

浅析时序数据库的流计算支持
描述
01
时序数据及其特点
时序数据(Time Series Data)是基于相对稳定频率持续产生的一系列指标监测数据,比如一年内的道琼斯指数、一天内不同时间点的测量气温等。时序数据有以下几个特点:
● 历史数据的不变性
● 数据的有效性
● 数据的时效性
● 结构化的数据
● 数据的大量性
02
时序数据库基本架构
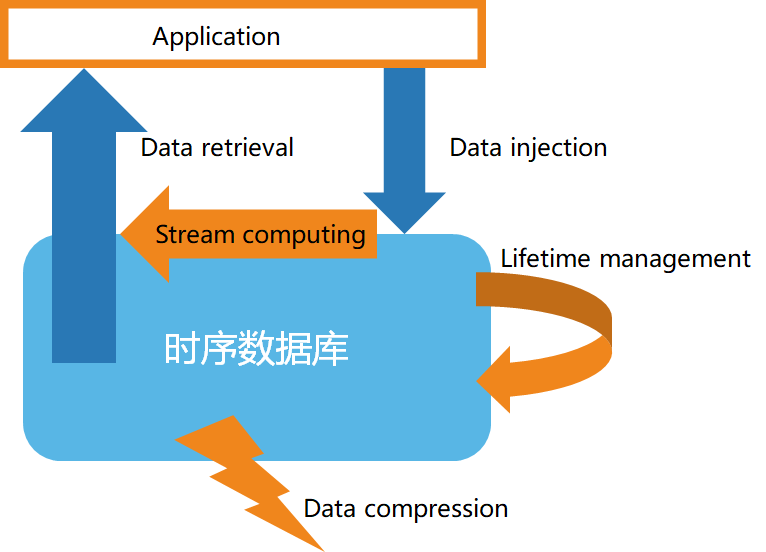
针对时序数据的特点,时序数据库一般具有以下特性:
● 高速的数据入库
● 数据的生命周期管理
● 数据的流处理
● 高效的数据查询
● 定制的数据压缩
03
流计算介绍
流计算主要是指针对实时获取来自不同数据源的海量数据,经过实时分析处理,从而获得有价值的信息。常见的业务场景包括实时事件的快速反应,市场变化的实时告警,实时数据的交互分析等。流计算一般包括如下几方面的功能:
1)过滤和转换 (filter & map)
2)聚合以及窗口函数 (reduce,aggregation/window)
3)多数据流合并以及模式匹配 (joining & pattern detection)
4)从流到块处理
04
时序数据库对流计算的支持
案例一:使用定制化的流计算 API,如下面例子所示:
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
案例二:使用类 SQL 指令,创建流计算以及定义流计算规则,如下:
CREATE STREAM current_stream TRIGGER AT_ONCE INTO current_stream_output_stb AS SELECT _wstart as start, _wend as end, max(current) as max_current FROM meters WHERE voltage <= 220 INTEVAL (5S) SLIDING (1s);
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
时序数据库是什么?时序数据库的特点2024-04-26 1850
-
涂鸦推出NekoDB时序数据库,助力全球客户实现低成本部署2023-07-24 2969
-
CeresDB 1.0正式发布,Rust高性能云原生时序数据库2023-03-06 1755
-
华为自研分布式时序数据库集群:初始GaussDB(for Influx)2022-12-02 1762
-
华为PB级时序数据库Gauss DB,助力海量数据处理2022-10-15 1990
-
华为时序数据库为智慧健康养老行业贡献应用之道2021-11-07 6871
-
关于时序数据库的内容2021-07-12 1547
-
工业互联网时代:我们为什么需要时序数据库之二2020-12-25 1534
-
时序数据库的前世今生2020-12-17 4633
-
时序数据库HiTSDB的深度解析!2019-07-22 1548
-
工业互联网时代,我们为什么需要时序数据库之二:适合的就是最好的2019-04-28 3846
-
工业互联网时代,我们为什么需要一个时序数据库?2019-01-28 7031
-
TableStore时序数据存储 - 架构篇2018-08-08 944
-
时间序列数据的存储和计算 - 开源时序数据库解析2018-01-25 3548
全部0条评论

快来发表一下你的评论吧 !
