

如何利用大规模语言模型将自然语言问题转化为SQL语句?
描述
1 简介
有的工作尝试引出中间推理步骤,通过将复杂问题显示分解为多个子问题,从而以分而治之的方式来解决。考虑到组合泛化对于语言模型有一定的挑战,这种递归方法的对于复杂任务特定有用。根据解决子问题的方式可以分为串行跟并行两种,串行的方式每个子问题相互依赖,前面子问题的答案会加入到后续子问题的prompt中,生成后续子问题的答案,而并行的方式则各个子问题的答案生成是独立的,最后再将多个子问题的答案融合到一起。
2 并行式
DECOMPRC
在阅读理解场景下,多跳阅读理解要求从众多段落中进行推理跟归纳。于是出现了新的方案DECOMPRC,将多跳阅读理解问题分解成多个相对简单的子问题(现有阅读理解模型可以回复),从而提高阅读理解准确性。

图1: DECOMPRC示例
整个方案分为三个部分
a) 将原始的多跳阅读理解问题分解为多个单跳子问题。可以根据多个不同的推理类型得到多种分解方式,这里需要根据不同推理类型分别训练多个用于问题分解的模型,对于每个分解模型,采用Point的方式,利用BERT对原问题进行预测,得到几个关键位置,利用关键位置原文本进行划分,再加上一些规则手段,就可以得到对应的子问题了。例如预测出一个中间位置,就可以将原问题分割成两部分,第一部分作为第一个子问题,第二部分作为第二个子问题,考虑到第二部分可能都是陈述句,就将前面的词转换成which。这里将分解模型简化为一个span prediction问题,只需要400个训练数据就得到很不错的效果了。
b) 在第一步会产生多种问题分解方式,对于每一种分解方式,利用单跳阅读理解模型回复每个子问题,然后根据不同分分解类型的特性得到最终的答案。
c) 对于每一种分解方式,将原问题,分解类型,该分解方式下的问题跟对应答案一同作为模型输入,预测哪种分解方式对应的结果最合理,将该分解方式下的答案作为多跳阅读理解问题的答案。
整个流程可以简单理解为,系统提供了几种将多跳问题分解为子问题的方式,分别计算每个分解方式的合理性,再选择其中最优的分解方式对应的答案作为原问题最终答案。
QA
在QA场景下,通过将复杂问题分解为相对简单的子问题(QA模型可以回复),从而提高问答的效果。具体到多跳QA问题上,现将复杂问题分解为多个子问题,利用单跳QA模型生成全部子问题的答案并融合到一起作为复杂问题的答案。
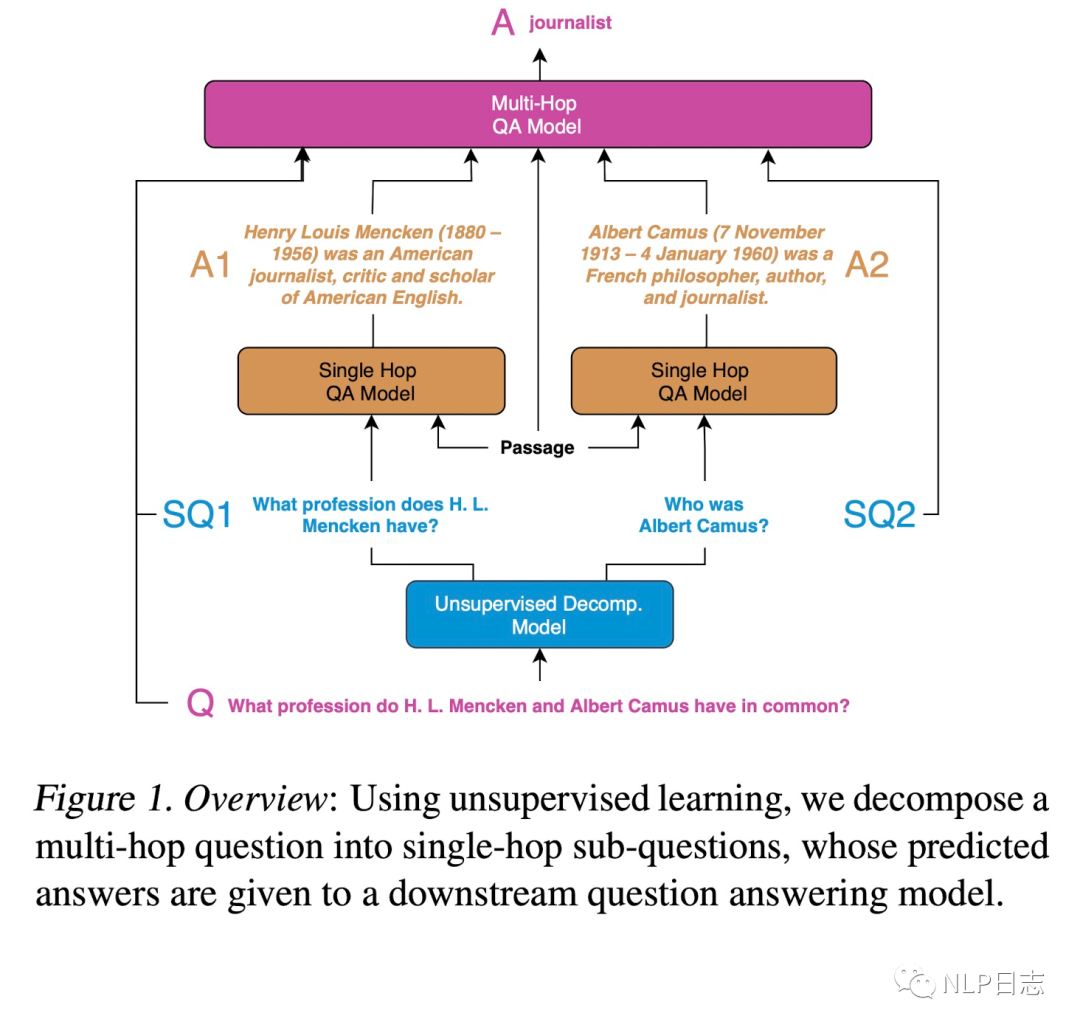
图2: QA场景下的recursive prompting方案示例
整个系统分为三个部分
a) 无监督问题分解,将原问题分解为多个相对简单的子问题。这里需要训练一个分解模型,用于将复杂问题分解成多个子问题。由于这个任务下的监督训练数据构造成本高昂,于是提出了一种无监督的训练数据构造方式,对于每一个复杂问题q,从语料集Q中检索召回得到N个对应的简单问题s作为q的子问题,N的取值可以依赖于具体任务或者具体问题。我们希望这些简单问题在某些方面跟q足够相似,同时这些简单问题s之间有明显差异。从而构造出复杂问题跟子问题序列之间的伪pair对(q, [s1,…sN]),用于训练分解模型。
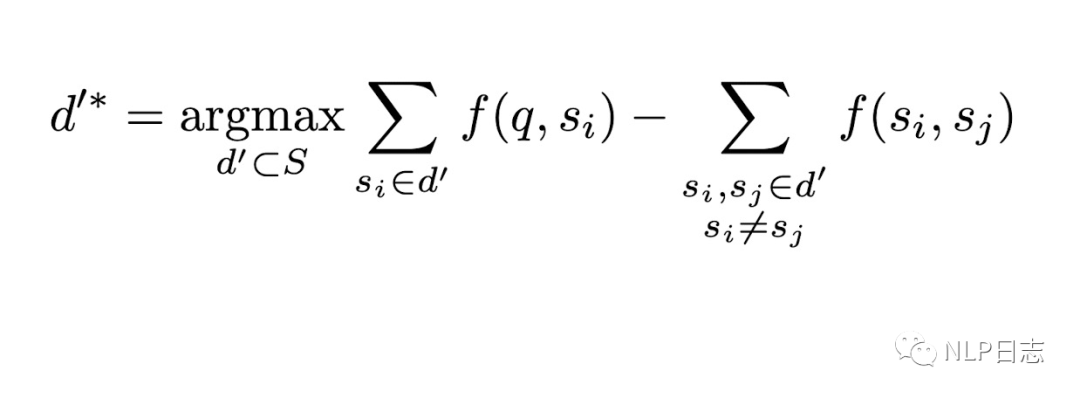
b) 生成子问题回复,利用现有的QA模型,去生成各个子问题的回复。这里不对QA模型有太多限制,只要它能正确回复语料库S中的简单问题即可,所以尽量采用在S中效果优异的QA模型。
c) 生成复杂问题回复,将复杂问题,各个子问题跟对应回复一同作为QA模型的输入,生成复杂问题的回复。这里的QA模型可以采用跟第二步一样的模型,只要将输入做对应调整即可。

图3: QA场景下的recursive prompting方案示例
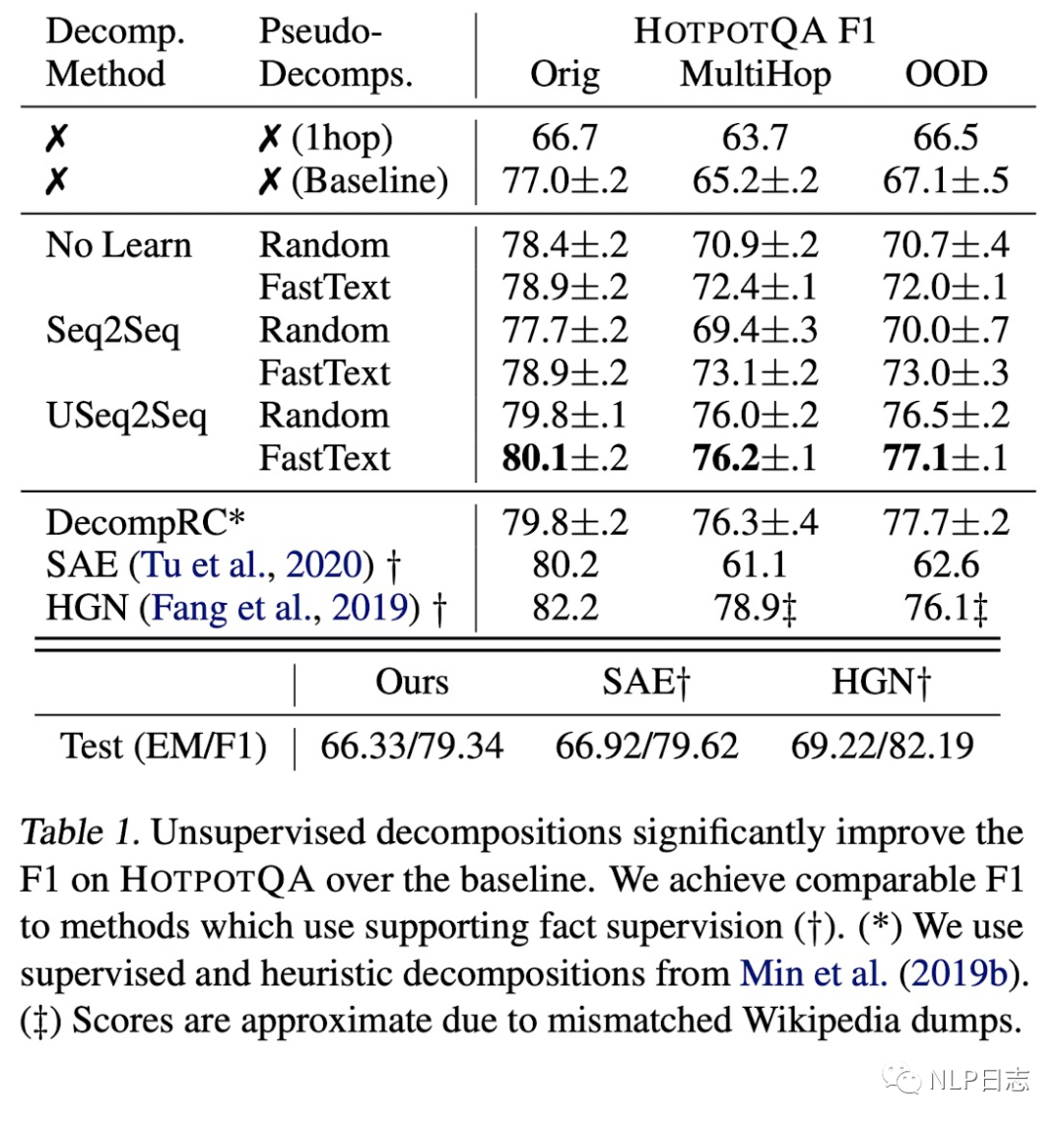
图4: 实验结果对比
从实验效果上可以明显看出这些问题分解的方式能够显著提升模型效果。
串行式
SEQZERO
如何利用大规模语言模型将自然语言问题转化为SQL语句?SEQZERO就是一种解法。由于SQL这种规范语言的复合结构,SQL语句很多情况下会显得复杂且冗长,要让语言模型学会生草本跟SQL语言需要大量训练数据,于是出现了一种基于few-shot的方法SEQZERO。
一个SQL语句包括多个部分,例如From **,SELCT **, WHERE **,只要能从自然语言问题中提出这几个部分对应的元素,然后通过规则可以转化为对应的SQL语句。于是SEQZERO的做法就是先利用语言模型预测得到其中一个元素,将该元素加入到原问题中生成下个元素,重复此操作直到生成全部元素,然后通过规则将所有结果组合起来的就得到对应的SQL语句。在预测每个元素的过程中,为了得到更加强大的泛化能力,采用了few-shot跟zero-shot的集成策略。
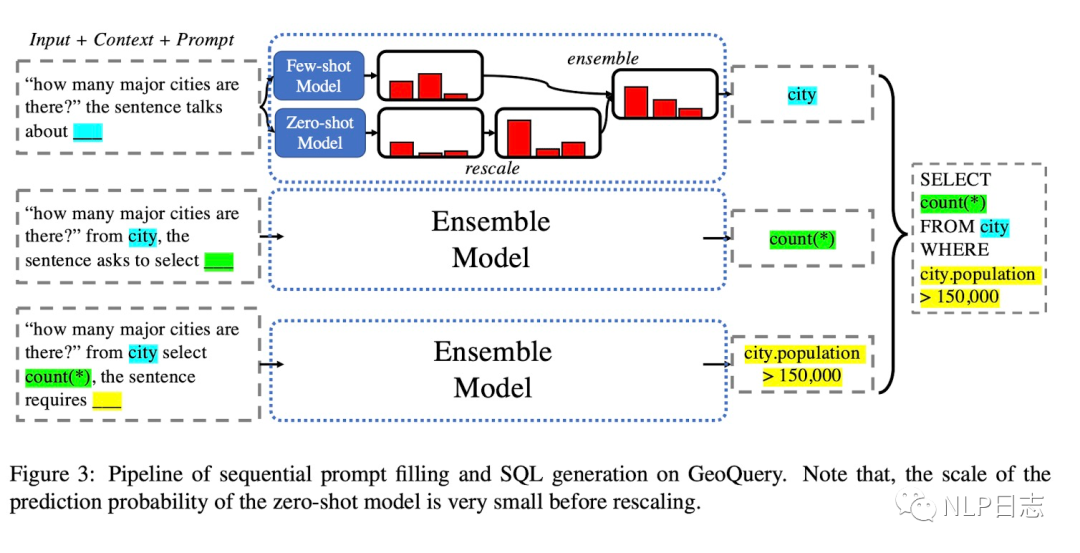
图5: SEQZERO示例
Least-to-most
虽然chain-of-thought prompting在很多自然语言推理任务有显著效果,但是当问题比prompt里的示例更难时,它的表现会很糟糕。举个例子,比如任务抽取文本每个单词最后一个字母,prompt的示例输入是3个单词,输入相对较短,但是问题的长度却是10个单词,这种情况下chain-of-thought prompting的策略就会失效。于是提出了Least-to-most,通过两阶段的prompting来解决这种问题,第一阶段通过prompting将原问题分解为一系列子问题,第二阶段则是通过prompting依次解决子问题,前面子问题的问题跟答案会加入到候选子问题的模型输入中去,方便语言模型更好地回复候选子问题。由于这两个阶段任务有所区别,对应的prompt内容也不同。
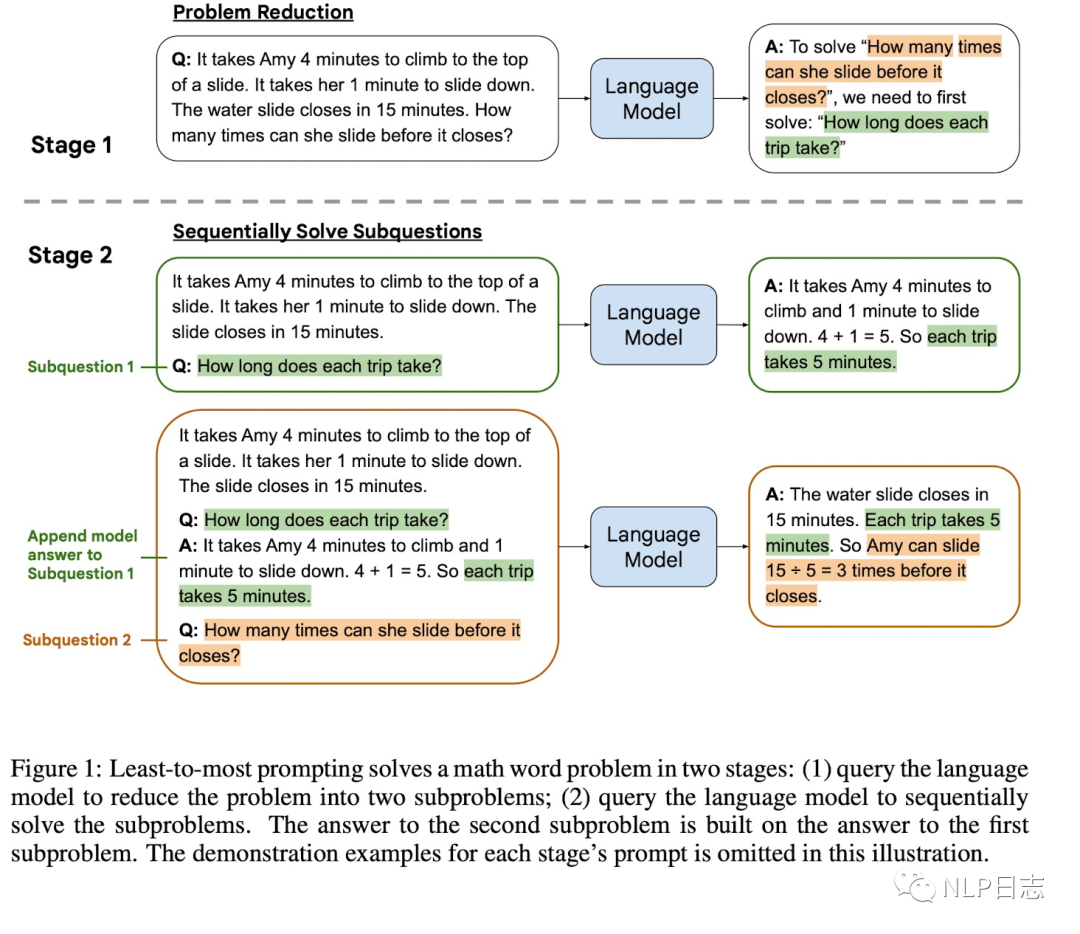
图6: Least-to-most示例
4 其他
Successive prompting
前面几种方法都是一开始就将问题分解为多个子问题,然后在通过串行或者并行的方式回复所有子问题,而successive prompting则是每次分解出一个子问题,让语言模型去回复该子问题,再将该子问题以及对应答案加入到模型输入种,进而分解出下一个子问题,重复这个过程直到没有新的子问题生成,那么最后一个子问题的答案就是原问题的答案。

图7: successive prompting示例
5 总结
Recursive prompting这种思路其实蛮好理解的,目前大规模语言模型处理这些简单任务效果是很不错的,但是复杂问题就比较糟糕了,一方面构造这些复杂问题相关数据的工作很艰巨,另一方面直接让语言模型在这些复杂问题数据上训练效果也很一般(想想为什么有些数据集上sota指标也很低)。但是让语言模型学会根据具体问题进行拆解,通过将复杂问题分解为相对简单的子问题,采用分而治之的方式,再将子问题答案汇总,不就得到原问题的答案了嘛。这也跟我们人类的行为模式更加接近,对于复杂任务,我们会通过合理规划将其划分为具体多个子任务,然后再去一一解决这些子任务。想想中华民族伟大复兴的道路,不也是通过一个又一个的五年计划逐步向前推进的嘛。
审核编辑:刘清
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1390
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 892
-
大规模语言模型的基本概念、发展历程和构建流程2023-12-07 6740
-
自然语言处理的概念和应用 自然语言处理属于人工智能吗2023-08-23 2886
-
自然语言和ChatGPT的大模型调教攻略2023-04-24 2196
-
如何使用TensorRT 8.0进行实时自然语言处理2022-04-02 2687
-
嵌入式SQL语句与主语言之间的通信2021-12-22 2337
-
什么是自然语言处理2021-09-08 2776
-
基于自然语言生成多表SQL语句模板填充的方法2021-04-09 1242
-
自然语言处理的语言模型2020-04-16 2805
-
关于自然语言处理之54 语言模型(自适应)2020-04-09 2307
-
自然语言处理怎么最快入门?2018-11-28 2736
-
python自然语言2018-05-02 6428
-
自然语言处理常用模型解析2017-12-28 6589
全部0条评论

快来发表一下你的评论吧 !
