

一张照片定制自己的3D数字化身?
描述
近日,由微软亚洲研究院提出的 Roll-out Diffusion Network (RODIN) 模型,首次实现了利用生成扩散模型在 3D 训练数据上自动生成 3D 数字化身(Avatar)的功能。仅需一张图片甚至一句文字描述,RODIN 扩散模型就能秒级生成 3D 化身,让低成本定制 3D 头像成为可能,为 3D 内容创作领域打开了更多想象空间。相关论文“RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”已被 CVPR 2023 接收。
创建个性化的用户形象在如今的数字世界中非常普遍,很多 3D 游戏都设有这一功能。然而在创建个人形象的过程中,繁琐的细节调整常常让人又爱又恨,有时候大费周章地选了与自己相似的眼睛、鼻子、发型、眼镜等细节之后,却发现拼接起来与自己仍大相径庭。既然现在的 AI 技术已经可以生成惟妙惟肖的 2D 图像,那么在 3D 世界中,我们是否可以拥有一个“AI 雕塑家”,仅通过一张照片就可以帮我们量身定制自己的 3D 数字化身呢?
微软亚洲研究院新提出的 3D 生成扩散模型 Roll-out Diffusion Network (RODIN)可以轻松做到。让我们先来看看 RODIN 的实力吧!


(a) 给定的照片

(b) 生成的虚拟形象
图1:给定一张照片 ,RODIN 模型即可生成虚拟形象

(a)输入文字“留卷发和大胡子穿着黑色皮夹克的男性”

(b) 输入文字“红色衣着非洲发型的女性”
图2:给定文本描述,RODIN 模型可直接生成虚拟形象
与传统 3D 建模需要投入大量人力成本、制作过程繁琐不同的是,RODIN 以底层思路的创新突破与精巧的模型设计,突破了二次元到三次元的结界,实现了只输入一张图片或一句文字就能在几秒之内生成定制的 3D 数字化身的能力。在此之前,AI 生成技术还仅仅围绕 2D 图像进行创作,RODIN 模型的出现也将极大地推动 AI 在 3D 生成领域的进步。相关论文“RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion”已被 CVPR 2023 接收。
论文链接:
RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
https://arxiv.org/abs/2212.06135
项目页面:
https://3d-avatar-diffusion.microsoft.com

RODIN模型首次将
扩散模型应用于3D训练数据
在 3D 生成领域,尽管此前有不少研究利用 GAN(生成对抗网络)或 VAE(变分自动编码器)技术,从大量 2D 图像训练数据中生成 3D 图像,但结果却不尽如人意,“两面派”、“三头哪吒”等抽象派 3D 图像时有出现。科研人员们认为,造成这种现象的原因在于这些方法存在一个基础的欠定(ill posed)问题,也就是说由于单视角图片存在几何二义性,从仅仅通过大量的 2D 数据很难学到高质量 3D 化身的合理分布,所以才造成了各种不完美的生成结果。
对此,微软亚洲研究院的研究员们转变思路,首次提出 3D Diffusion Model,利用扩散模型的表达能力来建模 3D 内容。这种方法通过多张视角图来训练 3D 模型,消除了歧义性、二义性所带来的“四不象”结果,从而得到一个正确解,创建出更逼真的 3D 形象。
然而,要实现这种方法,还需要克服三个难题:
-
首先,尽管扩散模型此前在 2D 内容生成上取得巨大成功,将其应用在 3D 数据上并没有可参考的实践方法和可遵循的前例。如何将扩散模型用于生成 3D 模型的多视角图,是研究员们找到的关键切入点;
-
其次,机器学习模型的训练需要海量的数据,但一个多视图、一致且多样、高质量和大规模的 3D 图像数据很难获取,还存在隐私和版权等方面的风险。网络公开的 3D 图像又无法保证多视图的一致性,且数据量也不足以支撑 3D 模型的训练;
-
第三,在机器上直接拓展 2D 扩散模型至 3D 生成,所需的内存存储与计算开销几乎无法承受。
多项技术创新让RODIN模型
以低成本生成高质量的3D图像
为了解决上述难题,微软亚洲研究院的研究员们创新地提出了 RODIN 扩散模型,并在实验中取得了优异的效果,超越了现有模型的 SOTA 水平。
RODIN 模型采用神经辐射场(NeRF)方法,并借鉴英伟达的 EG3D 工作,将 3D 空间紧凑地表达为空间三个互相垂直的特征平面(Triplane),并将这些图展开至单个 2D 特征平面中,再执行 3D 感知扩散。具体而言,就是将 3D 空间在横、纵、垂三个正交平面视图上以二维特征展开,这样不仅可以让 RODIN 模型使用高效的 2D 架构进行 3D 感知扩散,将三维图像降维成二维图像也大幅降低了计算复杂度和计算成本。
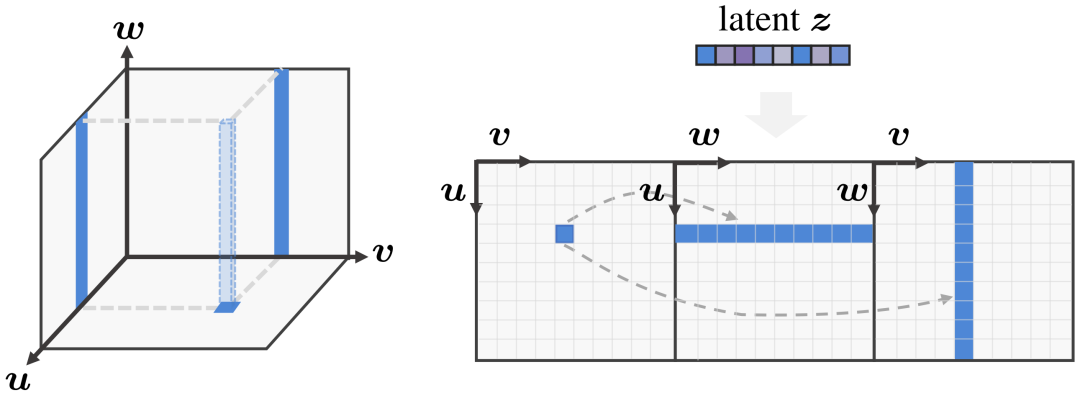
图3:3D 感知卷积高效处理 3D 特征。(左图) 用三平面(triplane)表达 3D 空间,此时底部特征平面的特征点对应于另外两个特征平面的两条线。(右图)引入 3D 感知卷积处理展开的 2D 特征平面,同时考虑到三个平面的三维固有对应关系。
要实现 3D 图像的生成需要三个关键要素:
-
3D 感知卷积,确保降维后的三个平面的内在关联。传统 2D 扩散中使用的 2D 卷积神经网络(CNN)并不能很好地处理 Triplane 特征图。而 3D 感知卷积并不是简单生成三个 2D 特征平面,而是在处理这样的 3D 表达时,考虑了其固有的三维特性,即三个视图平面中其中一个视图的 2D 特征本质上是 3D 空间中一条直线的投影,因此与其他两个平面中对应的直线投影特征存在关联性。为了实现跨平面通信,研究员们在卷积中考虑了这样的 3D 相关性,因此高效地用 2D 的方式合成 3D 细节。
-
隐空间协奏三平面 3D 表达生成。研究员们通过隐向量来协调特征生成,使其在整个三维空间中具有全局一致性,从而获得更高质量的化身并实现语义编辑,同时,还通过使用训练数据集中的图像训练额外的图像编码器,该编码器可提取语义隐向量作为扩散模型的条件输入。这样,整体的生成网络可视为自动编码器,用扩散模型作为解码隐空间向量。对于语义可编辑性,研究员们采用了一个冻结的 CLIP 图像编码器,与文本提示共享隐空间。
-
层级式合成,生成高保真立体细节。研究员们利用扩散模型先生成了一个低分辨率的三视图平面(64×64),然后再通过扩散上采样生成高分辨率的三平面(256×256)。这样,基础扩散模型集中于整体 3D 结构生成,而后续上采样模型专注于细节生成。
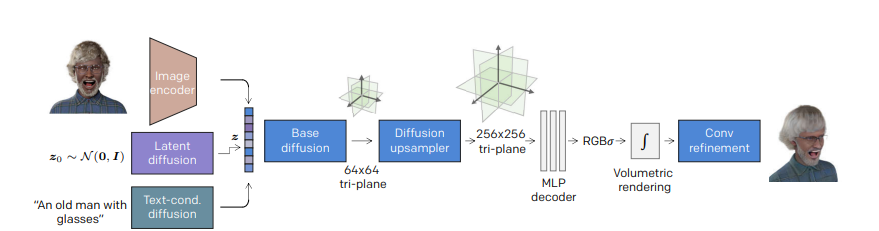
图4:RODIN 模型概述
此外,在训练数据集方面,研究员们借助开源的三维渲染软件 Blender,通过随机组合画师手动创建的虚拟 3D 人物图像,再加上从大量头发、衣服、表情和配饰中随机采样,进而创建了10万个合成个体,同时为每个个体渲染出了300个分辨率为256*256的多视图图像。在文本到 3D 头像的生成上,研究员们采用了 LAION-400M数据集的人像子集训练从输入模态到 3D 扩散模型隐空间的映射,最终让 RODIN 模型可以只使用一张 2D 图像或一句文字描述就能创建出逼真的 3D 头像。

图5:利用文字做 3D 肖像编辑

图6:更多随机生成的虚拟形象 (更多结果请点击阅读原文,移步项目网页)
微软亚洲研究院主管研究员张博表示,“此前,3D 领域的研究受限于技术或高成本,生成的 3D 结果主要是点云、体素、网格等形式的粗糙几何体,而 RODIN 模型可创建出前所未有的 3D 细节,为 3D 内容生成研究打开了新的思路。我们希望 RODIN 模型在未来可以成为 3D 内容生成领域的基础模型,为后续的学术研究和产业应用创造更多可能。”
让3D内容生成
更个性、更普适
现如今,虚拟人、数字化身在电影、游戏、元宇宙、线上会议、电商等行业和场景中的需求日益增多,但其制作流程却相当复杂专业,每个高质量的化身都必须由专业的 3D 画师精心创作,尤其是在建模头发和面部毛发时,甚至需要逐根绘制,其中的艰辛历程外人难以想象。微软亚洲研究院 RODIN 模型的快速生成能力,可以协助 3D 画师减轻数字化身创作的工作量,提升效率,促进 3D 内容产业的发展。
目前,3D 真人化身的创建耗时耗力,很多项目背后可能都有一个上百人的团队在做支持,实现方法更多的是借助虚幻引擎、游戏引擎,再加上画师的专业绘画能力,才能设计出高度逼真的真人定制 3D 化身,普通大众很难使用这些服务,通常只能得到一些现成的、与本人毫无关连的化身。而 RODIN 模型低成本和可定制化的 3D 建模技术,兼具普适性和个性化,让 3D 内容生成走向大众成为可能。
刘潏
微软亚洲研究院资深产品经理
尽管当前 RODIN 模型生成结果主要为半身的 3D 头像,但是其技术能力并不仅限于 3D 头像的生成。随着包括花草树木、建筑、汽车家居等更多类别和更大规模训练数据的学习,RODIN 模型将能生成更多样的 3D 图像。下一步,微软亚洲研究院的研究员们将用 RODIN 模型探索更多 3D 场景创建的可能,向一个模型生成 3D 万物的终极目标不断努力。
关注微软科技视频号
了解更多科技前沿资讯

- 相关推荐
- 热点推荐
- 微软
-
中国传动网:全球首张3D打印唱片发布 歌声也可3D打印2013-12-17 2998
-
如何读取某文件夹内第几张照片2017-09-06 3446
-
3D ToF怎么引领行业应用浪潮?2019-08-01 2799
-
3D电子产品目录加强数字化客户体验的同时成为创新的销售模式2020-05-26 1290
-
【PHYTEC开发板试用体验】3 通过开发板拍一张照片2022-06-12 4283
-
视觉处理,2d照片转3d模型2023-05-21 23692
-
一张照片就可识别用户身份准确率达99.5%2017-12-18 14098
-
谷歌面部追踪468点,无缝贴合3D人脸,不用深度 传感器2019-02-26 1665
-
一张照片进行AI“换脸”之后,可以突破刷脸支付的安全系统吗?2019-09-12 6246
-
Facebook 3D照片使用范围扩大,不再局限于模式照片2020-02-29 2368
-
一张照片揭示了即将推出的Realme X9的纤薄外形2021-01-27 3265
-
浅谈3D工厂数字化建模的发展2021-04-13 2012
-
关于3D数字化博物馆展示技术2021-04-19 1678
-
一张照片生成3D头像!苹果新模型击败StyleGAN22023-05-06 1843
-
欢创播报 腾讯元宝首发3D生成应用2024-07-18 2158
全部0条评论

快来发表一下你的评论吧 !
