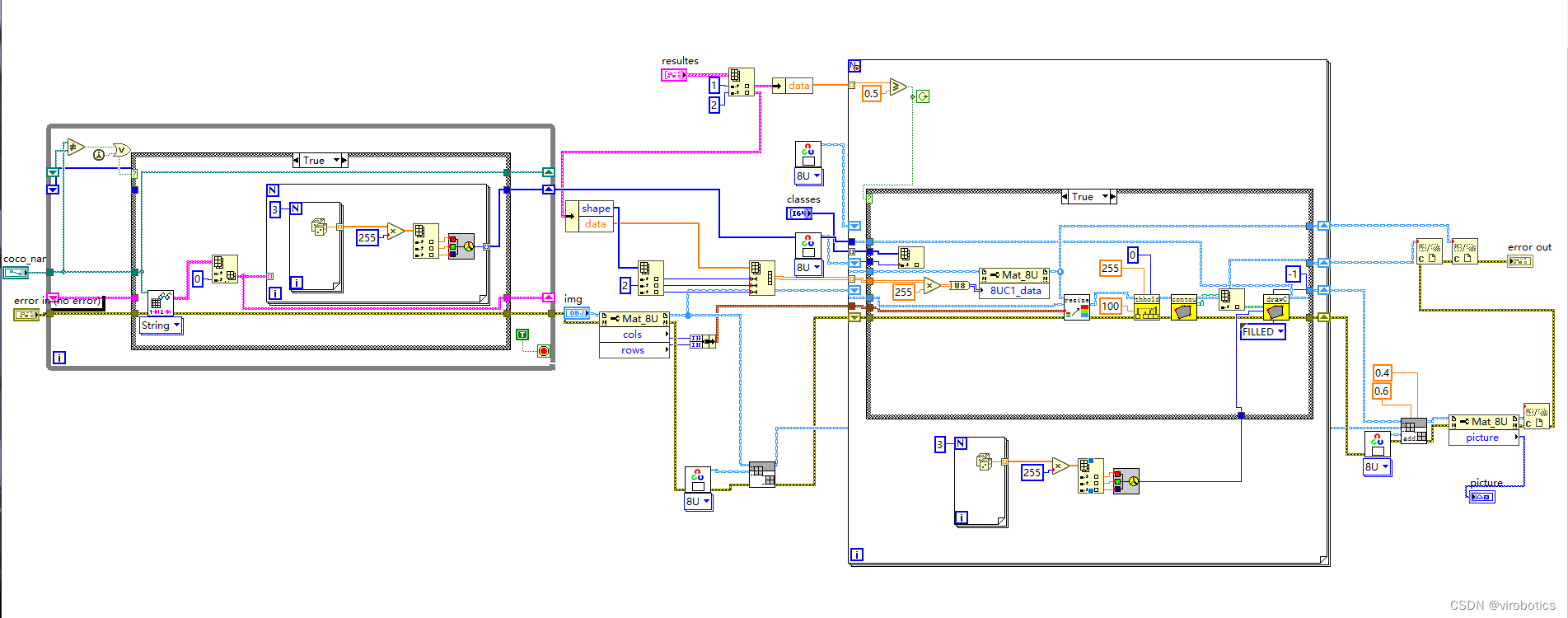
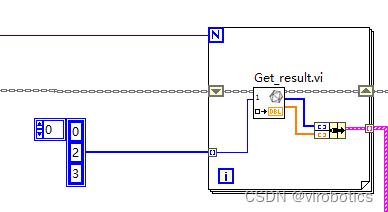
** 整体的程序框架如下:**
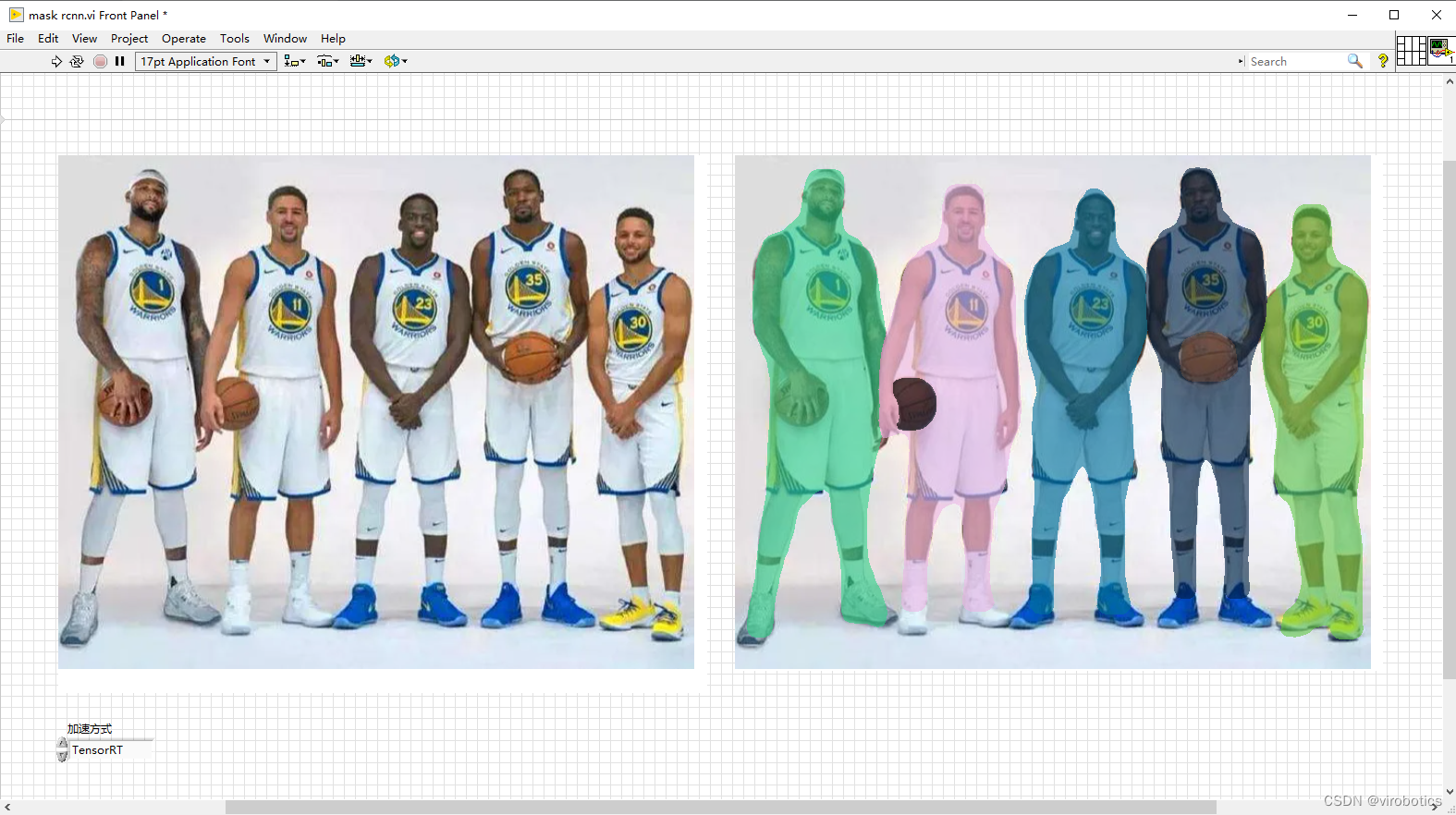
实例分割结果如下,我们会发现这个模型跑起来,他花的时间比之前就更长了。因为他不但要获取每一个对象的区域,还要也要把这个区域的轮廓给框出来,我们可以看到五个人及篮球都框出来了,使用不同的颜色分割出来了。








3、LabVIEW调用 Mask R-CNN 实现实时图像分割(mask rcnn_camera.vi)
整体思想和上面检测图片的实力分割差不多,不过使用了摄像头,并加了一个循环,对每一帧对象进行实力分割,3080系列显卡可选择TensorRT加速推理,分割会更加流畅。我们发现这个模型其实很考验检测数量的,所以如果你只是对人进行分割,那可以选择一个干净一些的背景,整体检测速度就会快很多。


大家可关注微信公众号: VIRobotics ,回复关键字: Mask R-CNN图像实例分割源码 获取本次分享内容的完整项目源码及模型。
四、Mask-RCNN训练自己的数据集(检测行人)
1.准备工作
- 训练需要jupyterlab环境,没有安装的同学需要通过pip install jupyterlab 安装
- **如果无法解决jupyterlab环境 可以使用colab或者kaggle提供的免费gpu环境进行训练 **
- 训练源码:mask-rcnn.ipynb
2.开始训练
-
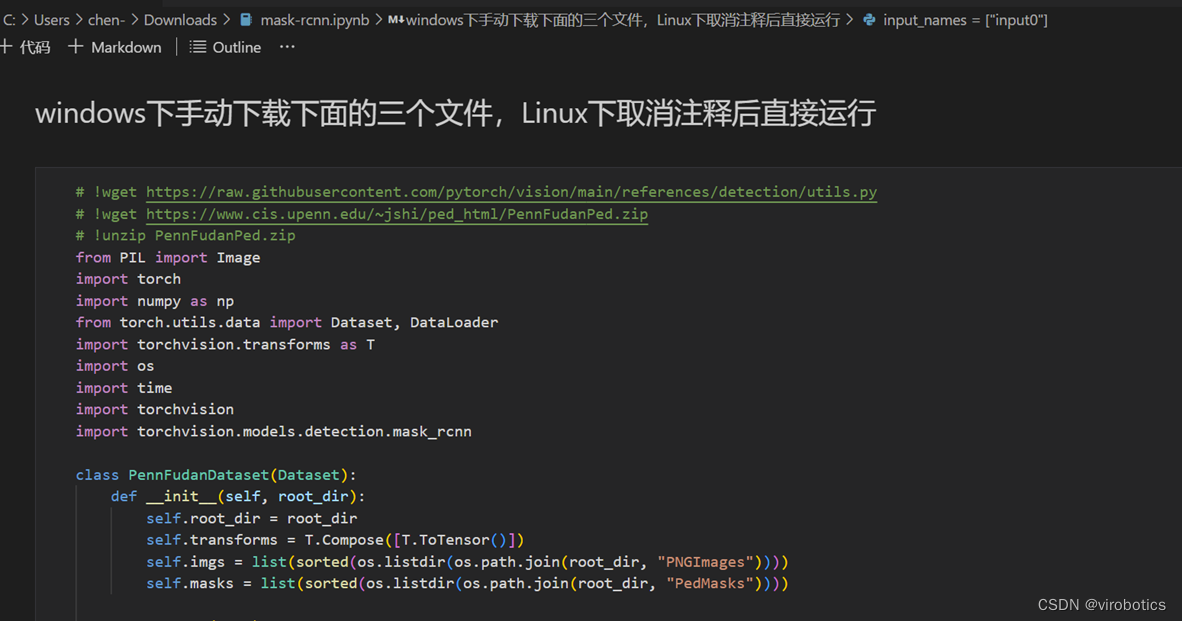
**根据提示运行这段代码,自动或手动下载依赖文件数据集并建立数据集解析类 **
-
定义单轮训练的函数:网络结构直接采用torchvison里现有的,不再重新定义
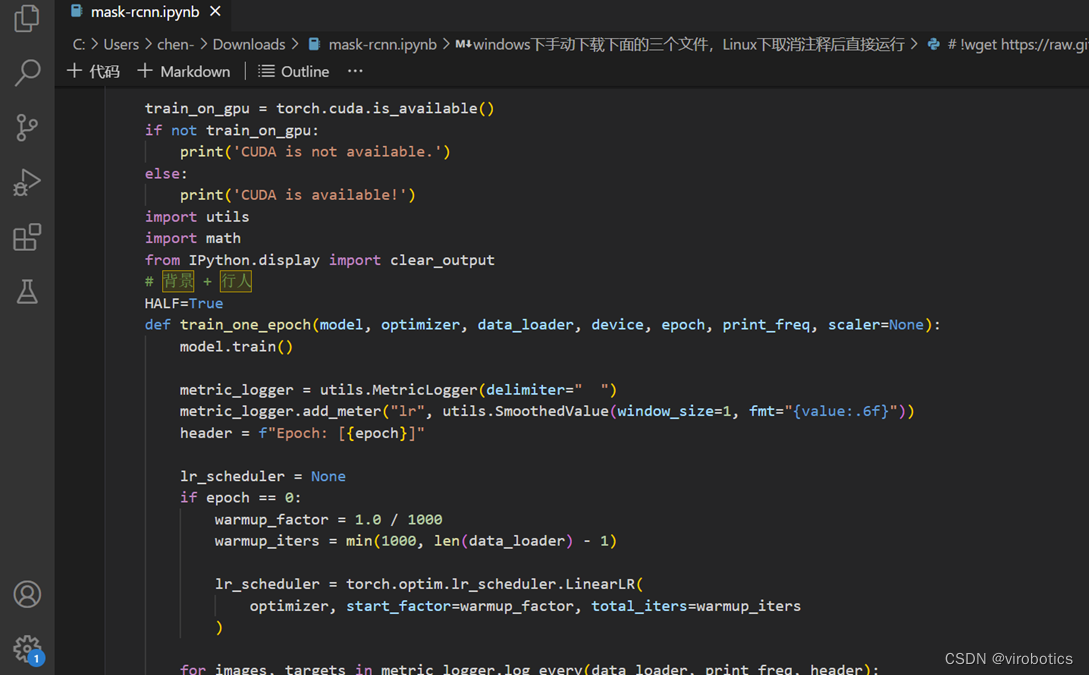
-
出现如下输出表示训练进行中
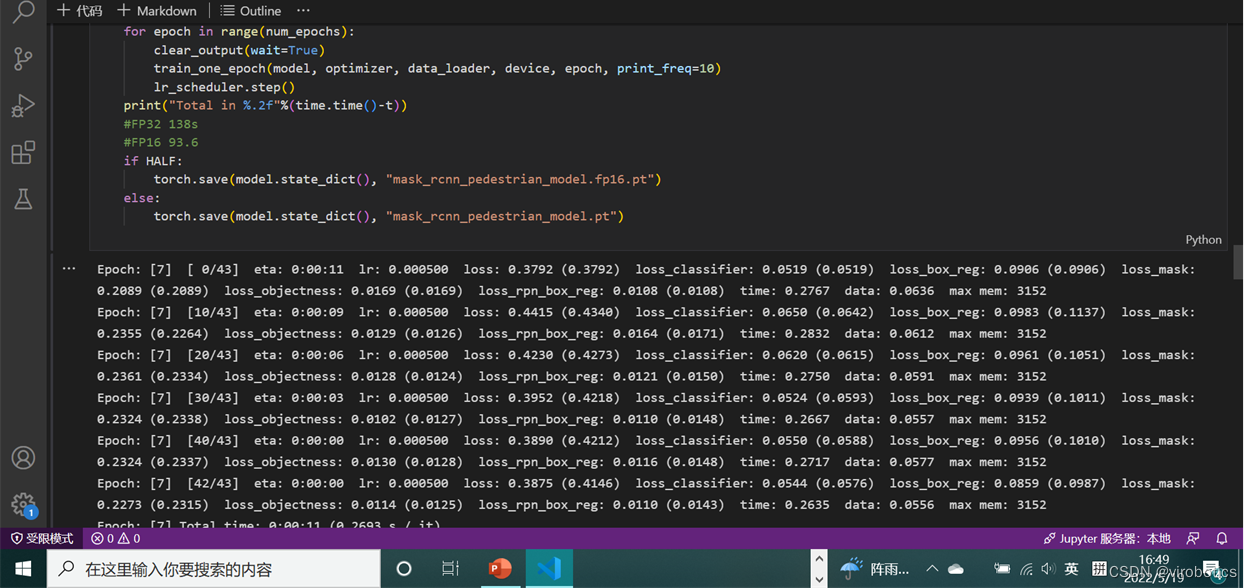
-
**修改这个文件名,改成自己的图片名字,运行看下训练效果 **
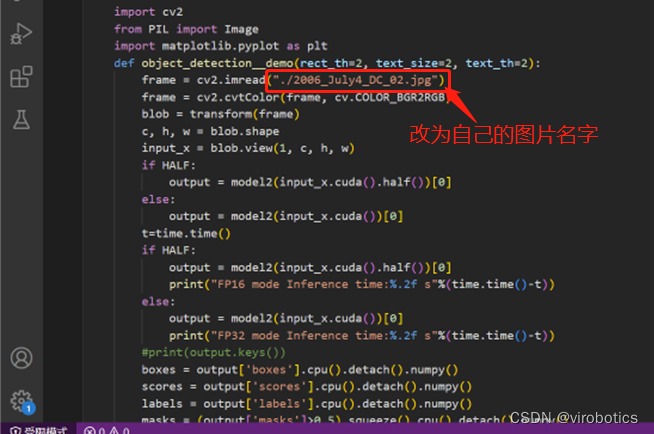




3、训练效果

4、导出ONNX

如果文章对你有帮助,欢迎关注、点赞、收藏
审核编辑 黄宇
-
手把手教你学FPGA仿真2023-10-19 1202
-
用于实例分割的Mask R-CNN框架2022-04-13 4063
-
手把手教你操作Faster R-CNN和Mask R-CNN2019-04-04 14294
-
手把手教你学LabVIEW视觉设计2019-03-06 3655
-
引入Mask R-CNN思想通过语义分割进行任意形状文本检测与识别2018-08-07 15171
-
什么是Mask R-CNN?Mask R-CNN的工作原理2018-07-20 69325
-
手把手教你如何开始DSP编程2018-04-09 1533
-
手把手教你安装Quartus II2016-09-18 1862
-
小草手把手教你LabVIEW仪器控制V1.02016-08-03 1419
-
手把手教你LabVIEW仪器控制2015-12-11 9192
-
【视频汇总】小草大神手把手教你Labview技巧及源代码分享2015-05-26 71026
-
【原创视频】小草手把手教你LabVIEW之VISION图像采集2015-05-01 53378
-
【汇总篇】小草手把手教你 LabVIEW 串口仪器控制2015-02-04 259274
-
美女手把手教你如何装机(中)2010-01-27 1706
全部0条评论

快来发表一下你的评论吧 !
